
Целью данной работы является создание программного кода системы. Однако детальных рекомендаций по поводу дисциплины и приемов кодирования дать не представляется возможным ввиду того, что не накладывается практически никаких ограничений на выбранный язык и платформу программирования. Поэтому сосредоточимся на процессах, которые сопутствуют созданию программного кода, являясь при этом не менее важными, а именно – тестировании и отладке. Требуется провести функциональное и нагрузочное тестирование, на основании которого выполнить мероприятия по исправлению найденных дефектов. Всю эту работу нужно отмечать в журнале отслеживания дефектов.
Журнал отслеживания дефектов.
Все найденные дефекты необходимо фиксировать в журнале, содержащем, по меньшей мере, следующие информационные поля:
Уникальный идентификатор дефекта (обязательное поле). Это поле может быть автоматически генерируемым, важно только чтобы в рамках одного журнала серийные номера дефектов не повторялись.
Описание проявления дефекта и способа его воспроизведения, возможно, со снимками экрана (обязательное поле).
Соответствует дефекту №» — указание на родственный дефект, проявлением или частным случаем которого является (обязательное поле). Если поле не заполнено, дефект считается уникальным.
Оценка важности (приоритета) в виде P1(высокий приоритет) — P5 (низкий приоритет) (обязательное поле). Эта оценка дается экспертным образом исходя из следующих соображений: наивысший приоритет получают дефекты, без устранения которых эксплуатация системы является в принципе невозможной, низший – дефекты, которые не являются принципиальными для работы системы, например, недостатки стилевого оформления.
Ответственный за исправление (обязательное поле). Это поле указывает, кто из разработчиков будет заниматься исправлением дефекта.
Ожидаемое время исправления (EFT) (обязательное поле). Это поле выражает ожидаемые трудозатраты исполнителя на исправление дефекта.
Состояние дефекта (обязательное поле): «зарегистрировано», «подтверждено», «не воспроизводится», «назначено», «отклонено исполнителем», «в работе», «исправлено», «не требует исправления», «исправление невозможно», «исправление заявлено», «исправление подтверждено».
Любое описание дефекта проходит определенный путь при исправлении, и этот путь в общем случае можно описать следующим сценарием. Прежде всего, описание дефекта получает статус «зарегистрировано», при котором известны серийный номер дефекта, дата регистрации, описание дефекта и способ его воспроизведения, имя тестировщика, составившего описание. Далее описание выполняется проверка воспроизводимости дефекта. По результатам проверки дефект получает статус «подтверждено» или «не воспроизводится». Возможен также вариант дублирующихся описаний дефектов, когда разные тестировщики обнаруживают проявление одной и той же ошибки. В этом случае заполняется поле «Соответствует дефекту №»
Подтвержденные уникальные дефекты получают рейтинг важности и назначаются исполнителям на исправление, при этом становятся известны имена исполнителей и ожидаемое время исправления. Назначенные исполнителям дефекты могут быть отклонены (в этом случае устанавливается статус «отклонено исполнителем») либо приняты к работе. Отклоненные дефекты назначаются повторно – другим исполнителям, либо получают статус «исправление невозможно»,если это явно следует из описания причины отклонения.
Исправленные дефекты получают статус «исправление заявлено» и ожидают проверки, дефекты, не требующие исправления, получают одноименный статус. После перекрестной проверки заявленных исправлений дефекты получают статус «исправление подтверждено» или «назначено», в зависимости от результатов.
В результате деятельности по исправлению в регистрационном журнале могут остаться только дефекты с конечными статусами «дефект не воспроизводится», «исправление подтверждено», «исправление невозможно». При этом не должно быть ни одной записи «исправление невозможно» с приоритетом выше P3.
Обязанности членов группы в процессе тестирования распределяются перекрестно: поиск ошибок в текстовых материалах документации выполняют совместно менеджер проекта и программист, программные ошибки и несоответствие реализации дизайна его макету – менеджер и технический редактор. Исполнители назначаются в соответствии с областью, которую адресует ошибка: программист исправляет код, редактор – тексты описаний. Назначения исполнителей и подтверждения исправленных ошибок выполняет менеджер.

Фактическим результатом лабораторной работы будет являться отлаженный программный код, исправленная документация и заполненный журнал отслеживания дефектов. Пример журнала отслеживания дефектов приведен в приложении Е.
Литература
1. Канер, Фолк, Нгуен, Тестирование программного обеспечения. (Перевод с английского) (2000, издательство ДиаСофт, ISBN 966-7393-87-9)
2. Бахтизин В. В., Глухова Л. А. Стандартизация и сертификация программного обеспечения: Учеб. пособие/ В. В. Бахтизин, Л. А. Глухова — Мн.: БГУИР, 2006. — 200с.:ил.
3. Роберт Калбертсон, Крис Браун, Гэри Кобб. Быстрое тестирование: Издательский дом «Вильямс» /Серия института качества программного обеспечения — 374с.:ил.
4. Синицын С. В., Налютин Н. Ю. Верификация программного обеспечения. М.:БИНОМ, 2008, 368c. ISBN 978-5-94774-825-3
5. Интернет-ресурс http://www.intuit.ru/department/se/testing/
При разработке
кодов применяются разные системы и
методы кодирования (их построение).
Под
системой
кодирования
понимается совокупность правил,
определяющих порядок обозначения
объектов классификации знаками, с
помощью которых обеспечивается
представление, передача, обработка и
хранение информации.
Порядковая
— порядковая нумерация всех позиций
номенклатуры, без пропуска свободных
номеров.
Серийная
— закрепление серий номеров по группам
позиций, обладающих общим признаком,
могут предусматриваться резервные
номера.
Десятичная
(позиционная) — каждый разряд кода (или
несколько разрядов) закрепляются за
определенным признаком. Вся номенклатура
кодов классифицируется сначала по
признаку, а уже внутри этого старшего
признака выделяются младшие по значению
признаки.
Смешанная
— здесь используется несколько систем
при кодировании. Применяется при
кодировании сложных многозначных
номенклатур (например: балансовый счет,
субсчет).
Комбинированная
— объединение в одном коде нескольких
признаков.
Для
построения классификатора применяются
иерархический
и фасетный
методы. Иерархический метод классификации
строится на основе последовательных
многоуровневых отношений между объектами
классификации. При этом каждый объект
может попасть только в одну классификационную
группу. Этот метод удобен для выделения
функционально подчиненных объектов.
Фасетный метод
классификации предусматривает деление
объектов кодирования одновременно по
нескольким классификационным признакам.
Каждый объект при этом может быть отнесен
к различным независимым классификационным
группам. Внутри этих групп признаки
могут иметь иерархическую структуру.
Стадии преобразования экономической информации
-
Сбор
и регистрация информации.
На
предприятии сбор и регистрация информации
происходит при выполнении различных
хозяйственных операций (прием готовой
продукции, получение и отпуск материалов,
…), в банках – при совершении
финансово-кредитных операций с
юридическими и физическими лицами. В
процессе сбора фактической информации
производится измерение, подсчет,
взвешивание материальных объектов,
подсчет денежных купюр, получение
временных и количественных характеристик
работы отдельных исполнителей. Сбор
информации регистрируется на материальном
носителе (документе, машинном
носителе).Запись в первичные документы
в основном осуществляется вручную,
поэтому процедуры сбора и регистрации
остаются наиболее трудоемкими и требуют
автоматизации.
Технические
средства:
-
персональные
компьютеры для ввода информации
документов и запись на машинный носитель; -
сканеры для
автоматического считывания информации
документов в виде графических символов,
распознавания графических образов и
преобразования в текст; -
считыватели
пластиковых карточек;
-
Передача
информации.
Передача информации
осуществляется различными способами:
с помощью курьера, пересылкой по почте,
доставкой транспортными средствами,
дистанционной передачей по каналам
связи и т. Дистанционная передача данных
сокращает время их движения, но удорожает
процесс. Но этот вид постоянно развивается
и совершенствуется и является наиболее
перспективным.
Комплекс
средств передачи информации:
-
локальные
вычислительные сети; -
региональные
вычислительные сети расширенного
масштаба; -
глобальные
вычислительные сети (Интернет);
Технические
средства:
модемы, факс-модемы, сетевой коммуникационное
оборудование.
-
Хранение
и накопление информации.
Хранении и накопление
информации предназначено для многократного
ее использования. Информация хранится
и накапливается в информационных базах,
на магнитных носителях в виде информационных
массивов, где данные располагаются в
определенном порядке.
Технические
средства:
Базы данных
хранятся на серверах БД, локальных
компьютерах.
В
качестве носителей информации
используются: магнитные диски, оптические
диски(лазерные), диски DVD
(цифровые видеодиски), флеш-память.
-
Обработка
информации.
Обработка информации
производится на компьютере, как правило,
децентрализовано, в местах возникновения
первичной информации, где организуются
автоматизированные рабочие места (АРМ)
специалистов или иной управленческой
службы. Обработка может проводиться не
только автономно, но и в компьютерных
вычислительных сетях.
Технические
средства:
Обработка
информации в ИС выполняется с помощью
компьютеров, которые делятся на классы:
-
микрокомпьютеры
– используются автономно в виде ПК,
либо в сети в качестве рабочих станций,
оснащенные современными микропроцессорами
(Intel?
AMD
и др.), имеют различную архитектуру
(ряд IBM
PC?
Macintosh
и др.). В эту группу входят портативные
компьютеры. -
Мини-компьютеры
– машины среднего уровня по
производительности и серверным
возможностям.
-
Формирование
результатной информации.
В ходе решения
задач на компьютере формируются
результатные документы, сводки, которые
печатаются или представляются в
электронном виде и предоставляются
пользователям.
Технические
средства:
для отображения
информации на экране используются
видеомониторы;
для вывода информации
используются принтеры, графопостроители.
Методы
доступа к БД. Системы управления базами
данных. Понятие данных и баз данных.
Структура файла БД, ее описание.
Данные,
по определению Уэбстера, есть «некоторый
факт; то, на чем основан вывод или любая
интеллектуальная система». Первичными
компонентами данных (т.е. самые маленькие
неделимые структурные единицы данных)
являются цифры, буквы и символы
естественного языка или их кодированное
представление в виде строки двоичных
билетов. Наименьшей семантически
значимой поименной единицей данных
является элемент данных. Совокупность
взаимосвязанных элементов данных
(полей), рассматриваемая в прикладной
программе как целое, называется логической
записью, а набор записей одного типа,
но разных по содержанию — файлом. Запись
данных определяется характером
выполняемой задачи. Например, в качестве
записи можно рассматривать данные
документа, отражающем информацию о
движении, объектов основных средств.
Совокупность таких записей образует
файл (или массив) данных. В теории и
практике автоматизированных информационных
систем понятие массива отождествляется
с понятием файла. Массив (файл) представляет
собой поименованную совокупность
данных, объединенных по некоторому
смысловому признаку или по нескольким
признакам, однотипным по структуре и
методу доступа. Хранение файлов может
быть организовано в дисковой памяти
ЭВМ.
Таким
образом, понятие базы данных может быть
сформулировано так: это совокупность
массивов (файлов) данных предназначенных
для обработки на ЭВМ, которая служит
для удовлетворения нужд многих
пользователей в рамках одного или
нескольких предприятий и организаций.
Информация хранится явным образом в
базе данных и может включать различные
типы логических записей. База данных
ориентирована на интегрированные
требования, а не на одну программу,
способную обработать несколько частных
файлов, каждый со своим собственным
форматом.
Например:
Программа Суперкалк обрабатывает данные
(таблицы) с расширением .cal;
программа EXEL
– с.xls;
ППП Clipper
— .dbf.
Чтобы
выполнить запрос на нужную информацию,
в этом случае необходимо написать
прикладную программу способную обработать
несколько частных файлов, каждый со
своим собственным форматом.
СУБД
Для
создания внутримашинного информационного
обеспечения (БД) используются СУБД –
системы управления и манипулирования
данными в базе данных (БД).
База
данных (БД) – это поименованная
совокупность специальным образом
организованных наборов данных, хранящихся
на диске.
Управление
БД включает в себя ввод данных, их
корректировку и манипулирование данными,
т.е. добавления, извлечения, обновления.
Развитые
СУБД обеспечивают независимость
прикладных программ, работающих с ними,
от конкретной организации информации
в базах данных. В зависимости от способа
организации данных различают: сетевые,
иерархические, распределенные, реляционные
СУБД.
Из
имеющихся СУБД наибольшее распространение
получили СУБД DBase
III,
Dbase
IV,
СУБД «Rebus»,
FOXPRO,
Microsoft
ACCESS,
Paradox,
а также СУБД компании Oracle
Informix,
Sybase,
Progress.
Интеграция различных
компонентов в единую систему предоставляет
пользователю неоспоримые преимущества
в интерфейсе, но неизбежно проигрывает
в части повышенных требований к
оперативной памяти.
Из имеющихся пакетов
можно выделить следующие:
Frame work, Microsoft Offic
Другой
концепцией организации БД является
концепция администратора
базы данных (АБД).
Под этим понятием подразумевается лицо
(или группа лиц, или целое штатное
подразделение), на которое возложено
управление средствами базы данных
предприятия. АБД должен быть энергичной
и способной личностью, организатором
по призванию, желательно с техническим
образованием. Он должен уметь поддерживать
взаимосвязи как с руководством высшего
уровня, так и с пользователями базы
данных, а также руководить штатом
технических специалистов.
Этот
штат должен включать лиц, имеющих опыт
работы в таких областях, как программное
обеспечение СУБД, операционные системы,
техническое обеспечение ЭВМ, прикладное
программирование, системное
программирование. Важно, чтобы в этот
штат были включены лица, имеющие полное
представление о работе предприятия и
его информационных потребностях.
Персонал
АБД должен уметь поддерживать хорошие
отношения с другими группами специалистов,
не входящих в отдел обработки данных. Место
АБД было определено тогда, когда
руководители предприятий осознали
необходимость централизованного
управления ресурсами БД, обработкой
данных и другими аспектами, связанными
с БД. АБД
является ответственным за анализ
потребностей пользователей, проектирование
БД, её внедрение, обновление, если
необходимо, — реорганизацию БД, а также
– за консультацию и обучение пользователей.
Структура
файла БД, ее описание.
Каждый
справочник в базе данных имеет свой
идентификатор (имя файла БД). В качестве
образца справочника предложен «Справочник
постоянных удержаний из заработной
платы»,
его идентификатор Zrp_Uder.dbf,
где ZRP_Uder
— имя (условное обозначение) справочного
массива, .dbf
— расширение файла базы данных (расширение
.dbf
соответствует всем исходным файлам
базы данных).
Файлы
отчетов (результатные файлы) имеют
расширение .frm
В таблице 1
приведен а структура справочника системы
ПРОНАР.
Структура
справочника постоянных удержаний из
заработной платы Zrp_Uder.dbf
_______________________________________________________________________Таблица1____
№ Наименование
Условное обоз Тип Длина Точ-
Назначение
п.п
показателя начение поля
ность показателя
__________________________________________________________________________
справочник
постоянных удержаний из зарплаты
работника может быть
следующей
структуры:
1.
Квартплата KV_PLATA
число 6 2 сумма
квартпл.
2.
