
Корректирующие коды «на пальцах»
Время на прочтение
11 мин
Количество просмотров 63K
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):

- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
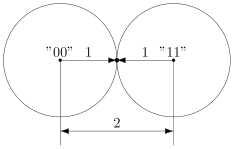
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
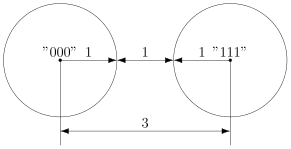
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.

Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Основными
характеристиками помехоустойчивых
кодов являются: длина кода n,
его основание m,
общее число кодовых комбинаций N,
число разрешенных кодовых комбинаций
Nр,
избыточность кода Ки
и минимальное кодовое расстояние dmin.
Длина
кода2
n
– это
число символов в кодовой комбинации.
Например, комбинация 11010 состоит из пяти
символов, следовательно, n=5.
Если все кодовые комбинации содержат
одинаковое число символов, то код
называется равномерным.
В неравномерных
кодах длина кодовых комбинаций может
быть разной.
Основание
кода m
– это число различных символов в коде.
Для двоичных кодов символами являются
1 и 0, поэтому m=2.
Число
кодовых комбинаций
для равномерного кода равно N=mn.
Например, для равномерного двоичного
кода, имеющего длину n=6,
число различных кодовых комбинаций
равно N=26=64.
Число
разрешенных кодовых комбинаций Nр
– это количество кодовых комбинаций
кода, используемых для передачи сообщений.
Для помехоустойчивых кодов Nр<N.
Оставшиеся кодовые комбинации N—Nр
называют запрещенными.
Если Nр=N,
то код является безызбыточным. Для
разделимых кодов Nр=2
k.
Избыточность
кода Ки
в общем случае определяется выражением
![]() .
.
(5.1)
и
показывает, какая доля длины кодовой
комбинации не используется для передачи
информации, а используется для повышения
помехоустойчивости кода. Для разделимых
кодов
![]() ,
,
(5.2)
где
величина k/n
называется относительной
скоростью кода.
Кодовое
расстояние d(А,В)
– это число позиций, в которых две
кодовые комбинации А
и В
отличаются друг от друга. Например, если
А=01101,
В=10111,то
d(А,В)=3.
Кодовое расстояние между комбинациями
А
и В
может быть найдено в результате сложения
по модулю 2 одноименных разрядов
комбинаций, а именно
![]() ,
,
(5.3)
где
ai
и
bi
– i-е
разряды кодовых комбинаций A
и
B;
символ
обозначает сложение по модулю 2. Например,
чтобы получить кодовое расстояние между
комбинациями 1101011 и 0111101 достаточно
подсчитать число единиц в сумме этих
комбинаций по модулю 2:

Кодовое
расстояние между различными комбинациями
конкретного кода может быть различным.
Так, для первичных кодов (приложения 1,
2) это расстояние для различных пар
кодовых комбинаций может принимать
значения от единицы до величины длины
кода.
Минимальное
кодовое расстояние dmin
–
это минимальное расстояние между
разрешенными кодовыми комбинациями
данного кода. Минимальное кодовое
расстояние является основной
характеристикой корректирующей
способности кода. В первичных
(безызбыточных) кодах все комбинации
являются разрешенными, поэтому минимальное
кодовое расстояние для них равно единице
(dmin
=
1).
Такие коды не способны обнаруживать и
исправлять ошибки. Для того чтобы код
обладал корректирующими способностями,
его минимальное кодовое расстояние
должно быть не менее двух (dmin
2).
Для
обнаружения всех ошибок кратностью3
s
и менее, минимальное кодовое расстояние
должно удовлетворять условию
dmin
s
+1
. (5.4)
Если
код используется для исправления ошибок
кратности не более t,
то минимальное кодовое расстояние
должно иметь значение
dmin
2t
+1
. (5.5)
Например,
из (5.4) и (5.5) следует, что для обнаружения
однократных ошибок (s
=
1) требуется код с dmin
=
2, а для того чтобы исправить такие
ошибки, требуется код с кодовым расстоянием
dmin
=
3.
Для
обнаружения s
ошибок и исправления t
ошибок должно выполняться условие
dmin
s
+ t
+1 . (5.6)
Таким
образом, задача построения кода с
заданной корректирующей способностью
сводится к обеспечению необходимого
кодового расстояния. Увеличение dmin
приводит к росту избыточности кода. При
этом желательно, чтобы число проверочных
символов r
было минимальным. В настоящее время
известен ряд верхних и нижних границ,
которые устанавливают связь между
кодовым расстоянием и числом проверочных
символов. Сведения о границах для
кодового расстояния будут приведены
позже в процессе оценки качества приема
кодированных сообщений.
Соседние файлы в папке Лекции. СИСТЕМЫ И СЕТИ
- #
- #
- #
- #
- #
- #
- #
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
6.5.2. Минимальное расстояние для линейного кода
6.5.3. Обнаружение и исправление ошибок
6.5.3.1. Распределение весовых коэффициентов кодовых слов
6.5.3.2.Одновременное обнаружение и исправление ошибок
6.5.4. Визуализация пространства 6-кортежей
6.5.5. Коррекция со стиранием ошибок
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
Конечно же, понятно, что правильно декодировать можно не все ошибочные комбинации. Возможности кода для исправления ошибок в первую очередь определяются его структурой. Весовой коэффициент Хэмминга (Hamming weight) w(U) кодового слова U определяется как число ненулевых элементов в U. Для двоичного вектора это эквивалентно числу единиц в векторе. Например, если U=100101101, то w(U) = 5. Расстояние Хэмминга (Hamming distance) между двумя кодовыми словами U и V, обозначаемое как d(U, V), определяется как количество элементов, которыми они отличаются.
U=100101101
V=011110100
d(U,V)=6
Согласно свойствам сложения по модулю 2, можно отметить, что сумма двух двоичных векторов является другим двоичным вектором, двоичные единицы которого расположены на тех позициях, которыми эти векторы отличаются.
U + V=111011001
Таким образом, можно видеть, что расстояние Хэмминга между двумя векторами равно весовому коэффициенту Хэмминга их суммы, т.е. d(U, V) = w(U + V). Также видно, что весовой коэффициент Хэмминга кодового слова равен его расстоянию Хэмминга до нулевого вектора.
6.5.2. Минимальное расстояние для линейного кода
Рассмотрим множество расстояний между всеми парами кодовых слой в пространстве Vn. Наименьший элемент этого множества называется минимальным расстоянием кода и обозначается dmin. Как вы думаете, почему нас интересует именно минимальное расстояние, а не максимальное? Минимальное расстояние подобно наиболее слабому звену в цепи, оно дает нам меру минимальных возможностей кода и, следовательно, характеризует его мощность.
Как обсуждалось ранее, сумма двух произвольных кодовых слов дает другой элемент пространства кодовых слов. Это свойство линейных кодов формулируется просто: если U и V — кодовые слова, то и W = U + V тоже должно быть кодовым словом. Следовательно, расстояние между двумя кодовыми словами равно весовому коэффициенту третьего кодового слова, т.е. d(U, V) = w(U + V) = w(W). Таким образом, минимальное расстояние линейного кода можно определить, не прибегая к изучению расстояний между всеми комбинациями пар кодовых слов. Нам нужно лишь определить вес каждого кодового слова (за исключением нулевого вектора) в подпространстве; минимальный вес соответствует минимальному расстоянию dmin. Иными словами, dmin соответствует наименьшему из множества расстояний между нулевым кодовым словом и всеми остальными кодовыми словами.
6.5.3. Обнаружение и исправление ошибок
Задача декодера после приема вектора r заключается в оценке переданного кодового слова Ui. Оптимальная стратегия декодирования может быть выражена в терминах алгоритма максимального правдоподобия (см. приложение Б); считается, что передано было слово Ui, если
![]() (6.41)
(6.41)
Поскольку для двоичного симметричного канала (binary symmetric channel — BSC) правдоподобие Ui относительно r обратно пропорционально расстоянию между r и U, можно сказать, что передано было слово Ui, если
![]() (6.42)
(6.42)
Другими словами, декодер определяет расстояние между r и всеми возможными переданными кодовыми словами Uj, после чего выбирает наиболее правдоподобное Uj, для которого
![]() (6.43)
(6.43)
где М = 2k — это размер множества кодовых слов. Если минимум не один, выбор между минимальными расстояниями является произвольным. Наше обсуждение метрики расстояний будет продолжено в главе 7.
На рис. 6.13 расстояние между двумя кодовыми словами U и V показано как расстояние Хэмминга. Каждая черная точка обозначает искаженное кодовое слово. На рис. 6.13, а проиллюстрирован прием вектора r1 находящегося на расстоянии 1 от кодового слова U и на расстоянии 4 от кодового слова V. Декодер с коррекцией ошибок, следуя стратегии максимального правдоподобия, выберет при принятом векторе r1 кодовое слово U. Если r1 получился в результате появления одного ошибочного бита в переданном векторе кода U, декодер успешно исправит ошибку. Но если же это произошло в результате 4-битовой ошибки в векторе кода V, декодирование будет ошибочным. Точно так же, как показано на рис. 6.13, б, двойная ошибка при передаче U может привести к тому, что в качестве переданного вектора будет ошибочно определен вектор r2, находящийся на расстоянии 2 от вектора U и на расстоянии 3 от вектора кода V. На рис. 6.13 показана ситуация, когда в качестве переданного вектора ошибочно определен вектор r3, который находится на расстоянии 3 от вектора кода U и на расстоянии 2 от вектора V. Из рис. 6.13 видно, что если задача состоит только в обнаружении ошибок, а не в их исправлении, то можно определить искаженный вектор — изображенный черной точкой и представляющий одно-, двух-, трех- и четырехбитовую ошибку. В то же время пять ошибок при передаче могут привести к приему кодового слова V, когда в действительности было передано кодовое слово U; такую ошибку невозможно будет обнаружить.
Из рис. 6.13 можно видеть, что способность кода к обнаружению и исправлению ошибок связана с минимальным расстоянием между кодовыми словами. Линия решения на рисунке служит той же цели, что и в процессе демодуляции, — для разграничения областей решения.
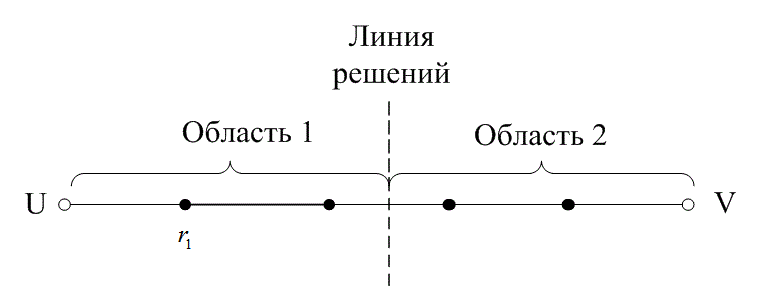
а)
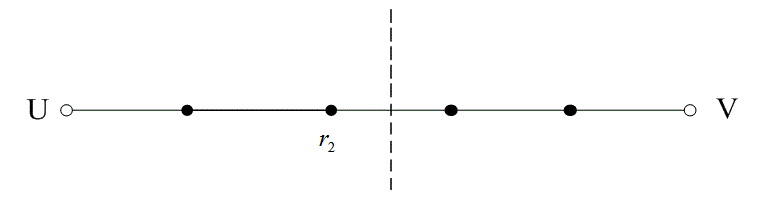
б)
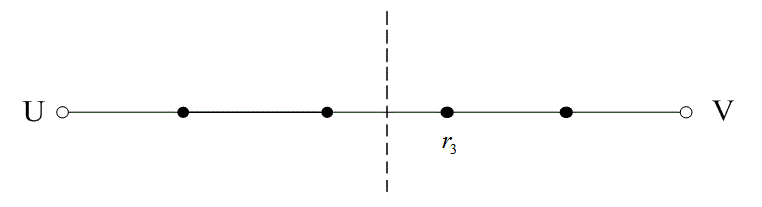
в)
Рис. 6.13. Возможности определения и исправления ошибок: а) принятый вектор r1; б) принятый вектор r2; в) принятый вектор r3
В примере, приведенном на рис. 6.13, критерий принятия решения может быть следующим: выбрать U, если r попадает в область 1, и выбрать V, если r попадает в область 2. Выше показывалось, что такой код (при dmin = 5) может исправить две ошибки. Вообще, способность кода к исправлению ошибок t определяется, как максимальное число гарантированно исправимых ошибок на кодовое слово, и записывается следующим образом [4].
![]() (6.44)
(6.44)
Здесь ![]() означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n—k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t +1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n—k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
![]() (6.45)
(6.45)
Оценка переходит в равенство, если декодер исправляет все ошибочные комбинации, содержащие до t ошибочных бит включительно, но не комбинации с числом ошибочных бит, большим t. Такие декодеры называются декодерами с ограниченным расстоянием. Вероятность ошибки в декодированном бите РB зависит от конкретного кода и декодера. Приближенно ее можно выразить следующим образом [5].
![]() (6.46)
(6.46)
В блочном коде, прежде чем исправлять ошибки, необходимо их обнаружить. (Или же код может использоваться только для определения наличия ошибок.) Из рис. 6.13 видно, что любой полученный вектор, который изображается черной точкой (искаженное кодовое слово), можно определить как ошибку. Следовательно, возможность определения наличия ошибки дается следующим выражением.
![]() (6.47)
(6.47)
Блочный код с минимальным расстоянием dmin гарантирует обнаружение всех ошибочных комбинаций, содержащих dmin — 1 или меньшее число ошибочных бит. Такой код также способен обнаружить и большую ошибочную комбинацию, содержащую dmin или более ошибок. Фактически код (n, k) может обнаружить 2n – 2k ошибочных комбинаций длины п. Объясняется это следующим образом. Всего в пространстве 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Даже правильное кодовое слово — это потенциальная ошибочная комбинация. Поэтому всего существует 2k -1 ошибочных комбинаций, которые идентичны 2k -1 ненулевым кодовым словам. При появлении любая из этих 2k — 1 ошибочных комбинаций изменяет передаваемое кодовое слово Uj на другое кодовое слово Uj. Таким образом, принимается кодовое слово Uj и его синдром равен нулю. Декодер принимает Uj за переданное кодовое слово, и поэтому декодирование дает неверный результат. Следовательно, существует 2k -1 необнаружимых ошибочных комбинаций. Если ошибочная комбинация не совпадает с одним из 2k кодовых слов, проверка вектора r с помощью синдромов дает ненулевой синдром и ошибка успешно обнаруживается. Отсюда следует, что существует ровно 2n-2k выявляемых ошибочных комбинаций. При больших n, когда 2k<<2n, необнаружимой будет только незначительная часть ошибочных комбинаций.
6.5.3.1. Распределение весовых коэффициентов кодовых слов
Пусть Aj — количество кодовых слов с весовым коэффициентом j в линейном коде (п, k). Числа A0,A1,…,An называются распределением весовых коэффициентов этого кода. Если код применяется только для обнаружения ошибок в двоичном симметричном канале, то вероятность того, что декодер не сможет определить ошибку, можно рассчитать, исходя из распределения весовых коэффициентов кода [5].
![]() (6.48)
(6.48)
где р — вероятность перехода в двоичном симметричном канале. Если минимальное расстояние кода равно dmin значения от А1 до ![]() , равны нулю.
, равны нулю.
Пример 6.5. Вероятность необнаруженной ошибки в коде
Пусть код (6,3), введенный в разделе 6.4.3, используется только для обнаружения наличия ошибок. Рассчитайте вероятность необнаруженной ошибки, если применяется двоичный симметричный канал, а вероятность перехода равна 10-2.
Решение
Распределение весовых коэффициентов этого кода выглядит следующим образом: A0=1, А1= А2 = 0, A3 = 4, A5 = 0, A6 = 0. Следовательно, используя уравнение (6.48), можно записать следующее.
![]()
Для р = 10-2 вероятность необнаруженной ошибки будет равна 3,9 х 10-6.
6.5.3.2. Одновременное обнаружение и исправление ошибок
Возможностями исправления ошибок с максимальным гарантированным (t), где t определяется уравнением (6.44), можно пожертвовать в пользу определения класса ошибок. Код можно использовать для одновременного исправления α и обнаружения β ошибок, причем ![]() , а минимальное расстояние кода дается следующим выражением [4].
, а минимальное расстояние кода дается следующим выражением [4].
![]() (6.49)
(6.49)
При появлении t или меньшего числа ошибок код способен обнаруживать и исправлять их. Если ошибок больше t, но меньше е+1, где е определяется уравнением (6.47), код может определять наличие ошибок, но исправить может только некоторые из них. Например, используя код с dmin = 7. можно выполнить обнаружение и исправление со следующими значениями α и β.
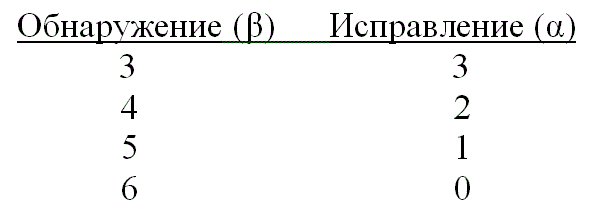
Заметим, что исправление ошибки подразумевает ее предварительное обнаружение. В приведенном выше примере (с тремя ошибками) все ошибки можно обнаружить и исправить. Если имеется пять ошибок, их можно обнаружить, но исправить можно только одну из них.
6.5.4. Визуализация пространства 6-кортежей
На рис. 6.14 визуально представлено восемь кодовых слов, фигурирующих в примере из раздела 6.4.3. Кодовые слова образованы посредством линейных комбинаций из трех независимых 6-кортежей, приведенных в уравнении (6.26); сами кодовые слова образуют трехмерное подпространство. На рисунке показано, что такое подпространство полностью занято восемью кодовыми словами (большие черные круги); координаты подпространства умышленно выбраны неортогональными. На рис. 6.14 предпринята попытка изобразить все пространство, содержащее шестьдесят четыре 6-кортежей, хотя точно нарисовать или составить такую модель невозможно. Каждое кодовое слово окружают сферические слои или оболочки. Радиус внутренних непересекающихся слоев — это расстояние Хэмминга, равное 1; радиус внешнего слоя — это расстояние Хэмминга, равное 2. Большие расстояния в этом примере не рассматриваются. Для каждого кодового слова два показанных слоя заняты искаженными кодовыми словами. На каждой внутренней сфере существует шесть таких точек (всего 48 точек), представляющих шесть возможных однобитовых ошибок в векторах, соответствующих каждому кодовому слову. Эти кодовые слова с однобитовыми возмущениями могут быть соотнесены только с одним кодовым словом; следовательно, такие ошибки могут быть исправлены. Как видно из нормальной матрицы, приведенной на рис. 6.11, существует также одна двухбитовая ошибочная комбинация, которая также поддается исправлению. Всего существует ![]() разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
разных двухбитовых ошибочных комбинаций, которыми может быть искажено любое кодовое слово, но исправить можно только одну из них (в нашем примере это ошибочная комбинация 010001). Остальные четырнадцать двухбитовых ошибочных комбинаций описываются векторами, которые нельзя однозначно сопоставить с каким-либо одним кодовым словом; эти не поддающиеся исправлению ошибочные комбинации дают векторы, которые эквивалентны искаженным векторам двух или большего числа кодовых слов. На рисунке все (56) исправимые кодовые слова с одно- и двухбитовыми искажениями показаны маленькими черными кругами. Искаженные кодовые слова, не поддающиеся исправлению, представлены маленькими прозрачными кругами.
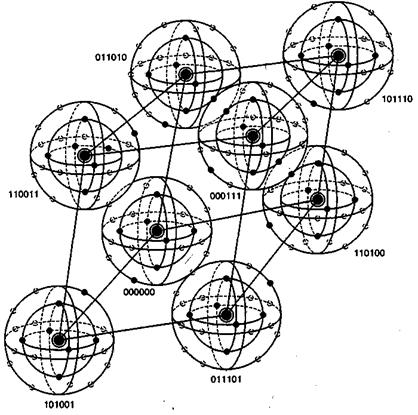
Рис, 6.14. Пример восьми кодовых слов в пространстве 6-кортежей
При представлении свойств класса кодов, известных как совершенные коды (perfect code), рис. 6.14 весьма полезен. Код, исправляющий ошибки в t битах, называется совершенным, если нормальная матрица содержит все ошибочные комбинации из t или меньшего числа ошибок и не содержит иных образующих элементов классов смежности (отсутствует возможность исправления остаточных ошибок). В контексте рис. 6.14 совершенный код с коррекцией ошибок в t битах — это такой код, который (при использовании обнаружения по принципу максимального правдоподобия) может исправить все искаженные кодовые слова, находящиеся на расстоянии Хэмминга t (или ближе) от исходного кодового слова, и не способен исправить ни одну из ошибок, находящихся на расстоянии, превышающем t.
Кроме того, рис. 6.14 способствует пониманию основной цели поиска хороших кодов. Предпочтительным является пространство, максимально заполненное кодовыми словами (эффективное использование введенной избыточности), а также желательно, чтобы кодовые слова были по возможности максимально удалены друг от друга. Очевидно, что эти цели противоречивы.
6.5.5. Коррекция со стиранием ошибок
Приемник можно сконструировать так, чтобы он объявлял символ стертым, если последний принят неоднозначно либо обнаружено наличие помех или кратковременных сбоев. Размер входного алфавита такого канала равен Q, а выходного —Q + 1; лишний выходной символ называется меткой стирания (erasure flag), или просто стиранием (erasure). Если демодулятор допускает символьную ошибку, то для ее исправления необходимы два параметра, определяющие ее расположение и правильное значение символа. В случае двоичных символов эти требования упрощаются — нам необходимо только расположение ошибки. В то же время, если демодулятор объявляет символ стертым (при этом правильное значение символа неизвестно), расположение этого символа известно, поэтому декодирование стертого кодового слова может оказаться проще исправления ошибки. Код защиты от ошибок можно использовать для исправления стертых символов или одновременного исправления ошибок и стертых символов. Если минимальное расстояние кода равно dmin, любая комбинация из ρ или меньшего числа стертых символов может быть исправлена при следующем условии [6].
![]() (6.50)
(6.50)
Предположим, что ошибки появляются вне позиций стирания. Преимущество исправления посредством стираний качественно можно выразить так: если минимальное расстояние кода равно dmin, согласно уравнению (6.50), можно восстановить dmin-1 стирание. Поскольку число ошибок, которые можно исправить без стирания информации, не превышает (dmin-1)/2, то преимущество исправления ошибок посредством стираний очевидно. Далее, любую комбинацию из α ошибок и γ стираний можно исправить одновременно, если, как показано в работе [6],
![]() (6.51)
(6.51)
Одновременное исправление ошибок и стираний можно осуществить следующим образом. Сначала позиции из у стираний замещаются нулями, и получаемое кодовое слово декодируется обычным образом. Затем позиции из у стираний замещаются единицами, и декодирование повторяется для этого варианта кодового слова. После обработки обоих кодовых слов (одно с подставленными нулями, другое — с подставленными единицами) выбирается то из них, которое соответствует наименьшему числу ошибок, исправленных вне позиций стирания. Если удовлетворяется неравенство (6.51), то описанный метод всегда дает верное декодирование.
Пример 6.6. Коррекция со стиранием ошибок
Рассмотрим набор кодовых слов, представленный в разделе 6.4.3.
000000 110100 011010 101110 101001 011101 110011 000111
Пусть передано кодовое слово 110011, в котором два крайних слева разряда приемник объявил стертыми. Проверьте, что поврежденную последовательность хx0011 можно исправить.
Решение
Поскольку ![]() , код может исправить
, код может исправить ![]() = 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
= 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
| Обноружение ошибок | ||||
| Исправление ошибок | ||||
| Коррекция ошибок | ||||
| Назад | ||||
Методы обнаружения ошибок
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых
комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или
равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают
большой «чувствительностью» к помехам. Внесение избыточности при использовании
помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким
образом, все множество
 комбинаций можно разбить на два подмножества:
комбинаций можно разбить на два подмножества:
подмножество разрешенных комбинаций, обладающих определенными признаками, и
подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все
кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только
их часть Nk , которая составляет подмножество разрешенных комбинаций. Если при приеме
выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о
наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При
этом принятая комбинация не декодируется (не принимается решение о переданном
сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами.
Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего
структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие
минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту
позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде
Хемминга добавляется m проверочных элементов для автоматического определения
местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации
составляет: n = k + m.
Метричное представление n,k-кодов
В настоящее время наибольшее внимание с точки зрения технических приложений
уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов
цифровая информация передается в виде отдельных кодовых комбинаций (блоков) равной
длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых
состоят из двух частей: информационной и проверочной. При общем числе n символов в блоке
число информационных символов равно k, а число проверочных символов:
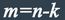
К основным характеристикам корректирующих кодов относятся:
|
— число разрешенных и запрещенных кодовых комбинаций; |
Для блочных двоичных кодов, с числом символов в блоках, равным n, общее число
возможных кодовых комбинаций определяется значением
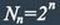
Число разрешенных кодовых комбинаций при наличии k информационных разрядов в
первичном коде:
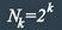
Очевидно, что число запрещенных комбинаций:
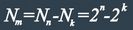
а с учетом ![]() отношение будет
отношение будет
![]()
где m – число избыточных (проверочных) разрядов в блочном коде.
Избыточностью корректирующего кода называют величину
![]()
откуда следует:
![]()
Эта величина показывает, какую часть общего числа символов кодовой комбинации
составляют информационные символы. В теории кодирования величину Bk называют
относительной скоростью кода. Если производительность источника информации равна H
символов в секунду, то скорость передачи после кодирования этой информации будет
![]()
поскольку в закодированной последовательности из каждых n символов только k символов
являются информационными.
Если число ошибок, которые нужно обнаружить или исправить, значительно, то необходимо
иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи
оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно
увеличивать как общее число символов, так и число информационных символов.
При этом длительность кодовых блоков будет существенно возрастать, что приведет к
задержке информации при передаче и приеме. Чем сложнее кодирование, тем длительнее
временная задержка информации.
Минимальное кодовое расстояние – dmin. Для того чтобы можно было обнаружить и
исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от
запрещенной. Если ошибки в канале связи действуют независимо, то вероятность преобразования
одной кодовой комбинации в другую будет тем меньше, чем большим числом символов они
различаются.
Если интерпретировать кодовые комбинации как точки в пространстве, то отличие
выражается в близости этих точек, т. е. в расстоянии между ними.
Количество разрядов (символов), которыми отличаются две кодовые комбинации, можно
принять за кодовое расстояние между ними. Для определения этого расстояния нужно сложить
две кодовые комбинации «по модулю 2» и подсчитать число единиц в полученной сумме.
Например, две кодовые комбинации xi = 01011 и xj = 10010 имеют расстояние d(xi,xj) , равное 3,
так как:

Здесь под операцией ⊕ понимается сложение «по модулю 2».
Заметим, что кодовое расстояние d(xi,x0) между комбинацией xi и нулевой x0 = 00…0
называют весом W комбинации xi, т.е. вес xi равен числу «1» в ней.
Расстояние между различными комбинациями некоторого конкретного кода могут
существенно отличаться. Так, в частности, в безызбыточном первичном натуральном коде n = k это
расстояние для различных комбинаций может изменяться от единицы до величины n, равной
разрядности кода. Особую важность для характеристики корректирующих свойств кода имеет
минимальное кодовое расстояние dmin, определяемое при попарном сравнении всех кодовых
комбинаций, которое называют расстоянием Хемминга.
В безызбыточном коде все комбинации являются разрешенными и его минимальное
кодовое расстояние равно единице – dmin=1. Поэтому достаточно исказиться одному символу,
чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код
обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность,
которая обеспечивала бы минимальное расстояние между любыми двумя разрешенными
комбинациями не менее двух – dmin ≥ 2..
Минимальное кодовое расстояние является важнейшей характеристикой помехоустойчивых
кодов, указывающей на гарантируемое число обнаруживаемых или исправляемых заданным
кодом ошибок.
Число обнаруживаемых или исправляемых ошибок
При применении двоичных кодов учитывают только дискретные искажения, при которых
единица переходит в нуль («1» → «0») или нуль переходит в единицу («0» → «1»). Переход «1» →
«0» или «0» → «1» только в одном элементе кодовой комбинации называют единичной ошибкой
(единичным искажением). В общем случае под кратностью ошибки подразумевают число
позиций кодовой комбинации, на которых под действием помехи одни символы оказались
замененными на другие. Возможны двукратные (g = 2) и многократные (g > 2) искажения
элементов в кодовой комбинации в пределах 0 ≤ g ≤ n.
Минимальное кодовое расстояние является основным параметром, характеризующим
корректирующие способности данного кода. Если код используется только для обнаружения
ошибок кратностью g0, то необходимо и достаточно, чтобы минимальное кодовое расстояние
было равно dmin ≥ g0 + 1.
В этом случае никакая комбинация из go ошибок не может перевести одну разрешенную
кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок
кратностью g0 можно записать
![]()
Чтобы можно было исправить все ошибки кратностью gu и менее, необходимо иметь
минимальное расстояние, удовлетворяющее условию dmin ≥ 2gu
![]()
В этом случае любая кодовая комбинация с числом ошибок gu отличается от каждой
разрешенной комбинации не менее чем в gu+1 позициях. Если условие ![]() не выполнено,
не выполнено,
возможен случай, когда ошибки кратности g исказят переданную комбинацию так, что она станет
ближе к одной из разрешенных комбинаций, чем к переданной или даже перейдет в другую
разрешенную комбинацию. В соответствии с этим, условие исправления всех ошибок кратностью
не более gи можно записать:
![]()
Из ![]() и
и ![]()
следует, что если код исправляет все ошибки кратностью gu, то число
ошибок, которые он может обнаружить, равно go = 2gu. Следует отметить, что эти соотношения
устанавливают лишь гарантированное минимальное число обнаруживаемых или
исправляемых ошибок при заданном dmin и не ограничивают возможность обнаружения ошибок
большей кратности. Например, простейший код с проверкой на четность с dmin = 2 позволяет
обнаруживать не только одиночные ошибки, но и любое нечетное число ошибок в пределах go < n.
Корректирующие возможности кодов
Вопрос о минимально необходимой избыточности, при которой код обладает нужными
корректирующими свойствами, является одним из важнейших в теории кодирования. Этот вопрос
до сих пор не получил полного решения. В настоящее время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают связь между максимально возможным минимальным
расстоянием корректирующего кода и его избыточностью.
Коды Хэмминга
Построение кодов Хемминга базируется на принципе проверки на четность веса W (числа
единичных символов «1») в информационной группе кодового блока.
Поясним идею проверки на четность на примере простейшего корректирующего кода,
который так и называется кодом с проверкой на четность или кодом с проверкой по паритету
(равенству).
В таком коде к кодовым комбинациям безызбыточного первичного двоичного k-разрядного
кода добавляется один дополнительный разряд (символ проверки на четность, называемый
проверочным, или контрольным). Если число символов «1» исходной кодовой комбинации
четное, то в дополнительном разряде формируют контрольный символ «0», а если число
символов «1» нечетное, то в дополнительном разряде формируют символ «1». В результате
общее число символов «1» в любой передаваемой кодовой комбинации всегда будет четным.
Таким образом, правило формирования проверочного символа сводится к следующему:
![]()
где i – соответствующий информационный символ («0» или «1»); k – общее их число а, под
операцией ⊕ здесь и далее понимается сложение «по модулю 2». Очевидно, что добавление
дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению
с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации
на разрешенные и неразрешенные. Код с проверкой на четность позволяет обнаруживать
одиночную ошибку при приеме кодовой комбинации, так как такая ошибка нарушает условие
четности, переводя разрешенную комбинацию в запрещенную.
Критерием правильности принятой комбинации является равенство нулю результата S
суммирования «по модулю 2» всех n символов кода, включая проверочный символ m1. При
наличии одиночной ошибки S принимает значение 1:
![]() — ошибок нет,
— ошибок нет,
![]() — однократная ошибка
— однократная ошибка
Этот код является (k+1,k)-кодом, или (n,n–1)-кодом. Минимальное расстояние кода равно
двум (dmin = 2), и, следовательно, никакие ошибки не могут быть исправлены. Простой код с
проверкой на четность может использоваться только для обнаружения (но не исправления)
однократных ошибок.
Увеличивая число дополнительных проверочных разрядов, и формируя по определенным
правилам проверочные символы m, равные «0» или «1», можно усилить корректирующие
свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. На этом и
основано построение кодов Хемминга.
Коды Хемминга позволяют исправлять одиночную ошибку, с помощью непосредственного
описания. Для каждого числа проверочных символов m =3, 4, 5… существует классический код
Хемминга с маркировкой
![]()
т.е. (7,4), (15,11) (31,26) …
При других значениях числа информационных символов k получаются так называемые
усеченные (укороченные) коды Хемминга. Так для кода имеющего 5 информационных символов,
потребуется использование корректирующего кода (9,5), являющегося усеченным от
классического кода Хемминга (15,11), так как число символов в этом коде уменьшается
(укорачивается) на 6.
Для примера рассмотрим классический код Хемминга (7,4), который можно сформировать и
описать с помощью кодера, представленного на рис. 1 В простейшем варианте при заданных
четырех информационных символах: i1, i2, i3, i4 (k = 4), будем полагать, что они сгруппированы в
начале кодового слова, хотя это и не обязательно. Дополним эти информационные символы
тремя проверочными символами (m = 3), задавая их следующими равенствами проверки на
четность, которые определяются соответствующими алгоритмами, где знак ⊕ означает
сложение «по модулю 2»: r1 = i1 ⊕ i2 ⊕ i3, r2 = i2 ⊕ i3 ⊕ i4, r3 = i1 ⊕ i2 ⊕ i4.
В соответствии с этим алгоритмом определения значений проверочных символов mi, в табл.
1 выписаны все возможные 16 кодовых слов (7,4)-кода Хемминга.
Таблица 1 Кодовые слова (7,4)-кода Хэмминга
|
k=4 |
m=4 |
|
i1 i2 i3 i4 |
r1 r2 r3 |
|
0 0 0 0 |
0 0 0 |
|
0 0 0 1 |
0 1 1 |
|
0 0 1 0 |
1 1 0 |
|
0 0 1 1 |
1 0 1 |
|
0 1 0 0 |
1 1 1 |
|
0 1 0 1 |
1 0 0 |
|
0 1 1 0 |
0 0 1 |
|
0 1 1 1 |
0 1 0 |
|
1 0 0 0 |
1 0 1 |
|
1 0 0 1 |
1 0 0 |
|
1 0 1 0 |
0 1 1 |
|
1 0 1 1 |
0 0 0 |
|
1 1 0 0 |
0 1 0 |
|
1 1 0 1 |
0 0 1 |
|
1 1 1 0 |
1 0 0 |
|
1 1 1 1 |
1 1 1 |
На рис.1 приведена блок-схема кодера – устройства автоматически кодирующего
информационные разряды в кодовые комбинации в соответствии с табл.1
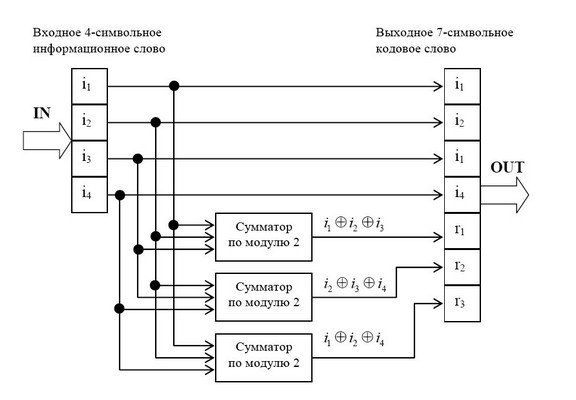
Рис. 1 Кодер для (7,4)-кода Хемминга
На рис. 1.4 приведена схема декодера для (7,4) – кода Хемминга, на вход которого
поступает кодовое слово
![]() . Апостроф означает, что любой символ слова может
. Апостроф означает, что любой символ слова может
быть искажен помехой в телекоммуникационном канале.
В декодере в режиме исправления ошибок строится последовательность:
![]()
![]()
![]()
Трехсимвольная последовательность (s1, s2, s3) называется синдромом. Термин «синдром»
используется и в медицине, где он обозначает сочетание признаков, характерных для
определенного заболевания. В данном случае синдром S = (s1, s2, s3) представляет собой
сочетание результатов проверки на четность соответствующих символов кодовой группы и
характеризует определенную конфигурацию ошибок (шумовой вектор).
Число возможных синдромов определяется выражением:
![]()
При числе проверочных символов m =3 имеется восемь возможных синдромов (23 =  .
.
Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены.
Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и
исправляется. Классические коды Хемминга имеют число синдромов, точно равное их
необходимому числу (что позволяет исправить все однократные ошибки в любом информативном
и проверочном символах) и включают один нулевой синдром. Такие коды называются
плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них
превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов
будет равно 24 =16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о
неполной упаковке кода (9,5).
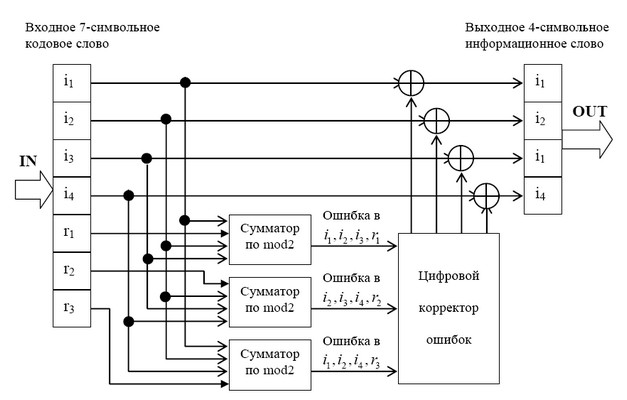
Рис. 2 Декодер для (7, 4)-кода Хемминга
Для рассматриваемого кода (7,4) в табл. 2 представлены ненулевые синдромы и
соответствующие конфигурации ошибок.
Таблица 2 Синдромы (7, 4)-кода Хемминга
|
Синдром |
001 |
010 |
011 |
100 |
101 |
110 |
111 |
|
Конфигурация ошибок |
0000001 |
0000010 |
0000100 |
0001000 |
0010000 |
0100000 |
1000000 |
|
Ошибка в символе |
m1 |
m2 |
i4 |
m1 |
i1 |
i3 |
i2 |
Таким образом, (7,4)-код позволяет исправить все одиночные ошибки. Простая проверка
показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно
создание такого цифрового корректора ошибок (дешифратора синдрома), который по
соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе.
После внесения исправления проверочные символы ri можно на выход декодера (рис. 2) не
выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и
декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и
выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при
перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)-
кодами Хемминга.
Циклические коды
Своим названием эти коды обязаны такому факту, что для них часть комбинаций, либо все
комбинации могут быть получены путем циклическою сдвига одной или нескольких базовых
комбинаций кода.
Построение такого кода основывается на использовании неприводимых многочленов в поле
двоичных чисел. Такие многочлены не могут быть представлены в виде произведения
многочленов низших степеней подобно тому, как простые числа не могут быть представлены
произведением других чисел. Они делятся без остатка только на себя или на единицу.
Для определения неприводимых многочленов раскладывают на простые множители бином
хn -1. Так, для n = 7 это разложение имеет вид:
(x7)=(x-1)(x3+x2)(x3+x-1)
Каждый из полученных множителей разложения может применяться для построения
корректирующего кода.
Неприводимый полином g(x) называют задающим, образующим или порождающим
для корректирующего кода. Длина n (число разрядов) создаваемого кода произвольна.
Кодовая последовательность (комбинация) корректирующего кода состоит из к информационных
разрядов и n — к контрольных (проверочных) разрядов. Степень порождающего полинома
r = n — к равна количеству неинформационных контрольных разрядов.
Если из сделанного выше разложения (при n = 7) взять полипом (х — 1), для которого
r=1, то k=n-r=7-1=6. Соответствующий этому полиному код используется для контроля
на чет/нечет (обнаружение ошибок). Для него минимальное кодовое расстояние D0 = 2
(одна единица от D0 — для исходного двоичного кода, вторая единица — за счет контрольного разряда).
Если же взять полином (x3+x2+1) из указанного разложения, то степень полинома
r=3, а k=n-r=7-3=4.
Контрольным разрядам в комбинации для некоторого кода могут быть четко определено место (номера разрядов).
Тогда код называют систематическим или разделимым. В противном случае код является неразделимым.
Способы построения циклических кодов по заданному полиному.
1) На основе порождающей (задающей) матрицы G, которая имеет n столбцов, k строк, то есть параметры которой
связаны с параметрами комбинаций кода. Порождающую матрицу строят, взяв в качестве ее строк порождающий
полином g(x) и (k — 1) его циклических сдвигов:
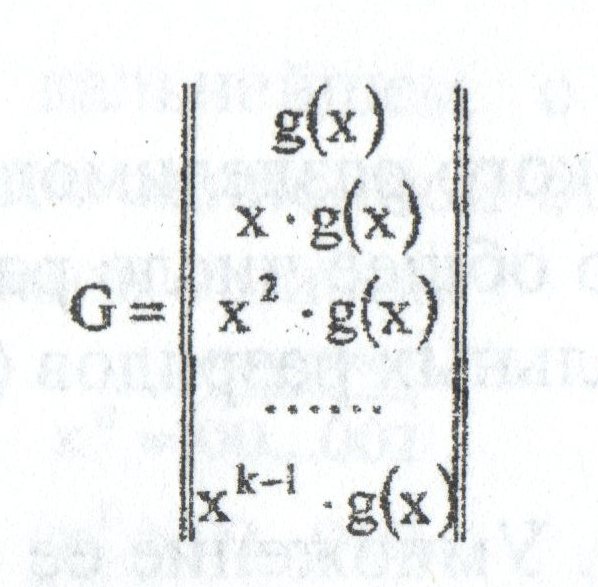
Пример; Определить порождающую матрицу, если известно, что n=7, k=4, задающий полином g(x)=x3+х+1.
Решение: Кодовая комбинация, соответствующая задающему полиному g(x)=x3+х+1, имеет вид 1011.
Тогда порождающая матрица G7,4 для кода при n=7, к=4 с учетом того, что k-1=3, имеет вид:

Порождающая матрица содержит k разрешенных кодовых комбинаций. Остальные комбинации кода,
количество которых (2k — k) можно определить суммированием по модулю 2 всевозможных сочетаний
строк матрицы Gn,k. Для матрицы, полученной в приведенном выше примере, суммирование по модулю 2
четырех строк 1-2, 1-3, 1-4, 2-3, 2-4, 3-4 дает следующие кодовые комбинации циклического кода:
001110101001111010011011101010011101110100
Другие комбинации искомого корректирующего кода могут быть получены сложением трех комбинаций, например,
из сочетания строк 1-3-4, что дает комбинацию 1111111, а также сложением четырех строк 1-2-3-4, что
дает комбинацию 1101001 и т.д.
Ряд комбинаций искомого кода может быть получено путем дальнейшего циклического сдвига комбинаций
порождающей матрицы, например, 0110001, 1100010, 1000101. Всего для образования искомого циклического
кода требуется 2k=24=16 комбинаций.
2) Умножение исходных двоичных кодовых комбинаций на задающий полином.
Исходными комбинациями являются все k-разрядные двоичные комбинации. Так, например, для исходной
комбинации 1111 (при k = 4) умножение ее на задающий полином g(x)=x3+х+1=1011 дает 1101001.
Полученные на основе двух рассмотренных способов циклические коды не являются разделимыми.
3) Деление на задающий полином.
Для получения разделимого (систематического) циклического кода необходимо разделить многочлен
xn-k*h(x), где h(x) — исходная двоичная комбинация, на задающий полином g(x) и прибавить полученный
остаток от деления к многочлену xn-k*h(x).
Заметим, что умножение исходной комбинации h(x) на xn-k эквивалентно сдвигу h(x) на (n-к) разрядов влево.
Пример: Требуется определить комбинации циклического разделимого кода, заданного полиномом g(x)=x3+х+1=1011 и
имеющего общее число разрядов 7, число информационных разрядов 4, число контрольных разрядов (n-k)=3.
Решение: Пусть исходная комбинация h(x)=1100. Умножение ее на xn-k=x3=1000 дает
x3*(x3+x2)=1100000, то есть эквивалентно
сдвигу исходной комбинации на 3 разряда влево. Деление комбинации 1100000 на комбинацию 1011, эквивалентно задающему полиному, дает:

Полученный остаток от деления, содержащий xn-k=3 разряда, прибавляем к полиному, в результате чего получаем искомую комбинацию
разделимого циклического кода: 1100010. В ней 4 старших разряда (слева) соответствуют исходной двоичной комбинации, а три младших
разряда являются контрольными.
Следует сделать ряд указаний относительно процедуры деления:
1) При делении задающий полином совмещается старшим разрядом со старшим «единичными разрядом делимого.
2) Вместо вычитания по модулю 2 выполняется эквивалентная ему процедура сложения по модулю 2.
3) Деление продолжается до тех пор, пока степень очередного остатка не будет меньше степени делителя (задающего полинома). При достижении
этого полученный остаток соответствует искомому содержанию контрольных разрядов для данной искомой двоичной комбинации.
Для проверки правильности выполнения процедуры определения комбинации циклического кода необходимо разделить полученную комб1шацию на задающий полином с
учетом сделанных выше замечаний. Получение нулевого остатка от такого деления свидетельствует о правильности определения комбинации.
Логический код 4В/5В
Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то
общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (25) двухразрядных буквенно-цифровых символа,
имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (24) символов.
Поэтому в результирующем коде можно подобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами
(code violation). В этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных.
Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии,
так как избыточные единицы пользовательской информации не несут, и только «занимают эфирное время». Избыточные коды позволяют приемнику распознавать
искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
Итак, рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере
приемника пять битов расшифровываются как информационные и служебные сигналы.
Для служебных сигналов отведены девять символов, семь символов — исключены.
Исключены комбинации, имеющие более трех нулей (01 — 00001, 02 — 00010, 03 — 00011, 08 — 01000, 16 — 10000). Такие сигналы интерпретируются символом
V и командой приемника VIOLATION — сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная
комбинация из пяти нулей (00 — 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET — отсутствие сигнала в линии.
Такое кодирование данных решает две задачи — синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения
последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале.
Цена за эти достоинства при таком способе кодирования данных — снижение скорости передачи полезной информации.
К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы
частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%.
Схема кодирования 4В/5В представлена в таблице.
|
Двоичный код 4В |
Результирующий код 5В |
|
0 0 0 0 |
1 1 1 1 0 |
|
0 0 0 1 |
0 1 0 0 1 |
|
0 0 1 0 |
1 0 1 0 0 |
|
0 0 1 1 |
1 0 1 0 1 |
|
0 1 0 0 |
0 1 0 1 0 |
|
0 1 0 1 |
0 1 0 1 1 |
|
0 1 1 0 |
0 1 1 1 0 |
|
0 1 1 1 |
0 1 1 1 1 |
|
1 0 0 0 |
1 0 0 1 0 |
|
1 0 0 1 |
1 0 0 1 1 |
|
1 0 1 0 |
1 0 1 1 0 |
|
1 0 1 1 |
1 0 1 1 1 |
|
1 1 0 0 |
1 1 0 1 0 |
|
1 1 0 1 |
1 1 0 1 1 |
|
1 1 1 0 |
1 1 1 0 0 |
|
1 1 1 1 |
1 1 1 0 1 |
Итак, соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по
одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей — например, в помощью
цифрового кода NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд.
Буква ^ В в названии кода означает, что элементарный сигнал имеет 2 состояния — от английского binary — двоичный. Имеются
также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется
код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256
исходных кодов приходится 36=729 результирующих символов.
Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального
уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились,
использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными
кодами не усложняет функциональные требования к этому оборудованию.
Единственное требование — для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код,
должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мб/с передатчик должен
работать с тактовой частотой 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по
линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже
спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника
и передатчика на повышенной тактовой частоте.
В основном для локальных сетей проще, надежней, качественней, быстрей — использовать логическое кодирование данных
с помощью избыточных кодов, которое устранит длительные последовательности нулей и обеспечит синхронизацию
сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного
логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц,
кодом NRZI необходимы частоты 25 — 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и
кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до 62,5 МГц. Но тем не менее, этот диапазон
еще «влазит» в полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного
кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться
линией на 100 МГц.
Скрэмблирование
Другой метод логического кодирования основан на предварительном «перемешивании» исходной информации таким
образом, чтобы вероятность появления единиц и нулей на линии становилась близкой.
Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble — свалка, беспорядочная сборка) .
При скремблировании данные перемешиваються по определенному алгоритму и приемник, получив двоичные данные, передает
их на дескрэмблер, который восстанавливает исходную последовательность бит.
Избыточные биты при этом по линии не передаются.
Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически
единственной операцией, используемой в скремблерах является XOR — «побитное исключающее ИЛИ», или еще говорят —
сложение по модулю 2. При сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается — 0.
Метод скрэмблирования очень прост. Сначала придумывают скрэмблер. Другими словами придумывают по какому соотношению
перемешивать биты в исходной последовательности с помощью «исключающего ИЛИ». Затем согласно этому соотношению из текущей
последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды
сдвигаются на 1 бит, а только что полученное значение («0» или «1») помещается в освободившийся самый младший разряд.
Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным
ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к
узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Например, скрэмблер может реализовывать следующее соотношение:
![]()
где Bi — двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai — двоичная цифра исходного
кода, поступающая на i-м такте на вход скрэмблера, Bi-3 и Bi-5 — двоичные цифры результирующего кода, полученные на
предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта, ⊕ — операция исключающего
ИЛИ (сложение по модулю 2).
Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001.
Скрэмблер, определенный выше даст следующий результирующий код:
B1=А1=1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
Таким образом, на выходе скрэмблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, п
рисутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную
последовательность на основании обратного соотношения.
![]()
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру
результирующего кода, и сдвигом между слагаемыми.
Главная проблема кодирования на основе скремблеров — синхронизация передающего (кодирующего) и принимающего
(декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация
необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации.
На практике для этих целей обычно применяется комбинация двух методов:
а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при ненахождении
такого бита активно начать поиск синхронизации с отправителем,
б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить
декодирование принимаемых битов информации «по памяти» без синхронизации.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода ^ Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
Рис. 3 Коды B8ZS и HDB3
На этом рисунке показано использование метода ^ B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки
кода AMI. Исходный код состоит из двух длинных последовательностей нулей (8- в первом случае и 5 во втором).
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять
цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей
единицы, 1* — сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В
результате на 8 тактах приемник наблюдает 2 искажения — очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому
приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей.
Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые 4 подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS.
Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала
V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то
используется последовательность 000V, а если число единиц было четным — последовательность 1*00V.
Таким образом, применение логическое кодирование совместно с потенциальным кодированием дает следующие преимущества:
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей,
которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования,
обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте.
Линейные блочные коды
При передаче информации по каналам связи возможны ошибки вследствие помех и искажений сигналов. Для обнаружения и
исправления возникающих ошибок используются помехоустойчивые коды. Упрощенная схема системы передачи информации
при помехоустойчивом кодировании показана на рис. 4
Кодер служит для преобразования поступающей от источника сообщений последовательности из k информационных
символов в последовательность из n cимволов кодовых комбинаций (или кодовых слов). Совокупность кодовых слов образует код.
Множество символов, из которых составляется кодовое слово, называется алфавитом кода, а число различных символов в
алфавите – основанием кода. В дальнейшем вследствие их простоты и наибольшего распространения рассматриваются главным
образом двоичные коды, алфавит которых содержит два символа: 0 и 1.
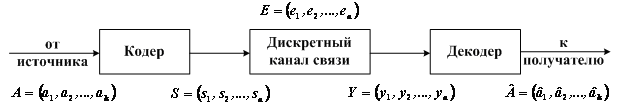
Рис. 4 Система передачи дискретных сообщений
Правило, по которому информационной последовательности сопоставляется кодовое слово, называется правилом кодирования.
Если при кодировании каждый раз формируется блок А из k информационных символов, превращаемый затем в n-символьную
кодовую комбинацию S, то код называется блочным. При другом способе кодирования информационная последовательность на
блоки не разбивается, и код называется непрерывным.
С математической точки зрения кодер осуществляет отображение множества из 2k элементов (двоичных информационных
последовательностей) в множество, состоящее из 2n элементов (двоичных последовательностей длины n). Для практики
интересны такие отображения, в результате которых получаются коды, обладающие способностью исправлять часть ошибок
и допускающие простую техническую реализацию кодирующих и декодирующих устройств.
Дискретный канал связи – это совокупность технических средств вместе со средой распространения радиосигналов, включенных
между кодером и декодером для передачи сигналов, принимающих конечное число разных видов. Для описания реальных каналов
предложено много математических моделей, с разной степенью детализации отражающих реальные процессы. Ограничимся рассмотрением
простейшей модели двоичного канала, входные и выходные сигналы которого могут принимать значения 0 и 1.
Наиболее распространено предположение о действии в канале аддитивной помехи. Пусть S=(s1,s2,…,sn)
и Y=(y1,y2,…,yn) соответственно входная и выходная последовательности двоичных символов.
Помехой или вектором ошибки называется последовательность из n символов E=(e1,e2,…,en), которую
надо поразрядно сложить с переданной последовательностью, чтобы получить принятую:
Y=S+E
Таким образом, компонента вектора ошибки ei=0 указывает на то, что 2-й символ принят правильно (yi=si),
а компонента ei=1 указывает на ошибку при приеме (yi≠si).Поэтому важной характеристикой вектора ошибки
является число q ненулевых компонентов, которое называется весом или кратностью ошибки. Кратность ошибки – дискретная случайная величина,
принимающая целочисленные значения от 0 до n.
Классификация двоичных каналов ведется по виду распределения случайного вектора E. Основные результаты теории кодирования получены в
предположении, что вероятность ошибки в одном символе не зависит ни от его номера в последовательности, ни от его значения. Такой
канал называется стационарным и симметричным. В этом канале передаваемые символы искажаются с одинаковой вероятностью
P, т.е. P(ei=1)=P, i=1,2,…,n.
Для симметричного стационарного канала распределение вероятностей векторов ошибки кратности q является биноминальным:
P(Ei)=Pq(1-P)n-q
которая показывает, что при P<0,5 вероятность β2=αj является убывающей функцией q,
т.е. в симметричном стационарном канале более вероятны ошибки меньшей кратности. Этот важный факт используется при построении
помехоустойчивых кодов, т.к. позволяет обосновать тактику обнаружения и исправления в первую очередь ошибок малой кратности.
Конечно, для других моделей канала такая тактика может и не быть оптимальной.
Декодирующее устройство (декодер) предназначено оценить по принятой последовательности Y=(y1,y2,…,yn)
значения информационных символов A‘=(a‘1,a‘2,…,a‘k,).
Из-за действия помех возможны неправильные решения. Процедура декодирования включает решение двух задач: оценивание переданного кодового
слова и формирование оценок информационных символов.
Вторая задача решается относительно просто. При наиболее часто используемых систематических кодах, кодовые слова которых содержат информационные
символы на известных позициях, все сводится к простому их стробированию. Очевидно также, что расположение информационных символов внутри кодового
слова не имеет существенного значения. Удобно считать, что они занимают первые k позиций кодового слова.
Наибольшую трудность представляет первая задача декодирования. При равновероятных информационных последовательностях ее оптимальное решение
дает метод максимального правдоподобия. Функция правдоподобия как вероятность получения данного вектора Y при передаче кодовых слов
Si, i=1,2,…,2k на основании Y=S+E определяется вероятностями появления векторов ошибок:
P(Y/Si)=P(Ei)=Pqi(1-P)n-qi
где qi – вес вектора Ei=Y+Si
Очевидно, вероятность P(Y/Si) максимальна при минимальном qi. На основании принципа максимального правдоподобия оценкой S‘ является кодовое слово,
искажение которого для превращения его в принятое слово Y имеет минимальный вес, т. е. в симметричном канале является наиболее вероятным (НВ):
S‘=Y+EHB
Если несколько векторов ошибок Ei имеют равные минимальные веса, то наивероятнейшая ошибка EHB определяется случайным выбором среди них.
В качестве расстояния между двумя кодовыми комбинациями принимают так называемое расстояние Хэмминга, которое численно равно количеству символов, в которых одна
комбинация отлична от другой, т.е. весу (числу ненулевых компонентов) разностного вектора. Расстояние Хэмминга между принятой последовательностью Y и всеми
возможными кодовыми словами 5, есть функция весов векторов ошибок Ei:
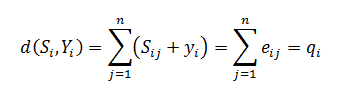
Поэтому декодирование по минимуму расстояния, когда в качестве оценки берется слово, ближайшее к принятой
последовательности, является декодированием по максимуму правдоподобия.
Таким образом, оптимальная процедура декодирования для симметричного канала может быть описана следующей последовательностью операций. По принятому
вектору Y определяется вектор ошибки с минимальным весом EHB, который затем вычитается (в двоичном канале — складывается по модулю 2) из Y:
Y→EHB→S‘=Y+EHB
Наиболее трудоемкой операцией в этой схеме является определение наи-вероятнейшего вектора ошибки, сложность которой
существенно возрастает при увеличении длины кодовых комбинаций. Правила кодирования, которые нацелены на упрощение
процедур декодирования, предполагают придание всем кодовым словам технически легко проверяемых признаков.
Широко распространены линейные коды, называемые так потому, что их кодовые слова образуют линейное
подпространство над конечным полем. Для двоичных кодов естественно использовать поле характеристики p=2.
Принадлежность принятой комбинации Y известному подпространству является тем признаком, по которому
выносится решение об отсутствии ошибок (EHB=0).
Так как по данному коду все пространство последовательностей длины n разбивается на смежные классы,
то для каждого смежного класса можно заранее определить вектор ошибки минимального веса,
называемый лидером смежного класса. Тогда задача декодера состоит в определении номера смежного класса,
которому принадлежит Y, и формировании лидера этого класса.
Принципы помехоустойчивого кодирования
Помехоустойчивым (корректирующим) кодированием называется кодирование при котором осуществляется обнаружение либо обнаружение и исправление ошибок в принятых кодовых комбинациях.
Возможность помехоустойчивого кодирования осуществляется на основании теоремы, сформулированной Шенноном, согласно ей:
если производительность источника (Hи’(A)) меньше пропускной способности канала связи (Ск), то существует по крайней мере одна процедура кодирования и декодирования при которой вероятность ошибочного декодирования сколь угодно мала, если же производительность источника больше пропускной способности канала, то такой процедуры не существует.
Основным принципом помехоустойчивого кодирования является использование избыточных кодов, причем если для кодирования сообщения используется простой код, то в него специально вводят избыточность. Необходимость избыточности объясняется тем, что в простых кодах все кодовые комбинации являются разрешенными, поэтому при ошибке в любом из разрядов приведет к появлению другой разрешенной комбинации, и обнаружить ошибку будет не возможно. В избыточных кодах для передачи сообщений используется лишь часть кодовых комбинаций (разрешенные комбинации). Прием запрещенной кодовой комбинации означает ошибку. Причем, в процессе приема закодированного сообщения возможны три случая (рисунок 3).

