
О LENOVO
+
О LENOVO
-
Наша компания
-
Новости
-
Контакт
-
Соответствие продукта
-
Работа в Lenovo
-
Общедоступное программное обеспечение Lenovo
КУПИТЬ
+
КУПИТЬ
-
Где купить
-
Рекомендованные магазины
-
Стать партнером
Поддержка
+
Поддержка
-
Драйверы и Программное обеспечение
-
Инструкция
-
Инструкция
-
Поиск гарантии
-
Свяжитесь с нами
-
Поддержка хранилища
РЕСУРСЫ
+
РЕСУРСЫ
-
Тренинги
-
Спецификации продуктов ((PSREF)
-
Доступность продукта
-
Информация об окружающей среде
©
Lenovo.
|
|
|
|
Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>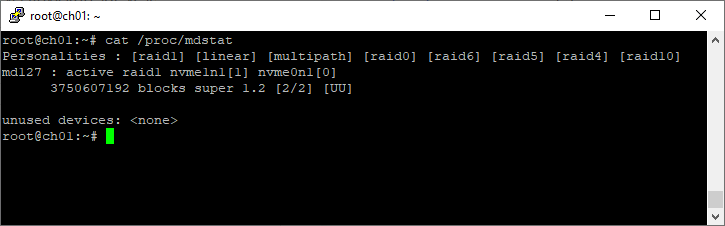
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1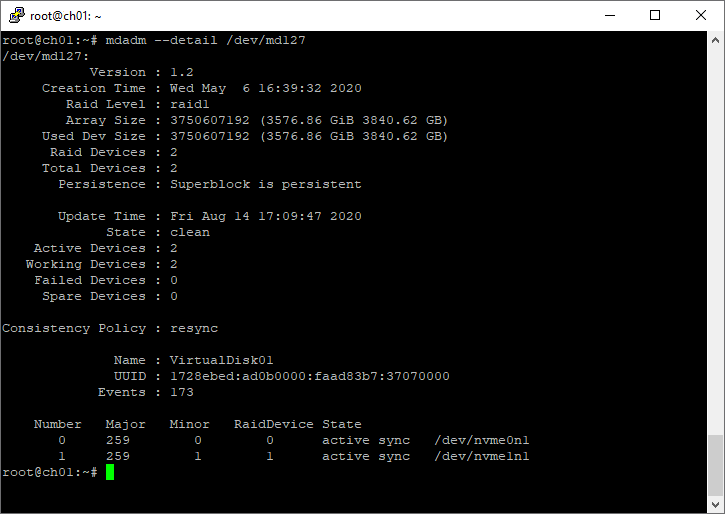
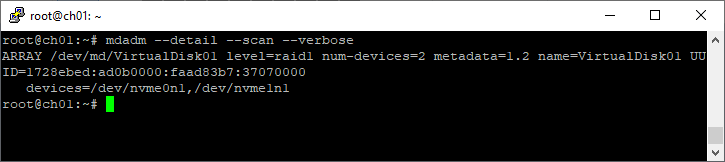
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) — отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.

 Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
 В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
 Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
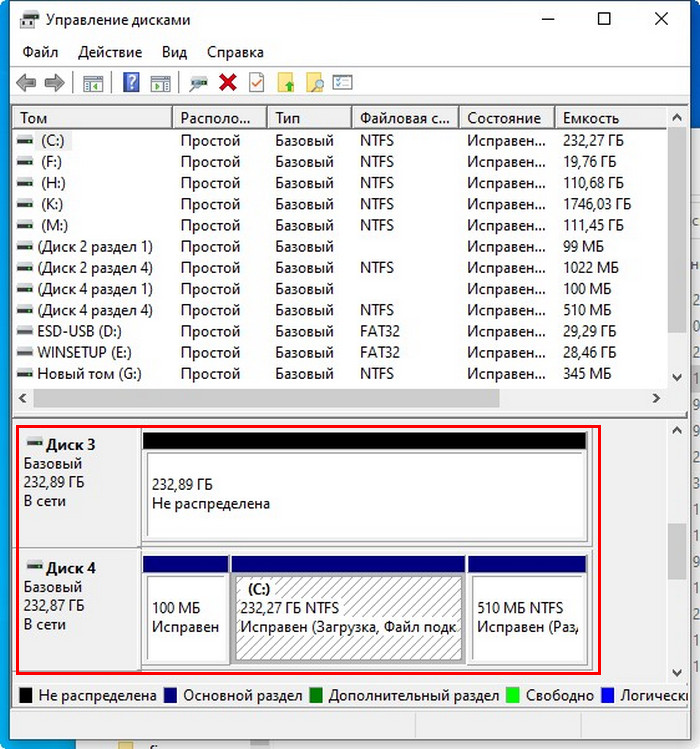 Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне обслуживает массивы RAID в конфигурациях 0, 1, 5, 10. Предоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов.

