
Тема может и банальная, но когда программа начинает работать как то не так, и вообще вести себя очень странно, часто приходится читать логи. И много логов, особенно если нет возможности отлаживать программу и не получается воспроизвести ошибку. Наверно каждый выработал для себя какие то правила, что, как и когда логировать. Ниже я хочу рассмотреть несколько правил записи сообщений в лог, а также будет небольшое сравнение библиотек логирования для языков php, ruby и go. Сборщики логов и системы доставки не будут рассматриваться сознательно (их обсуждали уже много раз).
Есть такая linux утилита, а также по совместительству сетевой протокол под названием syslog. И есть целый набор RFC посвящённый syslog, один из них описывает уровни логирования https://en.wikipedia.org/wiki/Syslog#Severity_level (https://tools.ietf.org/html/rfc5424). Согласно rfc 5424 для syslog определено 8 уровней логирования, для которых также дается краткое описание. Данные уровни логирования были переняты многими популярными логерами для разных языков программирования. Например, http://www.php-fig.org/psr/psr-3/ определяет те же самые 8 уровней логирования, а стандартный Ruby logger использует немного сокращённый набор из 5 уровней. Несмотря на формальное указание в каких случаях должен быть использован тот или иной уровень логов, зачастую используется комбинация вроде debug/info/fatal — первый для логирования во время разработки и тестирования, второй и третий в расчёте на продакшен. Потом в какой то момент на продакшене начинает происходить что то не понятное и вдруг оказывается, что info логов не хватает — бежим включать debug. И если они не сильно нагружают систему, то зачастую так и остаются включенными в продакшен окружении. По факту остаётся два сценария, когда нужно иметь логи:
- что-то происходит и надо знать что
- что-то сломалось и нужно дополнительно активировать триггер
По триггеру может происходить: уведомление об ошибке на email, аварийное завершение или перезапуск программы или другие типичные сценарии.
В языке Go в котором всё упрощено до предела, стандартный логер тоже прилично покромсали и оставили следующие варианты:
- Fatal — вывод в лог и немедленный выход в ОС.
- Panic — вывод в лог и возбуждение «паники» (аналог исключения)
- Print — просто выводит сообщение в лог
Запутаться, что использовать в конкретной ситуации уже практически невозможно. Но сообщения в таком сильно усеченном виде сложно анализировать, а также настраивать системы оповещения, типично реагирующих на какой нибудь AlertFatalError в тексте лога.
Я часто при написании программы с нуля повсеместно использую debug уровень для логирования с расчётом, что на продакшене будет выставлен уровень логирования info и тем самым сократится зашумлённость сообщениями. Но в таком подходе часто возникают ситуация, что логов вдруг становится не хватать. Трудно угадать, какая информация понадобиться, что бы отловить редкий баг. Возможно рационально всегда использовать по умолчанию уровень info, а в обработчиках ошибок уровень error и выше. Но если у вас сотни и больше сообщений лога в секунду, то тогда наверно есть смысл тонкой настройки между info/debug. В таких ситуациях уже имеет смысл использовать специализированные решения что бы не просаживать производительность.
Есть ещё тонкий момент, когда вы пишите что то вроде logger.debug(entity.values) — то при выставленном уровне логирования выше debug содержимое entity.values не попадёт в лог, но оно каждый раз будет вычисляться отъедая ресурсы. В Ruby логеру можно передать вместо строки сообщения блок кода: Logger.debug { entity.values }. В таком случае вычисления будут происходить только при выставленном соответствующем уровне лога. В языке Go для реализации ленивого вычисления в логер можно передать объект поддерживающий интерфейс Stringer.
После того, как разобрались с использованием уровней логов, нужно ещё уметь связывать разрозненные сообщения, особенно это актуально для многопоточных приложений или связанных между собой отдельных сервисов, когда в логах все сообщения оказываются вперемешку.
Типичный формат строки сообщения в логе можно условно разделить на следующие составные части:
[system info] + [message] + [context]Где:
system info: метка времени, ид процесса, ид потока и другая служебная информацияmessage: текст сообщенияcontext: любая дополнительная информация, контекст может быть общим для сообщений в рамках какой то операции.
Для того, чтобы связать пары запросответ часто используется http заголовок X-Request-ID. Такой заголовок может сгенерировать клиент, или он может быть сгенерирован на стороне сервера. Добавив его в контекст каждой строчки лога появится возможность лёгким движением руки найти все сообщения возникшие в рамках выполнения конкретного запроса. А в случае распределенных систем, заголовок можно передавать дальше по цепочке сетевых вызовов.
Но с единым контекстом в рамках запроса возникает проблема с различными ORM, http клиентами или другими сервисамибиблиотеками, которые живут своей жизнью. И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
reqLog := log.WithField("requestID", requestID)После этого такой экземпляр логера можно передать как зависимость в другие объекты. Но отсутствие стандартизированного интерфейса логирования (например как psr-3 в php) провоцирует создателей библиотек хардкодить малосовместимые реализации логеров. Поэтому если вы пишите свою библиотеку на Go и в ней есть компонент логирования, не забудьте предусмотреть интерфейс для замены логера на пользовательский.
Резюмируя:
- Логируйте с избытком. Никогда заранее не известно сколько и какой информации в логах понадобится в критический момент.
- Восемь уровней логирования — вам действительно столько надо? По опыту должно хватить максимум 3-4, и то при условии, что для них настроены обработчики событий.
- По возможности используйте ленивые вычисления для вывод сообщений в лог
- Всегда добавляйте текущий контекст в каждое сообщение лога, как минимум requestID.
- По возможности настраивайте сторонние библиотеки таким образом, чтобы они использовали логер с текущим контекстом запроса.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Насколько подробно вы покрываете приложение логами?
8.93%
У меня всё работает, логи не нужны (или логи пишет только фрэймворк)
35
14.54%
Логирую только ошибки
57
36.22%
Логирую «интересные» места
142
19.13%
Стараюсь покрыть логами всё приложение
75
21.17%
Использую несколько уровней логирования с настроенными уведомлениями в зависимости от типа ошибки
83
Проголосовали 392 пользователя.
Воздержались 130 пользователей.
Учимся правильно вести журналы в PHP-приложении, чтобы потом быстро находить и исправлять баги
https://gbcdn.mrgcdn.ru/uploads/post/2755/og_image/efacb053428ba430e214ab2a3bd538f6.png

Людям свойственно ошибаться. Это относится не только к разработчикам, но и к пользователям. В ходе разработки мы контролируем процесс и можем разобраться в неправильном поведении программы простой отладкой. А вот расследовать случай, который произошёл в production-окружении, не всегда просто. В таких ситуациях на помощь приходят журналы. И чтобы от них действительно была польза, их нужно вести правильно.
Логирование — это процесс ведения таких журналов. Помогает обнаружить скрытые ошибки, разобраться в проблемах пользователей и просто понять, что произошло на самом деле. В простейшей реализации такие журналы пишутся в текстовом файле и содержат точное время и описание произошедшего события. В логировании есть множество подходов и давно определены лучшие практики — это хорошо для нас.
В этой статье разберёмся, как правильно организовать ведение журналов в PHP-приложении, как эффективно с ними взаимодействовать и какие библиотеки и инструменты могут быть полезны.
Стандарт PSR-3. Уровни логирования
PSR — это свод рекомендаций для PHP-разработчиков. Он содержит советы по оформлению кода, некоторые интерфейсы и другие рекомендации. Один из его документов (PSR-3) посвящён реализации логера.
Знакомство с этими рекомендациями предлагаю начать с уровней логирования, которые в них предлагаются.
<?php namespace PsrLog; class LogLevel { const EMERGENCY = 'emergency'; const ALERT = 'alert'; const CRITICAL = 'critical'; const ERROR = 'error'; const WARNING = 'warning'; const NOTICE = 'notice'; const INFO = 'info'; const DEBUG = 'debug'; }
PSR-3 определяет 8 уровней сообщений. Если их использовать правильно, искать ошибки станет проще и получится оперативнее реагировать на инциденты. Давайте разберёмся, как выбрать уровень:
- DEBUG — отладочная информация, подробно раскрывающая детали события;
- INFO — любые интересные события. Например, когда пользователь авторизовался;
- NOTICE — важные события в рамках ожидаемого поведения;
- WARNING — исключительные ситуации, не являющиеся ошибками. Например, использование устаревшего метода, неправильный запрос в API;
- ERROR — ошибки, которые следует отслеживать, но они не требуют срочного исправления;
- CRITICAL — критическое состояние или событие. Например, недоступность компонента, неожиданное исключение (Exception);
- ALERT — ошибка или событие, требующие срочных действий. Например, когда база данных недоступна;
- EMERGENCY — ситуация, когда программа или система полностью выведены из строя.
Чтобы использовать эти уровни, достаточно добавлять их название к строке каждой записи журнала. Например:
[2021-01-01 12:10:35] website.INFO: User has changed his password
На уровни ALERT и EMERGENCY часто ставят дополнительное информирование, например по SMS. По INFO можно легко восстановить последовательность действий пользователя, по DEBUG — узнать точные значения переменных, результат работы функции в определённом месте и прочее.
PSR-3. Интерфейс для класса-логера
Помимо класса с уровнями, PSR-3 предлагает нам интерфейс для реализации собственных логеров — LoggerInterface. Соблюдать его очень полезно, так как большинство существующих библиотек его поддерживает. Если вы решите заменить свой логер на другой, просто подключите вместо него новый класс.
LoggerInterface требует реализации методов ведения журнала — и чтобы она учитывала уровни, которые мы разобрали выше. Создадим собственный класс-логер, который будет соответствовать этому интерфейсу и делать записи в файл.