Рисунок 3 — Случаи приема закодированного сообщения
Прием сообщения без ошибок является оптимальным, но возможен только если канал связи идеальный. В этом случае помехоустойчивое декодирование не нужно.
В реальном канале из-за воздействия помех происходят ошибки в принимаемых кодовых комбинациях. Если принимаемая кодовая комбинация в результате воздействия помех перешла (трансформировалась) из одной разрешенной комбинации в другую, то определить ошибку не возможно, даже при использовании помехоустойчивого кодирования.
Если же передаваемая разрешенная кодовая комбинация, в результате воздействия помех, трансформируется в запрещенную комбинация, то в этом случае существует возможность обнаружить ошибку и исправить ее.
Помехоустойчивое кодирование может осуществляться двумя способами: с обнаружением ошибок либо с исправлением ошибок. Возможность кода обнаруживать или исправлять ошибки определяется кодовым расстоянием.
Если осуществляется кодирование с обнаружением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше чем кратность обнаруживаемых ошибок, т. е.
d0? qо ош + 1.
Если данное условие не выполняется, то одни из ошибок обнаруживаются, а другие нет.
Если осуществляется кодирование с исправлением ошибок, то кодовое расстояние должно быть хотя бы на единицу больше удвоенного значения кратности исправляемых ошибок, т. е.
d0? 2qи ош + 1.
Если данное условие не выполняется, то одни из ошибок исправляются, а другие нет.
Следует отметить, что если код способен исправить одну ошибку (qи ош = 1), что соответствует кодовому расстоянию 3 (d0 = 1?2+1 = 3), то обнаружить он может две ошибки, т. к.
qо ош = d0 – 1 = 2.
Декодирование помехоустойчивых кодов
Декодирование — это процесс перехода от вторичного отображения сообщения к первичному алфавиту.
Декодирование помехоустойчивых кодов может осуществляться тремя способами: сравнения, синдромным и мажоритарным.
Способ сравнения основан на том, что, принятая кодовая комбинация сравнивается со всеми разрешенными комбинациями, которые заранее известны на приеме. Если принятая комбинация не совпадает ни с одной из разрешенных, выносится решение о принятии запрещенной комбинации. Недостатком данного способа является громоздкость и необходимость большого времени для декодирования в случае применения многоразрядных кодов. Данный способ используется в кодах с обнаружением ошибок.
Синдромный способ основан на вычислении определенным образом контрольного числа — синдрома ошибки (С). Если синдром ошибки равен нулю, то кодовая комбинация принята верно, если синдром не равен нулю, то комбинация принята не верно. Данный способ может быть использован в кодах с исправлением ошибок, в этом случае синдром указывает не только на наличие ошибки в кодовой комбинации, но и на место положение этой ошибки в кодовой комбинации. Для двоичного кода знание местоположения ошибки достаточно для ее исправления. Это объясняется тем, что любой символ кодовой комбинации может принимать всего два значения и если символ ошибочный, то его необходимо инвертировать. Следовательно, синдрома ошибки достаточно для исправления ошибок, если d0? 2qи ош + 1.
Мажоритарное декодирование основано на том, что каждый информационный символ кодовой комбинации определяется нескольким линейными выражениями через другие символы кодовой комбинации. Если принята комбинация без ошибок, то все соотношения остаются и все выражения дают одинаковые результаты (единицу или ноль). При ошибке в одном из разрядов эти соотношения нарушаются, в результате чего одни линейные выражения равны нулю, а другие единице. Решение о принятом символе определяется по большинству: если в результате вычислений выражений больше нулей, то принимается решение о принятии нуля, если больше единиц, то принимается решение о приеме единицы. Если, при декодировании, результаты вычисления выражений дают одинаковое число единиц и нулей, то при определении принятого символа приоритет имеет принятый символ, значение которого в данный момент определяется.
Классификация корректирующих кодов
Классификация корректирующих кодов представлена схемой (рисунок 4)
Блочные — это коды, в которых передаваемое сообщение разбивается на блоки и каждому блоку соответствует своя кодовая комбинация (например, в телеграфии каждой букве соответствует своя кодовая комбинация).

