
Как отмечалось в п.2.1, по ограниченным
данным выборки объема n можно
построить модель лишь с некоторой
точностью. её параметры a и b
являются оценками истинных значений α
и β, которые определяются генеральной
совокупностью объема N >> n.
Последней приписываются вероятностные
свойства с применением аксиом теории
вероятности, определений случайной
величины, вероятности, плотности
вероятности, оператора усреднения и
т.д. В рамках свойств генеральной
совокупности объема N рассматривается
спецификация модели линейной
регрессии
![]()
,
в
которой α, β, xi –
детерминированные (фиксированные или
известные) величины, а значения показателя
yi и ошибки модели i
– случайные величины (СВ) с
заданным распределением (например,
плотности вероятности). Часто yi,
i считаются
нормальными СВ (НСВ), тогда модель
называют нормальной.
Ограниченные данные выборки объема n
<< N позволяют вместо точной
модели (2.1) с параметрами α и β
построить приближенную модель (2.2)
![]()
.
Здесь еі – остатки
регрессии, вероятностные свойства
которых считаются аналогичными ошибкам
i , а
a, b – некоторые оценки (приближенные
значения) параметров модели.
Мы
будем оценивать дисперсии и
среднеквадратичные ошибки (СКО) для
оценок параметров модели и величины :
![]()
;
![]()
;
![]()
,
где M[X], D[X] – математическое
ожидание и дисперсия случайной величины
Х.
Для непрерывной случайной величины Х
с плотностью вероятности р(х)
они определяются как
![]()
,
![]()
.
Следовательно, для точного определения
того или иного параметра случайной
величины достаточно знать (или задать)
её распределение плотности вероятности.
2.4.1. Основные условия (гипотезы) анализа ошибок
Поскольку в корреляционно-регрессионном
анализе мы опираемся на методы
математической статистики и теории
вероятности, любые оценки ошибок
моделирования являются корректными
лишь при выполнении исходно принятых
условий (гипотез) в отношении величин
и переменных, входящих в модель. Примем
следующие гипотезы:
1. В спецификации модели (2.1) фактор х
и параметры модели α, β – детерминированные
величины, а показатель уi
и ошибки моделирования i
– случайные величины.
2. Ошибки моделирования имеют нулевое
среднее значение и некоррелированны:
![]()
Невыполнение второго условия называют
автокорреляцией ошибок модели.
3. Дисперсия ошибок моделирования i
показателя не зависят от номера i
(гомоскедастичность):
![]()
Невыполнение этого условия называют
гетероскедастичностью.
Дополнительным условием, которое может
не выполняться в ряде случаев, является
свойство нормальной модели:
4. Ошибки i
являются нормальными СВ:
N(0,
2) c нулевым
математическим ожиданием mε
= 0 и дисперсией 2.
2.4.2. Ошибки оценок параметров модели
Покажем сначала, что оценки МНК параметров
линейной модели являются несмещенными,
т.е. математические ожидания оценок
совпадают с истинными значениями
параметров:
M[b] = β, M[a] = α.
Действительно, согласно (2.12) и (2.7) имеем:

. (2.27)
С учетом (2.1), детерминированности vi
и условия
M[i]
= 0 гипотезы 2 получим в результате
усреднения оценки b в рамках
генеральной совокупности
![]()
.
Здесь использовано одно из свойств для
коэффициентов vi

(2.28)
которые
следуют из (2.27).
Аналогично, для параметра a с учетом
(2.6) и несмещенности b получим
![]()
.
Таким
образом, обе оценки МНК параметров
линейной модели являются несмещенными,
то есть сходятся при неограниченном
увеличении объема выборки к точным
значениям параметров α и β. Поэтому при
определении их дисперсий усредняются
квадраты разностей оценок и истинных
значений параметров.
Определим дисперсию коэффициента
регрессии. Известными свойствами
дисперсии СВ Х, умножаемой или
складываемой с константой с, являются:
![]()
. (2.29)
Тогда
с использованием (2.27) – (2.29)

.(2.30)
Здесь принято во внимание, что дисперсии
D[yi] =D[i],
так как показатель и ошибка модели
как случайные величины отличаются на
детерминированное слагаемое a+ bxi.
Дисперсию
постоянной составляющей модели определим
как
![]()
. (2.31)
Так как
![]()
. (2.32)
и
![]()
, (2.33)
то с
учетом (2.32), (2.33) дисперсия (2.31) становится
равной

. (2.34)
Более
сложным является определение оценки
дисперсии ошибок модели. Опуская вывод,
приведем окончательную формулу для
несмещенной оценки дисперсии ошибок
моделирования
![]()
, (2.35)
выраженную
через остатки регрессии (2.2).
Выражения (2.30), (2.34) дают точные значения
дисперсий оценок параметров модели,
однако практически воспользоваться
ими нельзя, так как точное значение
дисперсии ошибок 2
неизвестно (оно определяется из
генеральной совокупности, а не из
выборки). На основе выборочных данных
можно лишь оценить с помощью (2.35) эту
дисперсию. Поэтому на практике в формулы
(2.31), (2.35) вместо 2
подставляют её оценку (2.35) и получают
оценки дисперсий параметров b и a:

, (2.36)

. (2.37)
Эти
оценки используют лишь выборочные
данные. СКО этих оценок равны положительным
значениям квадратного корня из дисперсий.
В
лияние
СКО оценок параметров на точность модели
отражается на рис.2.5, а, б. Сдвиг
постоянной составляющей в пределах а
а
не является существенным при моделировании,
так как он не изменяется при всех
значениях фактора х и его можно
легко скорректировать. Более существенные
последствия имеет ошибка в определении
коэффициента регрессии b. Как видно
из рис.2.5, б, ошибки в прогнозах
показателя у* становятся тем
больше, чем больше отклонение от среднего
значения фактора х. Стандартное отклонение
у* b
имеет место при
![]()
.
В общем случае граничная ошибка регрессии
(с доверительной вероятностью 68%)
пропорциональна величине
![]()
.
Иначе говоря, чем больше отличается
значение фактора х при прогнозе от
среднего, тем больше можно ошибиться в
результате прогнозирования. Ясно также,
что СКО b
уменьшается с ростом объема выборки n,
так как растет число положительных
слагаемых в знаменателе (2.36).

