
Автор:
Louise Ward
Дата создания:
12 Февраль 2021
Дата обновления:
4 Июнь 2023

Содержание
- Связанные страницы ошибок

An ошибка переполнения указывает на то, что программа попыталась записать данные за пределами памяти.
У каждой программы есть часть памяти, выделенная для стека. Стек используется для хранения внутренних данных программы, работает очень быстро и отслеживает обратную адресацию. Программа может перейти в область, которая читает некоторые данные с жесткого диска, а затем возвращается из этой процедуры, чтобы продолжить обработку данных. Стек отслеживает исходный адрес, и программа использует его для возврата. Это все равно что оставлять панировочные сухари, чтобы найти дорогу обратно. В стеке есть ограниченное пространство для хранения. Если программное обеспечение пытается получить доступ к области стека за его пределами, возникает ошибка переполнения.
Проблема переполнения стека не так распространена в новых операционных системах, однако из-за небольшого размера на мобильных устройствах она может стать сложной задачей. Если ваша операционная система на мобильном устройстве выдает ошибку переполнения стека, возможно, у вас запущено слишком много приложений. У вас может быть вирус, использующий пространство стека. У вас может быть даже повреждение оборудования, которое может вызвать сообщение об ошибке переполнения стека. Проверьте использование вашего приложения и защиту от вирусов, а также запустите приложение для диагностики памяти на своем мобильном устройстве, чтобы узнать, помогает ли это устранить вашу ошибку.
Ошибка переполнения, возникающая при назначении хранилища, называется переполнением типа данных. Это означает, что определенный тип данных, используемый для хранения части данных, был недостаточно большим для хранения данных. Например, если вы попытаетесь поместить двенадцать банок супа в коробку, рассчитанную на десять банок, две банки «переполнят» это пространство. Точно так же определенные типы данных могут хранить только числа определенного размера. Если тип данных — однобайтный, и данные, которые должны быть сохранены, больше, чем значение без знака 256, возникает ошибка переполнения.
Этот тип ошибки обычно возникает только на старых машинах, пытающихся запустить современные операционные системы, так как емкость операционной системы превышает емкость оборудования. Другими словами, вы можете получить ошибки переполнения, когда приложение запрашивает 64 бита памяти, тогда как программа может предложить только 32. Разработчик программного обеспечения несет ответственность за правильное предотвращение или обработку этого типа ошибки переполнения.
Связанные страницы ошибок
- Почему у компьютеров возникают проблемы?
- Как исправить ошибку остановки системы переполнения стека.
- Типичные компьютерные ошибки и основные действия по устранению неполадок.
- Память (RAM) помощь и поддержка.
Ошибка, условия программирования, недополнение
What is an integer overflow error?
Why do i care about such an error?
What are some methods of avoiding or preventing it?
![]()
Earlz
61.8k98 gold badges301 silver badges498 bronze badges
asked Apr 14, 2010 at 21:46
![]()
8
Integer overflow occurs when you try to express a number that is larger than the largest number the integer type can handle.
If you try to express the number 300 in one byte, you have an integer overflow (maximum is 255). 100,000 in two bytes is also an integer overflow (65,535 is the maximum).
You need to care about it because mathematical operations won’t behave as you expect. A + B doesn’t actually equal the sum of A and B if you have an integer overflow.
You avoid it by not creating the condition in the first place (usually either by choosing your integer type to be large enough that you won’t overflow, or by limiting user input so that an overflow doesn’t occur).
answered Apr 14, 2010 at 21:51
![]()
JohnJohn
16k10 gold badges70 silver badges110 bronze badges
The easiest way to explain it is with a trivial example. Imagine we have a 4 bit unsigned integer. 0 would be 0000 and 1111 would be 15. So if you increment 15 instead of getting 16 you’ll circle back around to 0000 as 16 is actually 10000 and we can not represent that with less than 5 bits. Ergo overflow…
In practice the numbers are much bigger and it circles to a large negative number on overflow if the int is signed but the above is basically what happens.
Another way of looking at it is to consider it as largely the same thing that happens when the odometer in your car rolls over to zero again after hitting 999999 km/mi.
![]()
answered Apr 14, 2010 at 21:51
![]()
KrisKris
14.4k7 gold badges55 silver badges65 bronze badges
1
When you store an integer in memory, the computer stores it as a series of bytes. These can be represented as a series of ones and zeros.
For example, zero will be represented as 00000000 (8 bit integers), and often, 127 will be represented as 01111111. If you add one to 127, this would «flip» the bits, and swap it to 10000000, but in a standard two’s compliment representation, this is actually used to represent -128. This «overflows» the value.
With unsigned numbers, the same thing happens: 255 (11111111) plus 1 would become 100000000, but since there are only 8 «bits», this ends up as 00000000, which is 0.
You can avoid this by doing proper range checking for your correct integer size, or using a language that does proper exception handling for you.
answered Apr 14, 2010 at 21:52
![]()
Reed CopseyReed Copsey
552k78 gold badges1154 silver badges1373 bronze badges
1
An integer overflow error occurs when an operation makes an integer value greater than its maximum.
For example, if the maximum value you can have is 100000, and your current value is 99999, then adding 2 will make it ‘overflow’.
You should care about integer overflows because data can be changed or lost inadvertantly, and can avoid them with either a larger integer type (see long int in most languages) or with a scheme that converts long strings of digits to very large integers.
answered Apr 14, 2010 at 21:50
![]()
RiddariRiddari
1,7053 gold badges26 silver badges57 bronze badges
Overflow is when the result of an arithmetic operation doesn’t fit in the data type of the operation. You can have overflow with a byte-sized unsigned integer if you add 255 + 1, because the result (256) does not fit in the 8 bits of a byte.
You can have overflow with a floating point number if the result of a floating point operation is too large to represent in the floating point data type’s exponent or mantissa.
You can also have underflow with floating point types when the result of a floating point operation is too small to represent in the given floating point data type. For example, if the floating point data type can handle exponents in the range of -100 to +100, and you square a value with an exponent of -80, the result will have an exponent around -160, which won’t fit in the given floating point data type.
You need to be concerned about overflows and underflows in your code because it can be a silent killer: your code produces incorrect results but might not signal an error.
Whether you can safely ignore overflows depends a great deal on the nature of your program — rendering screen pixels from 3D data has a much greater tolerance for numerical errors than say, financial calculations.
Overflow checking is often turned off in default compiler settings. Why? Because the additional code to check for overflow after every operation takes time and space, which can degrade the runtime performance of your code.
Do yourself a favor and at least develop and test your code with overflow checking turned on.
answered Apr 14, 2010 at 23:52
![]()
dthorpedthorpe
35.3k5 gold badges75 silver badges119 bronze badges
0
I find showing the Two’s Complement representation on a disc very helpful.
Here is a representation for 4-bit integers. The maximum value is 2^3-1 = 7.
For 32 bit integers, we will see the maximum value is 2^31-1.
When we add 1 to 2^31-1 : Clockwise we move by one and it is clearly -2^31 which is called integer overflow

Ref : https://courses.cs.washington.edu/courses/cse351/17wi/sections/03/CSE351-S03-2cfp_17wi.pdf
answered Dec 29, 2020 at 17:41
![]()
mcvkrmcvkr
3,0996 gold badges38 silver badges63 bronze badges
From wikipedia:
In computer programming, an integer
overflow occurs when an arithmetic
operation attempts to create a numeric
value that is larger than can be
represented within the available
storage space. For instance, adding 1 to the largest value that can be represented
constitutes an integer overflow. The
most common result in these cases is
for the least significant
representable bits of the result to be
stored (the result is said to wrap).
You should care about it especially when choosing the appropriate data types for your program or you might get very subtle bugs.
answered Apr 14, 2010 at 21:49
![]()
Darin DimitrovDarin Dimitrov
1.0m270 gold badges3284 silver badges2923 bronze badges
1
From http://www.first.org/conference/2006/papers/seacord-robert-slides.pdf :
An integer overflow occurs when an integer is
increased beyond its maximum value or
decreased beyond its minimum value.
Overflows can be signed or unsigned.
P.S.: The PDF has detailed explanation on overflows and other integer error conditions, and also how to tackle/avoid them.
answered Apr 14, 2010 at 21:50
![]()
N 1.1N 1.1
12.4k6 gold badges43 silver badges61 bronze badges
I’d like to be a bit contrarian to all the other answers so far, which somehow accept crappy broken math as a given. The question is tagged language-agnostic and in a vast number of languages, integers simply never overflow, so here’s my kind-of sarcastic answer:
What is an integer overflow error?
An obsolete artifact from the dark ages of computing.
why do i care about it?
You don’t.
how can it be avoided?
Use a modern programming language in which integers don’t overflow. (Lisp, Scheme, Smalltalk, Self, Ruby, Newspeak, Ioke, Haskell, take your pick …)
answered Apr 14, 2010 at 23:17
![]()
Jörg W MittagJörg W Mittag
362k75 gold badges440 silver badges647 bronze badges
0
This happens when you attempt to use an integer for a value that is higher than the internal structure of the integer can support due to the number of bytes used. For example, if the maximum integer size is 2,147,483,647 and you attempt to store 3,000,000,000 you will get an integer overflow error.
answered Apr 14, 2010 at 21:50
![]()
1

Что означает ошибка OverflowError: math range error
Это ошибка переполнения из-за математических операций
Это ошибка переполнения из-за математических операций
Ситуация: для научной диссертации по логарифмам мы пишем модуль, который будет возводить в разные степени число Эйлера — число e, которое примерно равно 2,71828. Для этого мы подключаем модуль math, где есть нужная нам команда — math.exp(), которая возводит это число в указанную степень.
Нам нужно выяснить различные значения числа в степени от 1 до 1000, чтобы потом построить график, поэтому пишем такой простой модуль:
# импортируем математический модуль
import math
# список с результатами
results = []
# перебираем числа от 1 до 1000
for i in range(1000):
# добавляем результат в список
results.append(math.exp(i))
# и выводим его на экран
print(results[i-1])Но при запуске кода компьютер выдаёт ошибку:
❌ OverflowError: math range error
Что это значит: компьютер во время расчётов вылез за допустимые границы переменной — ему нужно записать в неё большее значение, чем то, на которое она рассчитана.
Когда встречается: во время математических расчётов, которые приводят к переполнению выделенной для переменной памяти. При этом общий размер оперативной памяти вообще не важен — имеет значение только то, сколько байт компьютер выделил для хранения нашего конкретного значения. Если у вас, например, 32 Гб оперативной памяти, это не поможет решить проблему.
Что делать с ошибкой OverflowError: math range error
Так как это ошибка переполнения, то самая частая причина этой ошибки — попросить компьютер посчитать что-то слишком большое.