После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
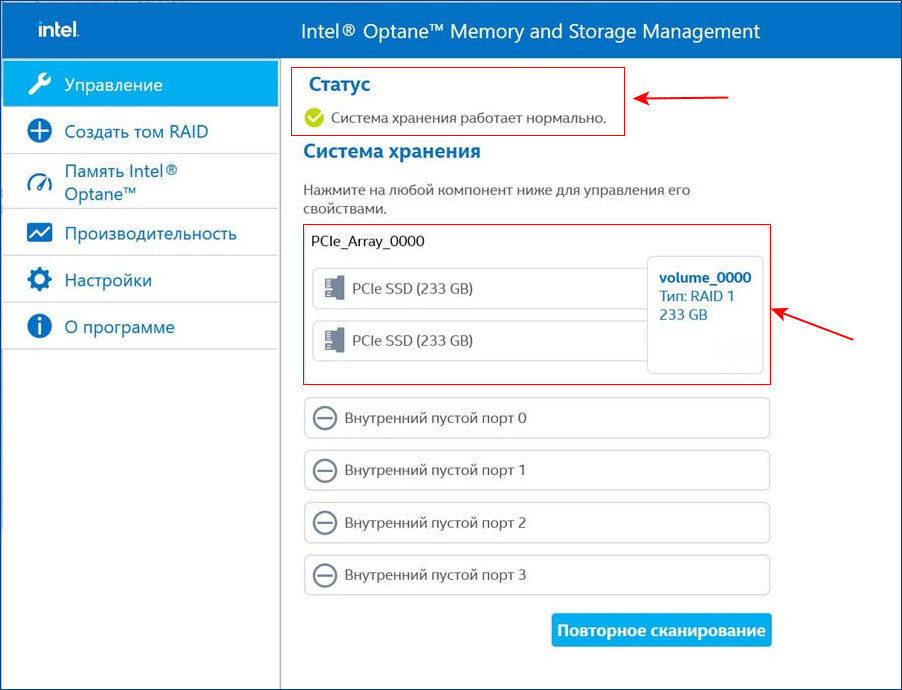 Вот этот массив в управлении дисками Windows.
Вот этот массив в управлении дисками Windows.
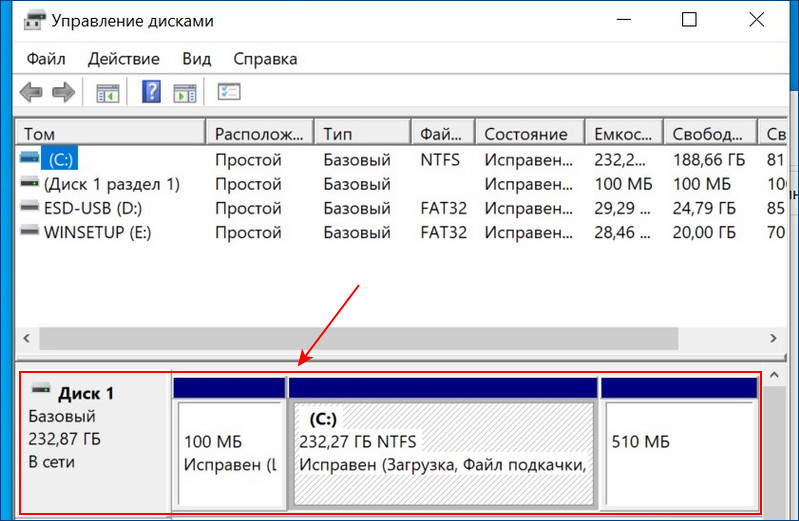 И в диспетчере устройств.
И в диспетчере устройств.
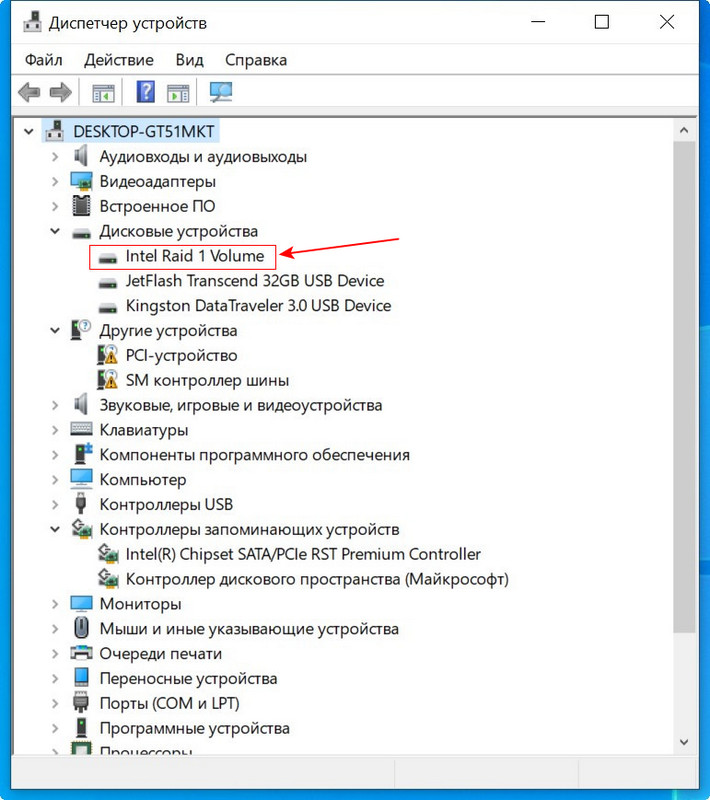 Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
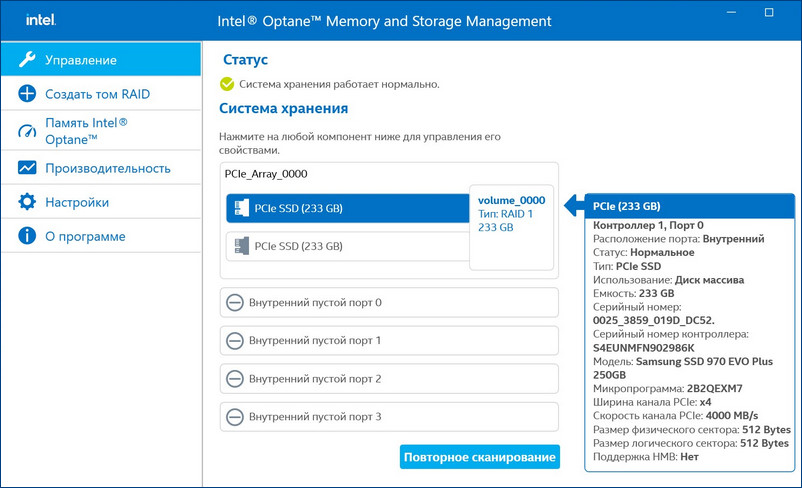 Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
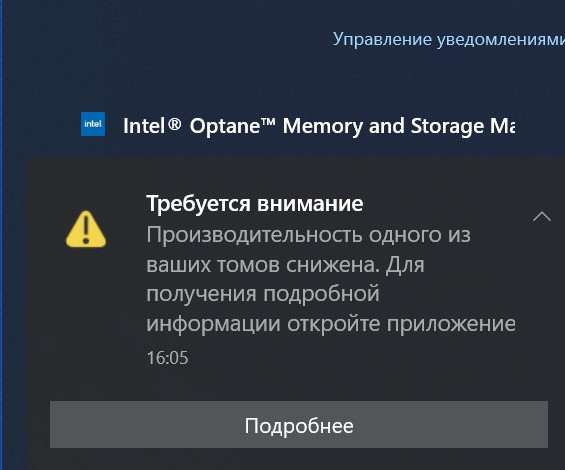 И в главном окне программы будет значиться, что один из дисков массива неисправен.
И в главном окне программы будет значиться, что один из дисков массива неисправен.
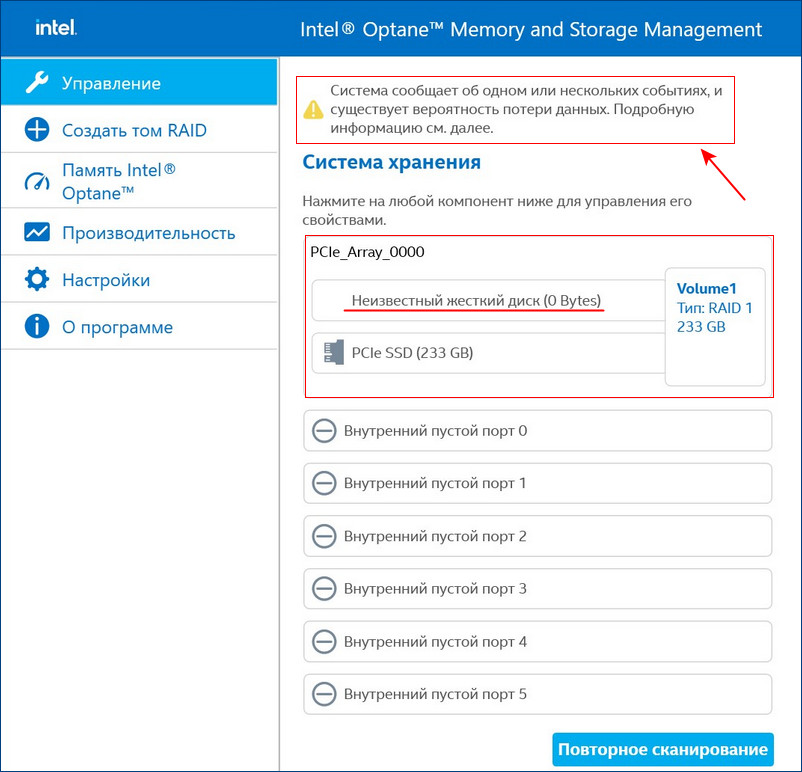 В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
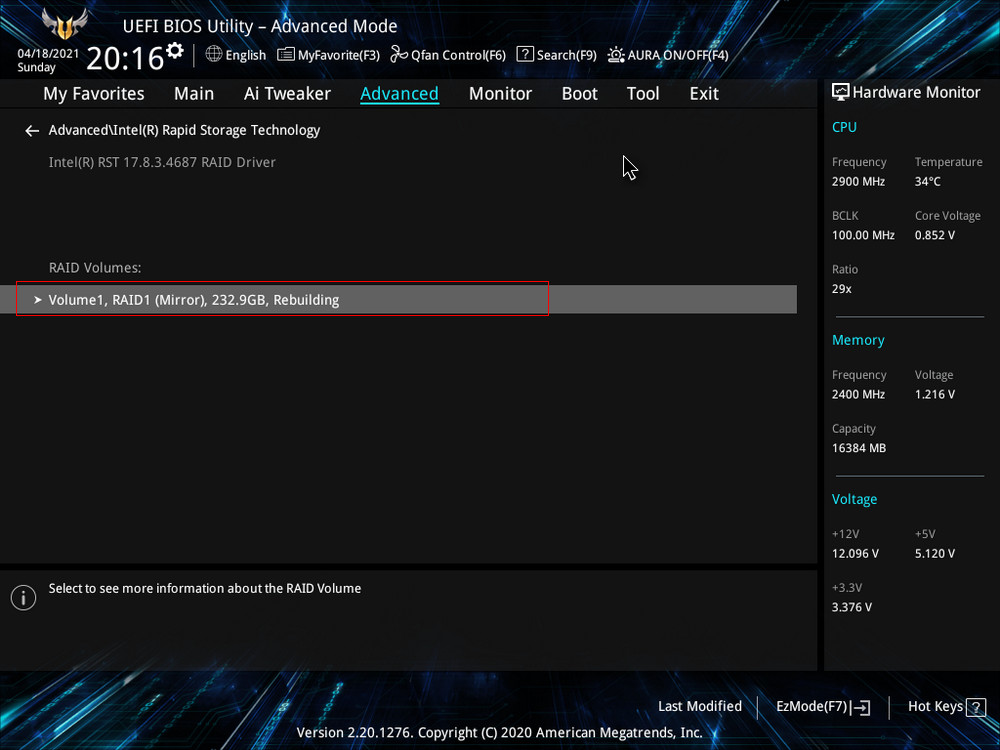
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
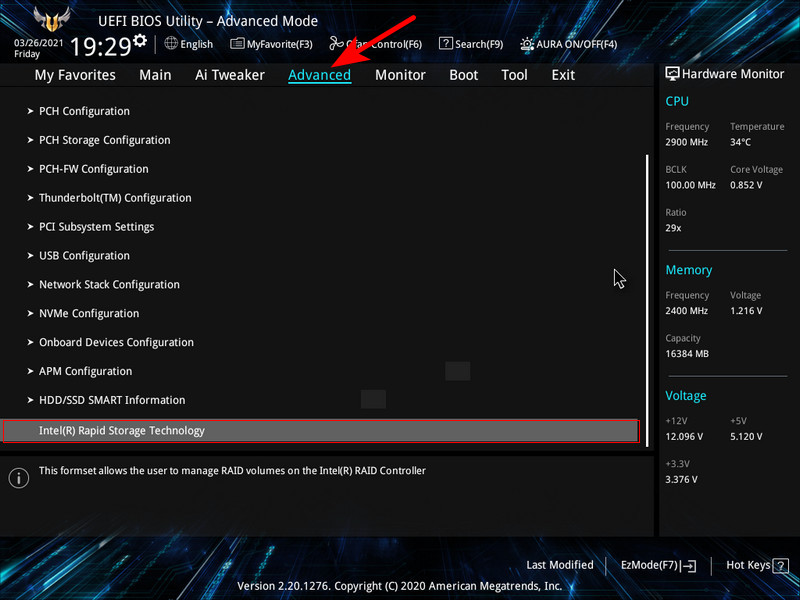
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен — «Volume 1 RAID 1 (mirroring), Degraded».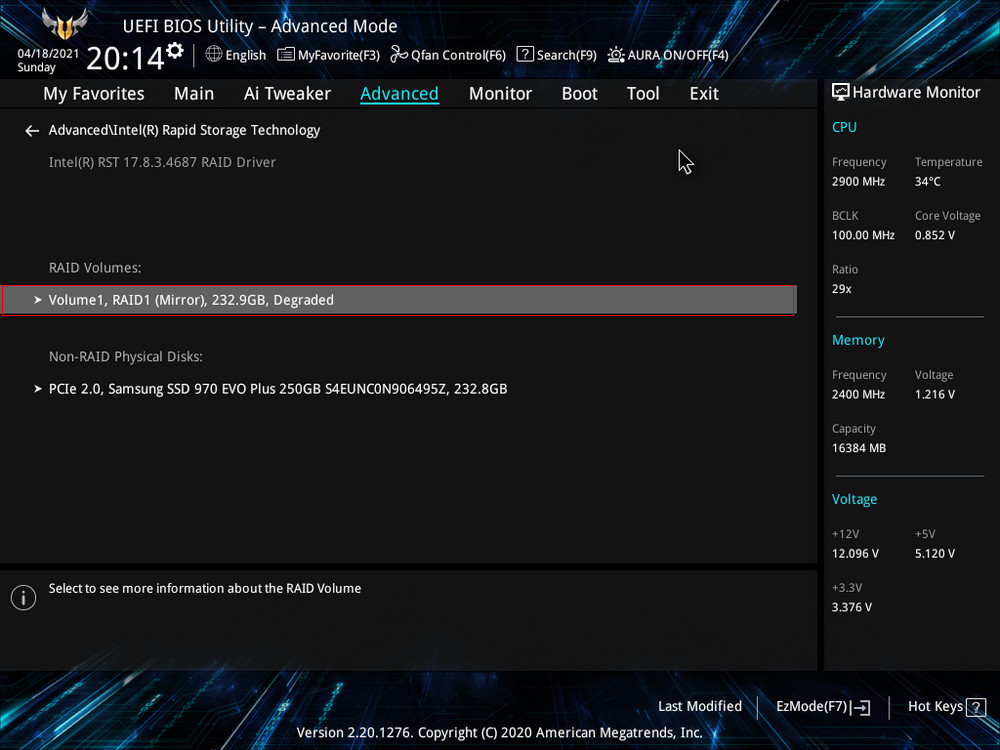 Выбираем «Rebuild» (Восстановить).