а б
Рис.2.5
Пример 2.2. Оценим
СКО и доверительные интервалы оценок
параметров модели примера 2.1 для малой
выборки объема n
= 5, приняв доверительную вероятность Р
= 0,954.
Оценка дисперсии
ошибок модели согласно (2.36) и расчетов,
приведенных в таблице 2.1, равна
![]()
.
Тогда СКО оценок
b
= 0,588 a
= – 0,529 параметров модели в соответствии
с (2.37), (2.38) равны
![]()
.
Ошибки оказались
сравнительно большими в связи с малым
объемом выборки (n
= 5). Найденные значения СКО являются
точечными ошибками оценок параметров.
Определим далее доверительные интервалы
этих оценок. Для нормальной модели
граничная ошибка равна
Δ = tσ,
где
параметр доверия t
= 1 при доверительной вероятности Р
= 0,68,
t = 2
при Р
= 0,954,
t =
3 при Р
= 0,997.
В нашем примере
t = 2
(Р
= 0,954), Δb
= 0,256, Δa
= 1,678,
тогда
доверительные интервалы для истинных
значений параметров
и α с границами b
Δb,
a
Δa
определяются как
[0,332; 0,844],
α
[ – 2,207; 1,149].
Это значит, что
при доверительной вероятности 95,4%
коэффициент регрессии
b (и,
соответственно, наклон прямой линии
модели) может измениться более чем в
2,5 раза, а девиация (отклонение) постоянной
составляющей а
близка к
1,7 у.е. Очевидно, подобные ошибки малой
выборки неприемлемы для практических
целей, поэтому реальные объемы выборки
должны составлять десятки, сотни и более
элементов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Как сделать анализ ошибок, чтобы сделать все ваши модели лучше
Перевод
Ссылка на автора

Введение
Существует множество способов улучшить готовые модели машинного обучения. Есть вещи, которые вы можете сделать как с моделями, так и с данными, чтобы получить лучшие результаты, чем со стандартной версией модели scikit-learn. Существует разработка функций, настройка гиперпараметров и выбор правильной функции стоимости. Если мы углубимся в глубокое обучение, то подойдем к идеям сетевых архитектур, трансферного обучения и многим другим. Как ученый, работающий с данными, это одни из первых и самых важных вещей, которые вы узнаете о построении моделей. Такие инструменты, как случайный поиск и поиск по сетке, должны быть в наборе инструментов каждого ученого, чтобы помочь оптимизировать этот процесс и построить наилучшую возможную модель.
Когда вы работаете над проектом, большинство людей делают все то, что я изложил выше, а затем, с помощью перекрестной проверки или разделения теста поезда, получают некоторую метрику оценки. Эти шаги повторяются до тех пор, пока не будет получена наилучшая возможная метрическая оценка, и модель не будет признана достойной использования. Это ни в коем случае не плохой путь. Обычно это приводит к отличным моделям, которые обеспечивают ценность так, как они должны. Однако, приложив немного дополнительных усилий, вы сможете сделать каждую модель, которую вы когда-либо построите, лучше. Мы можем сделать это с помощью анализа ошибок.
Анализ ошибок
Что это такое?
При построении модели вы можете сделать это случайно или намеренно. Случайный подход к построению модели заманчиво. Это требует меньше усилий и все же приносит результаты. Случайный подход был бы в том случае, когда после каждой итерации модели вы решаете попробовать что-то новое, чтобы сделать это лучше, не задумываясь о том, почему. Это просто так: идея пришла вам в голову, которая может улучшить счет Ф1, так почему бы не попробовать? Это легко и работает.

Преднамеренный подход к построению модели использует анализ ошибок. Анализ ошибок требует от вас копаться в результатах вашей модели после каждой итерации. Вы просматриваете данные и прогнозы на уровне наблюдений и формируете гипотезы о том, почему ваша модель не оправдалась при определенных прогнозах. Затем вы проверяете свою гипотезу, изменяя модель таким образом, чтобы исправить эту ошибку, и начинаете следующую итерацию. Каждая итерация моделирования занимает больше времени с анализом ошибок, но окончательные результаты лучше и, скорее всего, будут быстрее.
Правильный способ сделать анализ ошибок
Не существует установленного способа выполнения анализа ошибок. Это исследовательский и требует творчества и знаний в области. При этом я собираюсь рассказать вам о шагах, которые я обычно делаю, когда делаю это. Надеемся, что это даст вам отправную точку, чтобы найти отличные идеи от ошибок в вашей модели.
Процесс анализа ошибок
С каждой итерацией модели я начинаю с начала этих шагов и прохожу их, пока не найду что-то, что должно быть исправлено. Я делаю свою гипотезу, меняю свою модель и начинаю процесс снова, пока не буду удовлетворен. В этом разделе я расскажу вам о шагах, которые я предпринимаю, о некоторых вещах, которые вы можете найти неправильно, и о некоторых возможных решениях для них. Мы будем работать от самого высокого уровня данных до самого маленького уровня, ища ошибки на этом пути.
Ошибки уровня данных
Это тип анализа ошибок, который, вероятно, является наиболее распространенным, и большинство людей делают. Я хотел бы начать с рассмотрения ошибок модели в масштабе всех данных.
Чрезмерная фитинг / Под облегать
Проверьте, не перегружена ли ваша модель. Мой любимый способ сделать это — использовать кривые обучения, такие как приведенные ниже.