Чтобы исправить ошибку OverflowError: math range error, есть два пути — использовать разные трюки или специальные библиотеки для вычисления больших чисел или уменьшить сами вычисления. Про первый путь поговорим в отдельной статье, а пока сделаем проще: уменьшим диапазон с 1000 до 100 чисел — этого тоже хватит для построения графика:
# импортируем математический модуль
import math
# список с результатами
results = []
# перебираем числа от 1 до 100
for i in range(100):
# добавляем результат в список
results.append(math.exp(i))
# и выводим его на экран
print(results[i-1])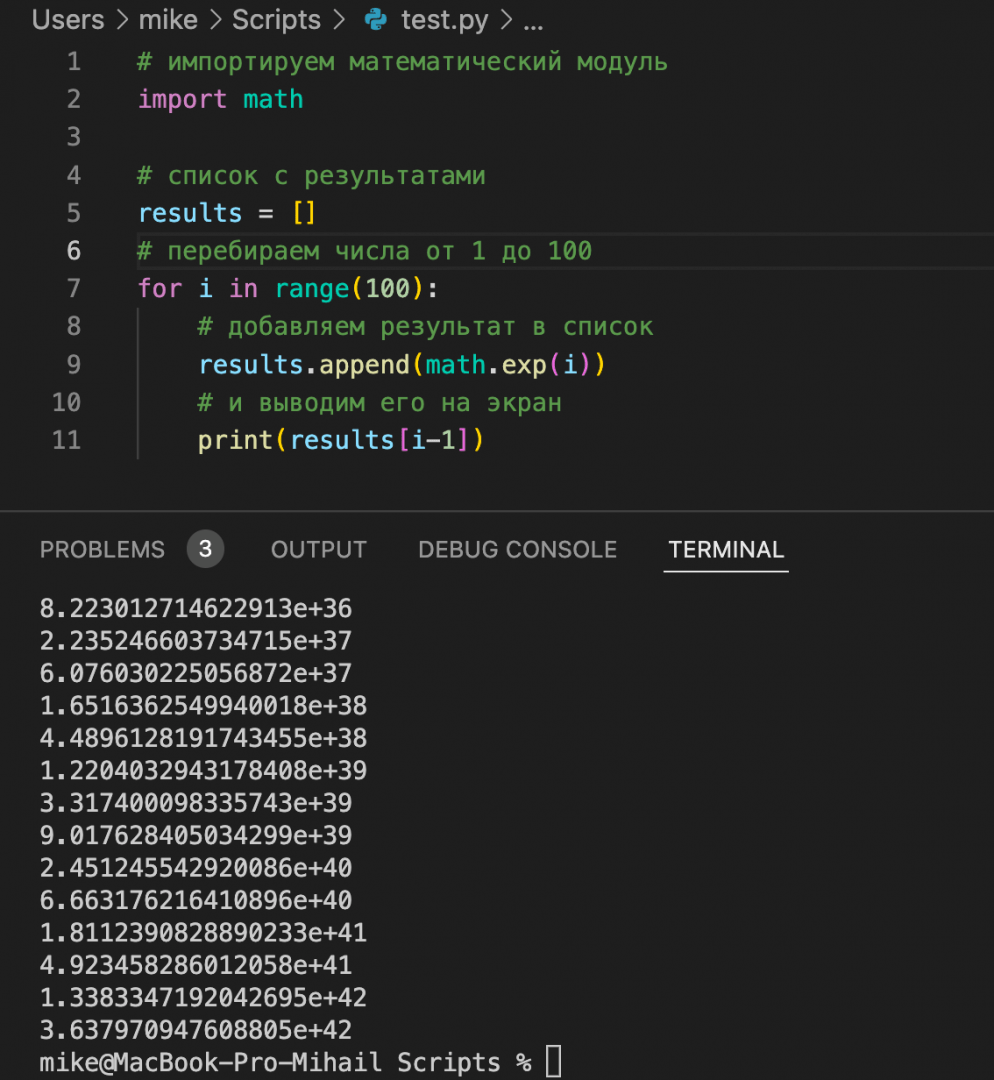
Вёрстка:
Кирилл Климентьев
Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
Начать карьеру в ИТ




Определение — Что означает ошибка переполнения?
В вычислениях ошибка переполнения — это ошибка, которая возникает, когда программа получает число, значение или переменную, выходящие за рамки ее способности обрабатывать. Этот тип ошибки несколько распространен в программировании, особенно при работе с целыми числами или другими числовыми типами переменных.
Техопедия объясняет ошибку переполнения
Различные типы ошибок переполнения включают те, которые относятся к стекам памяти, используемым для программирования, и те, которые имеют дело с резидентной памятью для хранения. Переполнение стека связано с перегрузкой условий, используемых для обработки процессов в вычислительном стеке, что может быть связано с одновременным запуском слишком большого количества программ, с вирусами или другими проблемами. Другие типы ошибок переполнения вызваны тем, что разработчики не предоставляют достаточно места для хранения поступающих данных.
Другой проблемой, обычно связанной с переполнением типов данных или переполнением стека, является рекурсия программы; например, когда программа вызывает слишком много методов или вложенных процессов, она переполняет то, что может обработать система. В некоторых случаях системе просто не хватает памяти для обработки требований, которые к ней предъявляются. Ошибка переполнения может также возникнуть в ситуациях, когда старые машины или системы пытаются использовать более новые операционные системы или приложения.
Устранение ошибок переполнения при разработке должно быть приоритетом для разработчиков. После этого компании могут выпускать исправления или обновления для устранения проблем с переполнением.
В статье разбираются причины возникновения и последствия ошибок переполнения буфера, предлагаются эффективные методы борьбы с ними. Изложение ориентировано на прикладных разработчиков, работающих с языками программирования Си/Си++ и операционными системами семейства Windows, однако многие из затронутых вопросов применимы и к Unix-подобным системам.
Просматривая популярную рассылку по информационной безопасности BUGTRAQ, легко убедиться, что подавляющее большинство уязвимостей приложений и операционных систем связано с ошибками переполнения буфера. Ошибки этого типа настолько распространены, что вряд ли существует хотя бы один полностью свободный от них программный продукт. Переполнение приводит не только к некорректной работе программы, но и к возможности удаленного вторжения в систему с наследованием всех привилегий компрометированной программы. Это обстоятельство широко используется злоумышленниками. Проблема настольно серьезна, что попытки ее решения предпринимаются как на уровне самих языков программирования, так и на уровне компиляторов. К сожалению, достигнутые результаты оставляют желать лучшего, и ошибки переполнения продолжают появляться даже в современных приложениях. Вот всего несколько примеров: Microsoft Internet Information Service 5.0, Outlook Express 5.5; Netscape Directory Server 4.1x; Apple QuickTime Player 4.1; ISC BIND 8; Lotus Domino 5.0 — список этот можно было бы продолжать и продолжать. А ведь все это серьезные продукты солидных компаний, не скупящихся на тестирование. Давайте поговорим о приемах программирования, следование которым значительно уменьшает вероятность появления ошибок переполнения, в то же время не требуя от разработчика особых дополнительных усилий.
Причины и последствия ошибок переполнения
Во многих языках программирования, в том числе и в Cи/Cи++, массив одновременно является и совокупностью определенного количества объектов данных некоторого типа, и безразмерным фрагментом памяти. Программист может получить указатель на начало массива, но не имеет возможности непосредственно определить его длину. В Си/Си++ не делается особых различий между указателями на массив и указателями на ячейку памяти. Допускаются различные математические операции с указателями.
Мало того, что контроль выхода указателя за границы массива всецело лежит на разработчике — строго говоря, этот контроль невозможен в принципе. Получив указатель на буфер, функция не может самостоятельно вычислить его размер и вынуждена либо полагать, что вызывающий код выделил буфер заведомо достаточного размера, либо требовать явного указания длины буфера в дополнительном аргументе (в частности, по первому сценарию работает gets, а по второму — fgets). Ни то, ни другое не может считаться достаточно надежным; знать наперед сколько памяти потребуется вызывающей функции, вообще говоря, невозможно, а постоянная «ручная» передача длины массива не только утомительна и непрактична, но и не застрахована от ошибок.
Другая частая причина возникновения ошибок переполнения буфера — слишком вольное обращение с указателями. Например, для перекодировки текста может использоваться следующий алгоритм: код преобразуемого символа складывается с указателем на начало таблицы перекодировки и из полученной ячейки извлекается искомый результат. Несмотря на изящество этого и подобных ему алгоритмов, он требует тщательного контроля исходных данных: передаваемый функции аргумент должен быть неотрицательным числом, не превышающим последний индекс таблицы перекодировки; в противном случае произойдет доступ совсем к другим данным. Однако о подобных проверках нередко забывают или реализуют их неправильно.
Можно выделить два типа ошибок переполнения: одни приводят к чтению не принадлежащих к массиву ячеек памяти, другие — к их модификации. В зависимости от расположения буфера за ним могут находиться:
- другие переменные и буферы;
- служебные данные (например, сохраненные значения регистров и адрес возврата из функции);
- исполняемый код;
- незанятая или несуществующая область памяти.
Несанкционированное чтение не принадлежащих к массиву данных может привести к утере конфиденциальности, а их модификация в лучшем случае заканчивается некорректной работой приложения (чаще всего «зависанием»), а в худшем — выполнением действий, никак не предусмотренных разработчиком (например, отключением защиты). Еще опаснее, если непосредственно за концом массива следуют адрес возврата из функции; в этом случае уязвимое приложение потенциально способно выполнить от своего имени любой код, переданный ему злоумышленником. И, если это приложение исполняется с наивысшими привилегиями (что типично для сетевых служб), взломщик сможет как угодно манипулировать системой.
Предотвращение возникновения ошибок переполнения
Таким образом, независимо от того, где располагается переполняющийся буфер — в стеке, сегменте данных или в области динамической памяти (куче), он делает работу приложения небезопасной. Поэтому представляет интерес поговорить о том, можно ли предотвратить такую угрозу и если да, то как.
Переход на другой язык
В идеале контроль за подобными ошибками следовало бы поручить языку, сняв это бремя с плеч программиста. Достаточно запретить непосредственное обращение к массиву, заставив вместо этого пользоваться встроенными операторами языка, которые бы постоянно следили за тем, происходит ли выход за установленные границы, и при необходимости либо возвращали ошибку, либо динамически увеличивали размер массива.
Именно такой подход использован в языках Ада, Perl, Java и некоторых других. Но сферу его применения ограничивает производительность: постоянные проверки требуют значительных накладных расходов, в то время как отказ от них позволяет транслировать даже серию операций обращения к массиву в одну инструкцию процессора. Тем более, такие проверки налагают жесткие ограничения на математические операции с указателями (в общем случае требуя их запретить), а это в свою очередь не позволяет реализовывать многие эффективные алгоритмы.
Если в критических областях применения (атомной энергетике, космонавтике и т.п.) выбор между производительностью и защищенностью автоматически делается в пользу последней, в офисных и уж тем более в бытовых приложениях ситуация обратная. В лучшем случае речь может идти только о разумном компромиссе. Покупать дополнительные мегабайты и мегагерцы ради одного лишь достижения надлежащего уровня безопасности и без всяких гарантий на отсутствие ошибок других типов рядовой клиент не будет, как бы его ни убеждали. Тем более, что ни Ада, ни Perl, ни Java (языки, не отягощенные проблемами переполнения) принципиально не способны заменить Си/Cи++, не говоря уже об ассемблере. Разработчики оказываются зажатыми между несовершенством используемого ими языка программирования и невозможностью перехода на другой язык. Даже если бы и появился язык, удовлетворяющий всем мыслимым требованиям, совокупная стоимость его изучения и переписывания с нуля созданного программного обеспечения многократно бы превысила убытки от отсутствия в старом языке продвинутых средств контроля за ошибками: производители вообще несут очень мало издержек за «ляпы» в своих продуктах и не особо одержимы идей их тотального устранения.