Для начала загрузим код стандарта PSR-3 с помощью Composer.
composer req psr/log
В загруженном пакете содержится несколько классов, трейтов и интерфейсов. Среди них — LogLevel, который мы разобрали выше, и интересующий нас в данный момент LoggerInterface. Давайте создадим новый класс, реализующий этот интерфейс. Важно: убедитесь, что у вас подключён класс-автозагрузчик (vendor/autoload.php).
<?php // index.php // Автозагрузчик Composer require_once 'vendor/autoload.php'; // Наш новый класс-логер require_once 'src/FileLogger.php';
<?php // src/FileLogger.php // Если `use` не добавился автоматически // - обязательно добавьте его самостоятельно use PsrLogLoggerInterface; // Наследуем интерфейс логера от PSR-3 class FileLogger implements LoggerInterface { // ... }
Класс мы создали. Но чтобы он удовлетворял требованиям стандарта, нужно написать все методы, описанные в интерфейсе. Самый важный из них — log. В нём будет указана основная логика записи в файл.
class FileLogger implements LoggerInterface { // ... public function log($level, $message, array $context = []): void { // Текущая дата в формате 1970-12-01 23:59:59 $dateFormatted = (new DateTime())->format('Y-m-d H:i:s'); // Собираем сообщение, подставив дату, уровень и текст из аргумента $message = sprintf( '[%s] %s: %s%s', $dateFormatted, $level, $message, PHP_EOL // Перенос строки ); // Пишем в файл gb.log file_put_contents('gb.log', $message, FILE_APPEND); // FILE_APPEND - позволяет добавлять записи к существующим, // не затирая старые логи } // ... }
Для полного удовлетворения интерфейса LoggerInterface нам осталось написать реализацию для методов emergency, alert, critical, error, warning, notice, info и debug, которые соответствуют уровням (их мы разобрали выше). Их реализация сводится к очень простому принципу: мы вызываем метод log, передав в него необходимый уровень.
class FileLogger implements LoggerInterface { // ... public function emergency($message, array $context = []): void { // Передаем уровень из класса LogLevel $this->log(LogLevel::EMERGENCY, $message, $context); } public function alert($message, array $context = []): void { $this->log(LogLevel::ALERT, $message, $context); } // и так далее // ... }
Использование логера
Теперь, когда наш класс реализует интерфейс, предложенный стандартом PSR-3, мы можем легко задействовать его в любом месте. Например, в файле index.php:
<?php // index.php // Автозагрузчик Composer require_once 'vendor/autoload.php'; // Наш новый класс-логер require_once 'src/FileLogger.php'; $logger = new FileLogger(); $logger->debug('Message from index.php');
Или в любом другом классе.
<?php use PsrLogLoggerInterface; class ExampleService { /** @var LoggerInterface */ private $logger; public function __construct(LoggerInterface $logger) { $this->logger = $logger; } public function doSomeAction(): void { // выполняем какие-либо действия $this->logger->debug('Message from ExampleService'); } }
Обратите внимание: в качестве типа аргумента конструктора мы указываем не конечную реализацию (FileLogger), а именно интерфейс стандарта PSR-3. Это удобно, потому что позволяет легко заменять применяемый логер на любой другой, поддерживающий этот интерфейс.
Контекст
Вы могли заметить, что все методы интерфейса LoggerInterface содержат аргумент $context. Зачем он нужен?
Контекст предназначен для передачи вспомогательной и зачастую динамичной информации. Например, если вы делаете отладочную запись (уровень debug), можно передать в контекст значение переменной.
Чтобы применять этот аргумент, нам нужно поддержать его в методе log. Давайте доработаем его, учитывая, что $context — массив.
<?php class FileLogger implements LoggerInterface { // ... public function log($level, $message, array $context = []): void { $dateFormatted = (new DateTime())->format('Y-m-d H:i:s'); // Преобразуем $context в формат json $contextString = json_encode($context); $message = sprintf( '[%s] %s: %s %s%s', $dateFormatted, $level, $message, $contextString, // Добавляем контекст к строке лога PHP_EOL ); file_put_contents('gb.log', $message, FILE_APPEND); } // ... }
Теперь в любом месте вызова логера мы можем передать вторым аргументом массив дополнительной информации.
<?php // index.php //... $userName = 'GeekBrains'; $userEmail = 'user@gb.ru'; $logger = new FileLogger(); $logger->debug('Message from index.php', [ 'user_name' => $userName, 'user_email' => $userEmail, ]);
В результате мы получим запись следующего вида:
[2021-09-02 13:00:24] debug: Message from index.php {"user_name":"GeekBrains","user_email":"user@gb.ru"}
Касательно контекста действует одно простое правило: любая динамическая информация должна передаваться в нём, но не в сообщении. То есть, если вы формируете сообщение в лог с помощью sprintf или конкатенацией строчных переменных, — скорее всего, эту информацию можно вынести в контекст. Соблюдая это правило, проще искать что-то в журнале, потому что не приходится предугадывать (или вычислять) значения переменных.
Библиотека Monolog
Несмотря на всю простоту принципа ведения журналов, в этой области широкий простор для модификаций. Мы могли бы поддержать другие форматы записей, реализовать отправку SMS или элементарно дать возможность менять имя конечного файла логов.
Здорово, что всё это уже реализовано в большинстве библиотек. Одна из самых распространённых – monolog.
Среди весомых преимуществ этого пакета:
- полная поддержка PSR-3;
- поддержка разных принципов обработки логов в зависимости от уровня;
- поддержка имён каналов (имена логеров);
- очень широкая поддержка фреймворков.
Чтобы начать использовать этот прекрасный инструмент, установим его с помощью Composer.
composer req monolog/monolog
Использование Monolog
Работа библиотеки monolog основывается на обработчиках. Они позволяют задавать конкретное поведение в ответ на события логирования. Например: запись в файл — это специальный обработчик, который называется StreamHandler. Давайте заменим использование нашего класса на загруженную библиотеку.
<?php // index.php use MonologLogger; use MonologHandlerStreamHandler; // Автозагрузчик Composer require_once 'vendor/autoload.php'; // В качестве аргумента передаем имя канала $logger = new Logger('gb-demo'); // Подключаем обработчик. В качестве аргумента у StreamHandler - путь к файлу $logger->pushHandler(new StreamHandler('gb.log')); // Далее все оставляем, как было $userName = 'GeekBrains'; $userEmail = 'user@gb.ru'; $logger->debug('Message from index.php', [ 'user_name' => $userName, 'user_email' => $userEmail, ]);
Если мы запустим этот код, в файле gb.log появится запись следующего вида:
[2021-09-02T13:16:14.122686+00:00] gb-demo.DEBUG: Message from index.php {"user_name":"GeekBrains","user_email":"user@gb.ru"} []
Очень похоже на то, что было у нас ранее, кроме добавления имени канала (gb-demo).
Важная особенность обработчиков monolog: им можно задать уровень, на котором они работают. Например, чтобы писать все ошибки в отдельный файл.
<?php // index.php use MonologHandlerStreamHandler; use MonologLogger; use PsrLogLogLevel; // ... $logger = new Logger('gb-demo'); $logger->pushHandler(new StreamHandler('gb.log')); $logger->pushHandler(new StreamHandler('errors.log', LogLevel::ERROR)); // ... $logger->emergency('It is not even an error. It is EMERGENCY!!!');
Подключённый на уровень ERROR обработчик будет принимать на себя все записи уровня ERROR и выше. Поэтому вызов метода emergency попадает в оба файла: gb.log и errors.log
Такое простое разделение записей по уровням значительно упрощает для нас реагирование на ошибки. Ведь больше не нужно искать их среди всех записей в журнале. Это простая и полезная функция.
Все записи от одного запроса
Когда мы разрабатываем проект, журналы читаются очень просто, они последовательны и ясны. Но когда продуктом пользуются несколько человек, логи могут перемешиваться и больше запутывать, чем помогать. Для решения этой проблемы есть простой трюк. Вместо имени канала (логера) используйте уникальный идентификатор сессии. Получить его можно с помощью встроенной функции session_id(). При этом сессия должна быть обязательно запущена с помощью session_start()
Рассмотрим пример реализации такого приёма:
<?php // index.php // Запускаем сессию session_start(); // ... // Передаем id сессии в название канала $logger = new Logger(session_id()); // ...
Что нам даёт такая простая доработка? Важную возможность — группировать все записи запросам пользователя.
// Это записи от первого запроса [2021-09-02T13:35:54.155043+00:00] b30m8k1fvmf638au7ph0edb3o5.DEBUG: Message from index.php {"user_name":"GeekBrains","user_email":"user@gb.ru"} [] [2021-09-02T13:35:54.156800+00:00] b30m8k1fvmf638au7ph0edb3o5.EMERGENCY: It is not even an error. It is EMERGENCY!!! [] [] // А это записи от второго запроса. У них отличаются названия каналов [2021-09-02T13:36:03.528474+00:00] u7fi04mn99h0timg148rles1um.DEBUG: Message from index.php {"user_name":"GeekBrains","user_email":"user@gb.ru"} [] [2021-09-02T13:36:03.529421+00:00] u7fi04mn99h0timg148rles1um.EMERGENCY: It is not even an error. It is EMERGENCY!!! [] []
Что дальше?
Monolog поддерживает множество полезных готовых обработчиков, на которые стоит обратить внимание:
- TelegramBotHandler — отправляет записи в Telegram от имени бота. Пригодится для высоких уровней логирования;
- SlackHandler — похож на предыдущий, но отправляет записи в Slack;
- SwiftMailerHandler — позволяет отправлять записи по email;
- ChromePHPHandler – даёт доступ к журналам прямо из браузера Chrome в режиме Live.
Заключение
Логирование поможет исправлять ошибки на ранних этапах разработки и быть уверенными, что ничего не сломалось в новой версии кода. А ещё расследовать случаи ваших пользователей и иметь общее видение проекта.