Как правило, я обнаружил на практике, что лучше всего сначала переписать, а затем использовать методы регулирования, чтобы вернуть модель в хорошее место.
Потенциальные исправления:
- Если переопределение, то регуляризация L1 или L2 или больше данных
- Если подгонка, то более сложная модель или больше функций
Распределение прогноза
Убедитесь, что распределение ваших данных выглядит примерно так же, как распределение ваших прогнозов. Если они не похожи друг на друга, у нас есть некоторые проблемы.
Потенциальные исправления:
- Удаление выбросов из данных
- Использование другой функции стоимости
Ошибки уровня группы
Как только ошибки уровня данных будут устранены, мы можем рассмотреть ошибки по группам. Целью этой части анализа ошибок является выявление групп, в которых модель работает плохо. Некоторые знания предметной области могут быть полезны при принятии решения о создании групп. Я бы предложил начать с очевидных групп, которые уже существуют в данных, а затем перейти к созданию групп из интуиции. Например, я мог бы начать с рассмотрения ошибок предсказания по категориальным переменным, а затем перейти к разбивке числовых переменных на корзины для изучения Когда я смотрю на группы, есть несколько конкретных вещей, на которые я всегда обращаю внимание.
За / Под Предсказаниями
Проверьте, есть ли какие-либо конкретные группы, для которых модель переоценивает или недооценивает большую часть времени. Если модель всегда переоценивает определенную группу, это похоже на то, что мы можем научить ее исправить. Также примите к сведению, если группам, которые работают плохо, не хватает данных.
Потенциальные исправления:
- Наказывать за чрезмерные прогнозы для этой группы
- Методы передискретизации при отсутствии данных
- Сбор данных, если данных не хватает
Большие средние ошибки
Проверьте, не вносит ли какая-либо группа вклада в общую ошибку больше, чем все остальные группы. Это важно отметить по нескольким причинам. Во-первых, мы явно хотим знать, что не так, чтобы это можно было исправить. Во-вторых, это важно для интерпретируемостии применение модели. Если модель работает хорошо во всех группах, кроме одной, вы можете просто использовать эту модель для всего, кроме этой группы, если это невозможно исправить.
Потенциальные исправления:
- К-стратифицированная перекрестная проверка для обеспечения групповых наблюдений в каждом расколе
- Методы передискретизации при отсутствии данных
- Сбор данных — это отсутствие данных
Индивидуальные ошибки
Теперь мы приступаем к мельчайшим деталям. Как только мы выполнили весь анализ ошибок более высокого уровня, пришло время погрузиться в ошибки каждого наблюдения. Мне нравится делать это, просматривая 20 лучших ошибок из моих прогнозов. В отличие от анализов более высокого уровня, у меня нет предложений по типичным ошибкам, которые вы можете найти. Вы должны пройти наблюдения и посмотреть на данные и прогноз и определить, был ли прогноз действительным. Иногда модель делала хороший прогноз, и цель этого наблюдения была просто шаткой. Это ошибки, с которыми мы можем жить. Если вы не думаете, что наблюдение кажется разумным, спросите себя, почему. Какую информацию упустила модель, которая должна была помочь ей сделать лучший прогноз? Пройдите несколько наблюдений в поисках закономерностей того, что может быть причиной ошибок. Вы можете найти что-то, что вы пропустили, прежде чем вы могли бы исправить. Вы можете обнаружить, что иногда ваша модель просто портится, и нет никаких причин, чтобы вы могли это увидеть. С этого момента вы либо продолжаете настраивать свою модель, решаете получить больше данных или считаете свою модель хорошей.
Реализуйте это
Анализ ошибок занимает много времени и требует много размышлений. Потратьте время на поиск и изучение причин, по которым ваша модель работает плохо. Шаблон для хорошего анализа ошибок таков:
- Найти ошибки
- Создайте гипотезу о том, что может исправить ошибки
- Проверка гипотезы
- Повторение
Выполнение этих шагов с небольшим творческим потенциалом и терпением поможет вам построить лучшую модель, чем вы могли бы с помощью одной лишь гипер-настройки.
Если у вас есть какие-либо вопросы о том, как сделать эффективный анализ ошибок, оставьте мне комментарий ниже, и я отвечу!
![]()
![]()

Error Analysis
Responsible-AI-Widgets provides a collection of model and data exploration and assessment user interfaces that enable a better understanding of AI systems. One of these interfaces is Error Analysis (+ Interpretability) dashboard.
You can use the Error Analysis dashboard to
- Identify cohorts with high error rate versus benchmark and visualize how the error rate is distributed.
- Diagnose the root causes of the errors by visually diving deeper into the characteristics of data and models (via its embedded interpretability capabilities).
For instance, you can use Error Analysis to discover that the model has a higher error rate for a specific cohort (e.g., females with income <$50K) vs. the rest of the population. Via its embedded interpretability capabilities of this dashboard, you can next understand the most impactful factors responsible for this subset’s erroneous predictions, inspect some individual records of that cohort receiving erroneous predictions, understand their feature importance values, and perform what-if analysis on them to diagnose the contributing error factors better.
Example Notebooks
- Error analysis and interpretability of a census income prediction model
- Error analysis and interpretability of a breast cancer prediction model
- Error analysis of a multi class classification model
- Error analysis of a housing price prediction model
- Error analysis of a critical temperature of superconductors prediction model
Error Analysis Dashboard
Error Analysis drives deeper to provide a better understanding of your machine learning model’s behaviors. Use Error Analysis to identify cohorts with higher error rates and diagnose the root causes behind these errors. Combined with Fairlearn and Interpret-Community, practitioners can perform a wide variety of assessment operations to build responsible machine learning. Use this dashboard to:
- Evaluate Cohorts: Learn how errors distribute across different cohorts at different levels of granularity
- Explore Predictions: Use built-in interpretability features or combine with InterpretML for boosted debugging capability
- Interactive Dashboard View customizable pre-built visuals to quickly identify errors and diagnose root causes
Run the dashboard via:
from raiwidgets import ErrorAnalysisDashboard ErrorAnalysisDashboard(global_explanation, dashboard_pipeline, dataset=X_test_original, true_y=y_test, categorical_features=categorical_features)
Once you load the visualization dashboard, you can investigate different aspects of your dataset and trained model via two stages:
- Identification
- Diagnosis
NOTE
Click on «Open in a new tab» on the top left corner to get a better view of the dashboard in a new tab.
Identification of Errors
Error Analysis identifies cohorts of data with higher error rate than the overall benchmark. These discrepancies might occur when the system or model underperforms for specific demographic groups or infrequently observed input conditions in the training data.
Different Methods for Error Identification
-
Decision Tree: Discover cohorts with high error rates across multiple features using the binary tree visualization. Investigate indicators such as error rate, error coverage, and data representation for each discovered cohort.
-
Error Heatmap: Once you form hypotheses of the most impactful features for failure, use the Error Heatmap to further investigate how one or two input features impact the error rate across cohorts.