В сбербанк BANK_SUM
число 6 2 сумма
отчислен.
в
сбербанк
3.
Ссуда SSUDA
_MAX
число 6 2 сумма выданной
работнику
ссуды
4.
Ссуда ежемесяч. SSUDA_SUM
число 6 2 сумма
ежемесяч.
отчислений
по
ссуде
из з.пл.
____________________________________________________________________________
Пример:
«Справочник постоянных удержаний
из ЗРП» используется
при начислении удержаний из заработной
платы работников предприятия.
Данные
в справочник закладываются один раз
на определенный длительный период.
Например, выданная работнику ссуда
вводится в поле SSUDA,
а сумма ежемесячных отчислений по
ссуде в поле SSUDA_SUM
— эта сумма
в
дальнейшем отражается в
«Расчетно-платежной ведомости»
и «Расчетном
листке» в
графе «Ссуда»,
используется
для контроля
отчислений в сбербанк, по ссуде и
квартплате из начисленной суммы ЗРП
работнику. По мере ежемесячных
отчислений по ссуде при начислении
удержаний из ЗРП работника, значение
поля SSUDA
контролируется программой, чтобы не
была превышена выданная работнику
сумма ссуды. Аналогично дать описание
остальным значениям полей данного
справочника.
Образец
заполнения справочника удержаний:
На
каждого работника предприятия в базе
данных «Лицевые
счета» бухгалтер
по мере необходимости вводит данные
о постоянных ежемесячных удержаниях
из ЗРП в
соответствующий справочник, который
выглядит так:
Таблица
2
_____________Справочник
постоянных удержаний_____________
Работник
Иванов
И.И. Таб.№ 153 Должность — бухгалтер
Ежемесячные
Сумма max
отчисления
Квартплата
120.00
В
сбербанк
300.00
Ссуда
250.00
5000.00
____________________________________________________________________
Способы
размещения информации в ПД.
Существуют три
основные формы размещения реквизитов
и показателей в документе: линейная ,
анкетная и табличная.
При линейной форме
размещения реквизиты располагаются
построчно один за другим. Для каждого
реквизита предусматривается место для
записи его наименования (сверху) и
значения (снизу).
При анкетной форме
размещения реквизиты располагаются
друг за другом в вертикальной
последовательности сверху вниз. Каждая
строка документа отводится для одного
реквизита (показателя). Слева размещается
наименование реквизита, справа – его
значение.
При табличной форме
реквизиты располагаются в виде таблицы
в соответствующих строко-графах. По
одному и тому же реквизиту может быть
записано несколько значений.
При установлении
расположения реквизитов и показателей
в документе следует учитывать их
назначение в процессе обработки данных
документа. Любой документ условно
делится на три зоны: Зона общих признаков,
Содержательная зона, Зона подписей.
Зона общих признаков
содержит постоянные, справочные и
группировочные реквизиты и показатели,
характерные для всего документа в целом
(Наименование предприятия, Наименование
и код структурного подразделения,
Наименование документа, Дата выписки
документа).
Содержательная
зона содержит постоянные, справочные,
группировочные и переменные реквизиты
и показатели, характерные для каждой
документостроки (Наименование материала,
Фамилия, имя и отчество работника,
Табельный номер работника, Корреспондируемый
счет, цена, количество, оклад, сумма).
Зона подписей
предусматривает строки для подписей
руководящих и ответственных лиц,
придающих документу юридическую силу.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Курсовая работа
Тестирование информационных систем
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
ГЛАВА 1. ОСНОВЫ ТЕСТИРОВАНИЯ ИНФОРМАЦИОННЫХ СИСТЕМ
1.1. Понятие «тестирования информационных систем»
1.2. Критерии тестирования
1.3. Принципы тестирования
ГЛАВА 2. МЕТОДЫ ТЕСТИРОВАНИЯ
2.1. Тестирование «белого ящика»
2.2. Тестирование «черного ящика»
ГЛАВА 3. ТЕСТИРОВАНИЕ ИНФОРМАЦИОННОЙ СИСТЕМЫ «УЧЕБНО-МЕТОДИЧЕСКИЙ РЕСУРС»
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ПРИЛОЖЕНИЕ. ПРИМЕНЕНИЕ СТАНДАРТА IEEE STD 829 ПРИ ПЛАНИРОВАНИИ И ВЫПОЛНЕНИИ ФУНКЦИОНАЛЬНОГО И НАГРУЗОЧНОГО ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
ВВЕДЕНИЕ
Известно, что основной задачей первых трех десятилетий компьютерной эры являлось развитие аппаратных компьютерных средств. Это было обусловлено высокой стоимостью обработки и хранения данных. В 80-е годы успехи микроэлектроники привели к резкому увеличению производительности компьютера при значительном снижении стоимости.
Основной задачей 90-х годов XX и начала XXI века стало совершенствование качества компьютерных приложений, возможности которых целиком определяются программным обеспечением (ПО).
Современный персональный компьютер имеет производительность большой ЭВМ 80-х годов. Сняты практически все аппаратные ограничения на решение задач. Оставшиеся ограничения приходятся на долю ПО.
Чрезвычайно актуальными стали следующие проблемы:
· аппаратная сложность опережает наше умение строить ПО, использующие потенциальные возможности аппаратуры;
· наше умение строить программы отстает от требований к новым программам;
· нашим возможностям эксплуатировать существующие программы угрожает низкое качество их разработки.
Достаточно много материалов посвящено тому, как создаются информационные системы и реализуются проекты по разработке программного обеспечения. Авторы могут придерживаться различных методологий разработки, спорить о преимуществах того или иного подхода а планировании процессов или документировании процедур, а также гибкости последних, однако общая схема создания информационных систем достаточно проста и состоит как правило из одних и тех же модулей и процессов:
· управление проектом в виде координации усилий проектной команды, направленных на достижение целей проекта оптимальным путем;
· постановка задачи в виде определения требований и последующих работ с ними;
· управление изменениями в проекте: изменение может касаться как непосредственно самих требований к системе, так и затрагивать организационную схему процесса, и могут порождаться либо самим Заказчиком (бизнес-аналитиком) либо являться следствием обнаруженных в ИС дефектов;
· разработка ПО, как непосредственное кодирование программной реализации функциональных требований и проектирование схем хранения и движения информации в ИС;
· тестирование ПО – процесс, решающий задачу верификации соответствия требований выдвинутых к ИС и их программной реализации;
· эксплуатация ПО как сумма задач, направленная на обеспечение технической и технологической поддержки процесса работы ИС, включая поддержку и необходимое системное администрирование.
Как видим, процесс разработки ИС состоит из нескольких взаимосвязанных модулей, которыми уже в свою очередь и оперируют авторы методологий и подходов, смещая приоритеты между направлениями или смешивая задачи нескольких направлений (предлагая, к примеру, осуществление задач тестирования в рамках деятельности по непосредственной разработке программной реализации и т.д.). Суть остается прежней – есть технологическая цепочка процессов разработки информационных систем, модули которого взаимозависимы и не могут функционировать в отрыве друг от друга.
Цель курсовой работы — рассмотреть подробно процесс тестирования как составляющую процесса обеспечения качества разработки ПО, а также теоретически обосновать основные положения данного процесса и проверить их практически на основе разработанной информационной системы «Учебно-методический ресурс».
В соответствии с целью были поставлены следующие задачи:
1. проанализировать литературу по теме курсовой работы;
2. рассмотреть и изучить понятие «тестирование программного обеспечения»;
3. выделить виды тестирования программного обеспечения;
4. изучить основные принципы и критерии, предъявляемые к тестированию программного обеспечения;
5. изучить основные методы тестирования программного обеспечения;
6. протестировать на основе изученного материала информационную систему «Учебно-методический ресурс».
Структура курсовой работы: работа состоит из введения, трех глав, заключения, списка литературы и одного приложения.
Первая глава посвящена изучению такого понятия, как «тестирование программного обеспечения».
Вторая глава посвящена изучению методов тестирования, таких как метод «белого ящика» и метод «черного ящика».
В третьей главе рассматривается процесс тестирования фрагмента информационной системы «Учебно-методический ресурс».
1.1. Понятие «тестирования информационных систем».
Качество программного продукта характеризуется набором свойств, определяющих, насколько продукт «хорош» с точки зрения заинтересованных сторон, таких как заказчик продукта, спонсор, конечный пользователь, разработчики и тестировщики продукта, инженеры поддержки, сотрудники отделов маркетинга, обучения и продаж. Каждый из участников может иметь различное представление о продукте и том, насколько он хорош или плох, то есть о том, насколько высоко качество продукта. Таким образом, постановка задачи обеспечения качества продукта выливается в задачу определения заинтересованных лиц, их критериев качества и затем нахождения оптимального решения, удовлетворяющего этим критериям. Тестирование является одним из наиболее устоявшихся способов обеспечения качества разработки программного обеспечения и входит в набор эффективных средств современной системы обеспечения качества программного продукта.
С технической точки зрения тестирование заключается в выполнении приложения на некотором множестве исходных данных м сверке получаемых результатов с заранее известными (эталонными) с целью установить соответствие различных свойств и характеристик приложения заказанным свойствам.
Программа – это аналог обычной формулы в математике.
Формула для функции f, полученной суперпозицией f1, f2, … fn – выражение, описывающее эту суперпозицию.
f=f1*f2*f3*…*fn
Если аналог f1, f2, … fn — операторы языка программирования, то их формула – программа.
Существует два метода обоснования истинности формул:
· Формальный подход или доказательство применяется, когда из исходных формул-аксиом с помощью формальных процедур (правил вывода) выводятся искомые формулы и утверждения (теоремы). Вывод осуществляется путем перехода от одних формул к другим по строгим правилам, которые позволяют свести процедуру перехода от формулы к формуле к последовательности текстовых подстановок. Преимущество формального подхода заключается в том, что с его помощью удается избегать обращений к бесконечной области значений и на каждом шаге доказательства оперировать только конечным множеством символов.
· Интерпретационный подход применяется, когда осуществляется подстановка констант в формулы, а затем интерпретация формул, как осмысленных утверждений в элементах множеств конкретных значений. Истинность интерпретируемых формул проверяется на конечных множествах возможных значений. Сложность подхода состоит в том, что на конечных множествах комбинации возможных значений для реализации исчерпывающей проверки могут оказаться достаточно велики.
Интерпретационный подход используется при экспериментальной проверке соответствия программы своей спецификации.
Применение интерпретационного подхода в форме экспериментов над исполняемой программой составляет суть отладки и тестирования.
Отладка(debug, debugging) – процесс поиска, локализации и исправления ошибок в программе. [6, c. 215]
Термин «отладка» в отечественной литературе используется двояко: для обозначения активности по поиску ошибок (собственно тестирование), по нахождению причин их появления и исправлению, или активности по локализации и исправлению ошибок.
Тестирование – это процесс выполнения ПО системы или компонента в условиях анализа или записи получаемых результатов с целью проверки (оценки) некоторых свойств тестируемого объекта. [11, c. 5]
Тестирование – это процесс анализа пункта требований к ПО с целью фиксации различий между существующим состоянием ПО и требуемым (что свидетельствует о проявлении ошибки) при экспериментальной проверке соответствующего пункта требований. [2, с. 13]
Тестирование – это контролируемое выполнение программы на конечном множестве тестовых данных и анализ результатов этого выполнения для поиска ошибок. [7, c. 27]
Порой термины «тестирование» и «отладка» используют взаимозаменяемо, но внимательные программисты различают два этих процесса. Тестирование – это средство обнаружения ошибок, тогда как отладка является средством поиска и устранения причин уже обнаруженных ошибок.
Шаги процесса задаются тестами.
Каждый тест определяет:
· Свой набор исходных данных и условий для запуска программы.
· Набор ожидаемых результатов работы программы.
Другое название теста – тестовый вариант. Полную проверку программы гарантирует исчерпывающее тестирование. Оно требует проверить все наборы исходных данных, все варианты их обработки и включает большое количество тестовых вариантов. В большинстве случаев исчерпывающее тестирование невозможно, прежде всего, из-за ограничения по времени.
^
На этапе кодирования программист пишет программы и сам их тестирует. Технология тестирования на этом этапе называется тестированием «стеклянного ящика» (glass box). Иногда ее называют тестированием «белого ящика» (white box) в противоположность классическому понятию «черного ящика» (black box).
При тестировании «черного ящика» программа рассматривается как объект, внутренняя структура которого неизвестна.
Тестировщик вводит данные и анализирует результат, но организация процесса обработки данных программой ему неизвестна. Подбирая тесты, специалист ищет интересные с его точки зрения входные данные и условия, которые могут привести к нестандартным результатам. Интересны для него, прежде всего, те представители каждого класса входных данных, на которых с наибольшей вероятностью могут проявиться ошибки тестируемой программы.
При тестировании «стеклянного ящика» ситуация совершенно иная. Тестировщик (как правило, это программист) разрабатывает тесты, основываясь на знании исходного кода, к которому он имеет полный доступ. В результате он получает следующие преимущества:
• направленность тестирования. Программист может тестировать программу по частям, разработать специальные тестовые подпрограммки, которые вызывают тестируемый модуль и передают ему интересующие программиста данные. Отдельный модуль легче протестировать именно как «стеклянный ящик»;
• полный охват кода. Программист всегда может определить, какие именно фрагменты кода работают в каждом тесте. Он видит, какие еще ветви кода остались непротестированными и может подобрать условия, в которых они будут выполнены;
•управление потоком. Программист всегда знает, какая функция должна выполняться в программе следующей и каким должно быть ее текущее состояние. Чтобы выяснить, работает ли программа так, как он думает, программист может включить в нее отладочные команды, отображающие информацию о ходе ее выполнения, или воспользоваться для этого специальным программным средством, называемым отладчиком. Отладчик может делать очень много полезных вещей: отслеживать и менять последовательность выполнения команд программы, показывать содержимое ее переменных и их адреса в памяти и др.;
• отслеживание целостности данных. Программисту известно, какая часть программы должна изменять каждый элемент данных. Отслеживая состояние данных с помощью того же отладчика, он может выявить такие ошибки, как изменение данных не теми модулями, их неверная интерпретация или неудачная организация. Программист может и самостоятельно автоматизировать тестирование;
• использование внутренних граничных точек. В исходном коде видны те граничные точки программы, которые скрыты от взгляда «извне». Например, для выполнения определенного действия может быть использовано несколько совершенно различных алгоритмов, и, не заглянув в код, невозможно определить, какой из них выбрал программист. Еще одним типичным примером может быть проблема переполнения буфера, используемого для временного хранения входных данных. Программист сразу может сказать, при каком количестве данных буфер переполнится, и ему не нужно при этом проводить тысячи тестов;
• тестирование, определяемое выбранным алгоритмом. Для тестирования обработки данных, использующей очень сложные вычислительные алгоритмы, могут понадобиться специальные технологии. В качестве классических примеров можно привести преобразование матрицы и сортировку данных. Тестировщику нужно точно знать, какие алгоритмы используются, и в необходимых случаях использовать специальную литературу.
В данном случае тестирование «стеклянного ящика» рассматривается как часть процесса программирования. Программисты выполняют эту работу постоянно, они тестируют каждый модуль после его написания, а затем еще раз после интеграции его в систему. Этому их учат еще в учебных заведениях. В большинстве учебников по тестированию именно этому его виду отводится основная роль.