Использование «кучи» для создания массивов
От использования статических массивов рекомендуется вообще отказаться (за исключением тех случаев, когда их переполнение заведомо невозможно). Вместо этого следует выделять память из кучи (Heap), преобразуя указатель, возвращенный функцией malloc к указателю на соответствующий тип данных (char, int), после чего с ним можно обращаться точно так же, как с указателем на обычный массив. Вернее, почти «точно так» — за двумя небольшими исключениями. Во-первых, получившая такой указатель функция может с помощью вызова msize узнать истинный размер буфера, не требуя от программиста явного указания данной величины. А, во-вторых, если в ходе работы выяснится, что этого размера недостаточно, она может динамически увеличить длину буфера, обращаясь к realloc всякий раз, как только в этом возникнет потребность. В этом случае, передавая функции, читающей строку с клавиатуры, указатель на буфер, не придется мучительно соображать: какой именно величиной следует ограничить его размер, — об этом позаботится сама вызываемая функция. Программисту же не придется добавлять еще одну константу в свою программу.
Отказ от индикатора завершения
По возможности не используйте какой бы то ни было индикатор завершения для распознания конца данных (например, нуль для задания конца строки). Во-первых, это приводит к неопределенности в длине самих данных и количества памяти, необходимой для их размещения, в результате чего возникают ошибки типа buff = malloc(strlen(Str)), которые с первого взгляда не всегда удается обнаружить (правильный код должен выглядеть так: buff = malloc(strlen(Str)+1), поскольку, в длину строки, возвращаемой функцией srtlen, не входит завершающий ее нуль).
Во-вторых, если по каким-то причинам индикатор конца будет уничтожен, функция, работающая с этими данными, «забредет» совсем не в свой «лес».
В-третьих, такой подход приводит к крайне неэффективному подсчету объема памяти, занимаемого данными: приходится их последовательно перебирать один за другим до тех пор пока не встретится символ конца, а, поскольку по соображениям безопасности при каждой операции конкатенации и присваивания необходимо проверять, достаточно ли свободного пространства для ее завершения, очень важно оптимизировать этот процесс.
Значительно лучше явным образом указывать размер данных в отдельном поле (так, например, задается длина строк в компиляторах Turbo Pascal и Delphi). Однако такое решение не устраняет несоответствия размера данных и количества занимаемой ими памяти. Поэтому надежнее вообще отказаться от какого бы то ни было задания длины данных и всегда помещать их в буфер строго соответствующего размера.
Избавиться от накладных расходов, связанных с необходимостью частых вызовов достаточно медленной функции realloc можно введением специального ключевого значения, обозначающего отсутствие данных. В частности, для этой цели подойдет тот же нуль, однако, теперь он будет иметь другое значение — обозначать не конец строки, а отсутствие символа в данной позиции. Конец же строки определяется размером выделенного под нее буфера данных. Выделив буфер «про запас» и забив его «хвост» нулями, можно значительно сократить количество вызовов realloc. (Правда, в этом случае за эффективное использование ресурсов процессора приходится расплачиваться существенным перерасходом памяти. — Прим. ред.)
Обработка структурных исключений
Описанные приемы реализуются без особых усилий и излишних накладных расходов. Единственным серьезным недостатком является их несовместимость со стандартными библиотеками, так как они интенсивно используют признак завершения и не умеют по указателю на начало буфера определять его размер. Частично эта проблема может быть решена написанием слоя переходного кода, «посредничающего» между стандартными библиотеками и вашей программой.
Однако следует помнить, что описанные подходы сами по себе не защищают от ошибок переполнения, а только уменьшают вероятность их появления. Они исправно работают только в том случае, когда разработчик всегда помнит о необходимости постоянного контроля за границами массивов. Гарантировать выполнение такого требования невозможно в любой «полновесной» программе, состоящей из десятков или сотен тысяч строк. К тому же, чем больше проверок делает программа, тем «тяжелее» и медлительнее получается код и тем вероятнее, что хотя бы одна из проверок реализована неправильно или по забывчивости не реализована вообще. Можно ли, избежав нудных проверок, в то же время получить высокопроизводительный код, гарантированно защищенный от ошибок переполнения?
Несмотря на смелость вопроса, на него есть основания дать положительный ответ. И помогает в этом обработка структурных исключений. В общих чертах идея состоит в следующем: выделяется некий буфер, с обеих сторон «окольцованный» несуществующими страницами памяти и устанавливается обработчик исключений, «отлавливающий» прерывания, вызываемые при попытке доступа к несуществующей странице (вне зависимости от того, был ли это запрос на запись или чтение). Необходимость постоянного контроля границ массива при каждом к нему обращении отпадает. Точнее, теперь она «перекладывается» на процессор, а от программиста требуется всего лишь написать несколько строк кода, возвращающего ошибку или увеличивающего размер буфера при его переполнении. Единственным незакрытым лазом останется возможность прыгнуть далеко-далеко за конец буфера и случайно попасть на не имеющую к нему никакого отношения, но все-таки существующую страницу. В этом случае прерывания не произойдет и обработчик исключений ничего не узнает о факте нарушения. Однако такая ситуация достаточно маловероятна (чаще всего буферы читаются и записываются последовательно, а не в разброс), поэтому ею можно полностью пренебречь.
Преимущества технологии обработки структурных исключений заключаются в надежности, компактности и ясности использующего ее программного кода, не отягощенного беспорядочно разбросанными проверками, затрудняющими его понимание. Основной недостаток — плохая переносимость и системная зависимость. Не всякие операционные системы позволяют прикладному коду манипулировать на низком уровне со страницами памяти, а те, что позволяют, реализуют это каждая по-своему. В Windows, к счастью, такая возможность есть.
Функция VirtualAlloc обеспечивает выделение сегмента виртуальной памяти, с которым можно обращаться в точности как и с обычным динамическим буфером, а вызов VirtualProtect позволят изменить его атрибуты защиты. Можно задавать любой требуемый тип доступа, например, разрешить только чтение памяти, но не запись или исполнение. Это позволяет защищать критически важные структуры данных от разрушения некорректно работающими функциями. А запрет на исполнение кода в буфере даже при наличии ошибок переполнения не дает злоумышленнику никаких шансов запустить собственноручно переданный им код.
Использование функций, непосредственно работающих с виртуальной памятью, позволяет творить настоящие чудеса, на которые не способны функции стандартной библиотеки Си/Cи++. Единственный их недостаток заключается в непереносимости. Однако эту проблему можно решить, собственноручно реализовав функции VirtualAlloc, VirtualProtect и некоторые другие (правда, в некоторых случаях это придется делать на уровне компонентов ядра; обработка же структурных исключений изначально заложена в Си++).
Таким образом, усилия, направленные на защиту от ошибок переполнения буфера не настолько чрезмерны, чтобы не окупить полученный результат.
Традиции против надежности
Здравый смысл подсказывает: «Если все очень хорошо, то что-то тут не так». Если описанные приемы программирования столь хороши, почему же они не получили массового распространения? Видимо, на практике не все так складно, как на бумаге.
Пожалуй, основной камень преткновения — «верность традициям». В сложившейся культуре программирования признаком хорошего тона считается использование везде, где только возможно, стандартных функций самого языка, а не специфических возможностей операционной системы, «привязывающих» программу к одной платформе. Вряд ли этот подход бесспорен, но многие разработчики ему следуют. Но что лучше — мобильный, но нестабильно работающий и небезопасный код или плохо переносимое (в худшем случае вообще не переносимое), зато устойчивое и безопасное приложение? Если отказ от использования стандартных библиотек позволит уменьшить количество ошибок в приложении и многократно повысить его безопасность, стоит ли этим пренебрегать? Удивительно, но существует и такое мнение, что непереносимость — более тяжкий грех, чем ошибки, от которых, как водится, никто не застрахован. Аргументы: дескать, ошибки — явление временное и теоретически устранимое, а непереносимость — это навсегда. Однако, использование в своей программе функций, специфичных для какой-то одной операционной системы, не является непреодолимым препятствием для ее переноса на платформы, где этих функций нет. Достаточно лишь реализовать эти функции самостоятельно.
Другая причина нераспространенности описанных приемов программирования — непопулярность обработки структурных исключений вообще. Эта технология так и не получила массового распространения — а жаль. Ведь при возникновении нештатной ситуации любое приложение может если не исправить положение, то, по крайней мере, записать не сохраненные данные на диск и затем корректно завершить свою работу. Напротив, если возникшее исключение не обрабатывается приложением, операционная система аварийно завершает его работу, а пользователь теряет все несохраненные данные.
Нет никаких объективных причин, препятствующих активному использованию структурной обработки исключений — кроме желания держаться за старые традиции, игнорируя все новое. Обработка структурных исключений — очень полезный механизм, области применения которого ограничены разве что фантазией разработчика.
Как с ними борются?
Было бы по меньшей мере удивительно, если бы с ошибками переполнения никто не пытался бы бороться. Такие попытки предпринимались неоднократно, но результат во всех случаях оставлял желать лучшего. Очевидное «лобовое» решение проблемы состоит в синтаксической проверке выхода за границы массива при каждом обращении к нему. Такие проверки реализованы в некоторых компиляторах Си, например, в Compaq C для Tru64 Unix и Alpha Linux. Они не предотвращают возможности переполнения вообще и обеспечивают лишь контроль непосредственных ссылок на элементы массивов, но бессильны предсказать значение указателей.
Проверка корректности указателей вообще не может быть реализована синтаксически, а осуществима только на машинном уровне. Bounds Checker — специальное дополнение для компилятора gcc — именно так и поступает, гарантированно исключая всякую возможность переполнения. Платой за надежность становится значительное, измеряемое десятками раз падение производительности программы. В большинстве случаев это не приемлемо, поэтому такой подход не стал популярен и практически никем не применяется. Bounds Checker хорошо подходит для облегчения отладки приложений, но вовсе не факт, что все допущенные ошибки проявят себя еще на стадии отладки и будут замечены тестировщиками. В рамках проекта Synthetix удалось найти несколько простых и надежных решений, не спасающих от ошибок переполнения, но затрудняющих их использование злоумышленниками для несанкционированного вторжения в систему. StackGuard, еще одно расширение к компилятору gcc, дополняет пролог и эпилог каждой функции особым кодом, контролирующим целостность адреса возврата.
Алгоритм в общих чертах таков: в стек вместе с адресом возврата заносится так называемое Canary Word, расположенный до адреса возврата. Искажение адреса обычно сопровождается и искажением Canary Word, что легко проконтролировать. Соль в том, что Canary Word содержит символы «», CR, LF, EOF, которые могут быть обычным путем введены с клавиатуры. А для усиления защиты добавляется случайная привязка, генерируемая при каждом запуске программы. Компилятор MS Visual C++ также способен контролировать сбалансированность стека на выходе из функции: сразу после входа в функцию он копирует содержимое регистра-указателя вершины стека в один из регистров общего назначения, а затем сверяет их перед выходом из функции. Недостаток: впустую расходуется один из семи регистров и совсем не проверяется целостность стека, а лишь его сбалансированность.
Bounds Checker для Windows 9x/NT, выпущенный компанией NuMega, неплохо отлавливает ошибки переполнения, но, поскольку он выполнен не в виде расширения к какому-нибудь компилятору, а представляет собой отдельное приложение, к тому же требующее для своей работы исходных текстов «подопытной» программы, может использоваться лишь для отладки.
Итак, готовых «волшебных» решений проблемы переполнения не существует и сомнительно, чтобы они появились в обозримом будущем. Да и так ли они необходимы при наличии поддержки структурных исключений со стороны операционной системы и современных компиляторов?
Поиск уязвимых программ
Приемы, предложенные в разделе «Предотвращение ошибок переполнения», хорошо использовать при создании новых программ, а внедрять их в существующие и более или менее устойчиво работающие продукты бессмысленно. Но даже проверенное временем приложение не застраховано от наличия ошибок переполнения, которые годами могут спать, пока не будут кем-то обнаружены.