Diagnosis of Errors
After identifying cohorts with higher error rates, Error Analysis enables debugging and exploring these cohorts further. Gain deeper insights about the model or the data through data exploration and model explanation. Different Methods for Error Diagnosis:
-
Data Exploration which explores dataset statistics and feature distributions. Compare cohort data stats with other cohorts or to benchmark data. Investigate whether certain cohorts are underrepresented or if their feature distribution is significantly different from the overall data.
-
Global Explanation which explore the top K important features that impact the overall model global explanation for a selected cohort of data. Understand how values of features impact model prediction. Compare explanations with those from other cohorts or benchmark.
-
Local Explanation which enables observing the raw data in the Instance View. Understand how each data point has correct or incorrect prediction. Visually identify any missing features or label noise that could lead to issues. Explore local feature importance values (local explanation) and individual conditional expectation (ICE) plots.
-
What-if analysis (Perturbation Exploration) which applies changes to feature values of selected data point and observe resulting changes to the prediction.
Supported Models
This interpretability and error analysis API supports regression and classification models that are trained on datasets in Python numpy.ndarray, pandas.DataFrame, iml.datatypes.DenseData, or scipy.sparse.csr_matrix format.
The explanation functions of Interpret-Community accept both models and pipelines as input as long as the model or pipeline implements a predict or predict_proba function that conforms to the Scikit convention. If not compatible, you can wrap your model’s prediction function into a wrapper function that transforms the output into the format that is supported (predict or predict_proba of Scikit), and pass that wrapper function to your selected interpretability techniques.
If a pipeline script is provided, the explanation function assumes that the running pipeline script returns a prediction. The repository also supports models trained via PyTorch, TensorFlow, and Keras deep learning frameworks.
Getting Started
This repository uses Anaconda to simplify package and environment management.
To setup on your local machine:
Install Python module, packages and necessary distributions
If you intend to run repository tests:
pip install -r requirements.txt
Set up and run Jupyter Notebook server
Install and run Jupyter Notebook
if needed:
pip install jupyter
then:
jupyter notebook
Зачеркивание красной ручкой и двойки (пока карандашом) — с детства мы привыкли считать, что ошибки — это плохо. Но на самом деле любые провалы могут многому нас научить, главное — грамотно их проанализировать. Сейчас расскажем, как это сделать.
Перед тем как мы перейдем к анализу, важно правильно настроиться. Ошибки — это нормально, их совершают все. Но не грызите себя изнутри — того, что случилось, уже не изменить. Главное, не уходите в отрицание и признайте, что вы действительно оступились. Особенно это важно, если ваши действия повлияли на других людей (кстати, советуем извиниться перед ними, если еще не сделали этого).
Признание своих ошибок — шаг к саморазвитию, на пути к нему вам также поможет наш бесплатный личный план.
Скачайте бесплатный PDF-план «Английский для саморазвития»
Скоро на имейл вам придет письмо с инструкцией. А пока запишитесь на бесплатное онлайн-занятие с преподавателем и получите в подарок еще 2 урока.
Скоро на имейл вам придет письмо с инструкцией. А в течение часа мы позвоним и подберем удобное время занятия. Продуктивного дня 🙂
Ой, произошла ошибка обработки. Попробуйте еще раз чуть позднее.
Ой, произошла ошибка обработки. Скорее всего, такой имейл или телефон уже зарегистрирован.
Ошибки — это то, что вы сделали не так, а провал — результат этих ошибок. Ответьте на вопросы и проанализируйте, какие ваши действия привели сначала к ошибкам, а потом — к провалу (можно по-английски, чтобы заодно потренировать язык).
What was I trying to do initially? — Что я изначально пытался сделать?
What went wrong? — Что пошло не так?
When did it go wrong? — Когда все пошло не так?
Why did it go wrong? — Почему все пошло не так?
Why did I set this goal in the first place? — Почему я вообще поставил эту цель?
Did I dedicate enough time to making that goal happen? — Уделял ли я этой цели достаточно времени?
Did I set smaller goals to help make my big goal seem more realistic? — Ставил ли я маленькие цели, которые бы помогли сделать достижение большой цели более реалистичным?
What things, either in or outside of my control, got in my way? — Какие вещи, находящиеся вне моего контроля или подконтрольные мне, помешали мне достичь цели?
«На ошибках учатся» — верная народная мудрость. Даже если все пошло не так, как вы планировали, из ошибки и провала всегда можно вынести ценные уроки, которые помогут вам в будущем.
How will I prevent the same failure in the future? — Как я предотвращу такой же провал в будущем?
What did I learn about myself during this experience? — Что я узнал о себе во время этого опыта?
What are 3 key takeaways from this failure? — Какие 3 ключевых урока я вынесу из этого провала?

Вы успешно проанализировали свои ошибки и провалы, теперь главное — это не оставить свои выводы на бумаге или в заметках в телефоне. Подумайте, что вы можете поменять в своей жизни уже сейчас, чтобы в будущем не наступать на одни и те же грабли.
Признать ошибку. Да, в 2021 году я действительно не выучил 200 новых английских слов и не перешел на уровень Intermediate. Не буду себя винить, а лучше проанализирую, почему так вышло, и подумаю, что мне поможет достичь цели в 2022-м.
Проанализировать, почему случился провал. Я не рассчитал свои силы и поставил слишком нереалистичную цель. А сил не было, потому что уже пару месяцев у меня совсем нет энергии.
Подумать, чему провал меня научил. Важно уделять внимание своему самочувствию, потому что оно напрямую влияет на продуктивность. И еще правильно формулировать цель и делить ее на промежуточные подцели.
Начать применять выводы на практике. Вот три вещи, которые я сделаю в ближайшее время:
- Сдам анализы и проверю, каких витаминов мне не хватает.
- Налажу режим и начну питаться более здорово.
- Пока поставлю цель не на целый год, а только на январь 2022-го, чтобы проверить, на что я действительно способен. Выучу 10 новых слов — это кажется реальной целью на месяц, и ее достижение придаст мне сил и поднимет мою уверенность в себе.
Факап найт — популярный формат среди предпринимателей, которые уверены, что нужно обязательно несколько раз как следует провалиться, прежде чем у вас получится построить успешный бизнес. Соберите друзей или коллег, подготовьте презентацию с главными провалами 2021 года и расскажите о них с выводами в конце и (желательно) с шуточками. На таких мероприятиях всегда душевная атмосфера, ведь провалы объединяют больше, чем успехи и достижения. Здорово узнать, что мы все не идеальны и порой ошибаемся.
Почему наши умозаключения так часто оказываются ошибочными? Что такое корреляция и причинность? Как рассуждать и делать выводы, опираясь на научный метод? Умение видеть взаимосвязь между явлениями нельзя рассматривать как необязательную опцию. Нам нужен этот навык, чтобы извлекать из массивов данных полезную информацию и уверенно прокладывать курс в океане повседневных решений.
Книга «Почему» научит правильно анализировать данные и определять причинно-следственные связи там, где они есть. Делимся интересными мыслями из нее.
Восприятие и умозаключения
Как вы впервые обнаружили, что лампочка загорается, если повернуть выключатель? Откуда вы знаете, что ружье, выстреливая, производит громкий звук, а не наоборот?
Мы получаем знания о причинах двумя основными путями:
- Восприятие (каузальный опыт). Видя, как в окно влетает кирпич, один бильярдный шар ударяет другой, заставляя катиться, горящая спичка поджигает фитиль свечи, мы получаем впечатления о причинной зависимости на основе входящей сенсорной информации.
- Умозаключения (опосредованные выводы о причинности с помощью дедуктивного метода и на основе некаузальной информации). Причины таких событий, как пищевые отравления, войны и хорошее здоровье, нельзя воспринять непосредственным образом — их предстоит вывести путем логического мышления на основе чего-то, отличающегося от непосредственных наблюдений.
Доверие, которое мы питаем к причинному восприятию, может нас подвести. Если вы слышите громкий звук, а после этого в комнате зажигается свет, легко решить, что эти события взаимосвязаны; однако временная привязка громкого звука и момента, когда некто щелкает выключателем, может быть простым совпадением.