^
Основной работой тестировщиков является регрессионное тестирование. у этого термина два значения, объединенных идеей повторного использования разработанных тестов. Предположим, что был проведен тест, в результате которого обнаружили ошибку, и программист ее исправил. После чего снова проводится тот же тест, чтобы убедиться, что ошибки больше нет. Это и есть регрессионное тестирование. Можно просмотреть несколько вариаций исходного теста, чтобы полностью проверить исправленный фрагмент программы. В данном случае задача регрессионного тестирования состоит в том, чтобы убедиться, что выявленная ошибка полностью исправлена программистом и больше не проявляется.
В некоторых коллективах в набор регрессионных тестов включают каждую найденную ошибку, даже если она была исправлена ранее. Каждый раз, когда в программу вносится изменение, все тесты проводятся снова. Особенно важно провести такое обстоятельное тестирование, если программа изменяется спустя достаточно длительное время или изменения вносятся другим программистом. Исправления очень чувствительны к таким изменениям, поскольку в тексте программы, если только они не задокументированы самым тщательным образом, выглядят как непонятные или неудачные фрагменты.
Второй пример применения регрессионного тестирования. После выявления и и
справления ошибки проводится стандартная серия тестов, но уже с другой целью — убедиться в том, что, исправляя одну часть программы, программист не испортил другую. В этом случае тестируется целостность всей программы, а не исправление одной ошибки.
Существует метод инкрементального тестирования, основанный на регрессионных тестах с использованием разработанных заглушек и оболочек.
^
5.4.1 Полный цикл тестирования разработанного программного продукта
Когда кодирование завершено, программа передается группе тестирования. Тестировщик ищет ошибки, составляет о них отчеты, затем получает новую версию программы и снова ищет ошибки. При этом находятся старые ошибки, не замеченные на первом этапе, и новые, появившиеся после доработки. В [15] подытожены данные об эффективности исправления найденных ошибок.
Если для исправления ошибки нужно изменить не более десяти операторов, вероятность того, что это будет сделано правильно с первого раза, составляет 50 %. Если для исправления ошибки нужно изменить около пятидесяти операторов, вероятность того, что это будет сделано правильно с первого раза, составляет 20 %.
Проблема состоит не только в том, что программист может не исправить ошибку до конца, а в большей степени в том, что исправления могут иметь побочные эффекты. Исправление одной ошибки может привести к появлению другой. Случается, что одна ошибка скрывает другую, которая проявляется только после ее устранения. К сожалению, программисты часто концентрируются только на поставленной перед ними проблеме и, решив ее, считают свою работу сделанной. Регрессионного тестирования, пусть даже самого поверхностного, они не выполняют.
Учитывая все сказанное, можно прийти к выводу, что тестировать одну и ту же программу приходится несколько раз. На ранних стадиях тестирования исправленные версии программы могут поступать каждые несколько часов или дней. Поэтому среди специалистов распространена практика не принимать новую версию, пока не будет самым тщательным образом протестирована предыдущая. Такое полное тестирование очередной версии с составлением итогового отчета обо всех известных проблемах и всех найденных в этой версии ошибках называют полным циклом.
Руководители проектов часто рассчитывают ограничиться двумя циклами тестирования: в первом выявить все ошибки, а во втором убедиться, что все они исправлены. Реально для тестирования может понадобиться порядка восьми циклов, а если на каждом из них тестировать программу менее тщательно — тогда от 20 до 30.
^
В этом разделе описывается стандартная последовательность событий, свойственная тестированию информационной системы как «черного ящика».
1. Планирование
Как и всякая работа, тестирование программного продукта начинается с планирования: определяется стратегия, разрабатываются серии тестов, распределяются между сотрудниками задания. Начинать планирование можно сразу после того, как команда проектировщиков выработает требования к программному продукту. Однако чаще подробное планирование начинается на первом цикле тестирования, когда к тестированию предоставляется готовый программный продукт.
2. Приемочное тестирование
При поступлении каждой новой версии информационной системы тестировщики, прежде всего, проверяют, достаточно ли она стабильна. Если система некорректно работает или даже «зависает» при проведении простейших тестов, следует прекратить тестирование и вернуть систему на доработку. Такое первое беглое тестирование называют приемочным или квалификационным.
Если приемочные тесты будут стандартизированы, их копии могут быть переданы программистам, чтобы те проводили их сами и не сдавали «сырые» программы на тестирование. Это позволит избежать возвратов тестировщиками неработающих программ, т.е. моментов, психологически неприятных для обеих сторон.
Приемочные тесты должны быть короткими. В них должны проверяться только основные функции и основные данные.
Во многих компаниях приемочные тесты частично автоматизированы с помощью специального программного обеспечения, выполняющего тестирование «черного ящика».
3. Проверка стабильности системы
Тестировщик должен оценить стабильность программы и количество циклов тестирования для составления календарного плана работ, оценить стоимость услуг по ее тестированию сторонним агентством или оценить качество программного продукта, который компания собирается купить и распространять.
В этом случае задача специалиста по тестированию состоит не в поиске ошибок, а в определении самых ненадежных частей программы. При этом начинать следует с изучения прилагаемого к программе руководства. В нем должны быть описаны все функции программы и приведены простые и наглядные примеры. Кроме того, необходимо провести еще несколько тестов, на которых, по мнению тестировщика, программа должна сбоить. В конце такого оценочного тестирования должно сложиться определенное представление о работоспособности системы и трудоемкости ее тестирования: сколько в программе ошибок и насколько тяжело будет ее протестировать. К сожалению, на данный момент отсутствует механизм транслирования этого представления в человеко-часы. Тестировщику придется полагаться только на собственный опыт и профессиональный навык.
Обычно предварительная оценка стабильности программы занимает около недели. Если для тестирования всех ее функций этого времени недостаточно, необходимо проверить часть из них. При этом необходимо обязательно включить в отчет обзор каждого раздела руководства.
Таким образом, реально оценивая трудоемкость тестирования, можно прийти к выводу, что не стоит рассчитывать на то, что разобраться с системой удастся, например, за неделю, если только она не элементарна и если это не очередная версия продукта, который был уже несколько раз протестирован.
^
Производительность является одной из важнейших характеристик современных информационных систем. Тестирование производительности, с одной стороны, позволяет найти узкие места и неоптимальные решения в системе и предложить методы их исправления. С другой стороны, тестирование производительности приложений на различных аппаратных комплексах может помочь заказчику подобрать необходимое оборудование, обеспечивающее требуемые показатели эффективности работы системы в целом.
При тестировании производительности системы применяются следующие тесты [21]:
• собственно тестирование производительности — применение тестов, использующих постоянный объем нагрузки, на различные конфигурации системы и программного окружения, для определения приемлемости производительности тестируемой системы и ее настройки (или оптимизации). Измерению подлежит количество транзакций в минуту, число пользователей, размер используемой базы данных и т.п.;
• сравнительное тестирование — применение тестов, использующих стандартные, рекомендованные нагрузки для измерения производительности системы и ее сравнения с рекомендованной производительностью системы (или измерениями);
• нагрузочное тестирование — проверка и определение приемлемости действующих пределов системы при различных объемах нагрузки, при этом сама тестируемая система остается постоянной. Измеряются характеристики объема нагрузки и времени ответа;
• анализ распределения и балансировки нагрузки. Если системы содержат распределенную архитектуру или балансировку нагрузок, проводятся специальные тесты для проверки методов функций распределения и балансировки нагрузок;
• тестирование конфликтов — проверка возможности системы корректно обрабатывать многочисленные запросы пользователей к одному ресурсу (записи данных, память и т.п.);
• тестирование объемов — проверка и анализ возможностей системы оперировать большими объемами данных. Проверяется как работа с большими объемами данных на входевыходе системы, так и работа с внутренними данными системы;
• стрессовое тестирование — проверка работы функций системы с некорректными параметрами. Стрессовое состояние системы может включать экстремальные нагрузки, дефицит памяти, отсутствие сервисов или аппаратного обеспечения, сжатые общие ресурсы;
• тестирование на расширяемость — измерение и анализ скорости выполнения различных операций продукта на множестве конфигураций программного и аппаратного обеспечения и систем управления базами данных.
^
Программный продукт должен пройти ряд завершающих тестов, после того как он готов и протестирован. Прежде всего, он должен быть еще раз сверен с наиболее подробными и близкими к нему проектными документами. В частности, должно быть проведено функциональное тестирование, при котором продукт сверяется с внешней спецификацией.
Затем программа сверяется с опубликованной печатной документацией: сверка с пользовательскими требованиями — тестирование целостности; сверка с системными требованиями — системное тестирование. Эти две процедуры представляют собой так называемое аттестационное тестирование.
Бета-тестирование
Бета-тестирование представляет собой обратную связь с пользователями, которая осуществляется после подтверждения тестировщиком стабильности программы и наличия необходимой документации. На этом этапе с программой работают ее потенциальные пользователи. Они эксплуатируют программу и доводят до разработчика свои замечания. Поскольку бета-тести-ровщики знают, что в программе могут оставаться еще очень серьезные ошибки, они не работают с ней полный день — на 20 часов тестирования у них уходит около трех недель.
Однако в определенных ситуациях бета-тестировщики работают с продуктом гораздо более основательно. Такие ситуации возникают в следующих случаях:
• пользователю очень нужен разрабатываемый продукт, даже если он и не надежен, но других подобных продуктов на рынке нет;
• разработчик способен достойно «отблагодарить» тестировщика. Обычно в качестве платы за бета-тестирование пользователь получает или бесплатную копию продукта, или значительную скидку. Если продукт дорогой, этого достаточно. Но если речь идет о системе, предназначенной для доступа к важной информации, и в этой программе происходит сбой, потеря данных может обойтись пользователю гораздо дороже стоимости программного продукта;
• разработчик дает пользователю выгодную гарантию (например, дается обещание, что в случае сбоя программы сотрудником компании-разработчика будут бесплатно введены потерянные данные).
Для того чтобы ознакомиться с практической методикой кодирования и тестирования сверху вниз, рассмотрим структурную диаграмму некоторого программного комплекса (рис.4.3).
Рис. 4.3. Структурная диаграмма программного комплекса
Структурная диаграмма является трехуровневой и состоит из шести программных модулей. Программный модуль первого уровня М1 (управляющий программных модулей) вызывает три программных модуля второго уровня М2, М3, М4. Программный модуль второго уровня М4 вызывает два программных модуля третьего уровня М5 и М6.
Проектирование и кодирование программного комплекса начинается с управляющего программного модуля М1. Для его тестирования и отладки необходимо иметь программные модули второго уровня, но, так как они еще не спроектированы и не закодированы, вместо них используются имитаторы этих программных модулей — заглушки ЗагМ2,ЗагМ3 и ЗагМ4. Назначение заглушек только в том, чтобы программный модуль верхнего уровня был выполнен, поэтому они могут быть простыми.
После того как главный программный модуль М1 будет оттестирован, вместо ЗагМ2 подключается программный модуль М2. Вместо программных модулей М3 И М4 установлены заглушки ЗагМ3 и ЗагМ4. Тестируется модуль М2.
Вместо ЗагМ3 подключается модуль М3, который тестируется.
Перед заменой заглушки ЗагМ4 на модуль М4 подключаются заглушки ЗагМ5 и ЗагМ6 и так далее до тестирования и отладки последнего программного модуля М6, после чего процесс проектирования, кодирования и комплексного тестирования программного комплекса завершается. При тестировании и отладке каждого программного модуля одновременно ведется тестирование и отладка программного комплекса в целом.
Структурное кодирование
Структурное кодирование (программирование) — это метод кодирования (программирования), предусматривающий создание понятных, простых и удобочитаемых программных модулей и программных комплексов на требуемом языке программирования. Для кодирования программных модулей используются унифицированные (базовые) структуры, такие как: следование, развилка полная, развилка неполная, выбор, цикл-пока, цикл-до и цикл с параметром.
Программные комплексы и программные модули, закодированные в соответствии с перечисленными правилами структурного программирования, называетсяструктурированными.
После разбиения программного комплекса на программные модули и подготовки спецификации на каждый программный модуль начинается работа по проектированию алгоритмов, реализующих спецификацию каждого программного модуля. Наиболее часто для описания алгоритмов используется словесная форма и графическая в виде схем алгоритмов. Словесная форма наиболее понятна и доступна, но не имеет определенных правил записи и поэтому неоднозначна. Графическая форма наглядна, информативна и однозначна, так как правила выполнения и условные обозначения определяются государственным стандартом ГОСТ 19.701-90 “Схемы алгоритмов, программ, данных и систем”. Каждый программный модуль изображается в графической форме на левой стороне листа, а на правой записывается программа на языке программирования.
Современные системы программирования, как правило, ориентированы на технологию нисходящего структурного программирования.
Сквозной контроль — это проверка программного комплекса, выполняемая на основе изучения его группой специалистов. На протяжении всего времени существования программного комплекса может осуществляться несколько проверок, охватывающих все этапы его разработки.
Помните — “цена” ошибок возрастает при их обнаружении на более поздних этапах разработки программного обеспечения. Обычно считается, что “цена” ошибки возрастает на порядок при задержке обнаружения на этап.
Отладка программы
Система программирования Турбо Паскаль имеет в своем составе достаточно развитую систему отладки. Поэтому ознакомимся с ней.
Для прогона программы необходимо дать команду Ctrl-F9. Если в программе обнаружена ошибка, то программа прекращает работу и восстанавливает окно редактора. Одновременно курсор переходит на ту строку программы, при компиляции или исполнении которой обнаружена ошибка. При этом в верхней строке редактора появляется диагностическое сообщение о причине ошибки. Это позволяет ускорить отладку программы, т.е. устранить в ней синтаксические ошибки и добиться правильной ее работы.
Если ошибка возникла на этапе работы программы, простое указание того места, где она обнаружена, может не дать нужной информации, так как ошибка может быть следствием неправильной подготовки данных. Например, если ошибка возникла при извлечении квадратного корня из отрицательного числа, будет указан оператор, в котором осуществлялась сама операция извлечения корня, хотя ясно, что первопричину ошибки следует искать где-то раньше, там, где переменной было присвоено отрицательное значение. В таких ситуациях следует прибегнуть к пошаговому исполнению команд, связанных с клавишами F4, F7 и F8:
F4 — используется при отладке: начать или продолжить исполнение программы и остановиться перед исполнением той ее строки, на которой стоит курсор;
F7 — выполнить следующую строку программы; если в строке есть обращение к процедуре (функции), войти в эту процедуру и остановиться перед исполнением первого ее оператора;
F8 — выполнить следующую строку программы; если в строке есть обращение к процедуре (функции), исполнить ее и не прослеживать ее работу.
На первых порах, до приобретения практического опыта в отладке программ, можно пользоваться только клавишей F7, после нажатия на которую среда осуществляет компиляцию, компоновку (связь с библиотекой стандартных процедур и функций) и загрузку программы, а затем остановит прогон перед исполнением первого оператора. Строка программы, содержащая этот оператор, будет выделена на экране цветом. Каждое новое нажатие на клавишу F7 будет вызывать выполнение всех операций, запрограммированных в текущей строке, и смещение указателя к следующей строке программы. В местах программы, вызывающих сомнение, можно просмотреть значения нужных вам переменных или выражений.