Главное — помнить простые правила:
- Следование PSR-3 позволит легче заменять классы-логеры в вашем коде и использовать внешние библиотеки.
- Разные уровни логирования помогут сосредоточиться на важном.
- Отделение динамической информации в контекст упростит поиск по журналам.
- Библиотека Monolog реализует практически все возможные хотелки. Обязательно изучите её.
- С помощью идентификатора сессии можно разделить записи в журналах по каждому запросу.
- Лучше писать много лишних логов, чем не дописать один важный.
Как разобраться с логированием: гайд для начинающих
Этот материал мы ориентировали на тех, кто в первый раз сталкивается с логированием серверных служб и web-серверов. Познакомим с уровнями логирования, расскажем об основных типах логов и перечислим инструменты для работы с ними.
Зачем оно вообще нужно, это логирование?
На анализе логов базируется работа большинства ИТ-специалистов. Администраторы ищут в файлах логирования причины сбоя сервиса. Разработчики опираются на логи, чтобы локализовать и устранить ошибки приложения или веб-сайта. Служба безопасности по логам, как по физическим уликам, определяет вид взлома, оценивает нанесенный ущерб и даже может идентифицировать взломщика. Вот почему логирование мы рекомендуем отладить в первую очередь: в любой непонятной ситуации ответ на вопрос вы будете искать в логах!

Уровни логирования
В идеале логи пишутся во время работы всех IT-систем, однако если писать все подряд и «складывать в кучу», полезная информация превратится в хаос. Чтобы упростить поиск и чтение логов, их делят на уровни. Основных четыре:
Debug — запись масштабных переходов состояний, например, обращение к базе данных, старт/пауза сервиса, успешная обработка записи и пр.
Warning — нештатная ситуация, потенциальная проблема, может быть странный формат запроса или некорректный параметр вызова.
Error — типичная ошибка.
Fatal — тотальный сбой работоспособности, когда нет доступа к базе данных или сети, сервису не хватает места на жестком диске.
Дополнительно файл логирования может расширяться записями еще двух уровней:
Trace — пошаговые записи процесса. Полезен, когда сложно локализовать ошибку.
Info — общая информация о работе службы или сервиса.
Работа с уровнями логирования регламентируется методическими документами и внутренними правилами организации. В них может определяться соответствие источника сообщения уровню логирования, значимость, порядок обработки каждого уровня и другие параметры.
Типы логов
Для удобства обработки логов их делят на типы:
системные, связанные с системными событиями,
серверные, отвечающие за процесс обращения к серверу,
почтовые, работающие с отправлениями,
логи баз данных, которые отражают процессы обращения к базам данных,
авторизационные и аутентификационные, которые отвечают за процесс входа, выхода из системы, восстановление доступа и пр.
У каждого типа логов свой журнал записи. Для проверки логов авторизации нужно идти в журнал доступов, чтобы проверить загрузку системы — в журнал dmesg, за данными о запросах пользователей — в access_log. Когда одни логи пишутся отдельно от других, проще диагностировать ситуацию и найти источник проблемы.

Логи в access_log
Инструменты для работы с логами
Сбор, хранение и анализ логов вручную хороши, когда у вас один сервер. Когда серверный парк разрастается, а приложений и сервисов становится больше десяти, работу с логами целесообразно автоматизировать и использовать специальные системы логирования, например, Graylog, ELK, Loggy или Splunk. Некоторые из них позволяют организовать полномасштабный мониторинг, настроить алерт раннего обнаружения конкретной проблемы или установить пороговые значения показателей, коррелирующих с угрозами информационной безопасности.
Логи сетевого, инженерного оборудования, баз данных и приложений мы храним в облачном хранилище. И вам советуем. Даже когда у вас полно места на жестких дисках и стоит мощная защита на все случаи жизни. Оборудование рано или поздно, а чаще неожиданно, выходит из строя, а злоумышленники давно умеют чистить файлы логирования, так что логи в облаке — это возможность восстановить события и расследовать инцидент даже при полном отказе системы.
Хранение логов в облаке
Логирование кажется второстепенным процессом, который занимает время, но не дает видимых результатов. Однако это только кажется и только до тех пор, пока не появится реальная проблема, с которой можно разобраться только по логам. И только если они записаны, распределены по уровням, собираются и доступны для анализа.
По следам происшествия: как логировать эффективно
Людям свойственно ошибаться. Это относится не только к разработчикам, но и к пользователям. В ходе разработки мы контролируем процесс и можем разобраться в неправильном поведении программы простой отладкой. А вот расследовать случай, который произошёл в production-окружении, не всегда просто. В таких ситуациях на помощь приходят журналы. И чтобы от них действительно была польза, их нужно вести правильно.
Логирование — это процесс ведения таких журналов. Помогает обнаружить скрытые ошибки, разобраться в проблемах пользователей и просто понять, что произошло на самом деле. В простейшей реализации такие журналы пишутся в текстовом файле и содержат точное время и описание произошедшего события. В логировании есть множество подходов и давно определены лучшие практики — это хорошо для нас.
В этой статье разберёмся, как правильно организовать ведение журналов в PHP-приложении, как эффективно с ними взаимодействовать и какие библиотеки и инструменты могут быть полезны.
Стандарт PSR-3. Уровни логирования
PSR — это свод рекомендаций для PHP-разработчиков. Он содержит советы по оформлению кода, некоторые интерфейсы и другие рекомендации. Один из его документов (PSR-3) посвящён реализации логера.
Знакомство с этими рекомендациями предлагаю начать с уровней логирования, которые в них предлагаются.
PSR-3 определяет 8 уровней сообщений. Если их использовать правильно, искать ошибки станет проще и получится оперативнее реагировать на инциденты. Давайте разберёмся, как выбрать уровень:
- DEBUG — отладочная информация, подробно раскрывающая детали события;
- INFO — любые интересные события. Например, когда пользователь авторизовался;
- NOTICE — важные события в рамках ожидаемого поведения;
- WARNING — исключительные ситуации, не являющиеся ошибками. Например, использование устаревшего метода, неправильный запрос в API;
- ERROR — ошибки, которые следует отслеживать, но они не требуют срочного исправления;
- CRITICAL — критическое состояние или событие. Например, недоступность компонента, неожиданное исключение (Exception);
- ALERT — ошибка или событие, требующие срочных действий. Например, когда база данных недоступна;
- EMERGENCY — ситуация, когда программа или система полностью выведены из строя.
Чтобы использовать эти уровни, достаточно добавлять их название к строке каждой записи журнала. Например:
На уровни ALERT и EMERGENCY часто ставят дополнительное информирование, например по SMS. По INFO можно легко восстановить последовательность действий пользователя, по DEBUG — узнать точные значения переменных, результат работы функции в определённом месте и прочее.
PSR-3. Интерфейс для класса-логера
Помимо класса с уровнями, PSR-3 предлагает нам интерфейс для реализации собственных логеров — LoggerInterface. Соблюдать его очень полезно, так как большинство существующих библиотек его поддерживает. Если вы решите заменить свой логер на другой, просто подключите вместо него новый класс.
LoggerInterface требует реализации методов ведения журнала — и чтобы она учитывала уровни, которые мы разобрали выше. Создадим собственный класс-логер, который будет соответствовать этому интерфейсу и делать записи в файл.
Для начала загрузим код стандарта PSR-3 с помощью Composer.
В загруженном пакете содержится несколько классов, трейтов и интерфейсов. Среди них — LogLevel, который мы разобрали выше, и интересующий нас в данный момент LoggerInterface. Давайте создадим новый класс, реализующий этот интерфейс. Важно: убедитесь, что у вас подключён класс-автозагрузчик (vendor/autoload.php).
Класс мы создали. Но чтобы он удовлетворял требованиям стандарта, нужно написать все методы, описанные в интерфейсе. Самый важный из них — log. В нём будет указана основная логика записи в файл.
Для полного удовлетворения интерфейса LoggerInterface нам осталось написать реализацию для методов emergency, alert, critical, error, warning, notice, info и debug, которые соответствуют уровням (их мы разобрали выше). Их реализация сводится к очень простому принципу: мы вызываем метод log, передав в него необходимый уровень.
Использование логера
Теперь, когда наш класс реализует интерфейс, предложенный стандартом PSR-3, мы можем легко задействовать его в любом месте. Например, в файле index.php:
Или в любом другом классе.
Обратите внимание: в качестве типа аргумента конструктора мы указываем не конечную реализацию (FileLogger), а именно интерфейс стандарта PSR-3. Это удобно, потому что позволяет легко заменять применяемый логер на любой другой, поддерживающий этот интерфейс.
Контекст
Вы могли заметить, что все методы интерфейса LoggerInterface содержат аргумент $context. Зачем он нужен?
Контекст предназначен для передачи вспомогательной и зачастую динамичной информации. Например, если вы делаете отладочную запись (уровень debug), можно передать в контекст значение переменной.
Чтобы применять этот аргумент, нам нужно поддержать его в методе log. Давайте доработаем его, учитывая, что $context — массив.
Теперь в любом месте вызова логера мы можем передать вторым аргументом массив дополнительной информации.
В результате мы получим запись следующего вида:
Касательно контекста действует одно простое правило: любая динамическая информация должна передаваться в нём, но не в сообщении. То есть, если вы формируете сообщение в лог с помощью sprintf или конкатенацией строчных переменных, — скорее всего, эту информацию можно вынести в контекст. Соблюдая это правило, проще искать что-то в журнале, потому что не приходится предугадывать (или вычислять) значения переменных.
Библиотека Monolog
Несмотря на всю простоту принципа ведения журналов, в этой области широкий простор для модификаций. Мы могли бы поддержать другие форматы записей, реализовать отправку SMS или элементарно дать возможность менять имя конечного файла логов.
Здорово, что всё это уже реализовано в большинстве библиотек. Одна из самых распространённых – monolog.