Выбираем «Rebuild» (Восстановить).
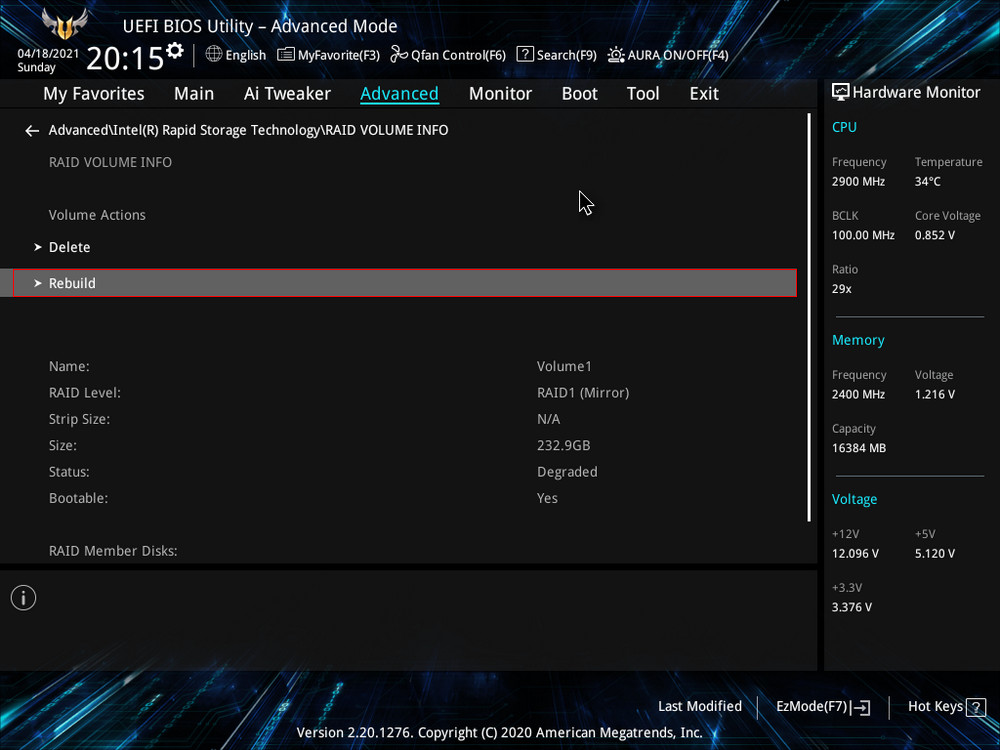 Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».
Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».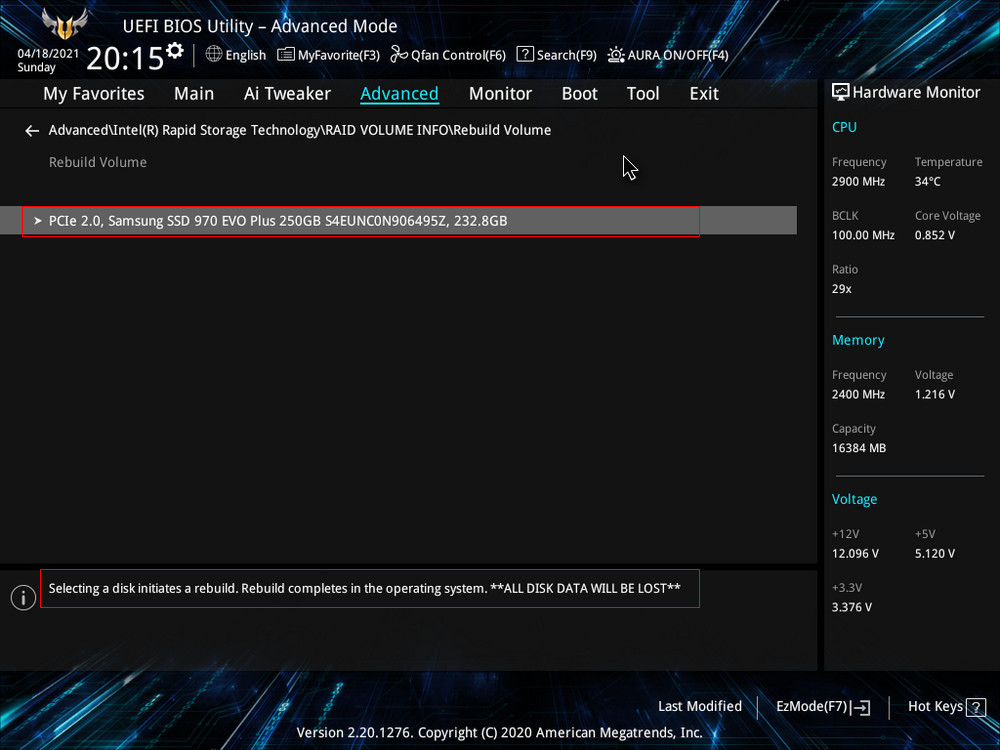 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
 Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
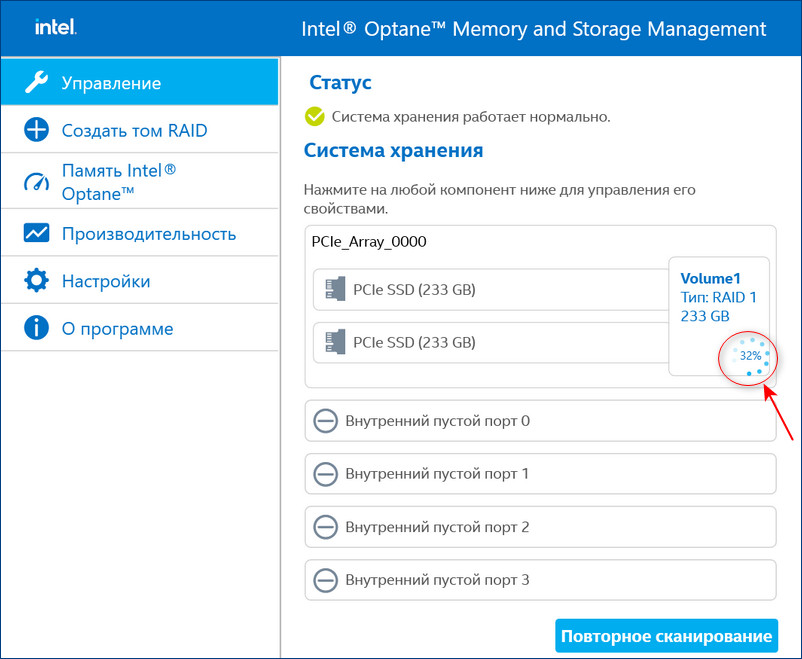
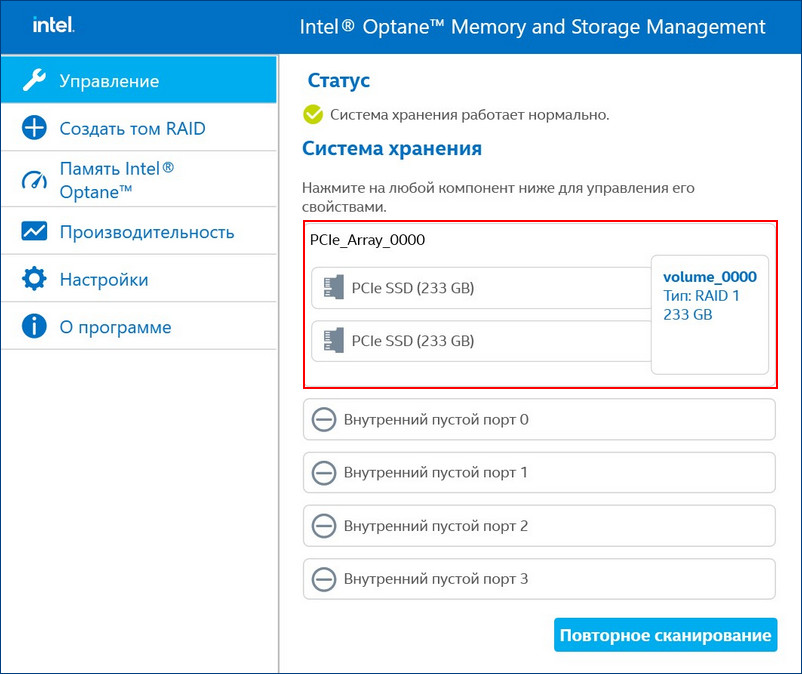
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
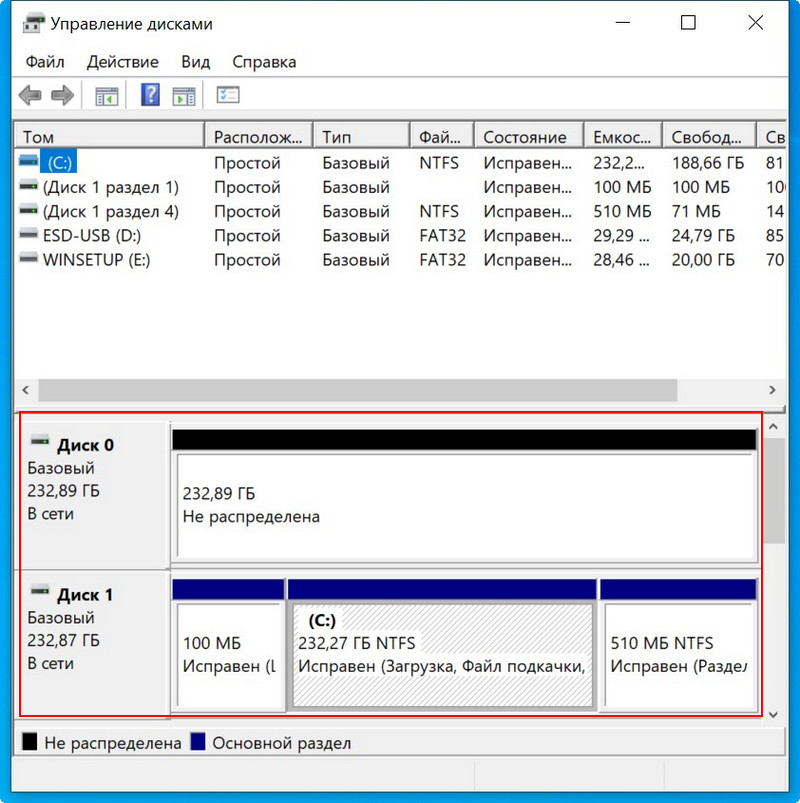 Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
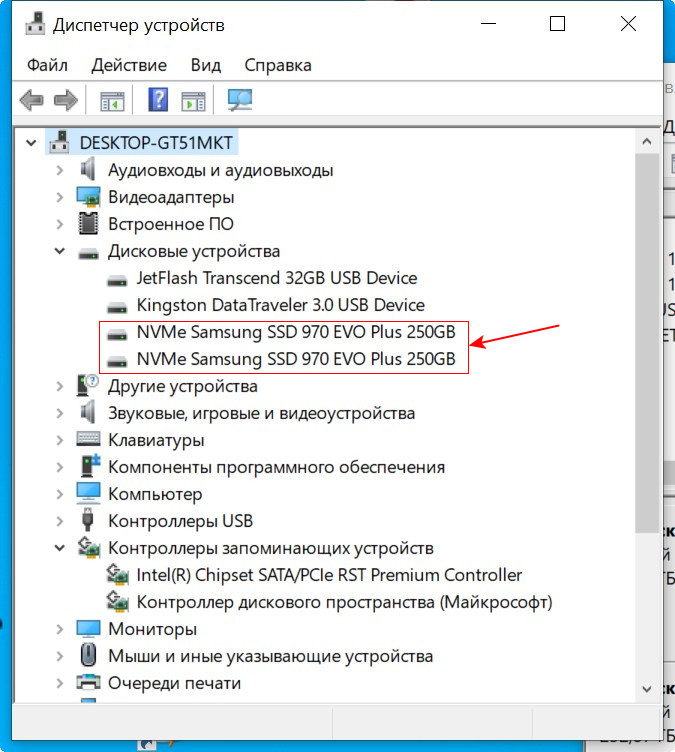 В главном окне программы жмём «Создать том RAID».
В главном окне программы жмём «Создать том RAID».
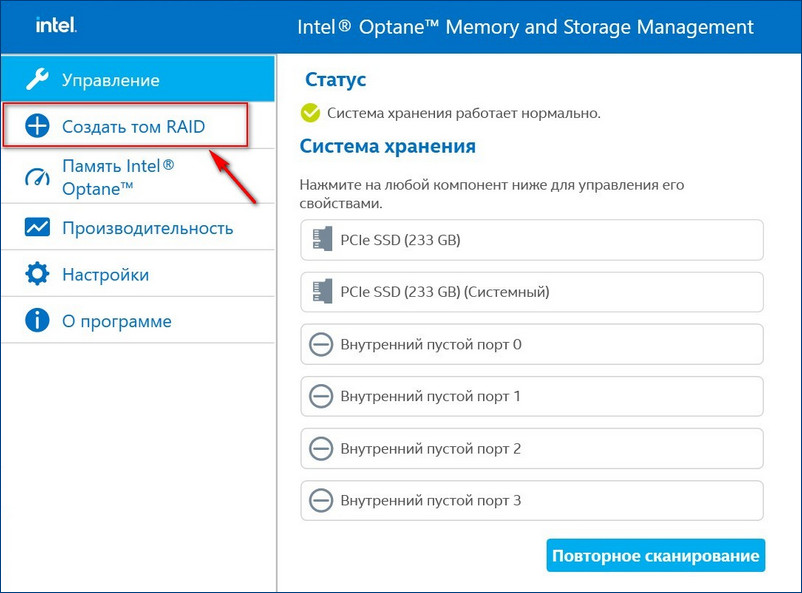 У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
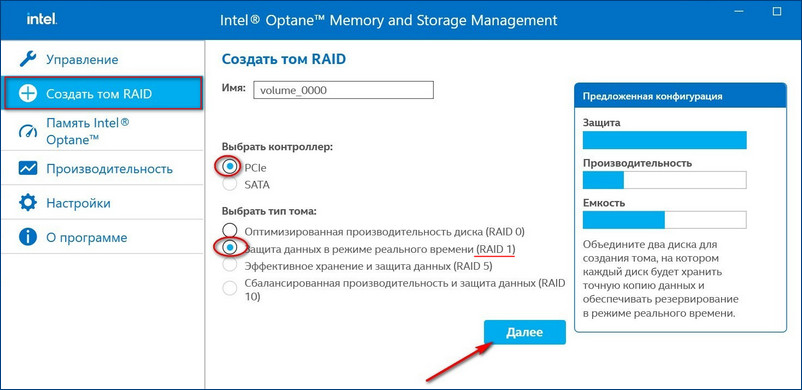 Выбираем два наших диска SSD PCIe M.2 NVMe.
Выбираем два наших диска SSD PCIe M.2 NVMe.
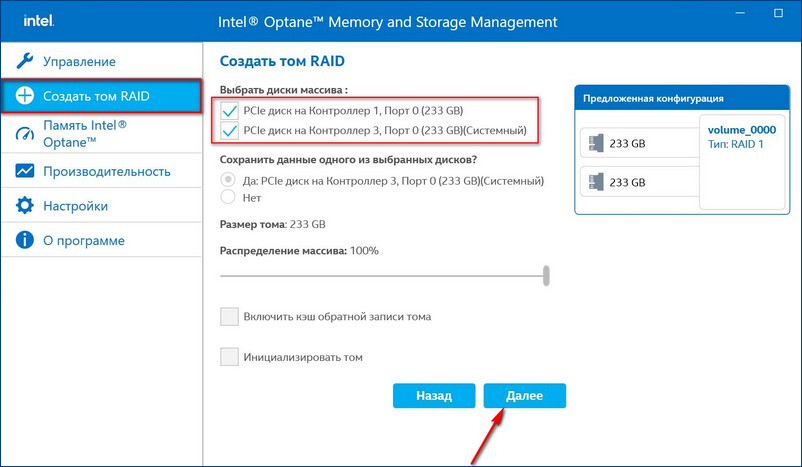 Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».  Можем наблюдать процесс восстановления массива.