Для этого установите курсор в то место текущей строки, где написано имя интересующей вас переменной, и нажмите Ctrl-F4. На экране откроется диалоговое окно, состоящее из трех полей. В верхнем поле будет стоять имя переменной. После этого нажмите Enter, чтобы получить в среднем поле текущее значение этой переменной. Если перед командой Ctrl-F4 курсор стоял на пустом участке строки или указал на другую переменную, верхнее поле также окажется пустым или будет содержать имя этой другой переменной. В этом случае следует ввести с помощью клавиатуры интересующее вас имя в верхнем поле и нажать клавишу Enter. Таким образом можно вводить не только имена прослеживаемых переменных, но и выражения с их участием — среда вычислит и покажет значение этого выражения.
При решении небольших примеров в процессе отладки целесообразно использовать такую возможность среды Турбо Паскаль, как одновременный вывод на экран дисплея окна редактора с программой (окно-1) и окна ввода данных и вывода решений (обычно вызывается командой Alt-F5).
Для одновременного наблюдения двух окон выполните следующие операции:
1. Нажмите клавишу F10 для перехода в режим выбора из главного меню.
2. Подведите указатель к опции Debug (отладка), нажмите клавишу Enter -на экране раскроется (выпадет) меню второго уровня.
3. Подведите указатель к пункту Output (вывод программы) и снова нажмите Enter. На экране вновь появится окно программы, но оно уже не будет исчезать при нажатии на любую клавишу — экран будет связан с этим окном постоянно.
4. Вновь нажмите клавишу F10, выберите Window, нажмите клавишу Enter.
5. В раскрывшемся меню подведите указатель к опции Tile (черепица) и нажмите клавишу Enter еще раз. Если все выполнено правильно, на экране будут одновременно присутствовать два меню.
Статьи к прочтению:
- К оформлению семестровой контрольной работы
- Когда путь подходит к концу – смени его. выбрав другой путь, ты сможешь пройти дальше.
Разворачиваем инфраструктуру для автоматизации функционального тестирования веб приложений
Похожие статьи:
-
Тестирование и отладка программ
Для проверки правильности функционирования программы выполняется тестирование. Тестирование – это исполнение программы с использованием некоторого набора…
-
Тестирование, отладка и оптимизация
(В литературе часто этот этап просто называют тестированием). На этом этапе производится всесторонняя проверка программ. По поводу того как должно…
Министерство
образования и науки Российской Федерации
Саратовский
государственный технический университет
Балаковский
институт техники, технологии и управления
КОДЫ
С ОБНАРУЖЕНИЕМ И ИСПРАВЛЕНИЕМ ОШИБОК.
КОДЫ ХЕММИНГА
Методические
указания к выполнению лабораторной
работы
по
курсу “Информационные сети и
телекоммуникации”
для
студентов специальности 210100
всех
форм обучения
Одобрено
редакционно-издательским
советом
Балаковского
института техники,
технологии и
управления
Балаково 2005
Цель
работы: ознакомление с основными
принципами помехозащищенного кодирования.
Получение практических навыков
помехоустойчивого кодирования и
исследование корректирующих свойств
кода Хемминга.
Основные понятия Помехоустойчивое кодирование
При
телеуправлении, телеизмерении и
телесигнализации в информационно-измерительных
и информационно-управляющих системах
(ИИС и ИУС) вся необходимая информация
передается по каналам связи. При этом
передача должна осуществляться без
искажений или с минимальными искажениями.
Для минимизации искажений информации
в системах передачи данных (СПД)
используется ее кодирование.
Кодирование
в СПД — это
преобразование дискретного сообщения
в дискретный сигнал, осуществляемое по
определенному правилу. Обратный
процесс-декодирование
— это
восстановление дискретного сообщения
по сигналу на выходе дискретного канала,
осуществляемое с учетом правила
кодирования.
Код
есть совокупность условных сигналов
или символов, обозначающих дискретные
сообщения.
Кодовая
комбинация —
это представление дискретного сигнала
в соответствующем (например, двоичном)
коде.
Кодирование
нашло широкое применение в современных
информационных системах при защите
передаваемой информации от помех либо
несанкционированного доступа. Коды
делятся на две основные разновидности:
помехозащищенные и непомехозащищенные.
Особенностью непомехозащищенных кодов
является наличие их в составе кодовых
комбинаций, которые отличаются друг от
друга лишь в одном разряде. Типичным
кодом такого типа является двоичный
код на все сочетания. Существует много
непомехозащищенных кодов, например,
единично-десятичный код, двоично-десятичный
код, числоимпульсный код, код Морзе, код
Грея и другие [1-3]. Помехозащищенными
называют коды, позволяющие обнаружить
или обнаружить и исправить ошибки в
кодовых комбинациях. Отсюда деление
этих кодов на две большие группы:
-
Коды
с обнаружением ошибок. -
Коды
с обнаружением и исправлением, ошибок
(корректирующие).
Основой
для обнаружения и исправления ошибок
такими кодами является увеличение
кодового расстояния между кодовыми
комбинациями (кодовые комбинации
различаются в двух и более разрядах).
Кодовое
расстояние (Хемминга)
— это минимальное число элементов, в
которых одна кодовая комбинация
отличается от другой (по всем парам
кодовых слов). В корректирующих кодах
комбинации построены по определенному
правилу, например, содержат четное число
единиц. Построение помехоустойчивого
кода с недоиспользованием части кодовых
комбинаций, приводящей к так называемой
“избыточности”. Избыточность означает,
что из исходных символов можно построить
больше комбинаций, чем предусмотрено
при их приеме. Таким образом, уменьшение
числа используемых комбинаций приводит
к повышению помехоустойчивости кода,
которая связана с увеличением кодового
расстояния.
Коды с обнаружением и исправлением ошибок
Если
кодовые комбинации составлены так, что
отличаются на кодовое расстояние d
≥ 3,
то они
образуют корректирующий код, который
позволяет по имеющейся в кодовой
комбинации, не только обнаруживать, но
и исправлять ошибки. Составление
корректирующих кодов производят по
следующему правилу. Сначала определяют
количество контрольных символов m,
которые следует добавить к кодовой
комбинации, состоящей из k
информационных символов. Далее
устанавливают место, где должны быть
расставлены в комбинации, и их состав,
т. е. является ли данный контрольный
символ “1” или “0”. На приеме обычно
делают проверку на четность определенной
части разрядов.
Соседние файлы в папке методические указания по лабораторной работе
- #
- #
- #
13.02.2014950.13 Кб35ИЗУЧЕНИЕ ДВУХПРОВОДНОЙ СХЕМЫ(нужна двухсторонняя печать).tif
- #
- #
- #
- #
- #
- #
13.02.20142.99 Mб24система телемеханики с ВРС.tif
![]()
| Обноружение ошибок | ||||
| Исправление ошибок | ||||
| Коррекция ошибок | ||||
| Назад | ||||
Методы обнаружения ошибок
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых
комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или
равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают
большой «чувствительностью» к помехам. Внесение избыточности при использовании
помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким
образом, все множество
 комбинаций можно разбить на два подмножества:
комбинаций можно разбить на два подмножества:
подмножество разрешенных комбинаций, обладающих определенными признаками, и
подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все
кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только
их часть Nk , которая составляет подмножество разрешенных комбинаций. Если при приеме
выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о
наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При
этом принятая комбинация не декодируется (не принимается решение о переданном
сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами.
Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего
структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие
минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту
позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде
Хемминга добавляется m проверочных элементов для автоматического определения
местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации
составляет: n = k + m.
Метричное представление n,k-кодов
В настоящее время наибольшее внимание с точки зрения технических приложений
уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов
цифровая информация передается в виде отдельных кодовых комбинаций (блоков) равной
длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых
состоят из двух частей: информационной и проверочной. При общем числе n символов в блоке
число информационных символов равно k, а число проверочных символов:
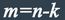
К основным характеристикам корректирующих кодов относятся:
|
— число разрешенных и запрещенных кодовых комбинаций; |
Для блочных двоичных кодов, с числом символов в блоках, равным n, общее число
возможных кодовых комбинаций определяется значением
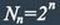
Число разрешенных кодовых комбинаций при наличии k информационных разрядов в
первичном коде:
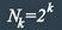
Очевидно, что число запрещенных комбинаций:
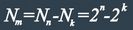
а с учетом ![]() отношение будет
отношение будет
![]()
где m – число избыточных (проверочных) разрядов в блочном коде.
Избыточностью корректирующего кода называют величину
![]()
откуда следует:
![]()
Эта величина показывает, какую часть общего числа символов кодовой комбинации
составляют информационные символы. В теории кодирования величину Bk называют
относительной скоростью кода. Если производительность источника информации равна H
символов в секунду, то скорость передачи после кодирования этой информации будет
![]()
поскольку в закодированной последовательности из каждых n символов только k символов
являются информационными.
Если число ошибок, которые нужно обнаружить или исправить, значительно, то необходимо
иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи
оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно
увеличивать как общее число символов, так и число информационных символов.
При этом длительность кодовых блоков будет существенно возрастать, что приведет к
задержке информации при передаче и приеме. Чем сложнее кодирование, тем длительнее
временная задержка информации.
Минимальное кодовое расстояние – dmin. Для того чтобы можно было обнаружить и
исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от
запрещенной. Если ошибки в канале связи действуют независимо, то вероятность преобразования
одной кодовой комбинации в другую будет тем меньше, чем большим числом символов они
различаются.
Если интерпретировать кодовые комбинации как точки в пространстве, то отличие
выражается в близости этих точек, т. е. в расстоянии между ними.
Количество разрядов (символов), которыми отличаются две кодовые комбинации, можно
принять за кодовое расстояние между ними. Для определения этого расстояния нужно сложить
две кодовые комбинации «по модулю 2» и подсчитать число единиц в полученной сумме.
Например, две кодовые комбинации xi = 01011 и xj = 10010 имеют расстояние d(xi,xj) , равное 3,
так как:

Здесь под операцией ⊕ понимается сложение «по модулю 2».
Заметим, что кодовое расстояние d(xi,x0) между комбинацией xi и нулевой x0 = 00…0
называют весом W комбинации xi, т.е. вес xi равен числу «1» в ней.
Расстояние между различными комбинациями некоторого конкретного кода могут
существенно отличаться. Так, в частности, в безызбыточном первичном натуральном коде n = k это
расстояние для различных комбинаций может изменяться от единицы до величины n, равной
разрядности кода. Особую важность для характеристики корректирующих свойств кода имеет
минимальное кодовое расстояние dmin, определяемое при попарном сравнении всех кодовых
комбинаций, которое называют расстоянием Хемминга.
В безызбыточном коде все комбинации являются разрешенными и его минимальное
кодовое расстояние равно единице – dmin=1. Поэтому достаточно исказиться одному символу,
чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код
обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность,
которая обеспечивала бы минимальное расстояние между любыми двумя разрешенными
комбинациями не менее двух – dmin ≥ 2..
Минимальное кодовое расстояние является важнейшей характеристикой помехоустойчивых
кодов, указывающей на гарантируемое число обнаруживаемых или исправляемых заданным
кодом ошибок.
Число обнаруживаемых или исправляемых ошибок
При применении двоичных кодов учитывают только дискретные искажения, при которых
единица переходит в нуль («1» → «0») или нуль переходит в единицу («0» → «1»). Переход «1» →
«0» или «0» → «1» только в одном элементе кодовой комбинации называют единичной ошибкой
(единичным искажением). В общем случае под кратностью ошибки подразумевают число
позиций кодовой комбинации, на которых под действием помехи одни символы оказались
замененными на другие. Возможны двукратные (g = 2) и многократные (g > 2) искажения
элементов в кодовой комбинации в пределах 0 ≤ g ≤ n.
Минимальное кодовое расстояние является основным параметром, характеризующим
корректирующие способности данного кода. Если код используется только для обнаружения
ошибок кратностью g0, то необходимо и достаточно, чтобы минимальное кодовое расстояние
было равно dmin ≥ g0 + 1.
В этом случае никакая комбинация из go ошибок не может перевести одну разрешенную
кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок
кратностью g0 можно записать
![]()
Чтобы можно было исправить все ошибки кратностью gu и менее, необходимо иметь
минимальное расстояние, удовлетворяющее условию dmin ≥ 2gu
![]()
В этом случае любая кодовая комбинация с числом ошибок gu отличается от каждой
разрешенной комбинации не менее чем в gu+1 позициях. Если условие ![]() не выполнено,
не выполнено,
возможен случай, когда ошибки кратности g исказят переданную комбинацию так, что она станет
ближе к одной из разрешенных комбинаций, чем к переданной или даже перейдет в другую
разрешенную комбинацию. В соответствии с этим, условие исправления всех ошибок кратностью
не более gи можно записать:
![]()
Из ![]() и
и ![]()
следует, что если код исправляет все ошибки кратностью gu, то число
ошибок, которые он может обнаружить, равно go = 2gu. Следует отметить, что эти соотношения
устанавливают лишь гарантированное минимальное число обнаруживаемых или
исправляемых ошибок при заданном dmin и не ограничивают возможность обнаружения ошибок
большей кратности. Например, простейший код с проверкой на четность с dmin = 2 позволяет
обнаруживать не только одиночные ошибки, но и любое нечетное число ошибок в пределах go < n.
Корректирующие возможности кодов
Вопрос о минимально необходимой избыточности, при которой код обладает нужными
корректирующими свойствами, является одним из важнейших в теории кодирования. Этот вопрос
до сих пор не получил полного решения. В настоящее время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают связь между максимально возможным минимальным
расстоянием корректирующего кода и его избыточностью.
Коды Хэмминга
Построение кодов Хемминга базируется на принципе проверки на четность веса W (числа
единичных символов «1») в информационной группе кодового блока.
Поясним идею проверки на четность на примере простейшего корректирующего кода,
который так и называется кодом с проверкой на четность или кодом с проверкой по паритету
(равенству).
В таком коде к кодовым комбинациям безызбыточного первичного двоичного k-разрядного
кода добавляется один дополнительный разряд (символ проверки на четность, называемый
проверочным, или контрольным). Если число символов «1» исходной кодовой комбинации
четное, то в дополнительном разряде формируют контрольный символ «0», а если число
символов «1» нечетное, то в дополнительном разряде формируют символ «1». В результате
общее число символов «1» в любой передаваемой кодовой комбинации всегда будет четным.
Таким образом, правило формирования проверочного символа сводится к следующему:
![]()
где i – соответствующий информационный символ («0» или «1»); k – общее их число а, под
операцией ⊕ здесь и далее понимается сложение «по модулю 2». Очевидно, что добавление
дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению
с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации
на разрешенные и неразрешенные. Код с проверкой на четность позволяет обнаруживать
одиночную ошибку при приеме кодовой комбинации, так как такая ошибка нарушает условие
четности, переводя разрешенную комбинацию в запрещенную.
