
I am using the XML-INTO op-code to parse a web service request. Every now and then I get errors in the logs
(RNX0351 - "The XML parser detected error code 302").
The help for a 302 is
302 The parser does not support the requested CCSID value or
the first character of the XML document was not '<'
To the best of my knowledge, the first character is «<» and the request is generated from a previous web service call so I would be very suprised if the CCSID has changed.
The error is repeatable, for the specific query so it is almost certainly data related, I am just unsure how I would go about identifying the offending item.
Any thoughts on how to determine the issue, or better yet, how to overcome it?
cheers
![]()
CalebC
91211 silver badges24 bronze badges
asked Jul 1, 2013 at 0:13
![]()
7
CCSID is an AS400/iSeries/Power System attribute, and it applies to the whole IFS.
It’s like a declaration of what inside the file is, or in other words what its internal encoding «should be».
It’s supposed that data content encoding in the file and the file one (the envelope) match, and the box uses this attribute to show and handle corresponding characters.
It sounds like you receive data under one encoding, but CCSID file doesn’t match.
Try changing CCSID on your file (only the envelope). E.G.: 37 (american), 500 (latin-1), 819 (utf-8), 850 (dos), 1252 (win) and display file after.
You can check first using ls -Sla yourfile in QSH or QP2TERM, or EDTF as well. CHGATTR allows you to change CCSID, as well as setccsid in QSH (again).
This way helped me to find related issues. Remember that although data may be visible in the four hundred, they may not be visible through a share folder in Win. It means that CCSID file, an content encoding don’t match.
Hope it helps.
answered Jan 29, 2015 at 22:42
![]()
Hi I’ve seen this error with XML data uploaded to AS400/iSeries/IBM i with FTP and the CCSID 819 (ISO 8859-1 ASCII) and it has some binary garbage in first few positions of file. Changed encoding to CCSID 1208 (UTF-8 with IBM PUA) using FTP «quote type c 1208» and the problem cleared and XML-INTO was successful.
So, suggestion about XML parser error 302 received when using XML-INTO is to look at the file (wrklnk …) and if first character is not «<» but instead some binary garbage then try CCSID 1208 for utf-8.
Statements in this answer about what 819 is and what ccsid represents utf-8 do not agree with previous answer but are correct, according to IBM documentation:
https://www-01.ibm.com/software/globalization/ccsid/ccsid819.html
https://www-01.ibm.com/software/globalization/ccsid/ccsid1208.html
answered Jun 3, 2018 at 15:21
![]()
Peter DeGregorioPeter DeGregorio
1,7191 gold badge11 silver badges5 bronze badges
I’m working on this problem a couple hours,
for me the solution was use option ccsid=UCS2 when you use data structure or variable to store xml.
something like that :
XML-INTO customer %XML( xmlSource : ‘ccsid=UCS2’);
I have the program running on ccsid = 870, every conversion to ccsid on the xmlSource field don’t work,
The strange thing that when I use the file with ccsid = 850, every thing work fine
I mention that becouse this is the first page when you looking about this problem.
Maybe this help someone.
answered Sep 23, 2018 at 20:05
![]()
Всем привет!
Подскажите, пожалуйста, как обойти сообщения с кодами 301 и 302, при попытке подключиться к некоторым ресурсам типо youtube.com, yandex.com и.т.д по HTTPS.
При это при подключении, например, к github.com код страницы получаю без проблем.
Получается, что ютуб как-то понимает, что я потенциальный парсер и банит подключение?