Самый простой и наиболее распространенный метод поиска уязвимостей заключается в методичном переборе всех возможных длин входных данных. Как правило, такая операция осуществляется не вручную, а специальными автоматизированными средствами. Но таким способом обнаруживаются далеко не все ошибки переполнения. Наглядной демонстрацией этого утверждения служит следующая программа:
int file(char *buff)
{ char *p; int a=0; char
proto[10];
p=strchr(&buff[0],?:?);
if (p) {
for (;a!=(p-&buff[0]);a++)
proto[a]=buff[a];
proto[a]=0;
if (strcmp(&proto[0],»file»))
return 0; else
WinExec(p+3,SW_SHOW);
}
else WinExec(&buff[0],SW_SHOW);
return 1;
}
main(int argc,char **argv)
{if (argc>1) file(&argv[1][0]);}
Программа запускает файл, имя которого указано в командной строке. Попытка вызвать переполнение вводом цепочек различной длины, скорее всего, ни к чему не приведет. Но даже беглый анализ исходного кода позволит обнаружить ошибку, допущенную разработчиком. Если в имени файла присутствует символ «:», программа полагает, что имя записано в формате «протокол://путь к файлу/имя файла» и пытается выяснить, какой именно протокол указан. При этом она копирует название протокола в буфер фиксированного размера, полагая, что при нормальном ходе вещей его хватит для вмещения имени любого протокола. Но если ввести цепочку наподобие «ZZZZZZZZZZZZZZZZZZZZZZ:», произойдет переполнение буфера со всеми вытекающими последствиями.
Приведенный пример — один из самых простых. На практике нередко встречаются и более коварные ошибки, проявляющиеся лишь при стечении множества маловероятных самих по себе обстоятельств. Обнаружить подобные уязвимости только лишь перебором входных данных невозможно (тем не менее, даже такой поиск позволяет выявить огромное число ошибок в существующих приложениях). Значительно лучший результат дает анализ исходных текстов программы. Чаще всего ошибки переполнения возникают вследствие путаницы между длинами и индексами массивов, выполнения операций сравнения до модификации переменной, небрежного обращения с условиями выхода из цикла, злоупотребления операторами «++» и «—», молчаливого ожидания символа завершения и т.д. Например, конструкция «buff[strlen(str)-1]=0», удаляющая заключительный символ возврата каретки, будет «спотыкаться» на цепочках нулевой длины, затирая при этом байт, предшествующий началу буфера.
Вообще же, поиск ошибок — дело неблагодарное и чрезвычайно осложненное инерцией мышления. Программист подсознательно исключает из проверки те значения, которые противоречат «логике» и «здравому смыслу», но тем не менее могут встречаться на практике. Поэтому легче решать эту задачу с конца: сначала определить, какие значения каждой переменной приводят к ненормальной работе кода (т.е. попытаться посмотреть на программу глазами взломщика), а уж потом выяснить, выполняется ли соответствующая проверка или нет.
Особняком стоят проблемы многопоточных приложений и ошибки их синхронизации. Однопоточное приложение выгодно отличается воспроизводимостью аварийных ситуаций: установив последовательность операций, приводящих к проявлению ошибки, их можно повторить в любое время требуемое число раз. Это значительно упрощает поиск и устранение источника их возникновения. Напротив, неправильная синхронизация потоков, как и полное ее отсутствие, порождает трудноуловимые «плавающие» ошибки, проявляющиеся время от времени с некоей (возможно, пренебрежительно малой) вероятностью.
Рассмотрим пример: пусть один поток модифицирует цепочку символов, и в тот момент, когда на место завершающего ее нуля помещен новый символ, но сам завершающий нуль еще не добавлен, второй поток пытается скопировать цепочку в свой буфер. Поскольку завершающего нуля нет, происходит выход за границы массива. Поскольку, потоки в действительности выполняются не одновременно, а вызываются поочередно, получая в свое распоряжение некоторое (как правило, очень большое) количество «тиков» процессора, вероятность прерывания потока в данном конкретном месте очень мала и даже самое тщательное, и широкомасштабное тестирование не всегда способно выловить такие ошибки. Вследствие трудностей воспроизведения аварийной ситуации разработчики в подавляющем большинстве случаев не смогут быстро обнаружить и устранить допущенную ошибку, поэтому пользователям придется довольно долго работать с приложением, ничем не защищенным от атак.
Печально, что, получив в свое распоряжение возможность делить процессы на потоки, многие программисты чересчур злоупотребляют этим, применяя потоки даже там, где легко было бы обойтись и без них. Стоит ли после этого удивляться крайней нестабильности многих распространенных продуктов? Не призывая разработчиков напрочь отказываться от потоков, хотелось бы заметить, что гораздо лучше распараллеливать решение задач на уровне процессов.
К сожалению, заменить потоки уже существующего приложения на процессы достаточно сложно и трудоемко. Однако порой это все же гораздо проще, чем искать источник ошибок многопоточного приложения.
Заключение
Задумываться о борьбе с ошибками переполнения следует еще до начала разработки программы, а не лихорадочно вспоминать о них на стадии завершения проекта. Если это и не поможет гарантированно их предотвратить, то по крайней мере уменьшит вероятность возникновения. Напротив, возлагать решение всех проблем на участников бета-тестирования и надеяться, что надежно работающий продукт удастся создать с одной лишь их помощью, слишком наивно. Тем не менее, именно такую тактику выбрали ведущие производители, — стремясь захватить рынок, они готовы распространять сырой программный продукт, который «доводится до ума» пользователями, сообщающими разработчику об обнаруженных ими ошибках, а взамен получающих либо «заплатку», либо обещание устранить ошибку в последующих версиях.
Как показывает практика, данная стратегия работает безупречно и даже обращает ошибку в пользу, а не в убыток — веской мотивацией пользователя к приобретению новой версии зачастую становятся отнюдь не ее новые возможности, а заверения, что все ошибки теперь исправлены. На самом деле исправляется лишь незначительная часть ошибок и добавляется множество новых.
Крис Касперски (kpnc@aport.ru) — независимый автор
Событие, когда результат компьютерной арифметики требует большего количества бит, чем может представить тип данных
 Целочисленное переполнение может быть продемонстрировано с помощью одометр переполнение, механическая версия явления. Все цифры устанавливаются на максимум 9, и следующее приращение белой цифры вызывает каскад переходящих добавлений, устанавливающих все цифры на 0, но нет более высокой цифры (цифра 100000), которая могла бы измениться на 1, поэтому счетчик сбрасывается в ноль. Это обертывание в отличие от насыщения.
Целочисленное переполнение может быть продемонстрировано с помощью одометр переполнение, механическая версия явления. Все цифры устанавливаются на максимум 9, и следующее приращение белой цифры вызывает каскад переходящих добавлений, устанавливающих все цифры на 0, но нет более высокой цифры (цифра 100000), которая могла бы измениться на 1, поэтому счетчик сбрасывается в ноль. Это обертывание в отличие от насыщения.
В компьютерном программировании, целочисленное переполнение происходит, когда арифметическая операция пытается создать числовое значение, которое находится за пределами диапазона, который может быть представлен заданным числом цифр — выше максимального или ниже минимального представимого значения.
Наиболее частым результатом переполнения является сохранение наименее значимых представимых цифр результата; считается, что результат оборачивается вокруг максимума (т.е. по модулю степень системы счисления, обычно два в современных компьютерах, но иногда десять или другое основание).
Состояние переполнения может привести к непредвиденным результатам. В частности, если возможность не была предвидена, переполнение может поставить под угрозу надежность программы и безопасность.
. Для некоторых приложений, таких как таймеры и часы, может быть желательным перенос при переполнении. В стандарте C11 указано, что для беззнаковых целых чисел перенос по модулю является определенным поведением, и термин «переполнение» никогда не применяется: «вычисление, включающее беззнаковые операнды, никогда не может переполниться».
На некоторых процессорах, таких как графические процессоры (графические процессоры) и процессоры цифровых сигналов (DSP), которые поддерживают арифметику насыщения, результаты переполнения будут «ограничены», т. е. установлены на минимум или максимум значение в представляемом диапазоне, а не обертывается.
Содержание
- 1 Источник
- 2 Флаги
- 3 Варианты определения и неоднозначность
- 4 Методы решения проблем целочисленного переполнения
- 4.1 Обнаружение
- 4.2 Предотвращение
- 4.3 Обработка
- 4.4 Явное распространение
- 4.5 Поддержка языка программирования
- 4.6 Насыщенная арифметика
- 5 Примеры
- 6 См. Также
- 7 Ссылки
- 8 Внешние ссылки
Источник
ширина регистра процессора определяет диапазон значений, которые могут быть представлены в его регистрах. Хотя подавляющее большинство компьютеров может выполнять арифметические операции с множественной точностью для операндов в памяти, позволяя числам быть произвольно длинными и избегать переполнения, ширина регистра ограничивает размеры чисел, с которыми можно работать (например, складывать или вычитать) с использованием одна инструкция на операцию. Типичная двоичная ширина регистра для целых чисел без знака включает:
- 4 бита: максимальное представимое значение 2-1 = 15
- 8 битов: максимальное представимое значение 2-1 = 255
- 16 бит: максимальное представляемое значение 2-1 = 65 535
- 32 бита: максимальное представляемое значение 2-1 = 4294967 295 (наиболее распространенная ширина для персональных компьютеров с 2005 года),
- 64 биты: максимальное представляемое значение 2-1 = 18,446,744,073,709,551,615 (наиболее распространенная ширина для персональных компьютеров процессоров, по состоянию на 2017 год),
- 128 бит: максимальное представляемое значение 2-1 = 340,282,366,920,938,463,463,374,607,431,768,211,455
Когда арифметическая операция дает результат, превышающий указанный выше максимум для N-битового целого числа, переполнение уменьшает результат до по модулю N-й степени 2, сохраняя только младшие значащие биты результата и эффективно оборачиваясь вокруг.
В частности, умножение или сложение двух целых чисел может привести к неожиданно маленькому значению, а вычитание из маленького целого числа может вызвать перенос на большое положительное значение (например, сложение 8-битных целых чисел 255 + 2 дает 1, что составляет 257 по модулю 2, и аналогичным образом вычитание 0 — 1 дает 255, дополнение до двух представление -1).
Такой переход может вызвать нарушение безопасности — если переполненное значение используется в качестве количества байтов, выделяемых для буфера, буфер будет выделен неожиданно маленьким, что может привести к переполнению буфера, которое, в зависимости от использования буфера, может, в свою очередь, вызвать выполнение произвольного кода.
Если переменная имеет тип целое число со знаком, программа может сделать предположение, что переменная всегда содержит положительное значение. Целочисленное переполнение может привести к переносу значения и стать отрицательным, что нарушает предположение программы и может привести к неожиданному поведению (например, сложение 8-битного целого числа 127 + 1 дает -128, дополнение до двух до 128). (Решением этой конкретной проблемы является использование целочисленных типов без знака для значений, которые программа ожидает и предполагает, что они никогда не будут отрицательными.)
Флаги
Большинство компьютеров имеют два выделенных флага процессора для проверки условия переполнения.
Флаг переноса устанавливается, когда результат сложения или вычитания с учетом операндов и результата как беззнаковых чисел не помещается в заданное количество битов. Это указывает на переполнение переносом или заимствованием из старшего бита. Сразу после операции добавления с переносом или вычитания с заимствованием содержимое этого флага будет использоваться для изменения регистра или области памяти, которая содержит старшую часть многословного значения.