Доверие к причинному восприятию может нас подвести. Источник
Временная и пространственная близость событий — параметры, из-за которых мы нередко делаем ложные выводы.
Например, мы часто слышим, что человеку сделали прививку от гриппа, а к вечеру у него развились схожие с гриппом симптомы, и люди верят, что именно укол стал поводом к этому. Но вакцина против гриппа, содержащая неактивную форму вируса, не может вызвать болезнь. Среди огромного количества привитых у некоторых развиваются другие сходные болезни (по чистому совпадению), или они подхватывают вирус, ожидая приема в клинике.
Время
Близлежащие по времени события могут привести к ошибочным заключениям о причинности. Представьте: у вас разболелась голова и вы приняли некое средство. Через несколько часов боль ушла. Можно ли утверждать, что помогло лекарство?
Временной паттерн позволяет сделать предположение, что ослабление симптома произошло благодаря приему лекарства, однако вы не можете сказать наверняка, что боль не прошла бы сама. Вам пришлось бы провести множество выборочных экспериментов, где вы бы принимали или не принимали препарат, а потом записывали, как быстро исчезала головная боль, чтобы иметь возможность утверждать хоть что-то относительно подобной причинной зависимости. Также пришлось бы сравнить действия лекарства и плацебо.

Причинная зависимость не всегда может быть оправдана. Источник
Длительные задержки между причиной и следствием тоже способны помешать достоверному установлению причинно-следственных связей. Некоторые следствия наступают быстро (удар по бильярдному шару заставляет его двигаться), а некоторые процессы протекают в замедленном режиме. Известно, что курение вызывает рак легких; но между первой сигаретой и днем, когда диагностируют рак, пролегают долгие годы.
Побочные эффекты от приема некоторых препаратов проявляются через десятилетия. Перемены в состоянии здоровья благодаря физическим упражнениям достигаются медленно и не сразу, и, если мы будем ориентироваться только на стрелку весов, может показаться, что вес сначала даже увеличивается, потому что мускулы наращиваются быстрее, чем уходит жир. Ожидая, что следствие должно идти непосредственно за причиной, мы не видим связи между этими глубоко взаимозависимыми факторами.
Корреляция
Корреляция (соотношение, взаимосвязь) не обязательно означает причинную зависимость. Эта мысль прочно вбита в мозги любого студента, изучающего статистику; но порой ошибаются даже те, кто понимает это высказывание и согласен с ним.
Сильная взаимосвязь может показаться убедительной и инициировать ряд успешных прогнозов. Но видимые корреляции иногда объясняются еще не измеренными причинами.
К примеру, мы нашли соотношение в ситуации, когда человек, съевший плотный завтрак, вовремя успевает на работу; однако, вероятно, оба фактора имеют общую причину: человек рано встал, а значит, у него было время хорошо позавтракать, вместо того чтобы в спешке бежать на службу.

Корреляция не обязательно означает причинную зависимость. Источник
Выявив корреляцию между двумя переменными, нужно проверить, способен ли подобный неизмеренный фактор (общая причина) объяснить эту взаимосвязь.
Более того, соотношения способны существовать, даже когда две переменные вообще никак не связаны. Корреляции бывают результатом абсолютной случайности (например, вы много раз за неделю сталкиваетесь с подругой на улице), искусственных условий эксперимента (вопросы могут быть подстроены под конкретные реакции), ошибки или сбоя (баг в компьютерной программе).
Без вариации нет корреляции
Представьте такую ситуацию: вы хотите узнать, как получить грант, поэтому спрашиваете всех друзей, которые его имеют, что, по их мнению, помогло им. Все кандидаты оформляли заявку шрифтом Times New Roman; согласно мнению половины, важно, чтобы на каждой странице была как минимум одна иллюстрация; а треть рекомендуют представить заявку за 24 часа до установленного срока. Означает ли это, что есть корреляция между названными условиями и получением гранта? Нет, не означает.
Поскольку все результаты идентичны, нельзя сказать, что произойдет, если поменять шрифт или представить заявку за минуту до истечения срока.

Без вариации нет корреляции. Источник
И тем не менее широко распространена ситуация, когда анализируются только факторы, ведущие к определенному исходу. Только представьте, насколько часто победителей спрашивают, как именно они добились успеха, а потом стараются этот успех воспроизвести, выполняя в точности те же действия.
Подобный подход полон недостатков по многим причинам, включая то, что люди просто не слишком хорошо умеют определять существенные факторы, недооценивают роль случайностей и переоценивают свои способности. В результате мы не только путаем факторы, которые по чистой случайности сопутствуют желаемому эффекту, с теми, которые действительно его обеспечивают, но и видим иллюзорные корреляции там, где их нет.

Люди не слишком хорошо умеют определять существенные факторы, недооценивают роль случайностей и переоценивают свои способности. Источник
Беседы с победителями бесполезны, поскольку можно сделать то же самое, но не преуспеть. Возможно, все кандидаты оформляют заявки на грант шрифтом Times New Roman (а значит, те, кто не получил гранты, порекомендуют использовать другой шрифт), а может, успешные кандидаты получили грант, несмотря на избыточное количество иллюстраций в документах. Не зная совокупности положительных и отрицательных примеров, мы не сможем даже предположить наличие корреляции.
Ошибка отбора
Одна из важных причин, почему мы ошибаемся с выводами, заключается в том, что данные могут не быть репрезентативными с точки зрения исходного распределения.
Если бы нам разрешили взглянуть на статистику смертей от гриппа, но предоставили только данные о количестве больных, поступивших в лечебные учреждения, мы наблюдали бы гораздо более высокий процент летальных исходов, чем в масштабах всего населения. Это происходит потому, что люди оказываются в стационаре, как правило, с более тяжелыми случаями или дополнительными заболеваниями (и с высокими шансами смерти от гриппа). Так мы сравниваем не все исходы, а только статистику для обратившихся к врачам на фоне симптоматики гриппа.