Можем наблюдать процесс восстановления массива.
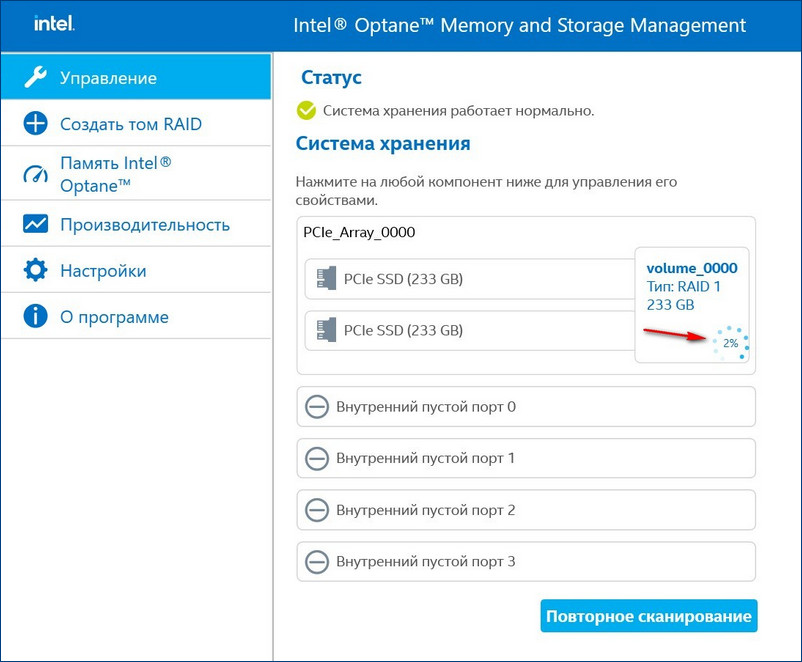 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
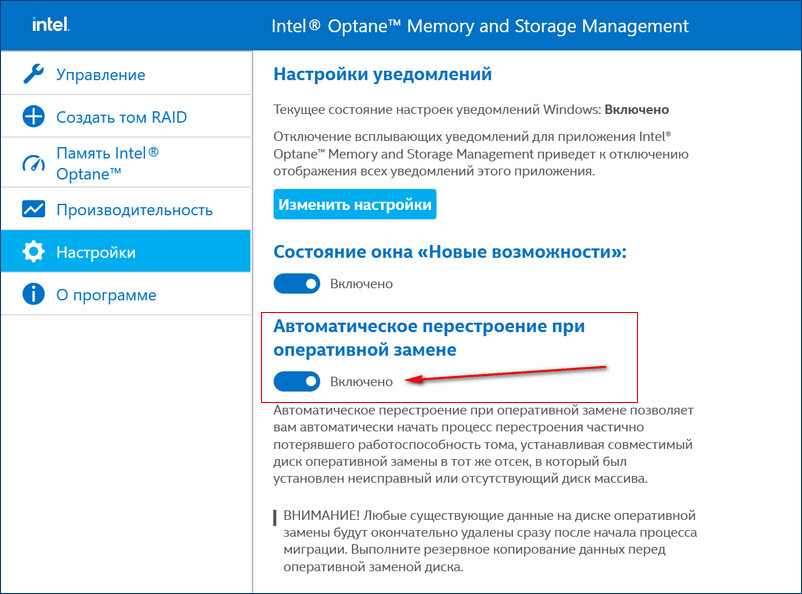
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Модераторы: Trinity admin`s, Free-lance moderator`s
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
5 RAID, чем проверить диски на бэды в массиве?
Есть 5 RAID Adaptec3200S на 5 винтах (Fujitsu MAN 3184NC). При загрузке, в логах W2K server появились ругательства на bad блоки:
1)Source: Disk Event: 11
The driver detected a controller error on DeviceHarddisk0DR0.
2)Source: Disk Event: 34
The driver disabled the write cache on device DeviceHarddisk0DR0.
Первое сообщение горит как Error, второе — Warning.
Иногда появляется сообщение, что контроллер детектирует Bad Block.
На сервере крутятся базы, поэтому вынимать винты и проверять на отдельном контроллере возможности нет. Чем можно провести проверку поверхности дисков прямо в рейде? Возможность выключить сервер есть.
-