Флаг переполнения устанавливается, когда результат операции над числами со знаком не имеет знака, который можно было бы предсказать по знакам операндов, например, отрицательный результат при сложении двух положительные числа. Это указывает на то, что произошло переполнение, и результат со знаком, представленный в форме с дополнением до двух, не уместится в данном количестве битов.
Варианты определения и неоднозначность
Для беззнакового типа, когда идеальный результат операции выходит за пределы представимого диапазона типа, а возвращаемый результат получается путем упаковки, это событие обычно определяется как переполнение. Напротив, стандарт C11 определяет, что это событие не является переполнением, и заявляет, что «вычисление с участием беззнаковых операндов никогда не может переполниться».
Когда идеальный результат целочисленной операции находится за пределами представимого диапазона типа и возвращаемый результат получается путем зажима, тогда это событие обычно определяется как насыщение. Использование зависит от того, является ли насыщение переполнением или нет. Чтобы устранить двусмысленность, можно использовать термины обертывание переполнения и насыщающее переполнение.
Термин «потеря значимости» чаще всего используется для математики с плавающей запятой, а не для целочисленной математики. Но можно найти много ссылок на целочисленное исчезновение. Когда используется термин целочисленное недополнение, это означает, что идеальный результат был ближе к минус бесконечности, чем представимое значение выходного типа, ближайшее к минус бесконечности. Когда используется термин целочисленное отсутствие переполнения, определение переполнения может включать в себя все типы переполнения или только те случаи, когда идеальный результат был ближе к положительной бесконечности, чем представимое значение выходного типа, ближайшее к положительной бесконечности.
Когда идеальный результат операции не является точным целым числом, значение переполнения может быть неоднозначным в крайних случаях. Рассмотрим случай, когда идеальный результат имеет значение 127,25, а максимальное представимое значение типа вывода — 127. Если переполнение определено как идеальное значение, выходящее за пределы представимого диапазона типа вывода, то этот случай будет классифицирован как переполнение. Для операций, которые имеют четко определенное поведение округления, может потребоваться отложить классификацию переполнения до тех пор, пока не будет применено округление. Стандарт C11 определяет, что преобразования из числа с плавающей запятой в целое число должны округляться до нуля. Если C используется для преобразования значения 127,25 с плавающей запятой в целое число, то сначала следует применить округление, чтобы получить идеальное целое число на выходе 127. Поскольку округленное целое число находится в диапазоне выходных значений, стандарт C не классифицирует это преобразование как переполнение..
Методы решения проблем целочисленного переполнения
Обработка целочисленного переполнения в различных языках программирования
| Язык | Целое число без знака | Целое число со знаком |
|---|---|---|
| Ada | по модулю модуль типа | поднять Constraint_Error |
| C /C ++ | по модулю степени двойки | неопределенное поведение |
| C# | по модулю степени 2 в непроверенном контексте; System.OverflowExceptionвозникает в проверенном контексте |
|
| Java | N / A | степень двойки по модулю |
| JavaScript | все числа имеют двойную точность с плавающей запятой, за исключением нового BigInt | |
| MATLAB | Встроенные целые числа насыщаются. Целые числа с фиксированной запятой, настраиваемые для переноса или насыщения | |
| Python 2 | N/A | , преобразовываются в longтип (bigint) |
| Seed7 | N / A | поднять OVERFLOW_ERROR |
| Схема | Н / Д | преобразовать в bigNum |
| Simulink | , конфигурируемый для переноса или насыщения | |
| Smalltalk | Н / Д | преобразовать в LargeInteger |
| Swift | Вызывает ошибку, если не используются специальные операторы переполнения. |
Обнаружение
Реализация обнаружения переполнения во время выполнения UBSanдоступна для Компиляторы C.
В Java 8 есть перегруженные методы, например, такие как Math.addExact (int, int) , которые выбрасывают ArithmeticException в случае переполнения.
Группа реагирования на компьютерные чрезвычайные ситуации (CERT) разработала целочисленную модель с неограниченным диапазоном значений (AIR), в значительной степени автоматизированный механизм устранения переполнения и усечения целых чисел в C / C ++ с использованием обработки ошибок времени выполнения.
Предотвращение
Распределяя переменные с типами данных, которые достаточно велики, чтобы содержать все значения, которые могут быть вычислены и сохранены в них, всегда можно избежать переполнения. Даже когда доступное пространство или фиксированные типы данных, предоставляемые языком программирования или средой, слишком ограничены, чтобы позволить переменным быть защищенным с большими размерами, тщательно упорядочивая операции и заранее проверяя операнды, часто можно гарантировать априори что результат никогда не будет больше, чем можно сохранить. Инструменты статического анализа, формальная проверка и методы проектирования по контракту могут использоваться для более надежной и надежной защиты от случайного переполнения.
Обработка
Если ожидается, что может произойти переполнение, то в программу можно вставить тесты, чтобы определить, когда это произойдет, и выполнить другую обработку, чтобы смягчить его. Например, если важный результат, вычисленный из переполнения пользовательского ввода, программа может остановиться, отклонить ввод и, возможно, предложить пользователю другой ввод, вместо того, чтобы программа продолжала работу с недопустимым переполненным вводом и, возможно, как следствие, неисправна. Этот полный процесс можно автоматизировать: можно автоматически синтезировать обработчик для целочисленного переполнения, где обработчик, например, является чистым выходом.
ЦП обычно имеют способ обнаружения этого для поддержки сложения чисел большего размера чем размер их регистра, обычно использующий бит состояния; этот метод называется арифметикой с высокой точностью. Таким образом, можно добавить два числа каждые два байта шириной, просто добавляя байты по шагам: сначала добавьте младшие байты, затем добавьте старшие байты, но если необходимо выполнить младшие байты, это арифметическое переполнение добавление байтов, и становится необходимым обнаруживать и увеличивать сумму старших байтов.
Явное распространение
, если значение слишком велико для сохранения, ему может быть присвоено специальное значение, указывающее, что произошло переполнение, а затем все последующие операции возвращают это значение флага. Такие значения иногда обозначаются как NaN, что означает «не число». Это полезно для того, чтобы можно было проверить проблему один раз в конце длинных вычислений, а не после каждого шага. Это часто поддерживается оборудованием с плавающей запятой, называемым FPU.
Поддержка языков программирования
В языках программирования реализованы различные методы предотвращения случайного переполнения: Ada, Seed7 (и некоторые варианты функциональных языков) запускают условие исключения при переполнении, тогда как Python (начиная с версии 2.4) легко преобразует внутреннее представление числа в соответствии с его ростом, в конечном итоге представляя его как long— чьи возможности ограничены только доступной памятью.
В языках с собственной поддержкой арифметики произвольной точности и безопасности типов (например, Python или Common Lisp ), числа автоматически увеличиваются до большего размера, когда происходят переполнения, или генерируются исключения (условия сигнализируются), когда существует ограничение диапазона. Таким образом, использование таких языков может помочь смягчить эту проблему. Однако в некоторых таких языках все еще возможны ситуации, когда может произойти целочисленное переполнение. Примером является явная оптимизация пути кода, который профилировщик считает узким местом. В случае Common Lisp это возможно с помощью явного объявления для обозначения типа переменной слова машинного размера (fixnum) и понижения уровня безопасности типа до нуля для конкретного блока кода.
Насыщенная арифметика
В компьютерной графике или обработке сигналов обычно работают с данными в диапазоне от 0 до 1 или от -1 на 1. Например, возьмите изображение в оттенках серого , где 0 представляет черный цвет, 1 представляет белый цвет, а значения между ними представляют оттенки серого. Одна операция, которую можно поддерживать, — это увеличение яркости изображения путем умножения каждого пикселя на константу. Насыщенная арифметика позволяет просто слепо умножать каждый пиксель на эту константу, не беспокоясь о переполнении, просто придерживаясь разумного результата, что все эти пиксели больше 1 (т. Е. «ярче белого» ) просто становятся белыми, а все значения «темнее черного» просто становятся черными.
Примеры
Непредвиденное арифметическое переполнение — довольно частая причина ошибок программы. Такие ошибки переполнения может быть трудно обнаружить и диагностировать, поскольку они могут проявляться только для очень больших наборов входных данных, которые с меньшей вероятностью будут использоваться в проверочных тестах.
Получение среднего арифметического двух чисел путем сложения их и деления на два, как это делается во многих алгоритмах поиска , вызывает ошибку, если сумма (хотя и не результирующее среднее) слишком велика для
Необработанное арифметическое переполнение в программном обеспечении управления двигателем было основной причиной крушения в 1996 году первого полета ракеты Ariane 5. Считалось, что программное обеспечение не содержит ошибок, так как оно использовалось во многих предыдущих полетах, но в них использовались ракеты меньшего размера, которые генерировали меньшее ускорение, чем Ariane 5. К сожалению, часть программного обеспечения, в которой произошла ошибка переполнения, даже не требовалась. запускался для Ariane 5 в то время, когда он привел к отказу ракеты — это был процесс режима запуска для меньшего предшественника Ariane 5, который остался в программном обеспечении, когда он был адаптирован для новой ракеты. Кроме того, фактической причиной сбоя был недостаток в технической спецификации того, как программное обеспечение справлялось с переполнением, когда оно было обнаружено: оно выполнило диагностический дамп на свою шину, которая должна была быть подключена к испытательному оборудованию во время тестирования программного обеспечения во время разработки. но был связан с двигателями рулевого управления ракеты во время полета; из-за сброса данных сопло двигателя сильно отклонилось в сторону, что вывело ракету из-под контроля аэродинамики и ускорило ее быстрое разрушение в воздухе.
30 апреля 2015 года Федеральное управление гражданской авиации США объявил, что прикажет операторам Boeing 787 периодически перезагружать его электрическую систему, чтобы избежать целочисленного переполнения, которое может привести к потере электроэнергии и развертыванию воздушной турбины, и Boeing развернул обновление ПО в четвертом квартале. Европейское агентство по авиационной безопасности последовало 4 мая 2015 года. Ошибка возникает через 2 центсекунды (248,55134814815 дней), указывая на 32-битное подписанное целое число.
. очевидно в некоторых компьютерных играх. В аркадной игре Donkey Kong, невозможно продвинуться дальше 22 уровня из-за целочисленного переполнения его времени / бонуса. Игра берет номер уровня, на котором находится пользователь, умножает его на 10 и добавляет 40. Когда они достигают уровня 22, количество времени / бонуса равно 260, что слишком велико для его 8-битного регистра значений 256, поэтому он сбрасывается. до 0 и дает оставшиеся 4 как время / бонус — слишком мало для завершения уровня. В Donkey Kong Jr. Math при попытке вычислить число, превышающее 10 000, отображаются только первые 4 цифры. Переполнение является причиной знаменитого уровня «разделенного экрана» в Pac-Man и «Ядерного Ганди» в Civilization. Это также привело к появлению «Дальних земель» в Minecraft, которые существовали с периода разработки Infdev до Beta 1.7.3; однако позже это было исправлено в Beta 1.8, но все еще существует в версиях Minecraft Pocket Edition и Windows 10 Edition. В игре Super Nintendo Lamborghini American Challenge игрок может заставить свою сумму денег упасть ниже 0 долларов во время гонки, будучи оштрафованным сверх лимита оставшихся денег после уплаты сбора за гонка, в которой происходит сбой целого числа, и игрок получает на 65 535 000 долларов больше, чем он получил бы после отрицательного результата. Подобный сбой происходит в S.T.A.L.K.E.R.: Clear Sky, где игрок может упасть до отрицательной суммы, быстро путешествуя без достаточных средств, а затем перейти к событию, где игрока ограбят и у него заберут всю валюту. После того, как игра попытается забрать деньги игрока на сумму в 0 долларов, игроку выдается 2147482963 игровой валюты.