Данные отбора должны быть репрезентативными. Источник
Или возьмем, к примеру, сайты, опрашивающие посетителей насчет их политических взглядов. В интернете не получится отобрать участников опроса случайно в масштабах всего населения, а данные источников с сильным политическим уклоном искажены еще сильнее.
Если посетители конкретной страницы активно поддерживают действующего президента, то результаты по ним, возможно, покажут, что рейтинг главы государства растет каждый раз, когда он произносит важную речь. Однако это показывает лишь то, что есть корреляция одобрения президента и произнесения им речей перед сторонниками.
Предвзятость подтверждения
Некоторые из когнитивных смещений, заставляющие нас видеть соотношение несвязанных факторов, сходны с ошибкой отбора. К примеру, предвзятость подтверждения заставляет искать доказательства в пользу определенного убеждения.
Иными словами, если вы верите, что лекарство вызывает некий побочный эффект, вы приметесь читать в интернете отзывы тех, кто уже принимал его и наблюдал это действие. Но таким образом вы игнорируете весь набор данных, не поддерживающих вашу гипотезу, вместо того чтобы искать свидетельства, которые, возможно, заставят ее переоценить.
Предвзятость подтверждения также может заставить вас отказаться от свидетельств, противоречащих вашей гипотезе; вы можете предположить, что источник сведений ненадежен или что исследование основывалось на ошибочных экспериментальных методах.