Среди весомых преимуществ этого пакета:
- полная поддержка PSR-3;
- поддержка разных принципов обработки логов в зависимости от уровня;
- поддержка имён каналов (имена логеров);
- очень широкая поддержка фреймворков.
Чтобы начать использовать этот прекрасный инструмент, установим его с помощью Composer.
Использование Monolog
Работа библиотеки monolog основывается на обработчиках. Они позволяют задавать конкретное поведение в ответ на события логирования. Например: запись в файл — это специальный обработчик, который называется StreamHandler. Давайте заменим использование нашего класса на загруженную библиотеку.
Если мы запустим этот код, в файле gb.log появится запись следующего вида:
Очень похоже на то, что было у нас ранее, кроме добавления имени канала (gb-demo).
Важная особенность обработчиков monolog: им можно задать уровень, на котором они работают. Например, чтобы писать все ошибки в отдельный файл.
Подключённый на уровень ERROR обработчик будет принимать на себя все записи уровня ERROR и выше. Поэтому вызов метода emergency попадает в оба файла: gb.log и errors.log
Такое простое разделение записей по уровням значительно упрощает для нас реагирование на ошибки. Ведь больше не нужно искать их среди всех записей в журнале. Это простая и полезная функция.
Все записи от одного запроса
Когда мы разрабатываем проект, журналы читаются очень просто, они последовательны и ясны. Но когда продуктом пользуются несколько человек, логи могут перемешиваться и больше запутывать, чем помогать. Для решения этой проблемы есть простой трюк. Вместо имени канала (логера) используйте уникальный идентификатор сессии. Получить его можно с помощью встроенной функции session_id(). При этом сессия должна быть обязательно запущена с помощью session_start()
Рассмотрим пример реализации такого приёма:
Что нам даёт такая простая доработка? Важную возможность — группировать все записи запросам пользователя.
Что дальше?
Monolog поддерживает множество полезных готовых обработчиков, на которые стоит обратить внимание:
- TelegramBotHandler — отправляет записи в Telegram от имени бота. Пригодится для высоких уровней логирования;
- SlackHandler — похож на предыдущий, но отправляет записи в Slack;
- SwiftMailerHandler — позволяет отправлять записи по email;
- ChromePHPHandler – даёт доступ к журналам прямо из браузера Chrome в режиме Live.
Заключение
Логирование поможет исправлять ошибки на ранних этапах разработки и быть уверенными, что ничего не сломалось в новой версии кода. А ещё расследовать случаи ваших пользователей и иметь общее видение проекта.
Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
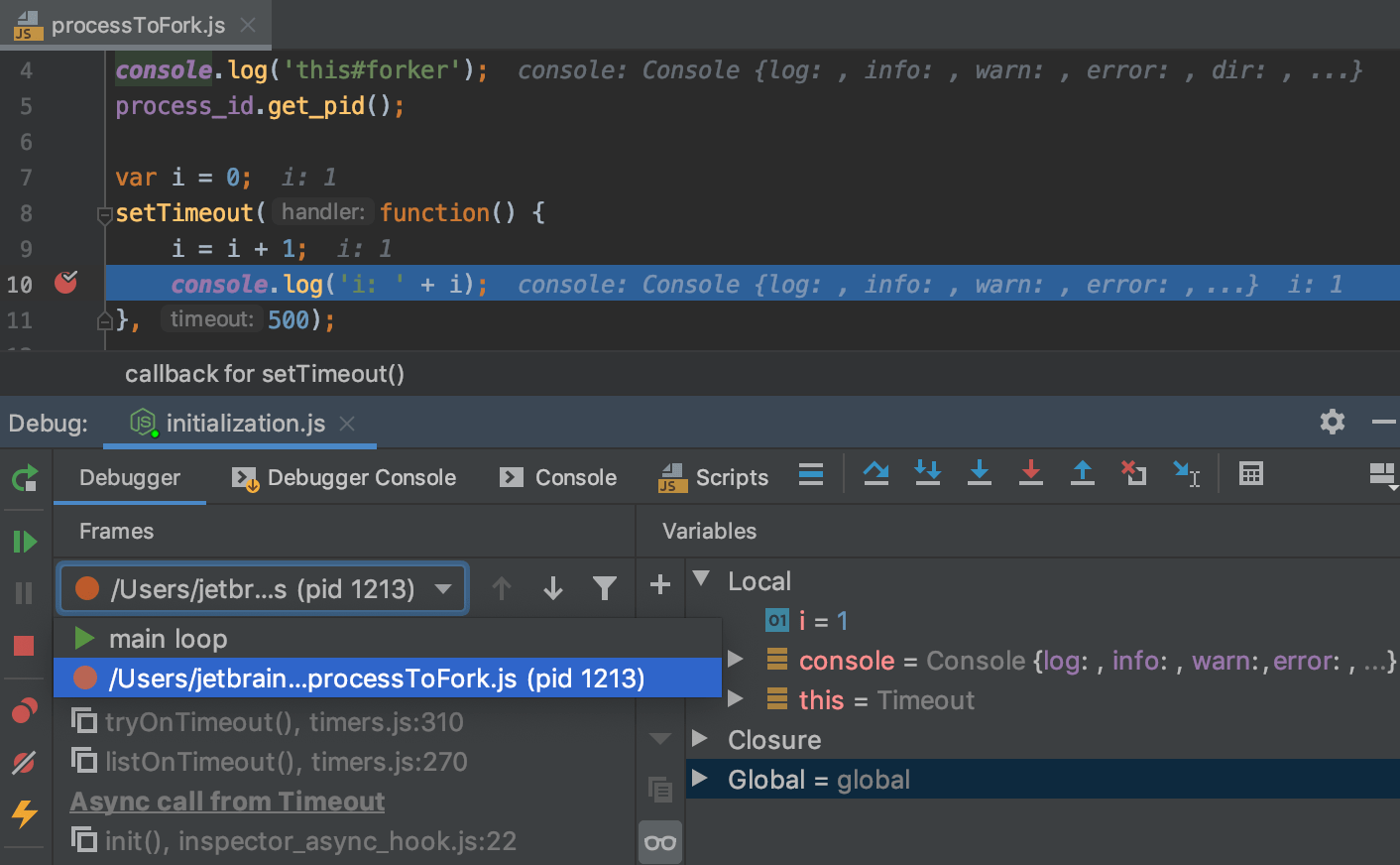
- Сложность реальных приложений
- Логирование
- Уровни логирования
- Ротация логов
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
- DNS. Система трансляции имени сайта в ip-адрес сервера.
- Веб-сервер. Программа, обслуживающая входящие запросы, перенаправляет их в код приложения и забирает от приложения данные для пользователей.
- Физический сервер (или виртуальный) с его окружением. Включает в себя операционную систему, установленные и запущенные обслуживающие программы, например, мониторинг.
- База данных. Внешнее хранилище, с которым связывается код приложения и обменивается информацией.
- Само приложение. Помимо кода, который пишут программисты, приложение включает в себя сотни тысяч и миллионы строк кода сторонних библиотек. Кроме этого, код работает внутри фреймворка, у которого свои собственные правила обработки входящих запросов.
- Фронтенд часть. Код, который выполняется в браузере пользователя. И системы сборки для разработки, например, Webpack.