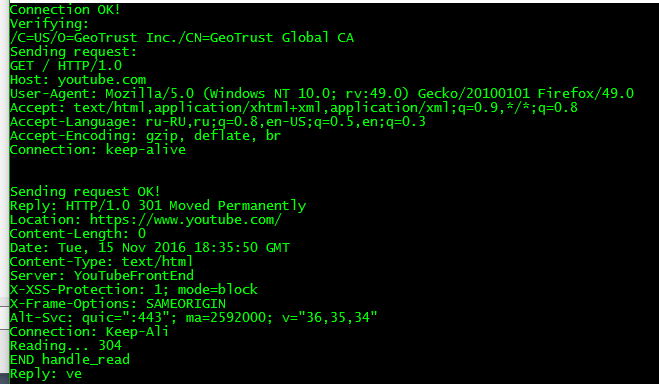 UDP: Добавил www — все работает, теперь проблема с кодировкой получаемого текста (Хидеры читаемы):
UDP: Добавил www — все работает, теперь проблема с кодировкой получаемого текста (Хидеры читаемы):
При выводе в файл — тоже самое
За последние 24 часа нас посетили 11373 программиста и 877 роботов. Сейчас ищут 646 программистов …
-

Вот решил сделать скриптец для своего интернет магазина, дополнительный скрипт при передачи имени товара
он должен будет сгенерить страничку и вписать там ключевые слова из яндекс.директ…Проблема в том что при считывании яшевской выдачи, при запросе допустим:
-
http://www.yandex.ru/yandsearch?text=Nokia+3250
— выводит это:
HTTP/1.1 302 Found Date: Sun, 01 Apr 2007 12:52:19 GMT Server: Apache/1.3.29 (Unix) mod_perl/1.29 mod_deflate/1.0.21 rus/PL30.19 Location: http://www.yandex.ru/yandsearch?text=Nokia+3250 Connection: close Content-Type: text/html; charset=iso-8859-1 X-Pad: avoid browser bug
Found
The document has moved here.Вот для наглядности еще недописанный мой скрипт:
-
//Здесь корректируем спец.символы
-
//открываем соединение с Яшей
-
$fp = fsockopen (‘yandex.ru’, 80, $errno, $errstr, 30);
-
$report.= «<center><font color=’red’>».$errstr($errno).«</font></center><br>»;
-
fputs ($fp, «GET /yandsearch?text=».$keywords.» HTTP/1.0rnHost: yandex.rurnrn«);
-
//Считуем пучками по 128 байт
-
//алгоритм выдирания имен ссылок
-
$p_start=explode(‘<div class=»ad-market»><div class=»cat»>’,$data);
-
$p_block=explode(‘предложения’,$p_start[0]);
-
for($i=0;$i<count($total_links);$i++)
-
$tmp=explode(‘</a>’,$total_links[$i]);
-
$keywords_list=$tmp[0].«<br>»;
-
echo «<html><head><title>».$keyword_list.«</title><meta name=’keywords’ content='».$keyword_list.«‘><meta name=’description’ content='».$keyword_list.«‘></head><body>».$keywords_list.«</body></html>»;
-
-
-
-
Как обработать ответ HTTP 302? Уверен что 70% тут незнает как, а пост уже быстренько переместили в «крутой» раздел…
Что-то с кешом думаю связано, но нигде немогу найти ответ как разобраться с этой проблемой…
-
Мне ктото подскажет как решить эту задачу?
-
FFFFx029A
Везде в своем скрипте замени адрес «yandex.ru» на «www.yandex.ru». -
FFFFx029A
А вы пробовали что-нибудь читать о HTTP? Например, самое что ни на есть официальное его описание:
http://www.ietf.org/rfc/rfc2616.txt.Если говорить о коде ответа 302, то вот цитата:
Не стоит обижаться на собственную неграмотность и уж тем более, «наезжать» на других…
- Автор темы
-
#1
Подскажите как обходятся 302 ответы сервера?
Например
Делает 302 редирект и возвращается по тому же урлу
Как можно парсить такие ресурсы?
Пользую класс Snoopy
PHP:
$snoopy = new Snoopy;
$snoopy->referer = "http://google.com/";
$snoopy->agent = "(compatible; MSIE 6.01; MSN 2.5; AOL 4.0; Windows Server 2003)";
$snoopy->cookies["SessionID"] = rand(122220000,2147483647);
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 3;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->fetch($index_url);отдает 302
почему не срабатывает
или тут что-то другое?
- Автор темы
-
#2
люди… =)
ну хоть какие-то мысли может есть?
или такие ресурсы нельзя парсить с помощью curl?
-
#3
или используйте другой класс, или пилите данный, так как он не отрабатывает перенаправления с http на https, необходима настройка параметров самого класса, в частности curl_path и, возможно, это еще не все …
-
#4
Возмодны два варинта
1) то, где запускается скрипт с вызовом класса, запрещено/не разрешено/не настроено работа с протоколом https
2) следите за куками, после редиректа с https страницы на первоначальную страницу запроса. там ставится кука
Set-Cookie JSESSIONID=p1jjkf2o6g95;Path=/
второй вариант проще всего решается настройками curl. первый вариант сложнее, но не критично
-
#5
Попробуй пихнуть в запрос реферер где значение будет этот адрес. Оно должно схавать.
- Автор темы
-
#6
или используйте другой класс, или пилите данный, так как он не отрабатывает перенаправления с http на https, необходима настройка параметров самого класса, в частности curl_path и, возможно, это еще не все …
phpinfo говорит
cURL support enabled
cURL Information libcurl/7.19.6 OpenSSL/0.9.7e zlib/1.2.3
curl с поддержкой ssl… настроить? что имеется ввиду?