Критерием правильности принятой комбинации является равенство нулю результата S
суммирования «по модулю 2» всех n символов кода, включая проверочный символ m1. При
наличии одиночной ошибки S принимает значение 1:
![]() — ошибок нет,
— ошибок нет,
![]() — однократная ошибка
— однократная ошибка
Этот код является (k+1,k)-кодом, или (n,n–1)-кодом. Минимальное расстояние кода равно
двум (dmin = 2), и, следовательно, никакие ошибки не могут быть исправлены. Простой код с
проверкой на четность может использоваться только для обнаружения (но не исправления)
однократных ошибок.
Увеличивая число дополнительных проверочных разрядов, и формируя по определенным
правилам проверочные символы m, равные «0» или «1», можно усилить корректирующие
свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. На этом и
основано построение кодов Хемминга.
Коды Хемминга позволяют исправлять одиночную ошибку, с помощью непосредственного
описания. Для каждого числа проверочных символов m =3, 4, 5… существует классический код
Хемминга с маркировкой
![]()
т.е. (7,4), (15,11) (31,26) …
При других значениях числа информационных символов k получаются так называемые
усеченные (укороченные) коды Хемминга. Так для кода имеющего 5 информационных символов,
потребуется использование корректирующего кода (9,5), являющегося усеченным от
классического кода Хемминга (15,11), так как число символов в этом коде уменьшается
(укорачивается) на 6.
Для примера рассмотрим классический код Хемминга (7,4), который можно сформировать и
описать с помощью кодера, представленного на рис. 1 В простейшем варианте при заданных
четырех информационных символах: i1, i2, i3, i4 (k = 4), будем полагать, что они сгруппированы в
начале кодового слова, хотя это и не обязательно. Дополним эти информационные символы
тремя проверочными символами (m = 3), задавая их следующими равенствами проверки на
четность, которые определяются соответствующими алгоритмами, где знак ⊕ означает
сложение «по модулю 2»: r1 = i1 ⊕ i2 ⊕ i3, r2 = i2 ⊕ i3 ⊕ i4, r3 = i1 ⊕ i2 ⊕ i4.
В соответствии с этим алгоритмом определения значений проверочных символов mi, в табл.
1 выписаны все возможные 16 кодовых слов (7,4)-кода Хемминга.
Таблица 1 Кодовые слова (7,4)-кода Хэмминга
|
k=4 |
m=4 |
|
i1 i2 i3 i4 |
r1 r2 r3 |
|
0 0 0 0 |
0 0 0 |
|
0 0 0 1 |
0 1 1 |
|
0 0 1 0 |
1 1 0 |
|
0 0 1 1 |
1 0 1 |
|
0 1 0 0 |
1 1 1 |
|
0 1 0 1 |
1 0 0 |
|
0 1 1 0 |
0 0 1 |
|
0 1 1 1 |
0 1 0 |
|
1 0 0 0 |
1 0 1 |
|
1 0 0 1 |
1 0 0 |
|
1 0 1 0 |
0 1 1 |
|
1 0 1 1 |
0 0 0 |
|
1 1 0 0 |
0 1 0 |
|
1 1 0 1 |
0 0 1 |
|
1 1 1 0 |
1 0 0 |
|
1 1 1 1 |
1 1 1 |
На рис.1 приведена блок-схема кодера – устройства автоматически кодирующего
информационные разряды в кодовые комбинации в соответствии с табл.1
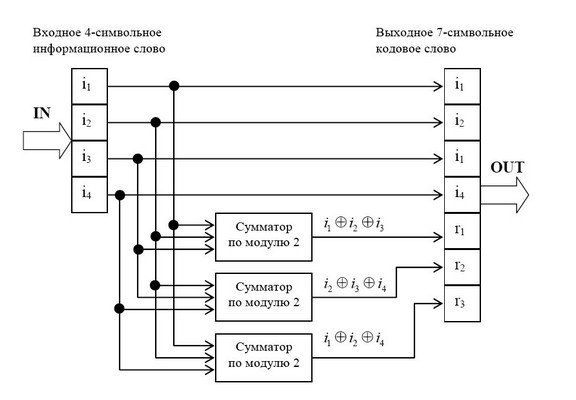
Рис. 1 Кодер для (7,4)-кода Хемминга
На рис. 1.4 приведена схема декодера для (7,4) – кода Хемминга, на вход которого
поступает кодовое слово
![]() . Апостроф означает, что любой символ слова может
. Апостроф означает, что любой символ слова может
быть искажен помехой в телекоммуникационном канале.
В декодере в режиме исправления ошибок строится последовательность:
![]()
![]()
![]()
Трехсимвольная последовательность (s1, s2, s3) называется синдромом. Термин «синдром»
используется и в медицине, где он обозначает сочетание признаков, характерных для
определенного заболевания. В данном случае синдром S = (s1, s2, s3) представляет собой
сочетание результатов проверки на четность соответствующих символов кодовой группы и
характеризует определенную конфигурацию ошибок (шумовой вектор).
Число возможных синдромов определяется выражением:
![]()
При числе проверочных символов m =3 имеется восемь возможных синдромов (23 = .
Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены.
Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и
исправляется. Классические коды Хемминга имеют число синдромов, точно равное их
необходимому числу (что позволяет исправить все однократные ошибки в любом информативном
и проверочном символах) и включают один нулевой синдром. Такие коды называются
плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них
превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов
будет равно 24 =16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о
неполной упаковке кода (9,5).
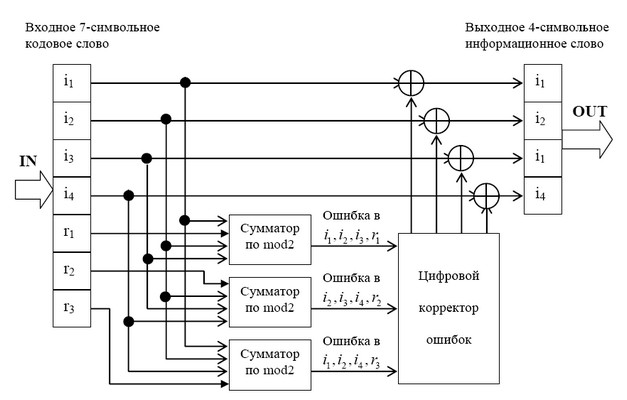
Рис. 2 Декодер для (7, 4)-кода Хемминга
Для рассматриваемого кода (7,4) в табл. 2 представлены ненулевые синдромы и
соответствующие конфигурации ошибок.
Таблица 2 Синдромы (7, 4)-кода Хемминга
|
Синдром |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
|
Конфигурация ошибок |
0000001 |
0000010 |
0000100 |
0001000 |
0010000 |
0100000 |
1000000 |
|
Ошибка в символе |
m1 |
m2 |
i4 |
m1 |
i1 |
i3 |
i2 |
Таким образом, (7,4)-код позволяет исправить все одиночные ошибки. Простая проверка
показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно
создание такого цифрового корректора ошибок (дешифратора синдрома), который по
соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе.
После внесения исправления проверочные символы ri можно на выход декодера (рис. 2) не
выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и
декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и
выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при
перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)-
кодами Хемминга.
Циклические коды
Своим названием эти коды обязаны такому факту, что для них часть комбинаций, либо все
комбинации могут быть получены путем циклическою сдвига одной или нескольких базовых
комбинаций кода.
Построение такого кода основывается на использовании неприводимых многочленов в поле
двоичных чисел. Такие многочлены не могут быть представлены в виде произведения
многочленов низших степеней подобно тому, как простые числа не могут быть представлены
произведением других чисел. Они делятся без остатка только на себя или на единицу.
Для определения неприводимых многочленов раскладывают на простые множители бином
хn -1. Так, для n = 7 это разложение имеет вид:
(x7)=(x-1)(x3+x2)(x3+x-1)
Каждый из полученных множителей разложения может применяться для построения
корректирующего кода.
Неприводимый полином g(x) называют задающим, образующим или порождающим
для корректирующего кода. Длина n (число разрядов) создаваемого кода произвольна.
Кодовая последовательность (комбинация) корректирующего кода состоит из к информационных
разрядов и n — к контрольных (проверочных) разрядов. Степень порождающего полинома
r = n — к равна количеству неинформационных контрольных разрядов.
Если из сделанного выше разложения (при n = 7) взять полипом (х — 1), для которого
r=1, то k=n-r=7-1=6. Соответствующий этому полиному код используется для контроля
на чет/нечет (обнаружение ошибок). Для него минимальное кодовое расстояние D0 = 2
(одна единица от D0 — для исходного двоичного кода, вторая единица — за счет контрольного разряда).
Если же взять полином (x3+x2+1) из указанного разложения, то степень полинома
r=3, а k=n-r=7-3=4.
Контрольным разрядам в комбинации для некоторого кода могут быть четко определено место (номера разрядов).
Тогда код называют систематическим или разделимым. В противном случае код является неразделимым.
Способы построения циклических кодов по заданному полиному.
1) На основе порождающей (задающей) матрицы G, которая имеет n столбцов, k строк, то есть параметры которой
связаны с параметрами комбинаций кода. Порождающую матрицу строят, взяв в качестве ее строк порождающий
полином g(x) и (k — 1) его циклических сдвигов:
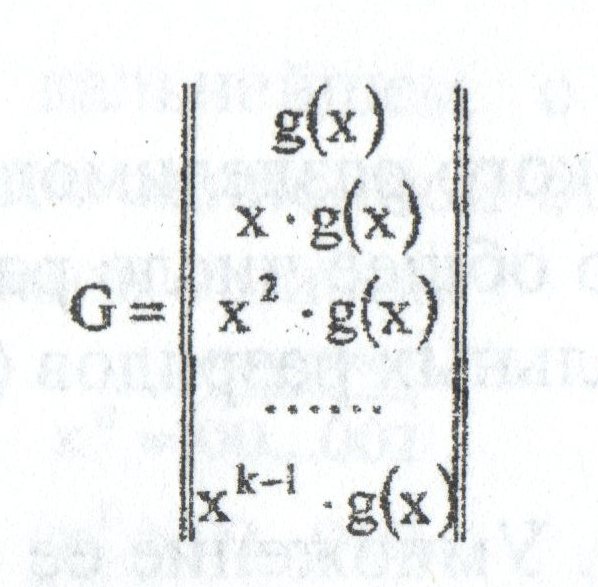
Пример; Определить порождающую матрицу, если известно, что n=7, k=4, задающий полином g(x)=x3+х+1.
Решение: Кодовая комбинация, соответствующая задающему полиному g(x)=x3+х+1, имеет вид 1011.
Тогда порождающая матрица G7,4 для кода при n=7, к=4 с учетом того, что k-1=3, имеет вид:

Порождающая матрица содержит k разрешенных кодовых комбинаций. Остальные комбинации кода,
количество которых (2k — k) можно определить суммированием по модулю 2 всевозможных сочетаний
строк матрицы Gn,k. Для матрицы, полученной в приведенном выше примере, суммирование по модулю 2
четырех строк 1-2, 1-3, 1-4, 2-3, 2-4, 3-4 дает следующие кодовые комбинации циклического кода:
001110101001111010011011101010011101110100
Другие комбинации искомого корректирующего кода могут быть получены сложением трех комбинаций, например,
из сочетания строк 1-3-4, что дает комбинацию 1111111, а также сложением четырех строк 1-2-3-4, что
дает комбинацию 1101001 и т.д.
Ряд комбинаций искомого кода может быть получено путем дальнейшего циклического сдвига комбинаций
порождающей матрицы, например, 0110001, 1100010, 1000101. Всего для образования искомого циклического
кода требуется 2k=24=16 комбинаций.
2) Умножение исходных двоичных кодовых комбинаций на задающий полином.
Исходными комбинациями являются все k-разрядные двоичные комбинации. Так, например, для исходной
комбинации 1111 (при k = 4) умножение ее на задающий полином g(x)=x3+х+1=1011 дает 1101001.
Полученные на основе двух рассмотренных способов циклические коды не являются разделимыми.
3) Деление на задающий полином.
Для получения разделимого (систематического) циклического кода необходимо разделить многочлен
xn-k*h(x), где h(x) — исходная двоичная комбинация, на задающий полином g(x) и прибавить полученный
остаток от деления к многочлену xn-k*h(x).
Заметим, что умножение исходной комбинации h(x) на xn-k эквивалентно сдвигу h(x) на (n-к) разрядов влево.
Пример: Требуется определить комбинации циклического разделимого кода, заданного полиномом g(x)=x3+х+1=1011 и
имеющего общее число разрядов 7, число информационных разрядов 4, число контрольных разрядов (n-k)=3.
Решение: Пусть исходная комбинация h(x)=1100. Умножение ее на xn-k=x3=1000 дает
x3*(x3+x2)=1100000, то есть эквивалентно
сдвигу исходной комбинации на 3 разряда влево. Деление комбинации 1100000 на комбинацию 1011, эквивалентно задающему полиному, дает:

Полученный остаток от деления, содержащий xn-k=3 разряда, прибавляем к полиному, в результате чего получаем искомую комбинацию
разделимого циклического кода: 1100010. В ней 4 старших разряда (слева) соответствуют исходной двоичной комбинации, а три младших
разряда являются контрольными.
Следует сделать ряд указаний относительно процедуры деления:
1) При делении задающий полином совмещается старшим разрядом со старшим «единичными разрядом делимого.
2) Вместо вычитания по модулю 2 выполняется эквивалентная ему процедура сложения по модулю 2.
3) Деление продолжается до тех пор, пока степень очередного остатка не будет меньше степени делителя (задающего полинома). При достижении
этого полученный остаток соответствует искомому содержанию контрольных разрядов для данной искомой двоичной комбинации.
Для проверки правильности выполнения процедуры определения комбинации циклического кода необходимо разделить полученную комб1шацию на задающий полином с
учетом сделанных выше замечаний. Получение нулевого остатка от такого деления свидетельствует о правильности определения комбинации.
Логический код 4В/5В
Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то
общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (25) двухразрядных буквенно-цифровых символа,
имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (24) символов.
Поэтому в результирующем коде можно подобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами
(code violation). В этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных.
Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии,
так как избыточные единицы пользовательской информации не несут, и только «занимают эфирное время». Избыточные коды позволяют приемнику распознавать
искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
Итак, рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере
приемника пять битов расшифровываются как информационные и служебные сигналы.
Для служебных сигналов отведены девять символов, семь символов — исключены.
Исключены комбинации, имеющие более трех нулей (01 — 00001, 02 — 00010, 03 — 00011, 08 — 01000, 16 — 10000). Такие сигналы интерпретируются символом
V и командой приемника VIOLATION — сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная
комбинация из пяти нулей (00 — 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET — отсутствие сигнала в линии.
Такое кодирование данных решает две задачи — синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения
последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале.
Цена за эти достоинства при таком способе кодирования данных — снижение скорости передачи полезной информации.
К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы
частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%.