gs
- Сотрудник Тринити

- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:

Сообщение
gs » 26 авг 2004, 17:06
consystency check из Adaptec Storage Manager или как он называется у адаптека (verify…)
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 26 авг 2004, 17:29
верификация Adaptec Storage Manager показывает, что диски в порядке, статус — optimal. Есть ли еще смысл дергаться и проверять чем то другим. Хотя непонятно, откуда тогда ошибка в логах Винды.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 26 авг 2004, 17:37
Если верифай проходит, то винты в порядке.
Кстати по логу не понятно, что это именно бэды. Вполне возможен сбой драйвера или контроллера (память его например).
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 27 авг 2004, 11:53
дословно сообщение о бэд-блоке звучит:
The device, Deviceharddisk0DR0, has a bad block.
ID — 7
Status- error.
Проверил логи, появляется прикаждой загрузке.
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:

Сообщение
ALEX_SE » 27 авг 2004, 15:33
Гхм…
Своеобразный массив — при загрузке у него, значит, беды есть, а потом они исчезают ![]() А вендозная программка от массива, в характеристиках дисков ничего такого не дает? Или в логах? Можен это он каждый раз одну и туже когда-то нейденную ошибку дает?
А вендозная программка от массива, в характеристиках дисков ничего такого не дает? Или в логах? Можен это он каждый раз одну и туже когда-то нейденную ошибку дает?
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 14:40
в логах ничего нет. Они вообще чистые. Никаких ругательств программа тоже не выдает. На Адаптеке нашел описание похожей ошибки, возникает, когда загрузочное устройство не поддерживает один из запросов Винды. Буду дальше разбираться.
-
a_shats
- Advanced member
- Сообщения: 5010
- Зарегистрирован: 27 авг 2002, 10:55
- Откуда: Москва
- Контактная информация:

Сообщение
a_shats » 31 авг 2004, 14:52
Подозрение одно есть: часто именно процессоры SAF-TE имеют такой SCSI ID (7). Понятно, что Win и не может ни писать на них, ни читать с ![]() .
.
Возможный вариант решения — если вышеописанное правда — поставить дрова для бэкплейна (точнее, все того же SAF-TE). Взять — либо на сайте вендора корпуса, если нет — часто применяются GEM от QLogic, на их сайте тоже дрова от них есть.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 31 авг 2004, 19:38
Вообще-то SCSI ID7 — это как правило сам контроллер ![]()
Вот только через рэйд дисковые каналы не должно быть видно…
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:
Сообщение
ALEX_SE » 31 авг 2004, 20:01
gs
Ага — так и есть! SAF-TE там имеют ID 4 и 5 на разных корзинах. 7 — это контроллер. Который, кстати, ни BIOS ни утилитами от RAID вроде как не показывают ![]()
Только одно НО — с какого перепуга винда его за диск-то сочла?..![]() И почему только при загрузке?[/b]
И почему только при загрузке?[/b]
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 20:21
корпус от Intel, а чья корзина не знаю, корпус опломбирован.
А ставить какие попало дрова страшно, чтобы все благополучно не рухнуло.
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 20:55
дело в том, что RAID используется в качестве загрузочного устройства, Винда стоит на нем и воспринимает его как диск.
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:
Сообщение
ALEX_SE » 01 сен 2004, 06:01
Правильные ли драйверы стоят на контроллер и на HSBP? И стоят ли вообще?
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 01 сен 2004, 10:55
На Адаптек 3200, стоят виндошные драйвера : Adaptec RAID-5 SCSI Disk Device.
НВ HSBP драйвера не стоят вообще. Система его видит в OTHER DEVICES как ESG-SHV SCA HSBP M14 SCSI Processor Device.
Что это за устойство,как его идентифицировать и какие подставить драйвера, я не знаю.
Вернуться в «Массивы — Технические вопросы, решение проблем.»
Перейти
- Серверы
- ↳ Серверы — Конфигурирование
- ↳ Конфигурации сервера для 1С
- ↳ Серверы — Решение проблем
- ↳ Серверы — ПО, Unix подобные системы
- ↳ Серверы — ПО, Windows система, приложения.
- ↳ Серверы — ПО, Базы Данных и их использование
- ↳ Серверы — FAQ
- Дисковые массивы, RAID, SCSI, SAS, SATA, FC
- ↳ Массивы — RAID технологии.
- ↳ Массивы — Технические вопросы, решение проблем.
- ↳ Массивы — FAQ
- Майнинг, плоттинг, фарминг (Добыча криптовалют)
- ↳ Proof Of Work
- ↳ Proof Of Space
- Кластеры — вычислительные и отказоустойчивые ( SMP, vSMP, NUMA, GRID , NAS, SAN)
- ↳ Кластеры, Аппаратная часть
- ↳ Deep Learning и AI
- ↳ Кластеры, Программное обеспечение
- ↳ Кластеры, параллельные файловые системы
- Медиа технологии, и цифровое ТВ, IPTV, DVB
- ↳ Станции видеомонтажа, графические системы, рендеринг.
- ↳ Видеонаблюдение
- ↳ Компоненты Digital TV решений
- ↳ Студийные системы, производство ТВ, Кино и рекламы
- Инфраструктурное ПО и его лицензирование
- ↳ Виртуализация
- ↳ Облачные технологии
- ↳ Резервное копирования / Защита / Сохранение данных
- Сетевые решения
- ↳ Сети — Вопросы конфигурирования сети
- ↳ Сети — Технические вопросы, решение проблем
- Общие вопросы
- ↳ Обсуждение общих вопросов
- ↳ Приколы нашего IT городка
- ↳ Регистрация на форуме
Управление дисковым массивом работающего на аппаратном контроллере LSI MegaRAID, мы рекомендуем производить с помощью консольного клиента MegaCLI
Установка MegaCLI:
wget http://www.lsi.com/downloads/Public/RAID%20Controllers/RAID%20Controllers%20Common%20Files/.zip
unzip 8.07.07_MegaCLI.zip
cd 8.07.07_MegaCLI/
chmod +x MegaCli
Основные команды для работы:
Получить статус и конфигурацию всех адаптеров
megacli -AdpAllInfo -aAll
Cтатус и параметры всех логических дисков
megacli -LDInfo -LAll -aAll
Статус и параметры физических устройств
megacli -PDList -a0
Статус и параметры диска в 4-м слоте
megacli -pdInfo -PhysDrv[252:4] -a0
Создание RAID6 массив MegaCLI
Давайте предположим, что у нас есть сервер с MegaRAID SAS
Получим список физических дисков:
megacli -PDlist -a0 | grep -e ‘^Enclosure Device ID:’ -e ‘^Slot Number:’
Enclosure Device ID: 29
Slot Number: 0
Enclosure Device ID: 29
Slot Number: 1
Enclosure Device ID: 29
Slot Number: 2
Enclosure Device ID: 29
Slot Number: 3
Enclosure Device ID: 29
Slot Number: 4
Enclosure Device ID: 29
Slot Number: 5
Enclosure Device ID: 29
Slot Number: 6
Enclosure Device ID: 29
Slot Number: 7
Enclosure Device ID: 29
Slot Number: 8
Enclosure Device ID: 245
Slot Number: 12
Пример конфигурирования JBOD на LSI 2208 (Supermicro X9DRH-7TF) При загрузке BIOS эти команды можно выполнить если зайти в preboot CLI по комбинации клавиш Ctrl+Y
Команды megacli и preboot CLI различаются по виду.
Например команда проверки поддержки JBOD для BIOS preboot CLI будет выглядеть так:
AdpGetProp enablejbod -aALL
А для megacli это используется как набор опций и параметров:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOB
megacli -AdpSetProp EnableJBOD 1 -aALL
Список доступных физических устройств:
megacli -PDList -aALL -page24
В списке надо найти значения полей Enclosure Device ID (например 252), Slot Number и Firmware state
Нужно отметить каждое из устройств которое надо сделать JBOD, как Good в поле Firmware state .
megacli -PDMakeGood -PhysDrv[252:0] -Force -a0
Или сразу много устройств:
megacli -PDMakeGood -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -Force -a0
Теперь можно создавать JBOD
megacli -PDMakeJBOD -PhysDrv[252:0] -a0
megacli -PDMakeJBOD -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -a0
Создать виртуальный диск RAID
Перед настройкой массива, возможно, потребуется удалить использованную ранее конфигурацию. Для того чтобы просто удалить логические устройства используйте CfgLdDel
megacli -CfgLdDel -Lall -aAll
Для того чтобы удалить всё (в том числе политику кэша) используйте «Очистку конфигурации»
megacli -CfgClr -aAll
Настройка RAID-0, 1 или 5. Вместо «r0» введите соответственно «r1» или «r5» (диски находятся в Enclosure 29, на портах 0 и 1, WriteBack включен, ReadCache адаптивный, Cache также включен без BBU)
megacli -CfgLdAdd -r0 [29:0,29:1] WB ADRA Cached CachedBadBBU -sz196GB -a0
Создать RAID10 Получить список дисков
megacli -PDList -aAll | egrep «Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state»
Создать массив из 6 дисков
megacli -CfgSpanAdd -r10 -Array0[252:0,252:1] -Array1[252:2,252:4] [-Array2[252:5,252:6] -a0
Показать как диски были определены в RAID-массиве:
megacli -CfgDsply -a0
Удалить массив с ID=2
MegaCli –CfgLDDel -L2 -a0
Инициализация массива Начать полную инициализацию для массива с ID=0
MegaCli -LDInit -Start -full -L0 -a0
Проверить текущий статус инициализации:
MegaCli -LDInit -ShowProg -L0 -a0
Управление CacheCade
Создать и назначить CacheCade для массива 0 (-L0) из зеркала (-r1) в режиме обратной записи (WB) на основе SSD дисков в слотах 6 и 7 (-Physdrv[252:6,252:7])
megacli -CfgCacheCadeAdd -r1 -Physdrv[252:6,252:7] WB -assign -L0 -a0
Включить
megacli -Cachecade -assign -L0 -a0
Отключить
megacli -Cachecade -remove -L0 -a0
Successfully removed VD from Cache
Просмотреть состояние:
megacli -CfgCacheCadeDsply -a0
megacli -LDInfo -LAll -a0
Замена неисправного диска
Отключить писк:
megacli -AdpSetProp -AlarmSilence -a0
Обратите внимание, что это не навсегда отключает сигнализацию, а просто выключает сигнал по текущей аварии.
Просмотреть состояние диска (подставьте нужное значение [E:S]):
megacli -pdInfo -PhysDrv [29:8] -a0
Пометить диск требующий замены как потерянный (если контроллер не сделал этого сам)
megacli -PDMarkMissing -PhysDrv [E:S] -aN
Получить параметры потерянного диска
megacli -Pdgetmissing -a0
Вы должны получить ответ подобный этому:
Adapter 0 — Missing Physical drives
No. Array Row Size Expected
0 0 4 1907200 MB
Подсветить диск который надо менять (подставьте нужное значение [E:S]):
megacli -PdLocate -start -PhysDrv [29:8] -a0
На некоторых шасси могут быть проблемы с индикацией. Это лечится такой командой:
megacli -AdpSetProp {UseDiskActivityforLocate -1} -aALL
В этом случае для маркировки диска будет использоваться лампочка активности.
Удаляем неисправный и вставляем новый диск.
Прекращаем подсветку и проверяем состояние диска:
megacli -PdLocate -stop -PhysDrv [29:8] -a0
megacli -pdInfo -PhysDrv [29:8] -a0
Может так случится, что он содержит метаданные от другого массива RAID (Foreign Configuration). Ваш контроллер не позволит использовать такой диск. Для проверки наличия Foreign Configuration
megacli -CfgForeign -Scan -aALL
Команда удаления Foreign Configuration (если вы уверены)
megacli -CfgForeign -Сlear -aALL<code>
Запускаем процесс замены
<code>megacli -PdReplaceMissing -PhysDrv [32:4] -Array0 -row4 -a0
[32:4] — это параметры диска которым вы меняете неисправный
Rebuild drive
megacli -PDRbld -Start -PhysDrv [32:4] -a0
Проверка процесса ребилда
megacli -PDRbld -ShowProg -PhysDrv [32:4] -a0
Использование smartctl
Получить список id
megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример скрипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Для контроля состояния дисков с помощью демона smartd нужно закомментировать DEVICESCAN в /etc/smartd.conf и добавить:
/dev/sda -d sat+megaraid,0 -a -s L/../../3/02
/dev/sda -d sat+megaraid,1 -a -s L/../../3/03
/dev/sda -d sat+megaraid,2 -a -s L/../../3/04
/dev/sda -d sat+megaraid,3 -a -s L/../../3/05
Значения параметров типа /3/02 — /3/05 определяют время запуска тестов для заданного диска
Содержание
- Как проверить raid массив windows
- Поиск и замена диска поврежденного диска в Raid-1
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг raid массивов в Windows Core
- Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
- Настройка RAID
- Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
- Пару слов о дисках и мат. плате
- Пример настройки RAID 0 в BIOS
- Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Как проверить raid массив windows

Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.

Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″> » width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.

в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:

В зависимости от количества разделов выполняем соответственно для разных разделов:
Далее команда на удаление из RAID
Для проверки типа разбиения надо выполнить следующую команду:
на не замененном диске
После этого выполнить команду:
(для MBR), и
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
(для GPT)
Источник
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |

Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
Элементы управления окна Проверка корректности RAID
 Элементы управления окна Проверка корректности RAID
Элементы управления окна Проверка корректности RAID Номер первого сектора в ряде.
Переход к предыдущей/следующей порции данных.
Источник
Мониторинг raid массивов в Windows Core

За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:

UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
 Доброго дня!
Доброго дня!
Согласитесь, звучит заманчиво?! Однако, многим пользователям слово «RAID» — либо вообще ничего не говорит, либо напоминает что-то такое отдаленное и сложное (явно-недоступное для повседневных нужд на домашнем ПК/ноутбуке). На самом же деле, все проще, чем есть. 👌 (разумеется, если мы не говорим о каких-то сложных производственных задачах, которые явно не нужны на обычном ПК)
Собственно, ниже в заметке попробую на доступном языке объяснить, как можно объединить диски в эти RAID-массивы, в чем может быть их отличие, и «что с чем едят».

Настройка RAID
Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
Обратите внимание также на табличку ниже.


Разумеется, видов RAID-массивов гораздо больше (RAID 5, RAID 6, RAID 10 и др.), но все они представляют из себя разновидности вышеприведенных (и, как правило, в домашних условиях не используются).
Пару слов о дисках и мат. плате
Не все материнские платы поддерживают работу с дисковыми массивами RAID. И прежде, чем переходить к вопросу объединению дисков, необходимо уточнить этот момент.
Как это сделать : сначала с помощью спец. утилит (например, AIDA 64) нужно узнать точную модель материнской платы компьютера.
Далее найти спецификацию к вашей мат. плате на официальном сайте производителя и посмотреть вкладку «Хранение» (в моем примере ниже, мат. плата поддерживает RAID 0, RAID 1, RAID 10).

Спецификация материнской платы
Если ваша плата не поддерживает нужный вам вид RAID-массива, то у вас есть два варианта выхода из положения:

RAID-контроллер (в качестве примера)
Важная заметка : RAID-массив при форматировании логического раздела, переустановки Windows и т.д. — не разрушится. Но при замене материнской платы (при обновлении чипсета и RAID-контроллера) — есть вероятность, что вы не сможете прочитать информацию с этого RAID-массива (т.е. информация не будет недоступна. ).
Что касается дисков под RAID-массив :
Пример настройки RAID 0 в BIOS
Важно : при этом способе информация с дисков будет удалена!
Примечание : создать RAID-массив можно и из-под Windows (например, если вы хотите в целях безопасности сделать зеркальную копию своего диска).
1) И так, первым делом необходимо подключить диски к компьютеру (ноутбуку). Здесь на этом не останавливаюсь.
2) Далее нужно зайти в BIOS и установить 2 опции:
Затем нужно сохранить настройки (чаще всего это клавиша F10) и перезагрузить компьютер.


Intel Rapid Storage Technology

Create RAID Volume
5) Теперь нужно указать:
После нажатия на кнопку Create Volume — RAID-массив будет создан, им можно будет пользоваться как обычным отдельным накопителем.


Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Рассмотрю ниже пару конкретных примеров.
2) Открываете управление дисками (для этого нужно: нажать Win+R, и в появившемся окне ввести команду diskmgmt.msc).
3) Теперь действия могут несколько отличаться.
Вариант 1 : допустим вы хотите объединить два новых диска в один, чтобы у вас был большой накопитель для разного рода файлов. В этом случае просто кликните правой кнопкой мышки по одному из новых дисков и выберите создание чередующегося тома (это подразумевает RAID 0). Далее укажите какие диски объединяете, файловую систему и пр.

Создать чередующийся или зеркальный том

Вариант 2 : если же вы беспокоитесь за сохранность своих данных — то можно подключенный к системе новый диск сделать зеркальным вашему основному диску с ОС Windows, причем эта операция будет без потери данных (прим.: RAID 1).

4) После Windows начнет автоматическую синхронизацию накопителей: т.е. с выбранного вами раздела все данные будут также скопированы на новый диск.

5) В общем-то, всё, RAID 1 настроен — теперь при любых изменениях файлов на основном диске с Windows — они автоматически будут синхронизированы (перенесены) на второй диск.
6) Удалить зеркало, кстати, можно также из управления дисками : пример на скрине ниже.
Источник
Adblock
detector
| RAID 0 (распределение) | RAID 1 (зеркалирование) |
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
|
* |
Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID… контекстного меню |
|
> |
Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |
Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
|
|
|
|
|
|
|
|
|
|
|
|
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.