Предвзятость подтверждения. Источник
Помимо предвзятости с точки зрения доказательств, может случиться ошибка интерпретации аргументов. Если в ходе «неслепого» тестирования нового лекарства доктор помнит, что пациент принимает это средство и считает, что оно ему помогает, то может начать искать признаки его эффективности. Поскольку многие параметры субъективны (например, подвижность или усталость), это может привести к отклонениям в оценке данных индикаторов и логическим заключениям о наличии несуществующих корреляций.
Есть и специфическая форма предвзятости подтверждения — иллюзорная корреляция. Она означает поиск соотношения там, где его нет. Возможная взаимосвязь симптомов артрита и погоды настолько широко разрекламирована, что считается доказанной. Однако знание о ней может привести к тому, что пациенты будут говорить о корреляции просто из ожидания ее увидеть. Когда ученые попытались проанализировать эту проблему, взяв за основу обращения пациентов, клинические анализы и объективные показатели, то не обнаружили абсолютно никакой связи.
По материалам книги «Почему».
Обложка поста отсюда.
Как сделать анализ ошибок, чтобы сделать все ваши модели лучше
Перевод
Ссылка на автора
Введение
Существует множество способов улучшить готовые модели машинного обучения. Есть вещи, которые вы можете сделать как с моделями, так и с данными, чтобы получить лучшие результаты, чем со стандартной версией модели scikit-learn. Существует разработка функций, настройка гиперпараметров и выбор правильной функции стоимости. Если мы углубимся в глубокое обучение, то подойдем к идеям сетевых архитектур, трансферного обучения и многим другим. Как ученый, работающий с данными, это одни из первых и самых важных вещей, которые вы узнаете о построении моделей. Такие инструменты, как случайный поиск и поиск по сетке, должны быть в наборе инструментов каждого ученого, чтобы помочь оптимизировать этот процесс и построить наилучшую возможную модель.
Когда вы работаете над проектом, большинство людей делают все то, что я изложил выше, а затем, с помощью перекрестной проверки или разделения теста поезда, получают некоторую метрику оценки. Эти шаги повторяются до тех пор, пока не будет получена наилучшая возможная метрическая оценка, и модель не будет признана достойной использования. Это ни в коем случае не плохой путь. Обычно это приводит к отличным моделям, которые обеспечивают ценность так, как они должны. Однако, приложив немного дополнительных усилий, вы сможете сделать каждую модель, которую вы когда-либо построите, лучше. Мы можем сделать это с помощью анализа ошибок.
Анализ ошибок
Что это такое?
При построении модели вы можете сделать это случайно или намеренно. Случайный подход к построению модели заманчиво. Это требует меньше усилий и все же приносит результаты. Случайный подход был бы в том случае, когда после каждой итерации модели вы решаете попробовать что-то новое, чтобы сделать это лучше, не задумываясь о том, почему. Это просто так: идея пришла вам в голову, которая может улучшить счет Ф1, так почему бы не попробовать? Это легко и работает.
Преднамеренный подход к построению модели использует анализ ошибок. Анализ ошибок требует от вас копаться в результатах вашей модели после каждой итерации. Вы просматриваете данные и прогнозы на уровне наблюдений и формируете гипотезы о том, почему ваша модель не оправдалась при определенных прогнозах. Затем вы проверяете свою гипотезу, изменяя модель таким образом, чтобы исправить эту ошибку, и начинаете следующую итерацию. Каждая итерация моделирования занимает больше времени с анализом ошибок, но окончательные результаты лучше и, скорее всего, будут быстрее.
Правильный способ сделать анализ ошибок
Не существует установленного способа выполнения анализа ошибок. Это исследовательский и требует творчества и знаний в области. При этом я собираюсь рассказать вам о шагах, которые я обычно делаю, когда делаю это. Надеемся, что это даст вам отправную точку, чтобы найти отличные идеи от ошибок в вашей модели.
Процесс анализа ошибок
С каждой итерацией модели я начинаю с начала этих шагов и прохожу их, пока не найду что-то, что должно быть исправлено. Я делаю свою гипотезу, меняю свою модель и начинаю процесс снова, пока не буду удовлетворен. В этом разделе я расскажу вам о шагах, которые я предпринимаю, о некоторых вещах, которые вы можете найти неправильно, и о некоторых возможных решениях для них. Мы будем работать от самого высокого уровня данных до самого маленького уровня, ища ошибки на этом пути.
Ошибки уровня данных
Это тип анализа ошибок, который, вероятно, является наиболее распространенным, и большинство людей делают. Я хотел бы начать с рассмотрения ошибок модели в масштабе всех данных.
Чрезмерная фитинг / Под облегать
Проверьте, не перегружена ли ваша модель. Мой любимый способ сделать это — использовать кривые обучения, такие как приведенные ниже.
Как правило, я обнаружил на практике, что лучше всего сначала переписать, а затем использовать методы регулирования, чтобы вернуть модель в хорошее место.
Потенциальные исправления:
- Если переопределение, то регуляризация L1 или L2 или больше данных
- Если подгонка, то более сложная модель или больше функций
Распределение прогноза
Убедитесь, что распределение ваших данных выглядит примерно так же, как распределение ваших прогнозов. Если они не похожи друг на друга, у нас есть некоторые проблемы.
Потенциальные исправления:
- Удаление выбросов из данных
- Использование другой функции стоимости
Ошибки уровня группы
Как только ошибки уровня данных будут устранены, мы можем рассмотреть ошибки по группам. Целью этой части анализа ошибок является выявление групп, в которых модель работает плохо. Некоторые знания предметной области могут быть полезны при принятии решения о создании групп. Я бы предложил начать с очевидных групп, которые уже существуют в данных, а затем перейти к созданию групп из интуиции. Например, я мог бы начать с рассмотрения ошибок предсказания по категориальным переменным, а затем перейти к разбивке числовых переменных на корзины для изучения Когда я смотрю на группы, есть несколько конкретных вещей, на которые я всегда обращаю внимание.
За / Под Предсказаниями
Проверьте, есть ли какие-либо конкретные группы, для которых модель переоценивает или недооценивает большую часть времени. Если модель всегда переоценивает определенную группу, это похоже на то, что мы можем научить ее исправить. Также примите к сведению, если группам, которые работают плохо, не хватает данных.