Схема кодирования 4В/5В представлена в таблице.
|
Двоичный код 4В |
Результирующий код 5В |
|
0 0 0 0 |
1 1 1 1 0 |
|
0 0 0 1 |
0 1 0 0 1 |
|
0 0 1 0 |
1 0 1 0 0 |
|
0 0 1 1 |
1 0 1 0 1 |
|
0 1 0 0 |
0 1 0 1 0 |
|
0 1 0 1 |
0 1 0 1 1 |
|
0 1 1 0 |
0 1 1 1 0 |
|
0 1 1 1 |
0 1 1 1 1 |
|
1 0 0 0 |
1 0 0 1 0 |
|
1 0 0 1 |
1 0 0 1 1 |
|
1 0 1 0 |
1 0 1 1 0 |
|
1 0 1 1 |
1 0 1 1 1 |
|
1 1 0 0 |
1 1 0 1 0 |
|
1 1 0 1 |
1 1 0 1 1 |
|
1 1 1 0 |
1 1 1 0 0 |
|
1 1 1 1 |
1 1 1 0 1 |
Итак, соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по
одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей — например, в помощью
цифрового кода NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд.
Буква ^ В в названии кода означает, что элементарный сигнал имеет 2 состояния — от английского binary — двоичный. Имеются
также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется
код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256
исходных кодов приходится 36=729 результирующих символов.
Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального
уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились,
использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными
кодами не усложняет функциональные требования к этому оборудованию.
Единственное требование — для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код,
должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мб/с передатчик должен
работать с тактовой частотой 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по
линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже
спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника
и передатчика на повышенной тактовой частоте.
В основном для локальных сетей проще, надежней, качественней, быстрей — использовать логическое кодирование данных
с помощью избыточных кодов, которое устранит длительные последовательности нулей и обеспечит синхронизацию
сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного
логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц,
кодом NRZI необходимы частоты 25 — 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и
кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до 62,5 МГц. Но тем не менее, этот диапазон
еще «влазит» в полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного
кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться
линией на 100 МГц.
Скрэмблирование
Другой метод логического кодирования основан на предварительном «перемешивании» исходной информации таким
образом, чтобы вероятность появления единиц и нулей на линии становилась близкой.
Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble — свалка, беспорядочная сборка) .
При скремблировании данные перемешиваються по определенному алгоритму и приемник, получив двоичные данные, передает
их на дескрэмблер, который восстанавливает исходную последовательность бит.
Избыточные биты при этом по линии не передаются.
Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически
единственной операцией, используемой в скремблерах является XOR — «побитное исключающее ИЛИ», или еще говорят —
сложение по модулю 2. При сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается — 0.
Метод скрэмблирования очень прост. Сначала придумывают скрэмблер. Другими словами придумывают по какому соотношению
перемешивать биты в исходной последовательности с помощью «исключающего ИЛИ». Затем согласно этому соотношению из текущей
последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды
сдвигаются на 1 бит, а только что полученное значение («0» или «1») помещается в освободившийся самый младший разряд.
Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным
ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к
узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Например, скрэмблер может реализовывать следующее соотношение:
![]()
где Bi — двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai — двоичная цифра исходного
кода, поступающая на i-м такте на вход скрэмблера, Bi-3 и Bi-5 — двоичные цифры результирующего кода, полученные на
предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта, ⊕ — операция исключающего
ИЛИ (сложение по модулю 2).
Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001.
Скрэмблер, определенный выше даст следующий результирующий код:
B1=А1=1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
Таким образом, на выходе скрэмблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, п
рисутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную
последовательность на основании обратного соотношения.
![]()
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру
результирующего кода, и сдвигом между слагаемыми.
Главная проблема кодирования на основе скремблеров — синхронизация передающего (кодирующего) и принимающего
(декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация
необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации.
На практике для этих целей обычно применяется комбинация двух методов:
а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при ненахождении
такого бита активно начать поиск синхронизации с отправителем,
б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить
декодирование принимаемых битов информации «по памяти» без синхронизации.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода ^ Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
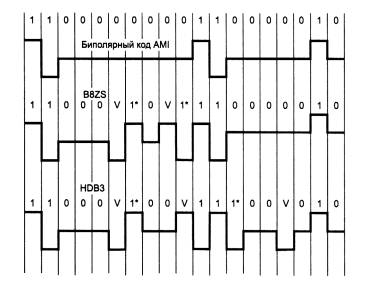
Рис. 3 Коды B8ZS и HDB3
На этом рисунке показано использование метода ^ B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки
кода AMI. Исходный код состоит из двух длинных последовательностей нулей (8- в первом случае и 5 во втором).
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять
цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей
единицы, 1* — сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В
результате на 8 тактах приемник наблюдает 2 искажения — очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому
приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей.
Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые 4 подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS.
Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала
V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то
используется последовательность 000V, а если число единиц было четным — последовательность 1*00V.
Таким образом, применение логическое кодирование совместно с потенциальным кодированием дает следующие преимущества:
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей,
которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования,
обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте.
Линейные блочные коды
При передаче информации по каналам связи возможны ошибки вследствие помех и искажений сигналов. Для обнаружения и
исправления возникающих ошибок используются помехоустойчивые коды. Упрощенная схема системы передачи информации
при помехоустойчивом кодировании показана на рис. 4
Кодер служит для преобразования поступающей от источника сообщений последовательности из k информационных
символов в последовательность из n cимволов кодовых комбинаций (или кодовых слов). Совокупность кодовых слов образует код.
Множество символов, из которых составляется кодовое слово, называется алфавитом кода, а число различных символов в
алфавите – основанием кода. В дальнейшем вследствие их простоты и наибольшего распространения рассматриваются главным
образом двоичные коды, алфавит которых содержит два символа: 0 и 1.
Рис. 4 Система передачи дискретных сообщений
Правило, по которому информационной последовательности сопоставляется кодовое слово, называется правилом кодирования.
Если при кодировании каждый раз формируется блок А из k информационных символов, превращаемый затем в n-символьную
кодовую комбинацию S, то код называется блочным. При другом способе кодирования информационная последовательность на
блоки не разбивается, и код называется непрерывным.
С математической точки зрения кодер осуществляет отображение множества из 2k элементов (двоичных информационных
последовательностей) в множество, состоящее из 2n элементов (двоичных последовательностей длины n). Для практики
интересны такие отображения, в результате которых получаются коды, обладающие способностью исправлять часть ошибок
и допускающие простую техническую реализацию кодирующих и декодирующих устройств.
Дискретный канал связи – это совокупность технических средств вместе со средой распространения радиосигналов, включенных
между кодером и декодером для передачи сигналов, принимающих конечное число разных видов. Для описания реальных каналов
предложено много математических моделей, с разной степенью детализации отражающих реальные процессы. Ограничимся рассмотрением
простейшей модели двоичного канала, входные и выходные сигналы которого могут принимать значения 0 и 1.
Наиболее распространено предположение о действии в канале аддитивной помехи. Пусть S=(s1,s2,…,sn)
и Y=(y1,y2,…,yn) соответственно входная и выходная последовательности двоичных символов.
Помехой или вектором ошибки называется последовательность из n символов E=(e1,e2,…,en), которую
надо поразрядно сложить с переданной последовательностью, чтобы получить принятую:
Y=S+E
Таким образом, компонента вектора ошибки ei=0 указывает на то, что 2-й символ принят правильно (yi=si),
а компонента ei=1 указывает на ошибку при приеме (yi≠si).Поэтому важной характеристикой вектора ошибки
является число q ненулевых компонентов, которое называется весом или кратностью ошибки. Кратность ошибки – дискретная случайная величина,
принимающая целочисленные значения от 0 до n.
Классификация двоичных каналов ведется по виду распределения случайного вектора E. Основные результаты теории кодирования получены в
предположении, что вероятность ошибки в одном символе не зависит ни от его номера в последовательности, ни от его значения. Такой
канал называется стационарным и симметричным. В этом канале передаваемые символы искажаются с одинаковой вероятностью
P, т.е. P(ei=1)=P, i=1,2,…,n.
Для симметричного стационарного канала распределение вероятностей векторов ошибки кратности q является биноминальным:
P(Ei)=Pq(1-P)n-q
которая показывает, что при P<0,5 вероятность β2=αj является убывающей функцией q,
т.е. в симметричном стационарном канале более вероятны ошибки меньшей кратности. Этот важный факт используется при построении
помехоустойчивых кодов, т.к. позволяет обосновать тактику обнаружения и исправления в первую очередь ошибок малой кратности.
Конечно, для других моделей канала такая тактика может и не быть оптимальной.
Декодирующее устройство (декодер) предназначено оценить по принятой последовательности Y=(y1,y2,…,yn)
значения информационных символов A‘=(a‘1,a‘2,…,a‘k,).
Из-за действия помех возможны неправильные решения. Процедура декодирования включает решение двух задач: оценивание переданного кодового
слова и формирование оценок информационных символов.
Вторая задача решается относительно просто. При наиболее часто используемых систематических кодах, кодовые слова которых содержат информационные
символы на известных позициях, все сводится к простому их стробированию. Очевидно также, что расположение информационных символов внутри кодового
слова не имеет существенного значения. Удобно считать, что они занимают первые k позиций кодового слова.
Наибольшую трудность представляет первая задача декодирования. При равновероятных информационных последовательностях ее оптимальное решение
дает метод максимального правдоподобия. Функция правдоподобия как вероятность получения данного вектора Y при передаче кодовых слов
Si, i=1,2,…,2k на основании Y=S+E определяется вероятностями появления векторов ошибок:
P(Y/Si)=P(Ei)=Pqi(1-P)n-qi
где qi – вес вектора Ei=Y+Si
Очевидно, вероятность P(Y/Si) максимальна при минимальном qi. На основании принципа максимального правдоподобия оценкой S‘ является кодовое слово,
искажение которого для превращения его в принятое слово Y имеет минимальный вес, т. е. в симметричном канале является наиболее вероятным (НВ):
S‘=Y+EHB
Если несколько векторов ошибок Ei имеют равные минимальные веса, то наивероятнейшая ошибка EHB определяется случайным выбором среди них.
В качестве расстояния между двумя кодовыми комбинациями принимают так называемое расстояние Хэмминга, которое численно равно количеству символов, в которых одна
комбинация отлична от другой, т.е. весу (числу ненулевых компонентов) разностного вектора. Расстояние Хэмминга между принятой последовательностью Y и всеми
возможными кодовыми словами 5, есть функция весов векторов ошибок Ei:
Поэтому декодирование по минимуму расстояния, когда в качестве оценки берется слово, ближайшее к принятой
последовательности, является декодированием по максимуму правдоподобия.
Таким образом, оптимальная процедура декодирования для симметричного канала может быть описана следующей последовательностью операций. По принятому
вектору Y определяется вектор ошибки с минимальным весом EHB, который затем вычитается (в двоичном канале — складывается по модулю 2) из Y:
Y→EHB→S‘=Y+EHB
Наиболее трудоемкой операцией в этой схеме является определение наи-вероятнейшего вектора ошибки, сложность которой
существенно возрастает при увеличении длины кодовых комбинаций. Правила кодирования, которые нацелены на упрощение
процедур декодирования, предполагают придание всем кодовым словам технически легко проверяемых признаков.
Широко распространены линейные коды, называемые так потому, что их кодовые слова образуют линейное
подпространство над конечным полем. Для двоичных кодов естественно использовать поле характеристики p=2.
Принадлежность принятой комбинации Y известному подпространству является тем признаком, по которому
выносится решение об отсутствии ошибок (EHB=0).
Так как по данному коду все пространство последовательностей длины n разбивается на смежные классы,
то для каждого смежного класса можно заранее определить вектор ошибки минимального веса,
называемый лидером смежного класса. Тогда задача декодера состоит в определении номера смежного класса,
которому принадлежит Y, и формировании лидера этого класса.
ФГБОУ ВПО «МОРДОВСКИЙ ГОСУДАРСТВЕННЫЙ ПЕДАГОГИЧЕСКИЙ ИНСТИТУТ ИМЕНИ. М Е. ЕВСЕВЬЕВА»
Физико – математический факультет
Кафедра информатики и вычислительной техники
КУРСОВАЯ РАБОТА
ПРОБЛЕМЫ КОДИРОВАНИЯ ИНФОРМАЦИИ
Автор курсовой работы___________________________________ Д.А. Храмов
Направление подготовки 050100.62 Педагогическое образование
Профиль Математика. Информатика.
Руководитель работы
д.ф.–м.н., проф. каф. ИВТ______________________________ Е.В. Щенникова
Саранск 2013
Содержание
Введение……………………………………………………………………………3
1 Кодирование информации………………………………………………………5
1.1 Кодирование текстовой информации…………………………………5
1.2 Кодирование графической информации……………………….……..6
1.3 Кодирование звуковой информации………………………………….9
2 Шум и защита от шума. Теория кодирования К.Шеннона …………………11
3 Способы обнаружения ошибок с их последующим исправлением…………13
4 Основные понятия корректирующих кодов…………………………………15
4.1 Линейные и групповые коды…………………………………………17
4.2 Код Хэмминга………………………………………………………….21
Заключение……………………………………………………………………… 27
Список литературы………………………………………………………………28
Введение
Кодирование – процесс представления информации в виде кода. Под термином «кодирование», как правило, понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Кодирование в узком смысле – способ сделать сообщение непонятным для всех, кто не владеет ключом кода.
Первым, кто использовал кодирование двух символьной информации, был Готфрид Вильгельм Лейбниц. Он считал: «Вычисление с помощью двоек … является для науки основным и порождает новые открытия. При сведении чисел к простым началам, каковыми являются 0 и 1, везде появляется чудесный порядок». Но, к сожалению, эта система была забыта.
Первым теоретическое решение проблемы передачи данных по зашумленным каналам предложил
Клод Шеннон, основоположник статистической теории информации. Работая в Bell Labs, Шеннон написал работу «Математическая теория передачи сообщений» (1948), где показал, что если пропускная способность канала выше энтропии источника сообщений, то сообщение можно закодировать так, что оно будет передано без излишних задержек.
Переход от теории к практике стал возможен благодаря усилиям Ричарда Хэмминга, коллеги Шеннона по Bell Labs, получившего известность за открытие класса кодов «коды Хэмминга».
Хэмминг первым предложил «коды с исправлением ошибок» (Error-Correcting Code, ECC). Современные модификации этих кодов используются во всех системах хранения данных и для обмена между процессором и оперативной памятью. Один из их вариантов, коды Рида-Соломона применяются в компакт-дисках, позволяя воспроизводить записи без скрипов и шумов, вызванных царапинами и пылинками. Существует множество версий кодов, построенных «по мотивам» Хэмминга, они различаются алгоритмами кодирования и количеством проверочных битов. Особое значение подобные коды приобрели в связи с развитием дальней космической связи с межпланетными станциями.
Цель моей курсовой работы, является ознакомление с методами обнаружения ошибок и защиты информации с помощью корректирующих кодов. Эта проблема в настоящее время относится к числу наиболее актуальных проблем, т.к. при обработке, передачи и хранении информации мы стремимся к повышению ее надежности.
Объект: процесс кодирования информации.
Задачи:
-
Проанализировать пособия по теории информации и информационной безопасности.
-
Выявить формы представления кодирования информации.
-
Обнаружение ошибок (проблем).
-
Методы и способы исправления ошибок.