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает написанный нами код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
# Формат: ip-address / date / HTTP-method / uri / response code / body size
173.245.52.110 - [19/Jan/2021:01:54:20 +0000] "GET /my HTTP/1.1" 200 46018
108.162.219.13 - [19/Jan/2021:01:54:20 +0000] "GET /sockjs-node/244/gdt1vvwa/websocket HTTP/1.1" 0 0
162.158.62.12 - [19/Jan/2021:01:54:20 +0000] "GET /packs/css/application.css HTTP/1.1" 304 0
162.158.62.84 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/runtime-eb0a99abbe8cf813f110.js HTTP/1.1" 304 0
108.162.219.111 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/application-2cba5619945c4e5946f1.js HTTP/1.1" 304 0
108.162.219.21 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/0564a7b5d773bab52e53.js HTTP/1.1" 304 0
108.162.219.243 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/6fb7e908211839fac06e.js HTTP/1.1" 304 0
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
# Выведет 4 минуты логов за 31 марта 2020 года с 19:31 по 19:35
grep "31/Mar/2020:19:3[1-5]" access.log
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
- Ruby On Rails (Ruby)
- Django (Python)
- Laravel (PHP)
- Spring Boot (Java)
- Fastify (Node.js)
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
# Сюда же выводятся ошибки, если они были
「wds」: Project is running at http://hexletdev4.com/
「wds」: webpack output is served from /packs/
「wds」: Content not from webpack is served from /root/hexlet/public/packs
「wds」: 404s will fallback to /index.html
「wdm」: assets by chunk 10.8 MiB (auxiliary name: application) 115 assets
sets by path js/ 13.8 MiB
assets by path js/*.js 13.8 MiB 52 assets
assets by path js/pages/*.js 5.1 KiB
asset js/pages/da223d3affe56711f31f.js 2.6 KiB [emitted] [immutable] (name: pages/my_learning) 1 related asset
asset js/pages/04adacfdd660803b19f1.js 2.5 KiB [emitted] [immutable] (name: pages/referral) 1 related asset
sets by chunk 9.14 KiB (auxiliary id hint: vendors)
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
- debug
- info
- warning
- error
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
// Пример логирования внутри программы
// Логер: https://github.com/pinojs/pino
import buildLogger from 'pino';
const logger = buildLogger(/* возможная конфигурация */);
logger.info('тут что то полезное');
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
# https://github.com/fastify/fastify-cli#options
FASTIFY_LOG_LEVEL=debug fastify-server.js
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
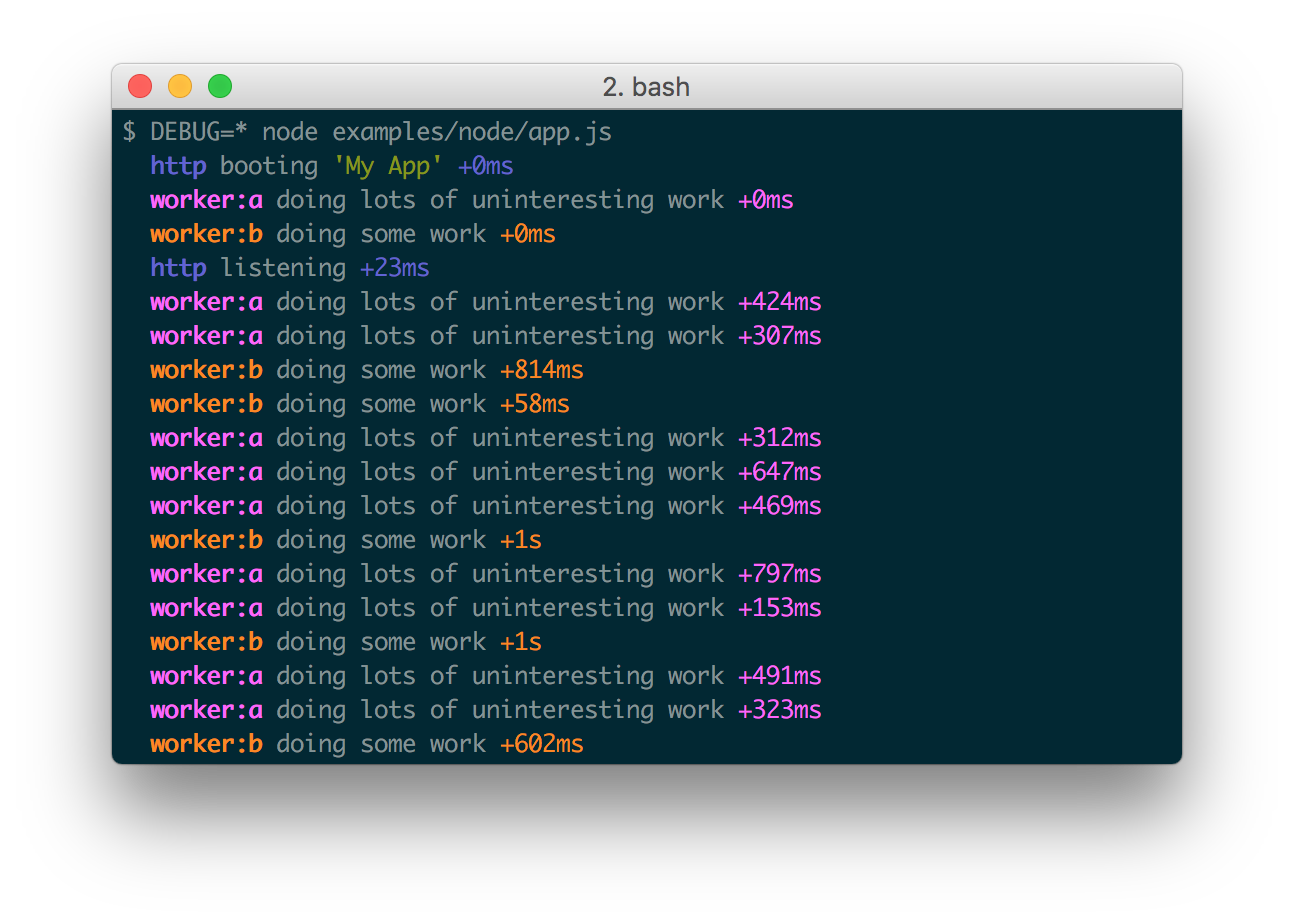
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
import debug from 'debug';
// Пространство имен http
const logHttp = debug('http');
const logSomethingElse = debug('another-namespace');
// Где-то в коде
logHttp(/* информация о http запросе */);
Запуск с нужным пространством:
DEBUG=http server.js
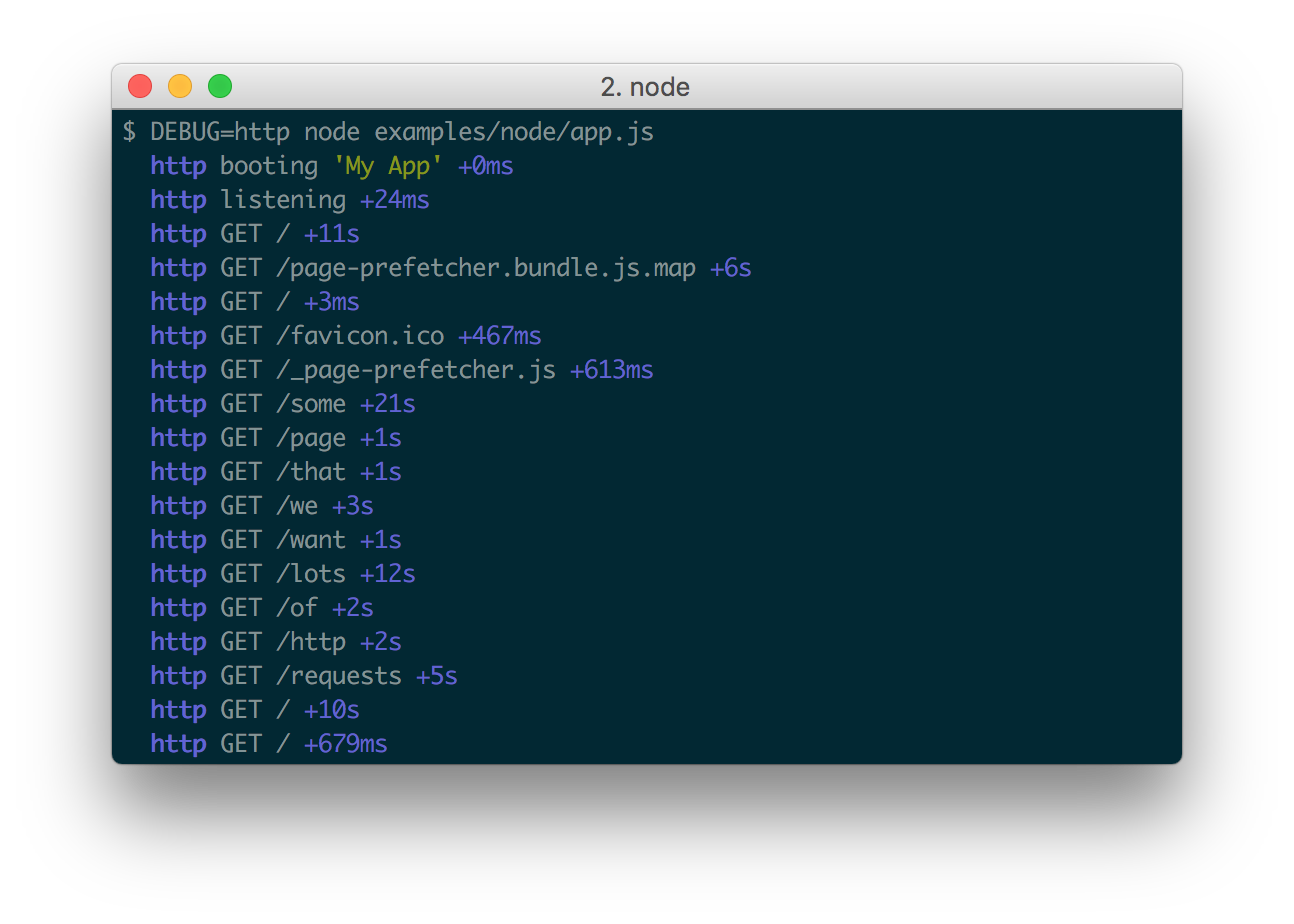
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системами созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
{«id»:13970,»url»:»/distributions/13970/click?bit=1&hash=91604a90c2650116d868cf1db62d454cb2b1436d305e0040effcaed4203feae5″,»title»:»u041au0442u043e u043fu0440u043eu0432u0435u0440u044fu0435u0442 u0432u0430u0448u0435u0433u043e u0448u043eu0444u0435u0440u0430 u043du0430 u0442u0440u0435u0437u0432u043eu0441u0442u044c? u0410 u043du0430 u0440u0438u0441u043a u0438u043du0444u0430u0440u043au0442u0430? «,»buttonText»:»u0423u0437u043du0430u0442u044c»,»imageUuid»:»29370595-d77a-5707-95b9-2f7879cddd4d»}
Логирование или как вести летопись работы программы
Написали программу с применением нейросети, но она выдает кучу ошибок? Где потом искать эти ошибки? Как структурировать полученную информацию?
Помочь с поиском ошибок может логирование — группа методов для сбора и сохранения информации о работе программы. Всю интересующую нас информацию мы можем записывать в текстовые файлы и потом их обрабатывать. К примеру, вот таким образом в случае деления на 0:
Тогда консоль нам покажет следующее:
А в логе с файлом увидим:
Конечно, реализовать самостоятельно такой способ — просто, и многие этим пользуются. Но у него тоже есть минус: если проект большой, надо не забывать придерживаться определенного формата их заполнения.
Но Python же один из самых дружелюбных языков.) Разработчики уже подумали о нас и создали хорошую библиотеку «logging».
Для работы с ней нам необходимо импортировать библиотеку logging и указать основные параметры. Всего параметров для настройки 6.
Так же существует 5 уровней логирования информации: от DEBUG (отладка) до critical (критичные ошибки).
На этом можно закончить с теорией, и перейдем к практике.
Теперь мы будем логировать нашу функцию деления уже с учетом модуля logging и попытаемся собрать максимум информации о ее работе. Давайте рассмотрим код нашего простенького скрипта, но уже с учетом использования логов.