Рисунок 4 — Классификация корректирующих кодов
Непрерывные — коды, в которых сообщение не разбивается на блоки, а проверочные символы располагаются между информационными.
Неразделимые — это коды, в кодовых комбинациях которых нельзя выделить проверочные разряды.
Разделимые — это коды, в кодовых комбинациях которых можно указать положение проверочных разрядов, т. е. кодовые комбинации можно разделить на информационную и проверочную части.
Систематические (линейные) — это коды, в которых проверочные символы определяются как линейные комбинации информационных символов, в таких кодах суммирование по модулю два двух разрешенных кодовых комбинаций также дает разрешенную комбинацию. В несистематических кодах эти условия не выполняются.
Код с постоянным весом
Данный код относится к классу блочных не разделимых кодов. В нем все разрешенные кодовые комбинации имеют одинаковый вес. Примером кода с постоянным весом является Международный телеграфный код МТК-3. В этом коде все разрешенные кодовые комбинации имеют вес равный трем, разрядность же комбинаций n=7. Таким образом, из 128 комбинаций (N0 = 27 = 128) разрешенными являются Nа = 35 (именно столько комбинаций из всех имеют W=3). При декодировании кодовых комбинаций осуществляется вычисление веса кодовой комбинации и если W?3, то выносится решение об ошибке. Например, из принятых комбинаций 0110010, 1010010, 1000111 ошибочной является третья, т. к. W=4. Данный код способен обнаруживать все ошибки нечетной кратности и часть ошибок четной кратности. Не обнаруживаются только ошибки смещения, при которых вес комбинации не изменяется, например, передавалась комбинация 1001001, а принята 1010001 (вес комбинации не изменился W=3). Код МТК-3 способен только обнаруживать ошибки и не способен их исправлять. При обнаружении ошибки кодовая комбинация не используется для дальнейшей обработки, а на передающую сторону отправляется запрос о повторной передаче данной комбинации. Поэтому данный код используется в системах передачи информации с обратной связью.
Код с четным числом единиц
Данный код относится к классу блочных, разделимых, систематических кодов. В нем все разрешенные кодовые комбинации имеют четное число единиц. Это достигается введением в кодовую комбинацию одного проверочного символа, который равен единице если количество единиц в информационной комбинации нечетное и нулю ? если четное. Например:
При декодировании осуществляется поразрядное суммирование по модулю два всех элементов принятой кодовой комбинации и если результат равен единице, то принята комбинация с ошибкой, если результат равен нулю принята разрешенная комбинация. Например:
101101 = 1 + 0 + 1 + 1 + 0 + 1 = 0 — разрешенная комбинация
101111 = 1 + 0 + 1 + 1 + 1 + 1 = 1 — запрещенная комбинация.
Данный код способен обнаруживать как однократные ошибки, так и любые ошибки нечетной кратности, но не способен их исправлять. Данный код также используется в системах передачи информации с обратной связью.
Код Хэмминга
Код Хэмминга относится к классу блочных, разделимых, систематических кодов. Кодовое расстояние данного кода d0=3 или d0=4.
Блочные систематические коды характеризуются разрядностью кодовой комбинации n и количеством информационных разрядов в этой комбинации k остальные разряды являются проверочными (r):
r = n — k.
Данные коды обозначаются как (n,k).
Рассмотрим код Хэмминга (7,4). В данном коде каждая комбинация имеет 7 разрядов, из которых 4 являются информационными,
При кодировании формируется кодовая комбинация вида:
а1 а2 а3 а4 b1 b2 b
где аi — информационные символы;
bi — проверочные символы.
В данном коде проверочные элементы bi находятся через линейные комбинации информационных символов ai, причем, для каждого проверочного символа определяется свое правило. Для определения правил запишем таблицу синдромов кода (С) (таблица 3), в которой записываются все возможные синдромы, причем, синдромы имеющие в своем составе одну единицу соответствуют ошибкам в проверочных символах:
- синдром 100 соответствует ошибке в проверочном символе b1;
- синдром 010 соответствует ошибке в проверочном символе b2;
- синдром 001 соответствует ошибке в проверочном символе b3.
Синдромы с числом единиц больше 2 соответствуют ошибкам в информационных символах. Синдромы для различных элементов кодовой комбинации аi и bi должны быть различными.
Таблица 3 — Синдромы кода Хэмминга (7;4)
| Число | Элементы синдрома | Элементы кодовой | ||
| синдрома | С1 | С2 | С3 | комбинации |
| 1 | 0 | 0 | 1 | b3 |
| 2 | 0 | 1 | 0 | b2 |
| 3 | 0 | 1 | 1 | a1 |
| 4 | 1 | 0 | 0 | b1 |
| 5 | 1 | 0 | 1 | a2 |
| 6 | 1 | 1 | 0 | a3 |
| 7 | 1 | 1 | 1 | a4 |
Определим правило формирования элемента b3. Как следует из таблицы, ошибке в данном символе соответствует единица в младшем разряде синдрома С4. Поэтому, из таблицы, необходимо отобрать те элементы аi у которых, при возникновении ошибки, появляется единица в младшем разряде. Наличие единиц в младшем разряде, кроме b3,соответствует элементам a1, a2 и a4. Просуммировав эти информационные элементы получим правило формирования проверочного символа:
b3 = a1 + a2 + a4
Аналогично определяем правила для b2 и b1:
b2 = a1 + a3 + a4
b1 = a2 + a3 + a4
Пример 3, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=1; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
![]()
В теории циклических кодов все преобразования кодовых комбинаций производятся в виде математических операций над полиномами (степенными функциями). Поэтому двоичные комбинации преобразуют в полиномы согласно выражения:
Аi(х) = аn-1xn-1 + аn-2xn-2 +…+ а0x0
где an-1, … коэффициенты полинома принимающие значения 0 или 1. Например, комбинации 1001011 соответствует полином
Аi(х) = 1?x6 + 0?x5 + 0?x4 + 1?x3 + 0?x2 + 1?x+1?x0 ? x6 + x3 + x+1.
При формировании кодовых комбинаций над полиномами производят операции сложения, вычитания, умножения и деления. Операции умножения и деления производят по арифметическим правилам, сложение заменяется суммированием по модулю два, а вычитание заменяется суммированием.
Разрешенные кодовые комбинации циклических кодов обладают тем свойством, что все они делятся без остатка на образующий или порождающий полином G(х). Порождающий полином вычисляется с применением ЭВМ. В приложении приведена таблица синдромов.
Этапы формирования разрешенной кодовой комбинации разделимого циклического кода Biр(х).
1. Информационная кодовая комбинация Ai преобразуется из двоичной формы в полиномиальную (Ai(x)).
2. Полином Ai(x) умножается на хr,
Ai(x)?xr
где r количество проверочных разрядов:
r = n — k.
3. Вычисляется остаток от деления R(x) полученного произведения на порождающий полином:
R(x) = Ai(x)?xr/G(x).
4. Остаток от деления (проверочные разряды) прибавляется к информационным разрядам:
Biр(x) = Ai(x)?xr + R(x).
5. Кодовая комбинация Bip(x) преобразуется из полиномиальной формы в двоичную (Bip).
Пример 4. Необходимо сформировать кодовую комбинацию циклического кода (7,4) с порождающим полиномом G(x)=х3+х+1, соответствующую информационной комбинации 0110.
1. Преобразуем комбинацию в полиномиальную форму:
Ai = 0110 ? х2 + х = Ai(x).
2. Находим количество проверочных символов и умножаем полученный полином на xr:
r = n – k = 7 – 4 =3
Ai(x)?xr = (х2 + х)? x3 = х5 + х4
3. Определяем остаток от деления Ai(x)?xr на порождающий полином, деление осуществляется до тех пор пока наивысшая степень делимого не станет меньше наивысшей степени делителя:
R(x) = Ai(x)?xr/G(x)