1 Кодирование информации
Современный ПК может обрабатывать различную информацию (числовую, текстовую, звуковую и видео). Вся информация в компьютере представлена в двоичном коде, т.е. Используется алфавит мощностью два. Это связанно, прежде всего, с тем, что удобно представлять в виде последовательности электрических импульсов (импульс отсутствует — 0, импульс есть — 1). Логическая последовательность нулей и единиц называется, машинным кодом.
1.1 Кодирование текстовой информации
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы — это возможные события): К = 2I 28 = 256, т.е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ — 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные, при помощи одной таблицы не будут правильно отображаться в другой кодировке.
В большинстве случаев о перекодировке текстовых документов заботится пользователь, а специальные программы — конвертеры, которые встроены в приложения.
Начиная с 1997г. последние версии Microsoft Windows Office поддерживают новую кодировку Unicode, которая на каждый символ отводит по 2 байта, а поэтому, можно закодировать не 256 символов, а 65536 различных символов.
1.2 Кодирование графической информации
В середине 50-х годов для больших ЭВМ, которые применялись в научных и военных исследованиях, впервые в графическом виде было реализовано представление данных. В настоящее время широко используются технологии обработки графической информации с помощью ПК.
Особенно интенсивно технология обработки графической информации с помощью компьютера стала развиваться в 80-х годах. Графическую информацию можно представлять в двух формах: аналоговой или дискретной. Живописное полотно, цвет которого изменяется непрерывно — это пример аналогового представления, а изображение, напечатанное при помощи струйного принтера и состоящее из отдельных точек разного цвета — это дискретное представление. Чем большее количество цветов используется (т. е. точка изображения может принимать больше возможных состояний), тем больше информации несет каждая точка, а, значит, увеличивается качество кодирования. Создание и хранение графических объектов возможно в нескольких видах — в виде векторного, фрактального или растрового изображения.
Отдельным предметом считается 3D (трехмерная) графика, в которой сочетаются векторный и растровый способы формирования изображений.
Если говорить о кодировании цветных графических изображений, то нужно рассмотреть принцип декомпозиции произвольного цвета на основные составляющие. Применяют несколько систем кодирования: HSB, RGB и CMYK.
1) Модель HSB характеризуется тремя компонентами: оттенок цвета (Hue), насыщенность цвета (Saturation) и яркость цвета (Brightness). Можно получить большое количество произвольных цветов, регулируя эти компоненты.
2) Принцип метода RGB заключается в следующем: известно, что любой цвет можно представить в виде комбинации трех цветов: красного (Red, R), зеленого (Green, G), синего (Blue, B). Другие цвета и их оттенки получаются за счет наличия или отсутствия этих составляющих.
3) Принцип метода CMYK. Эта цветовая модель используется при подготовке публикаций к печати. Каждому из основных цветов ставится в соответствие дополнительный цвет (дополняющий основной до белого).
Различают несколько режимов представления цветной графики:
1) полноцветный (TrueColor);
2) HighColor;
3) индексный.
При полноцветном режиме для кодирования яркости каждой из составляющих используют по 256 значений (восемь двоичных разрядов), то есть на кодирование цвета одного пикселя (в системе RGB) надо затратить 8*3=24 разряда. Это позволяет однозначно определять 16,5 млн цветов. Это довольно близко к чувствительности человеческого глаза. При кодировании с помощью системы CMYK для представления цветной графики надо иметь 8*4=32 двоичных разрядов.
Режим HighColor — это кодирование при помощи 16-разрядных двоичных чисел, то есть уменьшается количество двоичных разрядов при кодировании каждой точки. Но при этом значительно уменьшается диапазон кодируемых цветов.
При индексном кодировании цвета можно передать всего лишь 256 цветовых оттенков. Каждый цвет кодируется при помощи восьми бит данных. Но так как 256 значений не передают весь диапазон цветов, доступный человеческому глазу, то подразумевается, что к графическим данным прилагается палитра (справочная таблица), без которой воспроизведение будет неадекватным: море может получиться красным, а листья — синими. Сам код точки растра в данном случае означает не сам по себе цвет, а только его номер (индекс) в палитре. Отсюда и название режима — индексный.
Соответствие между количеством отображаемых цветов (К) и количеством бит для их кодировки (а) находиться по формуле: К = 2а («Таблица 1») .
«Таблица 1»
|
А |
К |
Достаточно для |
|
4 |
24 = 16 |
|
|
8 |
28 = 256 |
Рисованных изображений типа тех, что видим в мультфильмах, но недостаточно для изображений живой природы |
|
16 (HighColor) |
216 = 65536 |
Изображений, которые на картинках в журналах и на фотографиях |
|
24 (TrueColor) |
224 = 16 777 216 |
Обработки и передачи изображений, не уступающих по качеству наблюдаемым в живой природе |
1.3 Кодирование звуковой информации
С начала 90-х годов персональные компьютеры получили возможность работать со звуковой информацией. Каждый компьютер, имеющий звуковую плату, микрофон и колонки, может записывать, сохранять и воспроизводить звуковую информацию. Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда, тем он громче для человека, чем больше частота сигнала, тем выше тон. Программное обеспечение компьютера в настоящее время позволяет непрерывный звуковой сигнал преобразовывать в последовательность электрических импульсов, которые можно представить в двоичной форме.
Процесс преобразования звуковых волн в двоичный код в памяти компьютера:
Звуковая волна →Микрофон → Переменный электрический ток → Аудиоадаптер →Двоичный код → Память компьютера
Процесс воспроизведения звуковой информации, сохраненной в памяти компьютера:
Память компьютера → Двоичный код → Аудиоадаптер → Переменный электрический ток → Динамик → Звуковая волна
Аудиоадаптер (звуковая плата)– специальное устройство, подключаемое к компьютеру, предназначенное для преобразования электрических колебаний звуковой частоты в числовой двоичный код при вводе звука и для обратного преобразования (из числового кода в электрические колебания) при воспроизведении звука.
В процессе записи звука аудиоадаптер с определенным периодом измеряет амплитуду электрического тока и заносит в регистр двоичный код полученной величины.
Затем полученный код из регистра переписывается в оперативную память компьютера.
Качество компьютерного звука определяется характеристиками аудиоадаптера: частотой дискретизации и разрядностью.
Частота дискретизации – это количество измерений входного сигнала за 1 секунду.
Разрядность регистра– число бит в регистре аудиоадаптера.
2 Шум и защита от шума. Теория кодирования К.Шеннона
Термином «шум» называют разного рода помехи, искажающие передаваемый сигнал и приводящие к потере информации. Такие помехи возникают по техническим причинам: плохое качество линии связи, незащищенность друг от друга различных потоков информации, передаваемых по одним и тем же каналам. Например, при беседе по телефону, мы слышим шум и треск. В таких случаях необходима защита от шума. Способы защиты бывают самыми разными. Использование экранированного кабеля вместо «голого» провода; применение различных фильтров, отделяющих полезный сигнал от шума и т.п.
Клодом Шенноном была разработана специальная теория кодирования, дающая методы борьбы с шумом. Одна из важных идей этой теории состоит в том, что передаваемый по линии связи код должен быть избыточным. За счет этого потеря какой-то части информации при передаче может быть компенсирована. Например, если при разговоре по телефону вас плохо слышно, то, повторяя каждое слово дважды, вы имеете больше шансов на то, что собеседник поймет вас правильно.
Однако нельзя делать избыточность слишком большой. Это приведет к задержкам и удорожанию связи. Теория кодирования К. Шеннона как раз и позволяет получить такой код, который будет оптимальным. При этом избыточность передаваемой информации будет минимально возможной, а достоверность принятой информации — максимальной.
В современных системах цифровой связи часто применяется следующий прием борьбы с потерей информации. Все сообщение разбивается на порции — пакеты. Для каждого пакета вычисляется контрольная сумма (сумма двоичных цифр), которая передается вместе с данным пакетом. В месте приема заново вычисляется контрольная сумма принятого пакета, и если она не совпадает с первоначальной, то передача данного пакета повторяется. Так происходит пока исходная и конечная контрольные суммы не совпадут.
3 Способы обнаружения ошибок с их последующим исправлением
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
-
обнаружение ошибок в блоках данных и автоматический запрос повторной передачи поврежденных блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
-
обнаружение ошибок в блоках данных и отбрасывание поврежденных блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
-
Исправление ошибок применяется на физическом уровне.
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникших при передаче информации под влиянием помех, а так же при её хранении.
При записи в данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении её используют для того, чтобы обнаружить или исправить ошибки. Число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
Коды обнаружения ошибок в отличии от кодов исправляющих ошибки, могут только установить факт наличия ошибки.
Фактически любой код, исправляющий ошибки, может быть использован для их обнаружения. При этом он будет способен обнаружить большее число ошибок.
4 Основные понятия корректирующих кодов
Среди корректирующих кодов широко используются циклические коды, в ЭВМ эти коды применяются при последовательной передаче данных между ЭВМ и внешними устройствами, а также при передаче данных по каналам связи. Для исправления двух и более ошибок (d0 5) используются циклические коды БЧХ (Боуза — Чоудхури — Хоквингема), а также Рида-Соломона, которые широко используются в устройствах цифровой записи звука на магнитную ленту или оптические компакт-диски и позволяющие осуществлять коррекцию групповых ошибок. Способность кода обнаруживать и исправлять ошибки достигается за счет введений избыточности в кодовые комбинации, т.е. кодовым комбинациям из к двоичных информационных символов, поступающих на вход кодирующего устройства, соответствует на выходе последовательность из n двоичных символов (такой код называется (n, k) — кодом).
Если N0 = 2n-общее число кодовых комбинаций, а N = 2k — число разрешенных, то число запрещенных кодовых комбинаций равно
N0-N = 2n -2k.
При этом число ошибок, которое приводит к запрещенной кодовой комбинации равно (1).
 (1)
(1)
где S — кратность ошибки, т.е. количество искаженных символов в кодовой комбинации S = 0, 1, 2, …
Cni— сочетания из n элементов по i, вычисляемое, по формуле (2)
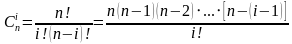 (2)
(2)
для S = 0; 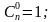
S = 1; 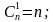
S = 2; 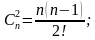
S= 3; 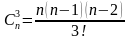 и т.д.
и т.д.
Для исправления S ошибок количество комбинаций кодового слова, составленного из m проверочных разрядов N = 2m, должно быть больше возможного числа ошибок (3), при этом количество обнаруживаемых ошибок в два раза больше, чем исправляемых
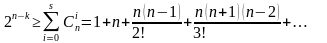 (3)
(3)
2m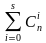 откуда
откуда 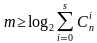 .
.
Для одиночной ошибки, как наиболее вероятной 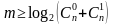 .
.
В зависимости от исходных данных кода (n или k) можно использовать
формулы (4).
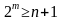 или
или 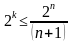 (4)
(4)
При этом, m = [log2(1+n)] или m = [log2 {(k+1)+ [log2(k+1)]}], где квадратные скобки обозначают округление до большего целого.
В таблице приведены соотношения между длиной кодовой комбинации и количеством информационных и контрольных разрядов для кода исправляющего одиночную ошибку, а также эффективность использования канала связи.
Для исправления двукратной ошибки (5).
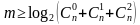 или
или 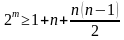 (5)
(5)
Введение избыточности в кодовые комбинации при использовании корректирующих кодов существенно снижает скорость передачи информации и эффективность использования канала связи.
Например, для кода (31, 26) скорость передачи информации равна
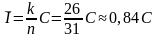 («Таблица 2»), т.е. скорость передачи уменьшается на 16%.
(«Таблица 2»), т.е. скорость передачи уменьшается на 16%.
«Таблица 2»
|
n |
7 |
10 |
15 |
31 |
63 |
127 |
255 |
|
k |
4 |
6 |
11 |
26 |
57 |
120 |
247 |
|
m |
3 |
4 |
4 |
5 |
6 |
7 |
8 |
|
|
0,57 |
0,6 |
0,75 |
0,84 |
0,9 |
0,95 |
0,97 |
Как видно из таблицы , чем больше n, тем эффективнее используется канал.
4.1 Линейные и групповые коды
Линейным называется код, в котором проверочные символы представляют собой линейные комбинации информационных.
Групповым называется код, который образует алгебраическую группу по отношению операции сложения по модулю два.
Свойство линейного кода: сумма (разность) кодовых векторов линейного кода дает вектор, принадлежащий этому коду.
Свойство группового кода: минимальное кодовое расстояние между кодовыми векторами равно минимальному весу ненулевых векторов. Вес кодового вектора равен числу единиц в кодовой комбинации.
Групповые коды удобно задавать при помощи матриц, размерность которых определяется параметрами k и n. Число строк равно k, а число столбцов равно n = k+m.(6).
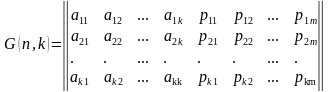 . (6)
. (6)
Коды, порождаемые этими матрицами, называются (n, k)-кодами, а соответствующие им матрицы порождающими (образующими, производящими). Порождающая матрица G состоит из информационной Ikk и проверочной Rkm матриц. Она является сжатым описанием линейного кода и может быть представлена в канонической (типовой) форме (7).
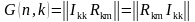 (7)
(7)
В качестве информационной матрицы удобно использовать единичную матрицу, ранг которой определяется количеством информационных разрядов (8).
 (8)
(8)
Строки единичной матрицы представляют собой линейно-независимые комбинации (базисные вектора), т.е. их по парное суммирование по модулю два не приводит к нулевой строке.
Строки порождающей матрицы представляют собой первые k комбинаций корректирующего кода, а остальные кодовые комбинации могут быть получены в результате суммирования по модулю два всевозможных сочетаний этих строк.
Столбцы добавочной матрицы Rkm определяют правила формирования проверок. Число единиц в каждой строке добавочной матрицы должно удовлетворять условию r1 d0-1, но число единиц определяет число сумматоров по модулю 2 в шифраторе и дешифраторе, и чем их больше, тем сложнее аппаратура.
Производящая матрица кода G(7,4) может иметь вид
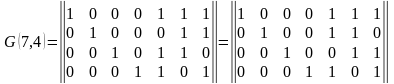 и т.д.
и т.д.
Процесс кодирования состоит во взаимно — однозначном соответствии к-разрядных информационных слов — I и n-разрядных кодовых слов – с(9)
c=IG (9)
Например: информационному слову I=[1 0 1 0] соответствует кодовое слово (10).
 (10)
(10)
При этом, информационная часть остается без изменений, а корректирующие разряды определяются путем суммирования по модулю два тех строк проверочной матрицы, номера которых совпадают с номерами разрядов, содержащих единицу в информационной части кода.
Процесс декодирования состоит в определении соответствия принятого кодового слова, переданному информационному. Это осуществляется с помощью проверочной матрицы H(n, k) (11).
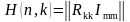 (11)
(11)
где RmkT -транспонированная проверочная матрица (поменять строки на столбцы); Imm— единичная матрица.
Для (7, 4)- кода проверочная матрица имеет вид (12).
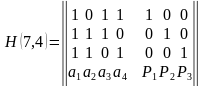 (12)
(12)
Между G(n ,k) и H(n, k) существует однозначная связь, т.к. они определяются в соответствии с правилами проверки, при этом для любого кодового слова должно выполняться равенство cHT= 0.