Как мы видим он немного увеличился в размерах, но при этом, для записи также использует лишь одна строчка.
В начале мы создаем переменную, в которой указываем идентификатор лога. Это нужно для того, к примеру, чтобы мы не путались из какого скрипта записываем лог. Это делается строкой —
logger = logging.getLogger(‘Stat’) —
После – мы указываем уровень лога и имя файла, в который мы будем его записывать:
logger.setLevel(logging.INFO)
file_name = logging.FileHandler(‘data.log’)
В конце нам надо создать формат записи, в котором мы укажем: время записи, имя скрипта, названия уровня и само сообщение. Остается только применить данный формат для нашего «логгера».
format_log = logging.Formatter(‘%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
file_name.setFormatter(format_log)
logger.addHandler(file_name)
Вот, на этом и все) В дальнейшем мы можем использовать наш логгер простым вызовом logger.info(‘Division’) или в случае описания ошибки logger.error(error_text). По окончанию работы скрипта данные будут сохранены в файл ‘data.log’.
А теперь посмотрим, что мы получили в логе:
Запись со временем, уровнем и сообщением! Такой лог, во-первых – удобно читать, а, во-вторых – удобно обрабатывать!
Использование модуля «logger» на маленьких программах, может, и не заметно, а вот на больших польза становится очевидна. Особенно, если эти логи в дальнейшем нуждаются в обработке, например, для Process Mining-а.
Вот таким простым способом мы с вами научились делать понятную и удобную запись логов в нашем скрипте!

Евгений Холодов
техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
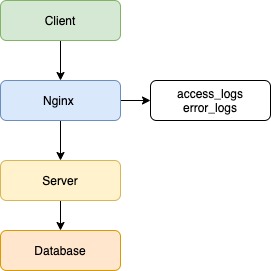
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: "GET /api/v1/users/levels HTTP/2.0", upstream: "http://127.0.0.1:5000/api/v1/users/levels", host: "app.dunice-testing.com"
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.

Логи можно сравнить с уликами на месте преступления, а разработчиков — с криминалистами. Роль логов трудно переоценить, ведь когда необходимо найти баг или причину сбоя, сразу обращаются к ним. Подобно тому, как отсутствие улик приводит к нераскрытым делам, отсутствие содержательных логов осложняет диагностику и устранение ошибок, превращая их в затянувшийся или вовсе невыполнимый процесс. Мне приходилось наблюдать, как люди мучились с такими инструментами, как Strace и tcpdump, или развертывали новый код в продакшене во время сбоя лишь затем, чтобы получить больше лог-файлов для выявления проблемы.

Как говорится: “Хорошо подготовиться — половину дела сделать”, так что каждому профессиональному разработчику следует научиться эффективно вести логи и быть готовым к работе с ними. В данной статье мы не только рассмотрим список полезных практик логирования в приложении, но и разберем теоретические основы данного процесса: что записываем, когда и кто этим должен заниматься.
Как осуществляется процесс отладки?
Прежде чем начать разговор о логах, необходимо ответить на два вопроса:
- Что такое программа?
- Как осуществляется отладка, в которой логи играют важную роль?
Программа как переходы состояний
Программа — это серия переходов между состояниями.
Состояния — это вся информация, которую программа хранит в своей памяти в определенный момент времени, а код программы определяет то, как она переходит от одного состояния к другому. Разработчики, использующие императивные языки программирования, такие как Java, зачастую акцентируют больше внимания на самом процессе (коде), чем состояниях. Однако понимание того, что программа является серией состояний, очень важно, поскольку они существенно ближе к тому, что должна делать программа, а не как.
Допустим, есть робот, задача которого — заполнить бензобак машины. Если мы рассмотрим выполняемые им действия как переходы состояний, то ему необходимо перейти от состояния (бак пустой, в наличии 50 $) к состоянию (бак полный, в наличии 15 $). Если же мы описываем его как процесс, то он должен найти заправку, доставить туда машину и заплатить. Конечно же, процесс имеет большое значение, но состояния дают более точную оценку правильности программы.
Отладка
Отладка — это мысленная реконструкция переходов состояний. Разработчики проигрывают в уме сценарий программы: как она принимает вводные данные, проходит через ряд изменений состояний и осуществляет вывод, а затем определяют, что пошло не так. Во время разработки этот мыслительный процесс подкрепляется использованием отладчика. Однако в продакшене делать это уже гораздо сложнее, поэтому на данном этапе чаще прибегают к помощи логов.
Что записывать в лог ?
Понимая суть процесса отладки, мы с легкостью ответим на этот вопрос:
Логи должны содержать информацию, необходимую для реконструкции переходов состояний.
Невозможно, да и не нужно, фиксировать все состояния во все отрезки времени. Например, полиции достаточно лишь нескольких точных набросков, а не видеоклона, для поимки преступника. Тоже самое относится и к логам: разработчикам нужно только внести в них информацию о том, когда происходит переход в критическое состояние. Кроме того, логи должны содержать ключевые характеристики текущего состояния и причину перехода.
Переход в критическое состояние
Не все переходы состояний стоит записывать в лог. Важно рассмотреть программу как серию изменяемых состояний, разделить их на фазы и затем сосредоточиться на времени, когда выполнение переходит от одной фазы к другой.
Предположим, что существуют 3 фазы запуска приложения:
- загрузка настроек программы;
- подключение к зависимостям;
- запуск сервера.
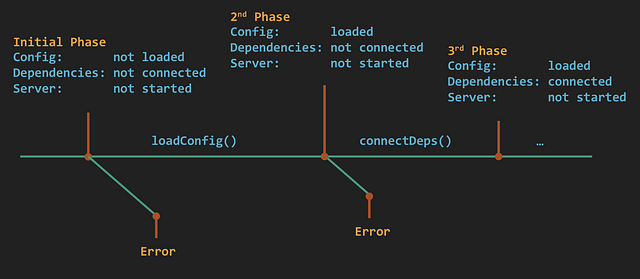
Было бы очень разумно вести логи в начале и конце каждой фазы. Если бы произошла ошибка на этапе подключения к зависимостям и приложение бы зависло, то логи отчетливо показали бы, что после загрузки настроек оно вошло во вторую фазу процесса, не завершив его. Располагая этой информацией, разработчики смогли бы быстро определить проблему.
Ключевые характеристики
Логирование состояний напоминает создание эскизов программы только с учетом ключевых характеристик основ бизнес-логики. Если есть информация закрытого характера, например персональные данные, то ее также нужно записать в лог, но в завуалированном виде.
Например, когда HTTP-сервер переходит из состояния ожидания запроса в состояние получения запроса, он должен зафиксировать в логе HTTP-метод и URL, так как они описывают основы HTTP-запроса. Остальные его элементы (заголовки или часть тела сообщения) записываются в том случае, если их значения влияют на бизнес-логику. Например, если поведение сервера сильно отличается между состояниями Content-Type:application/json и Content-Type:multipart/form-data, заголовок следует записать.
Причина перехода состояния
Логирование причины перехода состояния чрезвычайно полезно для отладки. Логи должны кратко охватывать содержание предыдущих и следующих состояний, а также объяснять их причины. Они помогают разработчикам получить общую картину и ориентироваться в процессе реконструкции (отладки) выполнения программы.
Пример
Рассмотрим простой пример для обобщения всего сказанного. Предположим, что сервер получает некорректный номер социального страхования, и разработчик намерен внести в лог информацию об этом событии.
Вот несколько анти-шаблонов логов, в которых отсутствуют ключевые характеристики состояния и причины:
- [2020–04–20T03:36:57+00:00] server.go: Error processing request (Запрос на обработку ошибок)
- [2020–04–20T03:36:57+00:00] server.go: SSN rejected (Номер социального страхования отклонен)
- [2020–04–20T03:36:57+00:00] server.go: SSN rejected for user UUID “123e4567-e89b-12d3-a456–426655440000” (Номер социального страхования отклонен для пользователя UUID “123e4567-e89b-12d3-a456–426655440000”)
Все они содержат определенную информацию, но ее недостаточно для ответов на вопросы, которые могут возникнуть у разработчиков в процессе поиска ошибки. Какой запрос не смог обработать сервер? Почему номер социального страхования был отклонен? Какой пользователь столкнулся с этой ситуацией? Грамотный и полезный для отладки лог будет выглядеть так:
[2020–04–20T03:36:57+00:00] server.go: Received a SSN request(track id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) from user uuid “123e4567-e89b-12d3-a456–426655440000”(previous state), rejecting it(next state) because the server is expecting SSN format AAA-GG-SSSS but got **-***(why)
([2020–04–20T03:36:57+00:00] server.go: Получен запрос номера социального страхования (трек id: “e4a49a27–1063–4ab3–9075-cf5faec22a16”) от пользователя user uuid “123e4567-e89b-12d3-a456–426655440000” (предыдущее состояние), запрос отклонен (следующее состояние), так как сервер требует номер социального страхования в формате AAA-GG-SSSS, а получил **-*** (причина)
Кто должен записывать логи?
Типичная ошибка, которую многие допускают, связана с тем, “кто” должен фиксировать информацию. Ведение логов не теми функциями оборачивается дублированием или дефицитом информации.
Программа как уровни абстракции
Большинство грамотно созданных программ подобны пирамиде с уровнями абстракции. Классы/функции верхних уровней разбивают сложную задачу на подзадачи, тогда как классы/функции нижних уровней абстрагируют реализацию подзадач, таких как черные ящики, и предоставляют интерфейсы для вызова верхним уровнем. Эта парадигма облегчает программирование, поскольку каждый уровень сосредоточен на своей логике, не беспокоясь о всевозможных деталях.