В структуре данных Покемон в играх с покемонами число полученных очков опыта хранится в виде 3-байтового целого числа. Однако в первом и втором поколениях группа опыта со средней медленной скоростью, которой требуется 1 059 860 очков опыта для достижения 100 уровня, по расчетам имеет -54 очка опыта на уровне 1. Поскольку целое число не имеет знака, значение превращается в 16 777 162. Если покемон набирает менее 54 очков опыта в битве, то покемон мгновенно перескакивает на 100-й уровень. Кроме того, если эти покемоны на уровне 1 помещаются на ПК, и игрок пытается их вывести, игра вылетает., из-за чего эти покемоны навсегда застревают на ПК. В тех же играх игрок, используя Редкие Конфеты, может повысить уровень своего Покемона выше 100 уровня. Если он достигает уровня 255 и используется другая Редкая Конфета, то уровень переполняется до 0 (из-за того, что уровень кодируется в один байт, например, 64 16 соответствует уровню 100).
 Ошибка целочисленной подписи в коде настройки стека, выпущенная компилятором Pascal, помешала Microsoft / IBM MACRO Assembler Version 1.00 (MASM), DOS программа 1981 года и многие другие программы, скомпилированные с помощью того же компилятора, для работы в некоторых конфигурациях с объемом памяти более 512 КБ.
Ошибка целочисленной подписи в коде настройки стека, выпущенная компилятором Pascal, помешала Microsoft / IBM MACRO Assembler Version 1.00 (MASM), DOS программа 1981 года и многие другие программы, скомпилированные с помощью того же компилятора, для работы в некоторых конфигурациях с объемом памяти более 512 КБ.
Microsoft / IBM MACRO Assembler (MASM) версии 1.00 и, вероятно, все другие программы, созданные с помощью того же Компилятор Паскаля имел ошибку переполнения целого числа и подписи в коде настройки стека, что не позволяло им работать на новых машинах DOS или эмуляторах в некоторых распространенных конфигурациях с более чем 512 КБ памяти. Программа либо зависает, либо отображает сообщение об ошибке и выходит в DOS.
В августе 2016 года автомат казино в Resorts World Casino распечатал призовой билет на 42 949 672,76 долларов в результате ошибки переполнения. Казино отказалось выплатить эту сумму, назвав это неисправностью, используя в свою защиту то, что в автомате четко указано, что максимальная выплата составляет 10 000 долларов, поэтому любой превышающий эту сумму приз должен быть результатом ошибки программирования. Верховный суд штата Айова вынес решение в пользу казино.
См. Также
- Переполнение буфера
- Переполнение кучи
- Переключение указателя
- Тестирование программного обеспечения
- буфер стека переполнение
- Статический анализ программы
- Сигнал Unix
Ссылки
Внешние ссылки
- Фракция № 60, Базовое целочисленное переполнение
- Фракция № 60, Целочисленная защита большого цикла
- Эффективная и Точное обнаружение целочисленных атак
- Классификация угроз WASC — Целочисленные переполнения
- Общие сведения о целочисленном переполнении в C / C ++
- Двоичное переполнение — двоичная арифметика
- Стандарт ISO C11
Ошибки переполнения буфера извне и изнутри как обобщенный опыт реальных атак
Ошибки переполнения буфера извне и изнутри как обобщенный опыт реальных атак — Архив WASM.RU
мы живем в суровом мире. программное обеспечение,
окружающее нас, содержит дыры, многие из которых размерами со слона. в дыры
лезут хакеры, вирусы и черви, совершающие набеги изо всех концов сети. червям
противостоят антивирусы, заплатки, брандмаузеры и другие умные слова,
существующие лишь на бумаге и бессильные сдержать размножение червей в реальной
жизни. сеть небезопасна – это факт. можно до потери пульса закидывать Билла
Гейтса тухлыми яйцами и кремовыми тортами, но ситуация от этого вряд ли
измениться.анализ показывает, что подавляющее большинство червей
и хакерских атак основаны на ошибках переполнения буфера, которые носят
фундаментальный характер и которых не избежало практически ни одно полновесное
приложение. попытка разобраться в этой, на первый взгляд довольно скучной и
незатейливой проблеме безопасности, погружает вас в удивительный мир, полный
приключений и интриг. захват управления системой путем переполнения
буфера – сложная инженерная задача, требующая нетривиального мышления и
превосходной экипировки. диверсионный код, заброшенный на выполнение, находится
весьма в жестких и агрессивных условиях не обеспечивающих и минимального уровня
жизнедеятельности.если вам нужен путеводитель по стране переполняющихся
буферов, снабженный исчерпывающим руководством по выживанию – эта статья
для вас!введение
Чудовищная
сложность современных компьютерных систем неизбежно приводит к ошибкам
проектирования и реализации, многие из которых позволяют злоумышленнику
захватывать контроль над удаленным узлом или делать с ним что-то нехорошее.
Такие ошибки называются дырами или уязвимостями (holes и vulnerability
соответственно).Мир
дыр чрезвычайно многолик и разнообразен: это и отладочные люки, и слабые
механизмы аутентификации, и функционально-избыточная интерпретация
пользовательского ввода, и некорректная проверка аргументов и т. д.
Классификация дыр чрезвычайно размыта, взаимно противоречива и затруднена (во
всяком случае, своего Карла Линнея дыры еще ждут), а методики их поиска и
«эксплуатации» не поддаются обобщению и требуют творческого подхода к
каждому отдельно взятому случаю. Было бы наивно надеяться, что
одна-единственная публикация сможет описать весь этот зоопарк! Давайте лучше
сосредоточимся на ошибках переполнения буферов (buffer overflow/overrun) – как на
наиболее важном, популярном, перспективном и приоритетном направлении.Большую
часть статьи мы будем витать в бумажных абстракциях теоретических построений и
лишь к концу спустимся на ассемблерную землю, обсуждая наиболее актуальные
проблемы практических реализаций. Нет, не подумайте! Никто не собирается в
сотый раз объяснять, что такое стек, адреса памяти и откуда они растут! Эта
публикация рассчитана на хорошо подготовленную читательскую аудиторию, знающую
ассемблер и бегло изъясняющуюся на Си/Си++ без словаря. Как происходит
переполнение буфера вы, вероятно, уже представляете и теперь хотели бы
ознакомится с полным списком возможностей, предоставляемых переполняющимися
буферами. Какие цели может преследовать атакующий? По какому принципу
происходит отбор наиболее предпочтительных объектов атаки? Ну и т. д…Другими
словами, в данной статье мы будем говорить исключительно о том, что можно
сделать с помощью переполнения и лишь в следующих статьях перейдем к вопросу
«как именно это сделать».Описанные
приемы работоспособны на большинстве процессорных архитектур и операционных
систем (например, UNIX/SPARC). Пусть вас не смущает, что приводимые примеры в основном
относятся к Windows NT и производным от нее системам. Просто, в момент написания статьи
другой операционной системы не оказалось под рукой.мясной рулет ошибок переполнения
или попытка классификации (скукота смертная)Согласно
«Новому Словарю Хакера» Эрика Раймонда ошибки переполнения буфера это
«то, что с неизбежностью происходит при попытке засунуть в буфер
больше, чем тот может переварить«. На самом деле, это всего лишь
частный случай последовательного переполнения при записи. Помимо него существуют
индексное переполнение, заключающееся в доступе к произвольной ячейке памяти за
концом буфера, где под «доступом» понимаются как операции чтения, так
и операции записи.Переполнение
при записи приводит к затиранию, а следовательно, искажению одной или
нескольких переменных (включая служебные переменные, внедряемые компилятором,
такие, например, как адреса возврата или указатели this), нарушая тем самым
нормальный ход выполнения программы и вызывая одно из следующих последствий:
- нет никаких последний
- программа выдает неверные данные или, попросту говоря, делает из чисел винегрет
- программа «вылетает», зависает или аварийно завершается с сообщением об ошибке
- программа изменяет логику своего поведения, выполняя незапланированные действия
Переполнение
при чтении менее опасно, т. к. «всего лишь» приводит к
потенциальной возможности доступа к конфиденциальным данным (например, паролям
или идентификаторам TCP/IP
соединения).Листинг 1 пример последовательно переполнения буфера при записи
Листинг 2 пример индексного переполнения буфера при чтении
За
концом буфера могут находится данные следующих типов: другие буфера, скалярные
переменные и указатели или же вовсе может не находится ничего (например,
невыделенная страница памяти). Теоретически, за концом буфера может
располагаться исполняемый код, но на практике такая ситуация практически
никогда не встречается.Наибольшую
угрозу для безопасности системы представляют именно указатели, поскольку они
позволяют атакующему осуществлять запись в произвольные ячейки памяти или
передавать управление по произвольным адресам, например, на начало самого
переполняющегося буфера в котором расположен машинный код, специально
подготовленный злоумышленником, и обычно называемый shell-кодом.Буфера,
располагающиеся за концом переполняющегося буфера, могут хранить некоторую
конфиденциальную информацию (например, пароли). Раскрытие чужих паролей, равно
как и навязывание атакуемой программе своего пароля – вполне типичное
поведение для атакующего.Скалярные
переменные могут хранить индексы (и тогда они фактически приравниваются к
указателям), флаги, определяющие логику поведения программы (в том числе и
отладочные люки, оставленные разработчиком) и прочую информацию.В
зависимости от своего местоположения буфера делаться на три независимые
категории: а) локальные буфера, расположенные в стеке и часто называемые
автоматическими переменными; б) статичные буфера, расположенные в секции
(сегменте) данных; в) динамические буфера, расположенные в куче. Все они
имеют свои специфичные особенности переполнения, которые мы обязательно
рассмотрим во всех подробностях, но сначала немного пофилософствуем.неизбежность ошибок переполнения в исторической перспективе
Ошибки
переполнения – это фундаментальные программистские ошибки, которые
чрезвычайно трудно отслеживать и фундаментальность которых обеспечивается самой
природой языка Си – наиболее популярного языка программирования всех
времен и народов, – а точнее его низкоуровневым характером взаимодействия
с памятью. Поддержка массивов реализована лишь частично и работа с ними требует
чрезвычайной аккуратности и внимания со стороны программиста. Средства
автоматического контроля выхода за границы отсутствуют, возможность определения
количества элементов массива по указателю и не ночевала, строки, завершающиеся
нулем, – вообще песня…Дело
даже не в том, что малейшая небрежность и забытая или некорректно реализованная
проверка корректности аргументов, приводит к потенциальной уязвимости
программы. Корректную проверку аргументов невозможно осуществить в принципе!
Рассмотрим функцию, определяющую длину переданной ей строки, и посимвольно
читающую эту строку до встречи с завершающим ее нулем. А если завершающего нуля
на конце не окажется? Тогда функция вылетит за пределы утвержденного блока
памяти и пойдет чесать непаханую целину посторонней оперативной памяти! В
лучшем случае это закончится выбросом исключения. В худшем – доступом к
конфиденциальным данным. Можно, конечно, передать максимальную длину строкового
буфера с отдельным аргументом, но кто поручиться, что она верна? Ведь этот
аргумент приходится формировать вручную и, следовательно, он не застрахован от
ошибок. Короче говоря, вызываемой функции ничего не остается как закладывается
на корректность переданных ей аргументов, а раз так – о каких проверках мы
вообще говорим?!С
другой стороны – выделение буфера возможно лишь после вычисления длины
принимаемой структуры данных, т. е. должно осуществляется динамически. Это
препятствует размещению буферов в стеке, поскольку, стековые буфера имеют
фиксированный размер, задаваемый еще на стадии компиляции. Зато стековые буфера
автоматически освобождаются при выходе из функции, снимания это бремя с плеч
программиста и предотвращая потенциальные проблемы с утечками памяти.