Элементы управления окна Проверка корректности RAID
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Модераторы: Trinity admin`s, Free-lance moderator`s
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
5 RAID, чем проверить диски на бэды в массиве?
Есть 5 RAID Adaptec3200S на 5 винтах (Fujitsu MAN 3184NC). При загрузке, в логах W2K server появились ругательства на bad блоки:
1)Source: Disk Event: 11
The driver detected a controller error on DeviceHarddisk0DR0.
2)Source: Disk Event: 34
The driver disabled the write cache on device DeviceHarddisk0DR0.
Первое сообщение горит как Error, второе — Warning.
Иногда появляется сообщение, что контроллер детектирует Bad Block.
На сервере крутятся базы, поэтому вынимать винты и проверять на отдельном контроллере возможности нет. Чем можно провести проверку поверхности дисков прямо в рейде? Возможность выключить сервер есть.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 26 авг 2004, 17:06
consystency check из Adaptec Storage Manager или как он называется у адаптека (verify…)
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 26 авг 2004, 17:29
верификация Adaptec Storage Manager показывает, что диски в порядке, статус — optimal. Есть ли еще смысл дергаться и проверять чем то другим. Хотя непонятно, откуда тогда ошибка в логах Винды.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 26 авг 2004, 17:37
Если верифай проходит, то винты в порядке.
Кстати по логу не понятно, что это именно бэды. Вполне возможен сбой драйвера или контроллера (память его например).
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 27 авг 2004, 11:53
дословно сообщение о бэд-блоке звучит:
The device, Deviceharddisk0DR0, has a bad block.
ID — 7
Status- error.
Проверил логи, появляется прикаждой загрузке.
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:
Сообщение
ALEX_SE » 27 авг 2004, 15:33
Гхм…
Своеобразный массив — при загрузке у него, значит, беды есть, а потом они исчезают ![]() А вендозная программка от массива, в характеристиках дисков ничего такого не дает? Или в логах? Можен это он каждый раз одну и туже когда-то нейденную ошибку дает?
А вендозная программка от массива, в характеристиках дисков ничего такого не дает? Или в логах? Можен это он каждый раз одну и туже когда-то нейденную ошибку дает?
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 14:40
в логах ничего нет. Они вообще чистые. Никаких ругательств программа тоже не выдает. На Адаптеке нашел описание похожей ошибки, возникает, когда загрузочное устройство не поддерживает один из запросов Винды. Буду дальше разбираться.
-
a_shats
- Advanced member
- Сообщения: 5010
- Зарегистрирован: 27 авг 2002, 10:55
- Откуда: Москва
- Контактная информация:
Сообщение
a_shats » 31 авг 2004, 14:52
Подозрение одно есть: часто именно процессоры SAF-TE имеют такой SCSI ID (7). Понятно, что Win и не может ни писать на них, ни читать с ![]() .
.
Возможный вариант решения — если вышеописанное правда — поставить дрова для бэкплейна (точнее, все того же SAF-TE). Взять — либо на сайте вендора корпуса, если нет — часто применяются GEM от QLogic, на их сайте тоже дрова от них есть.
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 31 авг 2004, 19:38
Вообще-то SCSI ID7 — это как правило сам контроллер ![]()
Вот только через рэйд дисковые каналы не должно быть видно…
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:
Сообщение
ALEX_SE » 31 авг 2004, 20:01
gs
Ага — так и есть! SAF-TE там имеют ID 4 и 5 на разных корзинах. 7 — это контроллер. Который, кстати, ни BIOS ни утилитами от RAID вроде как не показывают ![]()
Только одно НО — с какого перепуга винда его за диск-то сочла?..![]() И почему только при загрузке?[/b]
И почему только при загрузке?[/b]
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 20:21
корпус от Intel, а чья корзина не знаю, корпус опломбирован.
А ставить какие попало дрова страшно, чтобы все благополучно не рухнуло.
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 31 авг 2004, 20:55
дело в том, что RAID используется в качестве загрузочного устройства, Винда стоит на нем и воспринимает его как диск.
-
ALEX_SE
- Advanced member
- Сообщения: 594
- Зарегистрирован: 17 апр 2003, 10:23
- Откуда: Saratov
- Контактная информация:
Сообщение
ALEX_SE » 01 сен 2004, 06:01
Правильные ли драйверы стоят на контроллер и на HSBP? И стоят ли вообще?
-
trexx
- member
- Сообщения: 22
- Зарегистрирован: 08 июл 2004, 22:11
Сообщение
trexx » 01 сен 2004, 10:55
На Адаптек 3200, стоят виндошные драйвера : Adaptec RAID-5 SCSI Disk Device.
НВ HSBP драйвера не стоят вообще. Система его видит в OTHER DEVICES как ESG-SHV SCA HSBP M14 SCSI Processor Device.
Что это за устойство,как его идентифицировать и какие подставить драйвера, я не знаю.
Вернуться в «Массивы — Технические вопросы, решение проблем.»
Перейти
- Серверы
- ↳ Серверы — Конфигурирование
- ↳ Конфигурации сервера для 1С
- ↳ Серверы — Решение проблем
- ↳ Серверы — ПО, Unix подобные системы
- ↳ Серверы — ПО, Windows система, приложения.
- ↳ Серверы — ПО, Базы Данных и их использование
- ↳ Серверы — FAQ
- Дисковые массивы, RAID, SCSI, SAS, SATA, FC
- ↳ Массивы — RAID технологии.
- ↳ Массивы — Технические вопросы, решение проблем.
- ↳ Массивы — FAQ
- Майнинг, плоттинг, фарминг (Добыча криптовалют)
- ↳ Proof Of Work
- ↳ Proof Of Space
- Кластеры — вычислительные и отказоустойчивые ( SMP, vSMP, NUMA, GRID , NAS, SAN)
- ↳ Кластеры, Аппаратная часть
- ↳ Deep Learning и AI
- ↳ Кластеры, Программное обеспечение
- ↳ Кластеры, параллельные файловые системы
- Медиа технологии, и цифровое ТВ, IPTV, DVB
- ↳ Станции видеомонтажа, графические системы, рендеринг.
- ↳ Видеонаблюдение
- ↳ Компоненты Digital TV решений
- ↳ Студийные системы, производство ТВ, Кино и рекламы
- Инфраструктурное ПО и его лицензирование
- ↳ Виртуализация
- ↳ Облачные технологии
- ↳ Резервное копирования / Защита / Сохранение данных
- Сетевые решения
- ↳ Сети — Вопросы конфигурирования сети
- ↳ Сети — Технические вопросы, решение проблем
- Общие вопросы
- ↳ Обсуждение общих вопросов
- ↳ Приколы нашего IT городка
- ↳ Регистрация на форуме
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.
- Вводим команду для проверки состояния raid
cat /proc/mdstat
- Если в выводе в квадратных скобках стоит знак _ (например [U_]) — диск требуется заменить (он выпал из рейда).
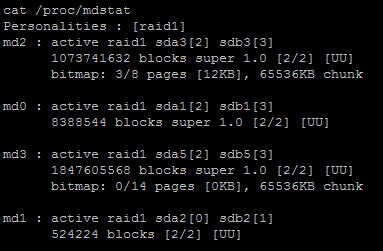
в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
- Если raid в порядке, то нужно проверить каждый диск отдельно следующей командой:
smartctl -a /dev/sd[X]
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
ls -l /dev/ | grep sd
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:
- количество перераспределенных секторов (Reallocated Sector)
- количество часов работы
- наличие ошибок смарт (сделайте коротки и расширенный тест SMART)
- нагрузка на диск в atop
- и другие параметры, определение неисправного диска по параметрам SMART, это тема отдельной статьи, поищите подробную информацию в интернете.
- Узнаём серийный номер неисправного диска командой:
smartctl -a /dev/sd[X]
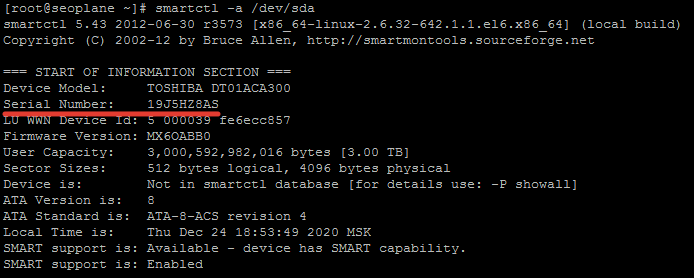
- Перед заменой диска крайне желательно необходимо сделать резервную копию данных
- Отключаем поврежденный диск от рейда. Для этого нужно пометить разделы диска как сбойные и изъять их из массива, для этого воспользуемся командой:
mdadm /dev/md0 -f /dev/sdb1 &&mdadm /dev/md0 -r /dev/sdb1
В зависимости от количества разделов выполняем соответственно для разных разделов:
mdadm /dev/md1 -f /dev/sdb2 &&mdadm /dev/md1 -r /dev/sdb2
mdadm /dev/md2 -f /dev/sdb3 &&mdadm /dev/md2 -r /dev/sdb3
Далее команда на удаление из RAID
mdadm /dev/md0 --remove /dev/sdb1
mdadm /dev/md1 --remove /dev/sdb2
mdadm /dev/md2 --remove /dev/sdb3
- Отправляем в дата-центр запрос на замену, к запросу также прикладываем модель и серийный номер исправного диска, узнать их можно командой:
hdparm -i /dev/
- После замены диска новый диск нужно разбить, в зависимости от типа разбиения диска (MBR или GPT).
Для проверки типа разбиения надо выполнить следующую команду:
gdisk -l /dev/sda
на не замененном диске
После этого выполнить команду:
sfdisk -d /dev/sda | sfdisk /dev/sdb
(для MBR), и
sgdisk -R /dev/sdb /dev/sda
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
sgdisk -G /dev/sdb
(для GPT)
- Добавить новый диск в массив командами:
mdadm /dev/md0 -a /dev/sdb1
mdadm /dev/md1 -a /dev/sdb2
mdadm /dev/md2 -a /dev/sdb3
- Добавить загрузчик командой:
grub-install /dev/sdb