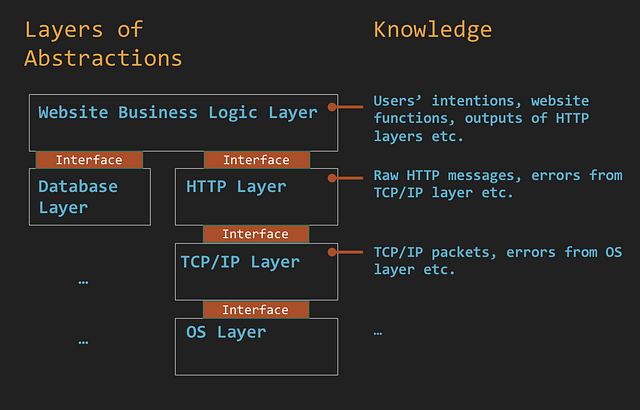
Например, веб-сайт может состоять из следующих уровней: бизнес-логика, HTTP и TCP/IP. Реагируя на URL-запрос, уровень бизнес-логики решает, какую веб-страницу показать, и отправляет ее контент на уровень HTTP, где он превращается в HTTP-ответ. Следующий уровень TCP/IP преобразует HTTP-ответ в пакеты TCP и рассылает их.
Ведите логи только на правильных уровнях
Как следствие абстракции, разные уровни имеют разные степени понимания выполняемой задачи. В предыдущем примере уровень HTTP не владел данными ни о количестве отправляемых пакетов TCP, ни о намерении пользователей в момент URL-запроса. Предпринимая попытку логирования, разработчикам следует выбрать правильный уровень, который содержит полную информацию о переходах состояний и причинах.
Вернемся к нашему примеру проверки корректности номера социального страхования. Допустим, что логика его проверки обернута в класс Validator следующим образом:
public class Validator {
// другие функции проверки...
public static void validateSSN(String ssn) throws ValidationException {
// выполнение проверки
String regex = "^(?!000|666)[0-8][0-9]{2}-(?!00)[0-9]{2}-?!0000)[0-9]{4}$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(ssn);
if (!matcher.matches()) {
// --> Записываем в лог местоположение A <--
logger.info("Bad SSN blah, blah, blah...");
throw new ValidationException(String.format("expecting SSN format AAA-GG-SSSS but got %s", ssn.replaceAll("\d", "*")));
}
}
}Есть еще другая функция, которая проверяет запрос, обновляющий информацию о пользователе, и вызывает проверку номера социального страхования.
public class Validator {
// другие функции проверки...
public static void validateUserUpdateRequest(UserUpdateRequestreq) {
// проверка другого атрибута req ...
try {
validateSSN(req.ssn);
} catch (ValidationException e) {
// --> Записываем в лог местоположение B <--
logger.info(String.format("Received a user update request(track id %s) from user uuid %s, rejecting it because %s", req.trackID, req.uid, e.getMessage()));
// другая логика обработки ошибки ...
}
// остальная логика...
}
}Существует два местоположения (A и B) для записи логов об ошибке проверки номера социального страхования, но только B владеет достаточной для этого информацией . В A программа не знает, ни какой запрос она обрабатывает, ни от какого пользователя он поступает. Логирование просто добавляет деталей. Будет лучше, если validateUserUpdateRequest выбросит ошибку из вызывающего компонента (validateRequest), содержащего больше контекста для лога.
Однако это вовсе не означает, что логирование на нижних уровнях программы совершенно необязательно, особенно когда они не раскрывают ошибки верхним уровням. Например, сетевой уровень может иметь встроенную логику повторных попыток, из чего следует, что верхние уровни не замечают проблем с прерывающимися соединениями. В общем, нижние уровни могут вести логи больше на уровне DEBUG, чем на INFO, в целях сокращения многословности. При необходимости разработчики могут настроить уровень лога для получения большего количества деталей.
Сколько должно быть логов?
Существует очевидное соотношение между объемом логов и их полезностью. Чем более содержательные логи, тем легче реконструировать переходы состояний. Вы можете воспользоваться двумя способами контроля количества логов:
Установите соотношение между логами и рабочей нагрузкой
Для контроля объема логов сначала важно его правильно измерить. Большинство программ имеют 2 типа рабочей нагрузки:
- получение рабочих элементов (запросов) и последующая реакция на них;
- запрос рабочих элементов откуда-либо и последующее выполнение действий.
В большинстве случаев процесс логирования запускается рабочей нагрузкой: чем больше ее у программы, тем больше логов она записывает. Могут быть и другие логи, не связанные с рабочей нагрузкой, но они становятся малозначимыми, когда программа начинает работу. Разработчики должны сохранять соотношение # логов и # рабочих элементов линейным. Иначе говоря:
# логов = X * # рабочих элементов+ константы
где X можно определить, изучив код. Разработчики должны иметь хорошее представление об X-факторах для своих программ и приводить их в соответствие с возможностями логирования и бюджетом. Вот еще несколько типичных случаев X:
- 0 < X < 1. Это значит, что логи отбираются выборочно, и не у всех рабочих элементов они есть, например ведётся запись только ошибок или используются другие алгоритмы отбора логов. Это способствует снижению объемов лога, но при этом может ограничить возможности поиска проблемы.
- X ~ 1. Это значит, что в среднем каждый рабочий элемент производит примерно одну запись. И это целесообразно до тех пор, пока один лог содержит достаточно информации (подробно в разделе “Что записывать в лог?”).
- X >> 1. У разработчиков должна быть весомая причина для того, чтобы X был существенно больше, чем 1. Когда рабочая нагрузка возрастает, например в случае с сервером, на который обрушивается внезапный шквал HTTP-запросов, то X лишь усиливает ее и чрезмерно нагружает инфраструктуру логирования, что обычно вызывает проблемы.
Используйте уровни логов
Что, если X все еще слишком большой даже после оптимизации? На помощь приходят уровни логов. Если X намного больше, чем 1, то можно поместить логи на уровень DEBUG, тем самым снизив X уровня INFO. В процессе устранения неполадок программа может временно выполняться на этом уровне для предоставления дополнительной информации.
Краткие выводы
Чтобы профессионально писать логи, следует рассматривать программу как серию переходов состояний с уровнями абстракции. Владея теоретическими знаниями, можно ответить на ключевые вопросы о логировании в приложении:
1.Когда писать логи? В момент перехода в критическое состояние.
2.Что записывать в лог? Ключевыехарактеристики текущего состояния и причину перехода состояния.
3.Кто должен записывать логи? Логирование должно происходить на правильном уровне, содержащем достаточно информации.
4.Каким должно быть количество логов? Определите X-фактор (по формуле # логов = X * # рабочих элементов+ константы) и настройте его экономно, но выгодно.
Читайте также:
- Логирование в Python с помощью Logzero
- Используйте перечисления, а не логические аргументы
- Логи в Python. Настройка и централизация
Перевод статьи Neal Hu: Logging Like a Pro
Привет, Хабр! Меня зовут Евгений Лабутин, я разработчик в МТС Digital. Расскажу вам о том, как мы на нашем проекте МТС Твой бизнес собираем логи с клиентских веб‑приложений. А еще обсудим вспомогательный микросервис логирования, который мы вывели в Open source, и поговорим о том, как устроено логирование в принципе.

Для чего мы логируем?
Логируем мы для решения двух очень важных задач.
Первая — мы хотим понимать, как ведет себя ПО на клиентских устройствах. Мы, конечно, тестируем на большом количестве устройств весь функционал, который выводим в продакшн. Но такое тестирование — это все равно капля в море по сравнению с разнообразием устройств и браузеров клиентов.
В клиентских логах мы встречали ошибки заблокированного localStorage и добавили в код обработку недоступного хранилища. Встречали ошибку отсутствующего API браузера — добавляли полифил или поднимали версию минимально поддерживаемого браузера для отображения заглушки устаревшего браузера. Встречали ошибки в сценариях, не предусмотренные логикой и тестированием, — исправляли их.
Попадались нам ошибки в расширениях браузера и даже вирусы на клиентских устройствах, ошибки заблокированной аналитики, ошибки потери интернет‑соединений. Все эти инциденты мы отрабатывали. Самая странная ошибка, которая у нас была — это ошибка во внешнем скрипте. Воспроизводится она только в mi‑браузерах у некоторых клиентов. Если знаете, что это за внешний скрипт — дайте знать в комментариях.
Логирование этих ошибок позволяет значительно повысить качество разрабатываемого ПО и фиксить проблемы до того, как пользователи их заметят.
Вторая задача — обработка инцидентов. Каждый раз, когда у клиента возникает ошибка в ПО, он звонит на горячую линию МТС и сообщает о проблеме. Оператор заводит инцидент во внутренней системе, далее информация попадает к нам в команду и мы начинаем разбор проблемы по логам. По ним мы можем воспроизвести цепочку действий пользователя и найти ошибку. Был даже случай, когда человек перестал пользоваться сервисом, но забыл отключить подписку. При обращении в колл‑центр он сообщил об этом и сказал, что не пользовался услугами. Мы проверили логи и действительно не нашли активности пользователя после даты списания. Деньги клиенту вернули.
Так логирование помогает значительно повысить качество ПО и лучше разбираться в ошибках, возникающих у пользователей.
Что мы логируем?
На стороне веб‑приложения логируются обычно исключения внутри приложения, глобальные исключения, важные события в логике (например, оплата). В набор этих логов входят: текст ошибки, стектрейс, локация ошибки, навигатор, идентификатор пользователя.
Никакие персональные данные не логируются по соображениям безопасности. Достаточно вспомнить взлом системы логирования Kibana (ELK), который позволял загружать на сервер чужой код и, в том числе, воровать чужие логи. При отсутствии логирования персональных данных украсть их становится значительно сложнее. А для идентификации логов с целью обработки инцидентов достаточно идентификатора пользователя.
Как логировать правильно?