Динамические буфера, выделяемые из кучи, намного менее популярны, поскольку их
использование уродует структуру программы. Если раньше обработка текущих ошибок
сводилась к немедленному return’у, то теперь перед выходом из функции приходится выполнять специальный
код, освобождающий все, что программист успел к этому времени понавыделять. Без
критикуемого goto (которое само по себе нехилый глюкодром) эта задача решается только
глубоко вложенными if’ами, обработчиками структурных исключений, макросами или внешними
функциями, что захламляет листинг и служит источником многочисленных и
трудноуловимых ошибок.Многие
библиотечные функции (например, gets, sprintf) не имеют никаких средств ограничения длины возвращаемых данных и
легко вызывают ошибки переполнения. Руководства по безопасности буквально кишат
категорическим запретами на использование последних, рекомендуя их «безопасные»
аналоги – fgets и snprintf, явно специфицирующие предельно допустимую длину буфера, передаваемую
в специальном аргументе. Помимо неоправданного загромождения листинга
посторонними аргументами и естественных проблем с их синхронизацией (при работе
со сложными структурами данных, когда один-единственный буфер хранит много
всякой всячины, вычисления длины оставшегося «хвоста» становится не
такой уж очевидной арифметической задачей и здесь очень легко допустить грубые
ошибки), программист сталкивается с необходимостью контроля целостности
обрабатываемых данных. Как минимум необходимо убедиться, что данные не были
варварски обрезаны и/или усечены, а как максимум – корректно обработать
ситуацию с обрезанием. А что мы, собственно, здесь можем сделать? Увеличить
буфер и повторно вызывать функцию, чтобы скопировать туда остаток? Не
слишком-то элегантное решение, к тому же всегда существует вероятность потерять
завершающий нуль на конце.В
Си++ ситуация с переполнением обстоит намного лучше, хотя проблем все равно
хватает. Подержка динамических массивов и «прозрачных» текстовых
строк наконец-то появилась (и это очень хорошо), но подавляющее большинство
реализаций динамических массивов работают крайне медленно, а строки тормозят
еще сильнее, поэтому в критических участках кода от них лучше сразу же
отказаться. Иначе и быть не может, поскольку, существует только один способ
построения динамических массивов переменной длины – представление их
содержимого в виде ссылочной структуры (например, двунаправленного списка). Для
быстрого доступа к произвольному элементу список нужно индексировать, а саму
таблицу индексов где-то хранить. Таким образом, чтение/запись
одного-единственненного символа выливается в десятки машинных команд и
множество обращений к памяти (а память была, есть и продолжает оставаться самым
узким местом, существенно снижающим общую производительность системы).Даже
если компилятор вдруг решит заняться контролем границ массива (одно
дополнительное обращение к памяти и три-четыре машинных команды), это не решит
проблемы, поскольку при обнаружении переполнения откомпилированная программа не
сможет сделать ничего умнее, чем аварийно завершить свое выполнение. Вызов
исключения не предлагать, поскольку если программист забудет его обработать (а
он наверняка забудет это сделать), мы получим атаку типа отказ в обслуживании.
Конечно, это не захват системы, но все равно нехорошо.Так
что ошибки переполнения были, есть и будут! От этого никуда не уйти, и коль
скоро мы обречены на длительное сосуществование с последними, будет нелишним
познакомиться с ними поближе…окутанные желтым туманом мифов и легенд
Журналисты,
пишущие о компьютерной безопасности, и эксперты по безопасности, зарабатывающие
на жизнь установкой этих самых систем безопасности, склоны преувеличивать значимость
и могущество атак, основанных на переполнении буфера. Дескать, хакеры буфера
гребут лопатой и если не принять адекватных (и весьма дорогостоящих!) защитных
мер, ваша информация превратится в пепел.Все
это так (ведь и на улицу лишний раз лучше не выходить – случается, что и
балконы падают), но за всю историю существования компьютерной индустрии не
насчитывается и десятка случаев широкомасштабного использования переполняющихся
буферов для распространения вирусов или атак. Отчасти потому, что атаки
настоящих профессионалов происходят бесшумно. Отчасти – потому, что
настоящих профессионалов среди современных хакеров практически совсем не
осталось…Наличие
одного или нескольких переполняющихся буферов еще ни о чем не говорит и
большинство ошибок переполнения не позволяет атакующему продвинуться дальше
банального DoS’а. Вот неполный перечень ограничений, с которыми приходится
сталкивается червям и хакерам:
- строковые переполняющиеся буфера (а таковых среди них большинство) не
позволяют внедрять символ нуля в середину буфера и препятствуют вводу некоторых
символов, которые программа интерпретирует особым образом;- размер переполняющихся буферов обычно оказывается катастрофически мал
для вмещения в них даже простейшего загрузчика или затирания сколь ни будь
значимых структур данных;- абсолютный адрес переполняющегося буфера атакующему чаще всего
неизвестен, поэтому приходится оперировать относительными адресами, что очень
непросто с технической точки зрения;- адреса системных и библиотечных функций меняются от одной операционной
системы к другой – это раз. ни на какие адреса уязвимой программы так же
нельзя закладываться, поскольку они непостоянны (особенно это актуально для UNIX-приложений,
компилируемых каждым пользователем самостоятельно) – а это два;- наконец, от атакующего требуется глубокое значение команд процессора,
архитектуры операционной системы, особенности различных компиляторов языка,
свободное от академических предрассудков мышление, плюс уйма свободного времени
для анализа, проектирования и отладки shell-кода.А
теперь для контраста перечислим мифы противоположной стороны – стороны
защитников информации, с какой-то детской наивностью свято верящих, что от
хакеров можно защититься хотя бы в принципе.
- не существуют никаких надежных методик автоматического (или хотя бы
полуавтоматического) поиска переполняющихся буферов, дающих удовлетворительный
результат и по-настоящему крупные дыры не обнаруживаются целенаправленным
поиском. их открытие – игра слепого случая;- все разработанные методики борьбы с переполняющимися буферами снижают
производительность (под час очень значительно), но не исключают возможность
переполнения полностью, хотя и портят атакующему жизнь;- межсетевые экраны отсекают лишь самых примитивнейших из червей,
загружающих свой хвост через отдельное TCP/IP соединение, отследить же передачу данных в контексте уже установленных
TCP/IP соединений никакой
межсетевой экран не в силах;Существуют
сотни тысяч публикаций, посвященных проблеме переполнения, краткий список
которых был приведен в предыдущей статье этого цикла. Среди них есть как
уникальные работы, так и откровенный поросячий визг, подогреваемый собственной
крутизной (мол, смотрите, я тоже стек сорвал! Ну и что, что в лабораторных
условиях?!). Статьи теоретиков от программирования элементарно распознаются
замалчиванием проблем, с которыми сразу же сталкиваешься при анализе
полновесных приложений и проектировании shell-кодов (по сути своей являющихся
высоко-автономными роботами).Большинство
автором ограничивается исключительно вопросами последовательного переполнения
автоматических буферов, оттесняя остальные виды переполнений на задний план, в
результате чего у многих читателей создается выхолощенное представление о
проблеме. На самом деле, мир переполняющихся буферов значительно шире, многограннее
и интереснее, в чем мы сейчас и убедимся.похороненный под грудой распечаток исходного и
дизассемблерного кодаКак
происходит поиск переполняющихся буферов и как осуществляется проектирование shell-кода? Первым делом
выбирается объект нападения, роль которого играет уязвимое приложение. Если вы
хотите убедиться в собственной безопасности или атаковать строго определенный
узел, вы должны исследовать конкретную версия, конкретного программного пакета,
установленного на конкретной машине. Если же вы стремитесь прославиться на весь
мир или пытаетесь сконструировать мощное оружие, дающее вам контроль над
десятками тысяч, а то и миллионами машин, ваш выбор становится уже не так
однозначен.С
одной стороны, это должна быть широко распространенная и по возможности
малоисследованная программа, исполняющаяся с наивысшими привилегиями и сидящая
на портах, которые не так-то просто закрыть. Разумеется, с точки зрения
межсетевого экрана все порты равноценны и ему абсолютно все равно что
закрывать. Однако, пользователи сетевых служб и администраторы придерживаются
другого мнения. Если от 135-порта, используемого червем Love San, в
подавляющем большинстве случаев можно безболезненно отказаться (лично автор
этой статьи именно так и поступил), то без услуг того же WEB-сервера обойдешься
едва ли.Чем
сложнее и монстроузнее исследуемое приложение, тем больше вероятность
обнаружить в нем критическую ошибку. Следует так же обращать внимание и на
формат представления обрабатываемых данных. Чаще всего переполняющиеся буфера
обнаруживаются в синтаксических анализаторах, выполняющих парсинг текстовых
строк, однако, большинство этих ошибок уже давно обнаружено и устранено. Лучше
искать переполняющиеся буфера там, где до вас их никто не искал. Народная
мудрость утверждает: хочешь что-то хорошо спрятать – положи это на самое
видное место. На фоне нашумевших эпидемий Love San’a и Slapper’а с этим трудно не согласиться. Кажется невероятным, что такие
очевидные переполнения до последнего времени оставались необнаруженными!Наличие
исходных текстов одновременно желательно и нежелательно. Желательно –
потому что они существенно упрощают и ускоряют поиск переполняющихся буферов, а
нежелательно… по той же самой причине! Как говориться: больше народу –
меньше кислороду. Действительно, трудно рассчитывать найти что-то новое в
исходнике, зачитанном всеми до дыр. Отсутствие исходных текстов существенно
ограничивает круг исследователей, отсекая многочисленную армию прикладных
программистов и еще большую толпу откровенных непрофессионалов. Здесь, в
прокуренной атмосфере ассемблерных команд, выживает лишь тот, кто программирует
быстрее, чем думает, а думает быстрее, чем говорит. Тот, кто может удержать в
голове сотни структур данных, буквально на физическом уровне ощущая их
взаимосвязь, и каким-то шестым чувством угадывая в каком направлении нужно
копать. Собственный программистский опыт может только приветствоваться.
Во-первых, так легче вжиться в привычки, характер и образ мышления разработчика
исследуемого приложения. Задумайтесь: а как бы вы решили данную задачу, окажись
на его месте? Какие бы могли допустить ошибки? Где бы проявили непростительную
небрежность, соблазнившись компактностью кода и элегантностью листинга?Кстати,
об элегантности. Бытует мнение, что неряшливый стиль программного кода
неизбежно провоцирует программиста на грубые ошибки (и ошибки переполнения в
том числе). Напротив, педантично причесанная программа ошибок скорее всего не
содержит и анализировать ее означает напрасно тратить свое время. Как знать…
Автору приходилось сталкиваться с вопиюще небрежными листингами, которые
работали как часы, потому что были сконструированы настоящими профессионалами,
наперед знающими где подстелить соломку, чтобы не упасть. Встречались и по
академически аккуратные программы, дотошно и не по одному разу проверяющие все,
что только можно проверить, но буквально нашпигованные ошибками переполнения.