Строки проверочной матрицы определяют правила формирования проверок. Для (7, 4)-кода соответствует (13).
p1+a1+a2a4 = S1 ;
p2+a1+a2a3 = S2 ; (13)
p3+a1+a3a4 = S3 .
Полученный синдром сравниваем со столбцами матрицы и определяем разряд, в котором произошла ошибка, номер столбца равен номеру ошибочного разряда. Для исправления ошибки ошибочный бит необходимо проинвертировать.
4.2 Код Хемминга
Код Хэмминга относится к классу линейных кодов и представляет собой систематический код – код, в котором информационные и контрольные биты, расположены на строго определенных местах в кодовой комбинации.
Код Хэмминга, как и любой (n, k)- код, содержит к информационных и m = n-k избыточных (проверочных) бит.
Избыточная часть кода строится т.о. чтобы можно было при декодировании не только установить наличие ошибки но, и указать номер позиции, в которой произошла ошибка, а значит, и исправить ее, инвертировав значение соответствующего бита.
Существуют различные методы реализации кода Хэмминга и кодов которые являются модификацией кода Хэмминга. Рассмотрим алгоритм построения кода для исправления одиночной ошибки.
-
По заданному количеству информационных символов — k, либо информационных комбинаций N = 2k , используя соотношения (14).
n = k+m, 2n (n+1)2k и 2m n+1 (14)
m = [log2 {(k+1)+ [log2(k+1)]}]
вычисляют основные параметры кода n и m.
2. Определяем рабочие и контрольные позиции кодовой комбинации. Номера контрольных позиций определяются по закону 2i,где i=1, 2, 3,… т.е. они равны 1, 2, 4, 8, 16,… а остальные позиции являются рабочими.
3. Определяем значения контрольных разрядов (0 или 1 ) при помощи многократных проверок кодовой комбинации на четность. Количество проверок равно m = n-k. В каждую проверку включается один контрольный и определенные проверочные биты. Если результат проверки дает четное число, то контрольному биту присваивается значение — 0, в противном случае — 1. Номера информационных бит, включаемых в каждую проверку, определяются по двоичному коду натуральных n –чисел разрядностью – m или при помощи проверочной матрицы H(mn), столбцы которой представляют запись в двоичной системе всех целых чисел от 1 до (2k –1) перечисленных в возрастающем порядке. Для m = 3 проверочная матрица имеет вид (15).
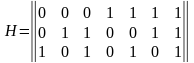 (15 )
(15 )
Количество разрядов m — определяет количество проверок («Таблица 3»).
В первую проверку включают коэффициенты, содержащие 1 в младшем (первом) разряде, т.е. b1, b3, b5 и т.д.
Во вторую проверку включают коэффициенты, содержащие 1 во втором разряде, т.е. b2, b3, b6 и т.д.
В третью проверку — коэффициенты которые содержат 1 в третьем разряде и т.д.
«Таблица 3»
|
Десятичные числа (номера разрядов кодовой комбинации) |
Двоичные числа и их разряды |
||
|
3 |
2 |
1 |
|
|
1 2 3 4 5 6 7 |
0 0 0 1 1 1 1 |
0 1 1 0 0 1 1 |
1 0 1 0 1 0 1 |
Для обнаружения и исправления ошибки составляются аналогичные проверки на четность контрольных сумм, результатом которых является двоичное (n-k) -разрядное число, называемое синдромом и указывающим на положение ошибки, т.е. номер ошибочной позиции, который определяется по двоичной записи числа, либо по проверочной матрице.
Для исправления ошибки необходимо проинвертировать бит в ошибочной позиции. Для исправления одиночной ошибки и обнаружения двойной используют дополнительную проверку на четность. Если при исправлении ошибки контроль на четность фиксирует ошибку, то значит в кодовой комбинации две ошибки.
В ЭВМ код Хэмминга чаще всего используется для обнаружения и исправления ошибок в ОП, памяти с обнаружением и исправлением ошибок ECCMemory (ErrorCheckingandCorrecting). Код Хэмминга используется как при параллельной, так и при последовательной записи. В ЭВМ значительная часть интенсивности потока ошибок приходится на ОП. Причинами постоянных неисправностей являются отказы ИС, а случайных изменение содержимого ОП за счет флуктуации питающего напряжения, кратковременных помех и излучений. Неисправность может быть в одном бите, линии выборки разряда, слова либо всей ИС. Сбой может возникнуть при формировании кода (параллельного), адреса или данных, поэтому защищать необходимо и то и др. Обычно дешифратор адреса встроен в микро схему и недоступен для потребителя. Наиболее часто ошибки дают ячейки памяти ЗУ, поэтому главным образом защищают записываемые и считываемые данные.
Наибольшее применение в ЗУ нашли коды Хэмминга с dmin=4, исправляющие одиночные ошибки и обнаруживающие двойные.
Проверочные символы записываются либо в основное, либо специальное ЗУ. Для каждого записываемого информационного слова (а не байта, как при контроле по паритету) по определенным правилам вычисляется функция свертки, результат которой разрядностью в несколько бит также записывается в память. Для 16-ти разрядного информационного слова используется 6 дополнительных бит (32 — 7 бит, 64 – 8 бит). При считывании информации схема контроля («Рис. 1»), используя избыточные биты, позволяет обнаружить ошибки различной кратности или исправить одиночную ошибку. Возможны различные варианты поведения системы:
-
автоматическое исправление ошибки без уведомления системы;
-
исправление однократной ошибки и уведомление системы только о многократных ошибках;
-
не исправление ошибки, а только уведомление системы об ошибках;
Модуль памяти со встроенной схемой исправления ошибок – EOS 72/64 (ECConSimm). Аналог микросхема к 555 вж 1 -это 16 разрядная схема с обнаружением и исправлением ошибок (ОИО) по коду Хэмминга G(22, 16), использование которой позволяет исправить однократные ошибки и обнаружить все двух кратные ошибки в ЗУ.
Избыточные (контрольные) разряды позволяют обнаружить и исправить ошибки в ЗУ в процессе записи и хранения информации.
В составе ВЖ-1 используются 16 информационных и 6 контрольных разрядов. (DB — информационное слово, CB — контрольное слово).
При записи осуществляется формирование кода, состоящего из 16 информационных и 6 контрольных разрядов, представляющих результат суммирование по модулю 2 восьми информационных разрядов в соответствии с кодом Хэмминга. Сформированные контрольные разряды вместе с информационными поступают на схему и записываются в ЗУ.
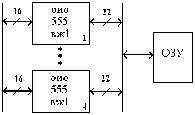
«Рис. 1» — схема контроля
При считывании шестнадцатиразрядное слово декодируется, восстанавливаясь вместе с 6 разрядным словом контрольным, поступают на схему сравнения и контроля. Если достигнуто равенство всех контрольных разрядов и двоичных слов, то ошибки нет.
Любая однократная ошибка в 16 разрядном слове данных изменяет 3 байта в 6 разрядном контрольном слове. Обнаруженный ошибочный бит инвертируется.
Заключение
Цель моей работы достигнута: я познакомился с методами обнаружения ошибок и защиты информации с помощью корректирующих кодов. Рассмотрел циклические коды, исправляющие более 2 ошибок (к ним относятся коды БЧХ (Боуза — Чоудхури — Хоквингема) и Рида-Соломона) и линейные коды (коды Хемминга). Все они основываются на избыточности информации.
Научились находить эту избыточность с помощью формул. Узнал, что любой код, исправляющий ошибки, может быть использован для их обнаружения. При этом он будет способен обнаружить большее число ошибок.
Познакомился с различными способами кодирования различных видов информации: текстовой, графической и звуковой.
Список литературы
-
Недвоичные арифметические корректирующие коды, проблемы передачи информации / В.М. Гриценко — 4-е изд. – 1969. – 19 – 27 с.
-
Помехоустойчивые коды в системах связи / Б.М. Золотник — M.: Радио и связь, 1989.—232 c.
-
Информационная безопасность. Лабораторный практикум: учебное пособие / А.В. Бабаш, Е.К. Баранова, Ю.Н. Мельникова. — М.: КНОРУС, 2012. – 136 с.
-
Теория передачи сигналов / Кловский Д.Д. — M.: Cвязь, 1984.
-
Цифровое кодирование звуковых сигналов / Ковалгин Ю.A., Вологдин Э.И. — Изд-во Kорона-принт, 2004. – 240с.
-
Курс теории информации / Колесников B.Д., Полтырев Г.Ш. — M.: Наука, 1982. 416 с.
-
Микропроцессорные кодеры и декодеры / В.М. Муттер, Г.A. Петров и др.—M.: Радио и связь, 1991.—184 с.
-
Экономное кодирование дискретной информации / Семенюк В. В. – СПб: СПбГИТМО (ТУ), 2001. – 115 с.
Подборка по базе: Самостоятельная работа Тема 1.4.docx, ДЛЯ ЗАЛИВКИ Окуджава. Военная тематика.docx, ОГП Тема №1.1. «Основы морально.docx, Педагогика. Тема 5..docx, Действия спасательной группы (пожарного расчета) в ходе проведен, 56 тема Яременко Е.А. Бухгалтерский финансовый баланс как источн, ПСП тема №11.2.doc, Практическая работа №1 Тема_ «Особенности содержания обновленных, АСР тема 3.doc, Практическая работа №1 Тема_ «Особенности содержания обновленных
Тема 3 Исправление ошибок в программном коде информационной системы в процессе эксплуатации
1 Основные задачи сопровождения информационной системы
Сопровождение системы защиты информации предприятия – это комплекс регламентных мероприятий, направленных на поддержание уровня её защищённости в соответствии с требованиями. От эффективности этих мероприятий зависит сохранность конфиденциальной информации и непрерывность бизнес-процессов. Данный этап работы по защите информации является не менее важным, чем сам процесс организации защиты.
Сопровождение информационной системы включает в себя:
управление (создание/удаление/настройка доступа) учетными записями всех пользователей, поддержание правил разграничения доступа;
управление СЗИ, в том числе параметрами настройки ПО и при необходимости восстановление их работоспособности;
установка обновлений программного обеспечения, в том числе программное обеспечение СЗИ;
изменение эксплуатационной документации и организационно-распорядительных документов по защите информации;
корректировки базовой конфигурации ИС и системы её защиты;
проведение повторной аттестации ИС или дополнительных аттестационных испытаний при необходимости;
периодический контроль уровня защищенности информации в ИС;
периодический контроль эффективности работы СЗИ, в том числе устранение ошибок и недостатков в её функционировании;
периодический контроль изменения угроз безопасности информации в процессе эксплуатации ИС и оперативное принятие мер защиты информации при возникновении новых угроз.
Сопровождение информационной системы позволяет максимально оперативно решать вопросы, которые могут возникнуть во время её использования, при изменении самой системы (частично или полностью). Высококвалифицированные специалисты нашей компании помогут вам в решении этой задачи. 2 Принципы тестирования информационных систем
2 Принципы тестирования информационных систем
Тестирование — очень важный и трудоемкий этап процесса разработки программного обеспечения, так как он позволяет выявить подавляющее большинство ошибок, допущенных при составлении программ.
Процесс разработки программного обеспечения предполагает три стадии тестирования:
·автономное тестирование компонентов программного обеспечения;
·комплексное тестирование разрабатываемого программного обеспечения;
·системное или оценочное тестирование на соответствие основным критериям качества.
Для повышения качества тестирования рекомендуется соблюдать следующие основные принципы:
·предполагаемые результаты должны быть известны до тестирования;
·следует избегать тестирования программы автором;
·досконально изучать результаты каждого теста;
·необходимо проверять работу программы на неверных данных;
·вероятность наличия необнаруженных ошибок в части программы пропорциональна числу ошибок, уже обнаруженных в этой части.
Формирование набора тестов имеет большое значение, поскольку тестирование является одним из наиболее трудоемких этапов (от 30 до 60 % общей трудоемкости) создания программного продукта. Существуют два принципиально разных подхода к формированию тестовых наборов – структурный и функциональный.
Структурный подход базируется на том, что известны алгоритмы работы программы. В основе структурного тестирования лежит концепция максимально полного тестирования всех маршрутов программы.
Функциональный подход основывается на том, что алгоритм работы программного обеспечения не известен. Тесты строят, опираясь на функциональные спецификации. Программа рассматривается как «черный ящик», и целью тестирования является выяснение обстоятельств, в которых поведение программы не соответствует требованиям.
Опытные отладчики обнаруживают ошибки путём сравнения шаблонов тестовых выходных данных с выходными данными тестируемых систем. Чтобы определить местоположение ошибки, необходимы знания о типах ошибок, шаблонах выходных данных, языке и процессе программирования. Очень важны знания о процессе разработке программного обеспечения.
3 Классификация ошибочных ситуаций
Модели ошибок описывают классы ошибок, которые можно сделать при разработке целевой программы. Классификация ошибочных ситуаций представлена в таблице Таблица 1.
Таблица 1 — Описание ошибочных ситуаций
| № | Название | Описание | Методы | Примеры |
| 1 | Ошибки способа обработки аргументов | Целевая операция имеет несколько вариантов работы, выбор которых зависит от значений аргументов. Ошибка состоит в отсутствии одного из вариантов работы или в выборе ошибочного для некоторых значений аргументов. | — domain testing;
— partition testing; — тестирование граничных значений. |
a. Операция вычисления абсолютной величины, работает по-разному для аргумента x >= 0 и для x < 0.
Ошибка может состоять в том, что случай x < 0 совсем забыли написать. b. Операция вычисления произведения элементов массива. Ошибка может состоять в том, что пустые массивы обрабатываются неправильно — обычно произведение пустого множества чисел считают равным 1. |
| 2 | Ошибки потока управления | Ошибка состоит в неправильном переходе или в неправильном условии перехода по потоку управления. | — flow graph testing;
— path testing. |
a. Неправильный переход.
b. Неверное условие. Вычисление суммы элементов массива. Ошибка в условии цикла может привести к неучету первого или последнего элементов. |
| 3 | Ошибки потока управления между подсистемами | Похожи на ошибки потока управления, но ориентировано на системное, а не компонентное тестирование.
Виды ошибок: — неправильные переходы между компонентами программы; — забыли реализовать некоторую операцию; — забыли вставить использование некоторого компонента. |
— transaction flow testing;
— use case based testing. |
Набор текста вместо числа в некотором поле может приводит к падению программы. |
| 4 | Ошибки потока данных | Неправильные зависимости между данными программы, пропущенные связи. | Data flow testing. | — Чтение «чужих» данных
— Чтение несогласованных данных. |
| 5 | Ошибки обработки формальных текстов | Ошибки состоят в нераспознавании или неправильной обработке некорректных текстов, отнесении правильных тестов к некорректным, неправильной обработке корректных текстов. | Syntax testing. | — компиляторы;
— интерпретаторы; — обработчики запросов. |
| 6 | Ошибки поведения, зависящего от состояния | Предполагается, что поведение программы существенно зависит ранее сделанных обращений к ней. Ошибки: переходы в неправильные состояния, неправильная работа в некотором состоянии. | Нажатие на кнопку «Возврат денег» в автомате для продажи газет может привести к выдаче денег, даже если человек до этого их не платил. |
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5