Возмодны два варинта
1) то, где запускается скрипт с вызовом класса, запрещено/не разрешено/не настроено работа с протоколом https
2) следите за куками, после редиректа с https страницы на первоначальную страницу запроса. там ставится кука
Set-Cookie JSESSIONID=p1jjkf2o6g95;Path=/
второй вариант проще всего решается настройками curl. первый вариант сложнее, но не критично
куку вижу, но в моем случае редиректа не происходит и соответственно ничего не ставится… я так понимаю достаточно хоть раз получить куку, но как сделать так что бы произошел редирект и она поставилась?
Попробуй пихнуть в запрос реферер где значение будет этот адрес. Оно должно схавать.
пробовал… не оно
-
#7
говорим только о пхп скриптах, никаких настроек самого пхп.
Классе «Snoopy» не позволяет, покрайней мере та версия, что я видел, не отрабатывает редирект с http на https, так как это не предусмотренно в регулярном выражении в самом классе, поэтому я и написал или правьте и доводите до ума этот класс, или пробуйте какой-либо другой
Я боролся с попыткой обойти это перенаправление 302. Прежде всего, цель этой конкретной части моего парсера — получить индекс следующей страницы, чтобы я мог пролистывать страницы. Прямые URL-адреса недоступны для этого сайта, поэтому я не могу просто перейти к следующему или чему-то еще; чтобы продолжить очистку фактических данных с помощью функции parse_details, мне нужно просмотреть каждую страницу и имитировать запросы.
Для меня это все в новинку, поэтому я сначала попробовал все, что смог найти. Я пробовал различные настройки («REDIRECT_ENABLED»:False, изменение handle_httpstatus_list и т. Д.), Но ни один из них не помогает мне пройти через это. В настоящее время я пытаюсь отслеживать местоположение перенаправления, но это тоже не работает. Вот пример одного из потенциальных решений, которым я пытался следовать.
try:
print('Current page index: ', page_index)
except: # Will be thrown if page_index wasnt found due to redirection.
if response.status in (302,) and 'Location' in response.headers:
location = to_native_str(response.headers['location'].decode('latin1'))
yield scrapy.Request(response.urljoin(location), method='POST', callback=self.parse)
Код, без разбора деталей и прочего, выглядит следующим образом:
def parse(self, response):
table = response.css('td> a::attr(href)').extract()
additional_page = response.css('span.page_list::text').extract()
for string_item in additional_page: # The text has some non-breaking
# spaces ( ) to ignore. We want the text representing the
# current page index only.
char_list = list(string_item)
for char in char_list:
if char.isdigit():
page_index = char
break # Now that we have the current page index, we
# can back out of this loop.
# Below is where the code breaks; it cannot find page_index since it is
# not getting to the site for scraping after redirection.
try:
print('Current page index: ', page_index)
# To get to the next page, we submit a form request since it is all
# setup with javascript instead of simlpy giving a URL to follow.
# The event target has 'dgTournament' information where the first
# piece is always '_ctl1' and the second is '_ctl' followed by
# the page index number we want to go to minus one (so if we want
# to go to the 8th page, its '_ctl7').
# Thus we can just plug in the current page index which is equal to
# the next we want to hit minus one.
# Here is how I am making the requests; they work until the (302)
# redirection...
form_data = {"__EVENTTARGET": "dgTournaments:_ctl1:_ctl" + page_index,
"__EVENTARGUMENT": {";;AjaxControlToolkit, Version=3.5.50731.0, Culture=neutral, PublicKeyToken=28f01b0e84b6d53e:en-US:ec0bb675-3ec6-4135-8b02-a5c5783f45f5:de1feab2:f9cec9bc:35576c48"}}
yield FormRequest(current_LEVEL, formdata=form_data, method="POST", callback=self.parse, priority=2)
В качестве альтернативы, решение может заключаться в том, чтобы следить за разбивкой на страницы по-другому, вместо того, чтобы делать все эти запросы? Исходная ссылка
https://m.tennislink.usta.com/TournamentSearch/searchresults.aspx?typeofsubmit=&action=2&keywords=&tournamentid=§iondistrict=&city=&state=&zip=&month=0&startdate=&enddate=&day=&year=2019&division=G16&category=28&surface=&onlineentry=&drawssheets=&usertime=&sanctioned=-1&agegroup=Y&searchradius=-1
если кто может помочь.