Потенциальные исправления:
- Наказывать за чрезмерные прогнозы для этой группы
- Методы передискретизации при отсутствии данных
- Сбор данных, если данных не хватает
Большие средние ошибки
Проверьте, не вносит ли какая-либо группа вклада в общую ошибку больше, чем все остальные группы. Это важно отметить по нескольким причинам. Во-первых, мы явно хотим знать, что не так, чтобы это можно было исправить. Во-вторых, это важно для интерпретируемостии применение модели. Если модель работает хорошо во всех группах, кроме одной, вы можете просто использовать эту модель для всего, кроме этой группы, если это невозможно исправить.
Потенциальные исправления:
- К-стратифицированная перекрестная проверка для обеспечения групповых наблюдений в каждом расколе
- Методы передискретизации при отсутствии данных
- Сбор данных — это отсутствие данных
Индивидуальные ошибки
Теперь мы приступаем к мельчайшим деталям. Как только мы выполнили весь анализ ошибок более высокого уровня, пришло время погрузиться в ошибки каждого наблюдения. Мне нравится делать это, просматривая 20 лучших ошибок из моих прогнозов. В отличие от анализов более высокого уровня, у меня нет предложений по типичным ошибкам, которые вы можете найти. Вы должны пройти наблюдения и посмотреть на данные и прогноз и определить, был ли прогноз действительным. Иногда модель делала хороший прогноз, и цель этого наблюдения была просто шаткой. Это ошибки, с которыми мы можем жить. Если вы не думаете, что наблюдение кажется разумным, спросите себя, почему. Какую информацию упустила модель, которая должна была помочь ей сделать лучший прогноз? Пройдите несколько наблюдений в поисках закономерностей того, что может быть причиной ошибок. Вы можете найти что-то, что вы пропустили, прежде чем вы могли бы исправить. Вы можете обнаружить, что иногда ваша модель просто портится, и нет никаких причин, чтобы вы могли это увидеть. С этого момента вы либо продолжаете настраивать свою модель, решаете получить больше данных или считаете свою модель хорошей.
Реализуйте это
Анализ ошибок занимает много времени и требует много размышлений. Потратьте время на поиск и изучение причин, по которым ваша модель работает плохо. Шаблон для хорошего анализа ошибок таков:
- Найти ошибки
- Создайте гипотезу о том, что может исправить ошибки
- Проверка гипотезы
- Повторение
Выполнение этих шагов с небольшим творческим потенциалом и терпением поможет вам построить лучшую модель, чем вы могли бы с помощью одной лишь гипер-настройки.
Если у вас есть какие-либо вопросы о том, как сделать эффективный анализ ошибок, оставьте мне комментарий ниже, и я отвечу!
17 авг. 2022 г.
читать 2 мин
Регрессионный анализ — это метод, который мы можем использовать для понимания взаимосвязи между одной или несколькими переменными-предикторами и переменной отклика .
Один из способов оценить, насколько хорошо регрессионная модель соответствует набору данных, — вычислить среднеквадратичную ошибку , которая представляет собой показатель, указывающий нам среднее расстояние между прогнозируемыми значениями из модели и фактическими значениями в наборе данных.
Чем ниже RMSE, тем лучше данная модель может «соответствовать» набору данных.
Формула для нахождения среднеквадратичной ошибки, часто обозначаемая аббревиатурой RMSE , выглядит следующим образом:
СКО = √ Σ(P i – O i ) 2 / n
куда:
- Σ — причудливый символ, означающий «сумма».
- P i — прогнозируемое значение для i -го наблюдения в наборе данных.
- O i — наблюдаемое значение для i -го наблюдения в наборе данных.
- n — размер выборки
В следующем примере показано, как интерпретировать RMSE для данной модели регрессии.
Пример: как интерпретировать RMSE для регрессионной модели
Предположим, мы хотим построить регрессионную модель, которая использует «учебные часы» для прогнозирования «экзаменационного балла» студентов на конкретном вступительном экзамене в колледж.
Мы собираем следующие данные для 15 студентов:
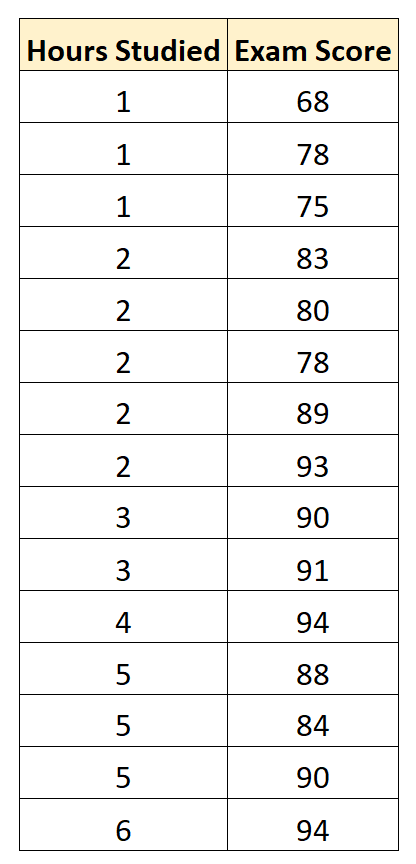
Затем мы используем статистическое программное обеспечение (например, Excel, SPSS, R, Python) и т. д., чтобы найти следующую подогнанную модель регрессии:
Экзаменационный балл = 75,95 + 3,08 * (часы обучения)
Затем мы можем использовать это уравнение, чтобы предсказать экзаменационную оценку каждого студента, исходя из того, сколько часов они учились:
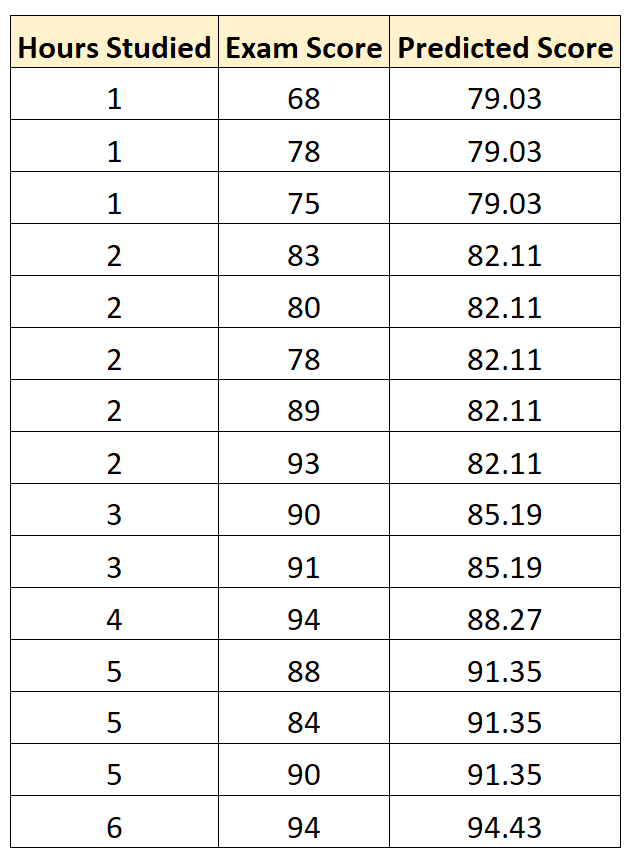
Затем мы можем вычислить квадрат разницы между каждой прогнозируемой оценкой экзамена и фактической оценкой экзамена. Затем мы можем извлечь квадратный корень из среднего значения этих разностей:
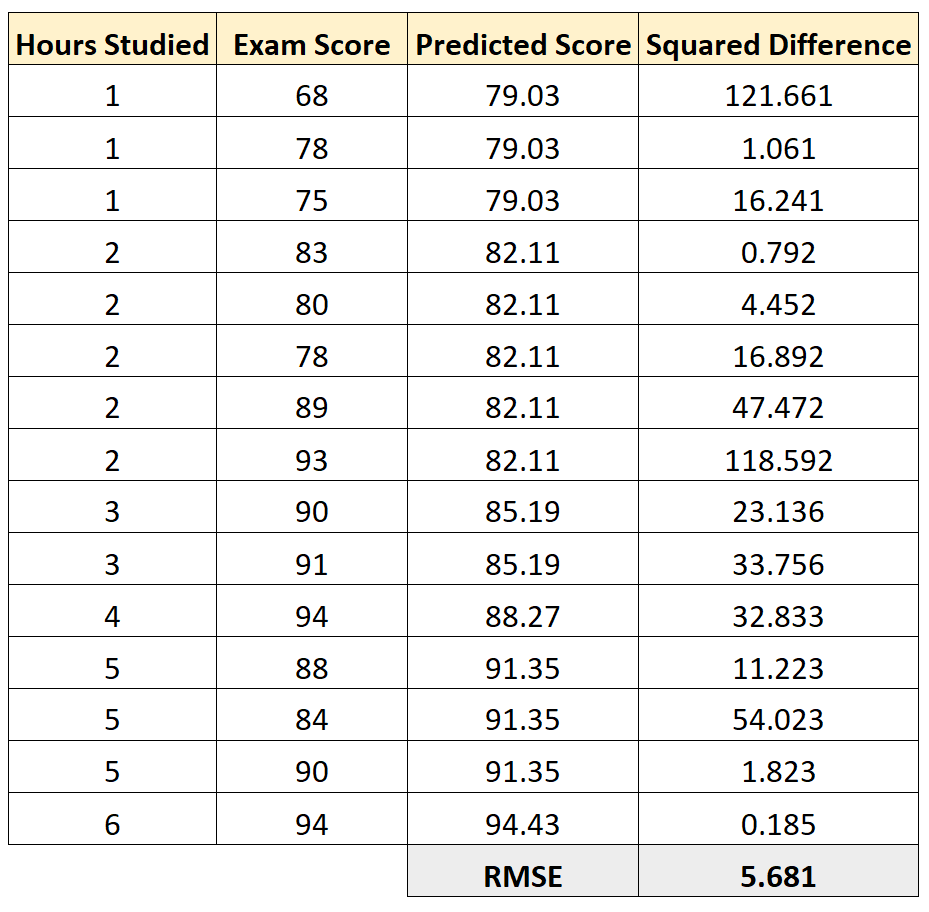
RMSE для этой регрессионной модели оказывается равным 5,681 .
Напомним, что остатки регрессионной модели представляют собой разницу между наблюдаемыми значениями данных и значениями, предсказанными моделью.
Остаток = (P i – O i )
куда
- P i — прогнозируемое значение для i -го наблюдения в наборе данных.
- O i — наблюдаемое значение для i -го наблюдения в наборе данных.
И помните, что RMSE регрессионной модели рассчитывается как:
СКО = √ Σ(P i – O i ) 2 / n
Это означает, что RMSE представляет собой квадратный корень из дисперсии остатков.
Это значение полезно знать, поскольку оно дает нам представление о среднем расстоянии между наблюдаемыми значениями данных и прогнозируемыми значениями данных.
Это отличается от R-квадрата модели, который сообщает нам долю дисперсии переменной отклика, которая может быть объяснена предикторной переменной (переменными) в модели.
Сравнение значений RMSE из разных моделей
RMSE особенно полезен для сравнения соответствия различных моделей регрессии.
Например, предположим, что мы хотим построить регрессионную модель, чтобы предсказать результаты экзаменов студентов, и мы хотим найти наилучшую возможную модель среди нескольких потенциальных моделей.
Предположим, мы подгоняем три разные модели регрессии и находим соответствующие им значения RMSE:
- RMSE модели 1: 14,5
- RMSE модели 2: 16,7
- RMSE модели 3: 9,8
Модель 3 имеет самый низкий RMSE, что говорит нам о том, что она способна лучше всего соответствовать набору данных из трех потенциальных моделей.
Дополнительные ресурсы
Калькулятор среднеквадратичной ошибки
Как рассчитать RMSE в Excel
Как рассчитать RMSE в R
Как рассчитать RMSE в Python