Перед тем, как мы начнем собирать логи в Kibana или Loki, давайте сначала разберемся, как нужно писать код системы логирования.
Кажется, что самый простой способ логирования выглядит так:
console.log("Это самое правильное логирование!");Но есть проблема, такой код можно прочитать только на клиентском устройстве. Можно, конечно, подменить API браузерной консоли для отправки на сервер, но это антипаттерн, который называется манки‑патчинг и мы к нему прибегать не будем.
Kibana и Loki не имеют своих модулей логирования в веб‑приложениях. Но можно найти известный аналог под названием Sentry. Это готовая, удобная, и наглядная система логирования для клиентских ошибок. Тогда может логировать через Sentry?
import * as Sentry from "@sentry/browser";
Sentry.captureMessage("Вот теперь точно лучшая система логирования!!!");Но нет, при таком способе мы не увидим логи локально, сделаем вендор лок на систему Sentry, не сможем корректно настроить уровни логирования.
Логируем правильно!
Для логирования мы используем метод, принятый в корпоративной разработке. Мы используем объект, реализующий паттерн helper, выглядит он следующим образом:
import * as Sentry from "@sentry/browser";
export class Logger {
public logLevel: LogLevels = LogLevels.Info;
public constructor () {
Sentry.init({
dsn: "https://examplePublicKey@o0.ingest.sentry.io/0",
maxBreadcrumbs: 50
});
}
public log(message: string, data: unknown) {
if (this.logLevel <= LogLevels.Info) {
console.log(message, data);
Sentry.captureMessage(message, "debug");
}
}
public warning(message: string, data: unknown) {
if (this.logLevel <= LogLevels.Warn) {
console.warn(message, data);
Sentry.captureMessage(message, "warning");
}
}
public error (message: string, data: unknown, error: Error) {
if (this.logLevel <= LogLevels.Error) {
console.error(message, data, error);
Sentry.captureMessage(message, "error");
Sentry.captureException(error);
}
}
public info/debug/trace (message: string, data: unknown) {...}
}
// singleton
export const logger = new Logger();
Вызывается такой объект‑помощник через DI, если он есть. Если DI нет — как уже созданный singleton объект logger.
Написав такой объект, мы создали абстракцию, которая позволяет избавиться от привязки к конкретной системе логирования. Теперь при логировании в коде мы везде используем этот объект и не боимся, что рано или поздно систему логирования надо будет поменять. Кроме того, мы получили возможность настраивать уровень логирования в зависимости от потребностей и в случае необходимости можем включить более детальные логи отдельному клиенту.
Внезапно мы потеряли Sentry, но обрели Kibana
По мере цифровой трансформации компании МТС нам понадобилось поменять контуры в которых хостятся наши приложения. В старом контуре была отлаженная система логирования, построенная на Sentry, но по не зависящим от нас причинам от него пришлось отказаться (надеюсь, что временно). Зато в новом контуре уже вовсю работала система логирования ELK, с панелью визуализацией на Kibana.
Оставался только вопрос: как логи веб‑приложения отправить в Kibana? Ведь она умеет работать только с серверными логами и не имеет модуля для веб‑приложений. А некоторые приложения (в том числе микрофронтенды) еще и опубликованы, как статичные файлы, и не имеют своего серверного приложения.
Ответ на вопрос оказался крайне прост — мы сделали микросервис, который принимает логи от веб‑приложения и выводит их в консоль контейнера. Далее контейнеры уже имеют функционал по считыванию логов и отправку их систему логирования: Logstash (часть ELK), Loki и другие.
Первым делом мы трансформировали код нашего логера, закомментировав там Sentry на случай, если он вернется. А еще добавили код который засылает логи на микросервис логирования.
Код принял следующий вид:
export class Logger {
...
public log(message: string, data: unknown) {
if (this.logLevel <= LogLevels.Info) {
console.log(message, data);
// Sentry.captureMessage(message, "debug");
fetch("/logs/log/info", {
method: "POST",
body: JSON.stringify({
message: message,
data: data,
userAgent: navigator.userAgent,
location: location.href,
...other data
})
});
}
}
...
}
Добавив всего 10 строчек в наш логер, мы научили его работать с новым микросервисом логирования. А в целом такая абстракция как логер помогла нам избавиться от правки тысяч строк кода, в которых происходит логирование.
Микросервис логирования
Микросервис мы создали по уже отлаженному процессу, о котором я писал ранее. Взяли фреймворк NestJS, создали всего один контроллер с логикой, закатали в контейнер и опубликовали. Сам микросервис мы вывели в Open source, код выложен на github, а готовый контейнер можно запустить прямо сейчас из dockerhub.
Вместо NestJS могло бы быть что‑то легковесное. Например, C# или Go, но тогда кроме меня их некому было бы поддерживать.
Вся логика контроллера выглядит следующем образом:
@Controller("logs")
export class LogController {
@Post("log")
public writeLog(@Body() body: object, @Headers() headers: object): void {
console.log(
JSON.stringify({
...body,
logLevel: LogLevels.Info,
time: Date.now(),
userIp: headers["x-real-ip"],
traceId: headers["x-trace-id"]
})
);
}
}Этот микросервис запускается в контейнере, логи с которого считывает драйвер логирования LogStash, в результате чего мы наблюдаем логи в Kibana.
Таким образом, вся трансформация системы логирования заняла всего пару часов. Они ушли на написание и деплой контейнера, а также на правки кода логера.
Что дает Kibana?
Kibana — это интерфейс для работы с логами, он позволяет фильтровать их, строить графики, делать свои дашбоарды и (самое полезное) смотреть сквозные логи. Можно построить сквозные логи по всей системе по идентификатору пользователя или другим параметрам, понять, какую кнопку клиент нажал на фронтенде и к каким последствиям это привело на бэкенде.
Нужно признать, что в Sentry гораздо удобнее анализировать проблемы, чтобы понять в каких браузерах и на каких устройствах воспроизводится, пройтись, так сказать, по хлебным крошкам.
Спасибо за уделенное статье время! Надеюсь, мой опыт вам пригодится. Если у вас есть вопросы или замечания — с удовольствием пообщаюсь в комментариях к статье!
Этот материал мы ориентировали на тех, кто в первый раз сталкивается с логированием серверных служб и web-серверов. Познакомим с уровнями логирования, расскажем об основных типах логов и перечислим инструменты для работы с ними.
Зачем оно вообще нужно, это логирование?
На анализе логов базируется работа большинства ИТ-специалистов. Администраторы ищут в файлах логирования причины сбоя сервиса. Разработчики опираются на логи, чтобы локализовать и устранить ошибки приложения или веб-сайта. Служба безопасности по логам, как по физическим уликам, определяет вид взлома, оценивает нанесенный ущерб и даже может идентифицировать взломщика. Вот почему логирование мы рекомендуем отладить в первую очередь: в любой непонятной ситуации ответ на вопрос вы будете искать в логах!
Файлы логирования
Уровни логирования
В идеале логи пишутся во время работы всех IT-систем, однако если писать все подряд и «складывать в кучу», полезная информация превратится в хаос. Чтобы упростить поиск и чтение логов, их делят на уровни. Основных четыре:
-
Debug — запись масштабных переходов состояний, например, обращение к базе данных, старт/пауза сервиса, успешная обработка записи и пр.
-
Warning — нештатная ситуация, потенциальная проблема, может быть странный формат запроса или некорректный параметр вызова.
-
Error — типичная ошибка.
-
Fatal — тотальный сбой работоспособности, когда нет доступа к базе данных или сети, сервису не хватает места на жестком диске.
Дополнительно файл логирования может расширяться записями еще двух уровней:
-
Trace — пошаговые записи процесса. Полезен, когда сложно локализовать ошибку.
-
Info — общая информация о работе службы или сервиса.
Работа с уровнями логирования регламентируется методическими документами и внутренними правилами организации. В них может определяться соответствие источника сообщения уровню логирования, значимость, порядок обработки каждого уровня и другие параметры.
Типы логов
Для удобства обработки логов их делят на типы:
-
системные, связанные с системными событиями,
-
серверные, отвечающие за процесс обращения к серверу,
-
почтовые, работающие с отправлениями,
-
логи баз данных, которые отражают процессы обращения к базам данных,
-
авторизационные и аутентификационные, которые отвечают за процесс входа, выхода из системы, восстановление доступа и пр.
У каждого типа логов свой журнал записи. Для проверки логов авторизации нужно идти в журнал доступов, чтобы проверить загрузку системы — в журнал dmesg, за данными о запросах пользователей — в access_log. Когда одни логи пишутся отдельно от других, проще диагностировать ситуацию и найти источник проблемы.
Логи в access_log
Инструменты для работы с логами
Сбор, хранение и анализ логов вручную хороши, когда у вас один сервер. Когда серверный парк разрастается, а приложений и сервисов становится больше десяти, работу с логами целесообразно автоматизировать и использовать специальные системы логирования, например, Graylog, ELK, Loggy или Splunk. Некоторые из них позволяют организовать полномасштабный мониторинг, настроить алерт раннего обнаружения конкретной проблемы или установить пороговые значения показателей, коррелирующих с угрозами информационной безопасности.
Логи сетевого, инженерного оборудования, баз данных и приложений мы храним в облачном хранилище. И вам советуем. Даже когда у вас полно места на жестких дисках и стоит мощная защита на все случаи жизни. Оборудование рано или поздно, а чаще неожиданно, выходит из строя, а злоумышленники давно умеют чистить файлы логирования, так что логи в облаке — это возможность восстановить события и расследовать инцидент даже при полном отказе системы.

Хранение логов в облаке
Логирование кажется второстепенным процессом, который занимает время, но не дает видимых результатов. Однако это только кажется и только до тех пор, пока не появится реальная проблема, с которой можно разобраться только по логам. И только если они записаны, распределены по уровням, собираются и доступны для анализа.