4. Прибавляем остаток от деления к информационным разрядам и переводим в двоичную систему счисления:
Biр(x) = Ai(x)?xr+ R(x) = х5 + х4 + 1? 0110001.
5. Преобразуем кодовую комбинацию из полиномиальной формы в двоичную:
Biр(x) = х5 + х4 + 1 ? 0110001 = Biр
Как видно из комбинации четыре старших разряда соответствуют информационной комбинации, а три младших — проверочные.
Формирование разрешенной кодовой комбинации неразделимого циклического кода.
Формирование данных комбинаций осуществляется умножением информационной комбинации на порождающий полином:
Biр(x) = Ai(x)?G(x).
Причем умножение можно производить в двоичной форме.
Пример 5, необходимо сформировать кодовую комбинацию неразделимого циклического кода используя данные примера 2, т. е. G(x) = х3+х+1, Ai(x) = 0110, код (7,4).
1. Переводим комбинацию из двоичной формы в полиномиальную:
Ai = 0110? х2+х = Ai(x)
2. Осуществляем деление Ai(x)?G(x)

3. Переводим кодовую комбинацию из полиномиальной форы в двоичную:
Bip(x) = х5+х4+х3+х ? 0111010 = Bip
В этой комбинации невозможно выделить информационную и проверочную части.
Матричное представление систематических кодов
Систематические коды, рассмотренные выше (код Хэмминга и разделимый циклический код) удобно представить в виде матриц. Рассмотрим, как это осуществляется.
Поскольку систематические коды обладают тем свойством, что сумма двух разрешенных комбинаций по модулю два дают также разрешенную комбинацию, то для формирования комбинаций таких кодов используют производящую матрицу Gn,k. С помощью производящей матрицы можно получить любую кодовую комбинацию кода путем суммирования по модулю два строк матрицы в различных комбинациях. Для получения данной матрицы в нее заносятся исходные комбинации, которые полностью определяют систематический код. Исходные комбинации определяются исходя из условий:
1) все исходные комбинации должны быть различны;
2) нулевая комбинация не должна входить в число исходных комбинаций;
3) каждая исходная комбинация должна иметь вес не менее кодового расстояния, т. е. W?d0;
4) между любыми двумя исходными комбинациями расстояние Хэмминга должно быть не меньше кодового расстояния, т. е. dij?d0.
Производящая матрица имеет вид:

Производящая подматрица имеет k строк и n столбцов. Она образована двумя подматрицами: информационной (включает элементы аij) и проверочной (включает элементы bij). Информационная матрица имеет размеры k?k, а проверочная — r?k.
В качестве информационной подматрицы удобно брать единичную матрицу Ekk:

Проверочная подматрица Gr,k строится путем подбора различных r-разрядных комбинаций, удовлетворяющих следующим правилам:
1) в каждой строке подматрицы количество единиц должно быть не менее d0-1;
2) сумма по модулю два двух любых строк должна иметь не менее d0-2 единицы;
Полученная таким образом подматрица Gr,k приписывается справа к подматрице Ekk, в результате чего получается производящая матрица Gn,k. Затем, используя производящую матрицу, можно получить любую комбинацию кода путем суммирования двух и более строк по модулю два в различных комбинациях.
Пример 6. Необходимо построить производящую матрицу кода Хэмминга способного исправлять 1 ошибку и имеющего n=7. Закодировать с помощью полученной матрицы комбинацию Ai=1101.
Определяем кодовое расстояние:
d0=2qи ош+1= 2?1+1=3.
Для кодов с d0=3 количество проверочных разрядов определяется по формуле:
r=log2(n+1)= log28=3.
Определяем разрядность информационной части:
k = n — r = 7 — 4 =3.
Запишем все возможные комбинации проверочной подматрицы: 000, 001, 010, 011, 100, 101, 110, 111. Выберем из этих комбинаций те, что удовлетворяют правилам:
1) в каждой строке не менее d0-1, этому условию соответствуют комбинации 011, 101, 110, 111;
2) сумма двух любых комбинаций по модулю два содержит единиц не менее d0-2:

3) записываем проверочную подматрицу:

4) приписываем полученную подматрицу к единичной и получаем производящую матрицу:

Если произвести определение d0 для исходных комбинаций полученной матрицы (определив расстояние Хэмминга для всех пар комбинаций), то оно окажется равным 3.
Для кодирования заданной комбинации Ai, необходимо просуммировать те строки матрицы G, которые в информационной части имеют единицу на том месте, на котором они находятся в комбинации Аi. Для заданной комбинации 1101 единичными разрядами являются а1, а2, а4. В матрице G единицы на этих местах имеют строки: первая, вторая и четвертая. Просуммировав их получаем разрешенную комбинацию заданного кода.

Сравнивая полученную кодовую комбинацию Bip с комбинацией полученной примере 3, для которой также использована комбинация Ai=1101, видим что они одинаковы.
Для кода Хэмминга выше были определены правила формирования проверочных символов bk:

Эти правила можно отобразить в виде проверочной матрицы Нn,k. Она состоит из n столбцов (соответствует разрядности кодовой комбинации) и r столбцов (соответствует количеству проверочных разрядов кодовой комбинации). В правой части матрицы указываются синдромы, соответствующие ошибкам в проверочных символах, в левой части записываются элементы информационной части комбинации, причем, те элементы, которые участвуют в образовании определенного элемента bi равны единицы, а те которые не участвуют — нулю.

В данном случае обведенные пунктиром проверочные элементы образуют единичную матрицу. Проверочная матрица позволяет определить ошибочный разряд, поскольку каждый столбец данной матрицы представляет собой синдром соответствующего символа. При этом строки матрицы будут соответствовать разрядам синдрома Ck. Например, согласно приведенной проверочной матрице, синдром соответствующий ошибку в разряде а1 имеет вид 011, в разряде а2 — 101, в разряде а3 — 110, в разряде а4 — 111, в разряде b1 — 100, в разряде b2 — 010, в разряде b3 — 001. Также с помощью проверочной матрицы легко определить проверочные и символы и сформировать кодовую комбинацию. Например, необходимо сформировать кодовую комбинацию кода Хэмминга (7,4) соответствующую информационным символам 1101.
В соответствии с проверочной матрицей определяем bi:
b1 = 1 + 0 + 1 = 0; b2 = 1 + 0 + 1=0; b3 = 1 + 1 + 1 = 1.
Добавляем проверочные символы к информационным и получаем кодовую комбинацию:
Biр = 1101001.
Также проверочную матрицу можно построить и другим способом. Для этого сначала строится единичная матрица Еr. К которой слева приписывается подматрица Dk,r. Каждая строка этой подматрицы соответствует столбцу проверочных разрядов подматрицы Сr,k производящей матрицы Gn,k.

Такое преобразование строк матрицы в столбцы называется транспонированием.
В результате получаем

Декодирование циклических кодов
При декодировании таких кодов (разделимых и неразделимых) используется Синдромный способ. Вычисление синдрома осуществляется в три этапа:
1. принятая комбинация Bip’ преобразуется их двоичной формы в полиномиальную (Bip(x));
2. осуществляется деление Bip(x) на порождающий полином G(x) в результате чего определяется синдром ошибки C(x) (остаток от деления);
3. синдром ошибки преобразуется из полиномиальной формы в двоичную;
4. По проверочной матрице или таблице синдромов определяется ошибочный разряд;
5. Ошибочный разряд в Bip’(x) инвертируется;
6. Исправленная комбинация преобразуется из полиномиальной формы в двоичную Bip.
делением принятой кодовой комбинации Biр’(x) на порождающий полином G(x), который заранее известен на приеме. Остаток от деления и является синдромом ошибки С(х).
Мажоритарное декодирование циклических кодов
Мажоритарное декодирование может применятся только для декодирования систематических кодов (кода Хэмминга, циклического разделимого кода). Рассмотрим мажоритарное декодирование на примере циклического кода.