Тщательность сама по себе еще ни от чего не спасает. Для предотвращения ошибок
нужен богатый программистский опыт, – и опыт оставленный граблями в том
числе. Но вместе с опытом зачастую появился и вальяжная небрежность –
своеобразный «отходяк» от юношеского увлечения эффективностью и
оптимизаций.Признаком
откровенного непрофессионализма является пренебрежение #defin’ами или безграмотное
использование последних. В частности, если размер буфера buff определяется через MAX_BUF_SIZE, то и размер
копируемой в него строки должен ограничиваться им же, а не MAX_STR_SIZE, заданным в отдельном
define.
Обращайте внимание и на характер аргументов функций, работающих с блоками
данных. Передача функции указателя без сообщения размера блока – частая
ошибка начинающих, равно как и злоупотребление функциями strcpy/strncpy. Первая –
небезопасна (отсутствует возможность ограничить предельно допустимую длину
копируемой строки), вторая – ненадежна (отсутствует возможность оповещения
о факте «обрезания» хвоста строки, не уместившегося в буфер, что само
по себе может служить весьма нехилым источником ошибок).Хорошо,
ошибка переполнения найдена. Что дальше? А дальше только дизассемблер. Не
пытайтесь выжать из исходных текстов хоть какую-то дополнительную информацию.
Порядок размещения переменных в памяти не определен и практически никогда не
совпадает с порядком их объявления в программе. Может оказаться так, что
большинства из этих переменных в памяти попросту нет и они размещены
компилятором в регистрах, либо же вовсе отброшены оптимизатором как ненужные
(Попутно заметим, что все демонстрационные листинги, приведенные в этой статье,
рассчитывают, что переменные располагаются в памяти в порядке их объявления).Впрочем,
не будем забегать вперед. Дизассемблирование – это тема для отдельной
статьи, которую планируется опубликовать в следующих номерах журнала.цели и возможности атаки
Конечная
цель любой атаки – заставить систему сделать что-то «нехорошее».
Такое, что нельзя добиться легальным путем. Существует по меньшей мере четыре
различных способа реализации атаки:
- чтение секретных переменных;
- модификация секретных переменных;
- передача управления на секретную функции программы;
- передача управления на код, переданный жертве самим злоумышленником;
Чтение секретных переменных. На роль секретных
переменных в первую очередь претендуют пароли на вход в систему, а так же
пароли доступа к конфиденциальной информации. Все они так или иначе содержатся
в адресном пространстве уязвимого процесса, зачастую располагаясь по
фиксированным адресам (под «входом в систему» здесь подразумевается
имя пользователя и пароль, обеспечивающие удаленное управление уязвимым
приложением).Еще
в адресном пространстве процесса содержатся дескрипторы секретных файлов,
сокеты, идентификаторы TCP/IP
соединений и многое другое. Разумеется, вне текущего контекста они не имеют
никакого смысла, но могут быть использованы кодом, переданном жертве
злоумышленником, и осуществляющим, например, установку «невидимого» TCP/IP-соединения, прячась под
«крышей» уже существующего.Ячейки
памяти, хранящие указатели на другие ячейки, «секретными» строго
говоря не являются, однако, знание их содержимого значительно облегчает атаку.
В противном случае атакующему придется определять опорные адреса вслепую.
Допустим, в уязвимой программе содержится следующий код: char *p = malloc(MAX_BUF_SIZE); где p – указатель на
буфер, содержащий секретный пароль. Допустим так же, что в программе имеется
ошибка переполнения, позволяющая злоумышленнику читать содержимое любой ячейки
адресного пространства. Весь вопрос в том: как этот буфер найти? Сканировать
всю кучу целиком не только долго, но и небезопасно, т. к. можно легко
натолкнуться на невыделенную страницу памяти и тогда выполнение процесса
аварийно завершиться. Автоматические и статические переменные в этом отношении
более предсказуемы. Поэтому, атакующий должен сначала прочитать содержимое
указателя p,
а уже затем – секретный пароль, на который он указывает. Разумеется, это
всего лишь пример, которым возможности переполняющего чтения не ограничиваются.Само
же переполняющее чтение реализуется по меньшей мере четырьмя следующими
механизмами: «потерей» завершающего нуля в строковых буферах, модификаций
указателей (см. «указатели и индексы«), индексным
переполнением (см. там же) и навязываем функции printf (и другим функциям форматированного вывода)
лишних спецификаторов.Модификация секретных переменных. Возможность
модификации переменных дает значительно больше возможностей для атаки,
позволяя: а) навязывать уязвимой программе «свои» пароли,
дескрпиторы файлов, TCP/IP
идентификаторы и т. д.; б) модифицировать переменные, управляющие
ветвлением программы; в) манипулировать индексами и указателями, передавая
управление по произвольному адресу (и адресу, содержащему код, специально
подготовленный злоумышленником в том числе).Чаще
всего модификация секретных переменных реализуется посредством
последовательного переполнения буфера, по обыкновению своему поражающему целый
каскад побочных эффектов. Например, если за концом переполняющегося буфера
расположен указатель на некоторую переменную, в которую после переполнения
что-то пишется, злоумышленник сможет затереть любую ячейку памяти на свой выбор
(за исключением ячеек, явно защищенных от модификации, например кодовой секции
или секции .rodata, разумеется).Передача управления на секретную функцию программы. Модификация указателей на исполняемый код привод к возможности
передачи управления на любую функцию уязвимой программы (правда, с передачей
аргументов имеются определенные проблемы). Практически каждая программа
содержит функции, доступные только root’у, и предоставляющие те или иные управленческие возможности (например,
создание новой учетной записи, открытие сессии удаленного управления, запуск
файлов и т.д.). В более изощренных случаях управление передается на середину
функции (или даже на середину машинной инструкции), с таким расчетом, чтобы
процессор выполнил замысел злоумышленника, даже если разработчик программы не
предусматривал ничего подобного.Передача
управления обеспечивается либо за счет изменения логики выполнения программы,
либо за счет подмены указателей на код. И то, и другое опирается на модификацию
ячеек программы, кратно рассмотренную выше.Передача управления на код, переданный жертве самим злоумышленником является разновидностью механизма передачи управления на секретную
функцию программу, только сейчас роль этой функции выполняет код,
подготовленный злоумышленником и тем или иным способом переданный на удаленный
компьютер. Для этой цели может использоваться как сам переполняющийся буфер,
так и любой другой буфер, доступный злоумышленнику для непосредственной
модификации и в момент передачи управления на shell-код присутствующий в адресном пространстве
уязвимого приложения (при этом он должен располагаться по более или менее
предсказуемым адресам, иначе передавать управление будет некому и некуда).жертвы переполнения или объекты атаки
Переполнение
может затирать ячейки памяти следующих типов: указатели, скалярные переменные и
буфера. Объекты языка Си++ включают в себя как указатели (указывающие на
таблицу виртуальных функций, если таковые в объекте есть), так и скалярные
данные-члены (если они есть). Самостоятельной сущности они не образуют и вполне
укладываются в приведенную выше классификацию.указатели и индексы
В
классическом Паскале и других «правильных» языках указали
отсутствуют, но в Си/Си++ они вездесущи. Чаще всего приходится иметь дело с
указателями на данные, несколько реже встречаются указатели на исполняемый код
(указатели на виртуальные функции, указатели на функции, загружаемые
динамической компоновкой и т. д.). Современный Паскаль (раньше
ассоциируемый с компилятором TurboPascal, а теперь еще
и DELPHI)
также немыслим без указателей. Даже если в явном виде указатели и не
поддерживаются, на них держатся динамические структуры данных (куча,
разряженные массивы), используемые внутри языка.Указатели
удобны. Они делают программирование простым, наглядным, эффективным и
естественным. В то же время указатели во всех отношениях категорически
небезопасны. Попав в руки хакера или пищеварительный тракт червя они
превращаются в оружие опустошительной мощности, – своеобразный аналог BFG-900 или, по крайней
мере, плазмогана. Забегая вперед отметим, что указатели обоих типов
потенциально способны к передаче управления на несанкционированный машинный
код.Вот
с указателей на исполняемый код мы и начнем. Рассмотрим ситуацию, когда следом
за переполняющимся буфером buff, расположен указатель на функцию, которая инициализируется до и
вызывается после переполнения буфера (возможно, вызывается не сразу, а спустя
некоторое время). Тогда, мы заполучим аналог функции call или говоря,
другими словами, инструмент для передачи управления по любому (ну или почти
любому) машинному адресу, в том числе и на сам переполняющийся буфер (тогда
управление получит код, переданный злоумышленником).
Листинг 3 фрагмент программы, подверженной переполнению с затиранием
указателя на исполняемый кодПодробнее
о выборе целевых адресов мы поговорим в другой раз, сейчас же сосредоточимся на
поиске затираемых указателей. Первым в голову приходит адрес возврата из
функции, находящийся внизу кадра стека. (правда, чтобы до него дотянуться
требуется пересечь весь кадр целиком и не факт, что нам это удастся, к тому же
его целостность контролируют многие защитные системы, подробнее о которых планируется
рассказать в следующей статье).Другая
популярная мишень – указатели на объекты. В Си++ программах обычно
присутствует большое количество объектов, многие из которых создаются вызовом
оператора new,
возвращающим указатель на свежесозданный экземпляр объекта. Невиртуальные
функции-члены класса вызываются точно так же, как и обычные Си-функции
(т. е. по их фактическому смещению), поэтому они неподвластны атаке.
Виртуальные функции-члены вызываются намного более сложным образом, через
цепочку следующих операций: указатель на экземпляр объекта à указатель на таблицу виртуальных
функций à указатель на
конкретную виртуальную функцию. Указатели на таблицу виртуальных функций не
принадлежат объекту и внедряются в каждый его экземпляр, который чаще всего сохраняется
в оперативной памяти, реже – в регистровых переменных. Указатели на
объекты так же размещаются либо в оперативной памяти, либо в регистрах, при
этом на один и тот же объект может указывать множество указателей (среди
которых могут встретиться и такие, которые расположены непосредственно за
концом переполняющегося буфера). Таблица виртуальных функций (далее просто
виртуальная таблица) принадлежит не экземпляру объекта, а самому объекту,
т. е. упрощенно говоря, мы имеем одну виртуальную таблицу на каждый
объект. «Упрощенно» потому, что в действительности виртуальная
таблица помещается в каждый obj-файл, в котором встречается обращение к членам данного объекта
(раздельная компиляция дает о себе знать). И хотя линкеры в подавляющем
большинстве случаев успешно отсеивают лишние виртуальные таблицы, иногда они
все-таки дублируются (но это уже слишком высокие материи для начинающих). В
зависимости от «характера» выбранной среды разработки и
профессионализма программиста виртуальные таблицы размещаются либо в секции .data (не защищенной от
записи), либо в секции .rodata (доступной лишь на чтение), причем последний случай встречается
значительно чаще.Давайте
для простоты рассмотрим приложения с виртуальными таблицами в секции .data. Если злоумышленнику
удастся модифицировать один из элементов виртуальной таблицы, то при вызове
соответствующей виртуальной функции управление получит не она, а совсем другой
код! Однако, добиться этого будет непросто! Виртуальные таблицы обычно
размещаются в самом начале секции данных, т. е. перед статическими
буферами и достаточно далеко от автоматических буферов (более конкретное
расположение указать невозможно, т. к. в зависимости от операционной
системы стек может находится как ниже, так и выше секции данных). Так что
последовательное переполнение здесь непригодно и приходится уповать на
индексное, все еще остающееся теоретической экзотикой, робко познающий
окружающий мир.Модифицировать
указатель на объект и/или указатель на виртуальную таблицу намного проще,
поскольку они не только находятся в области памяти, доступной для модификации,
но и зачастую располагаются в непосредственной близости от переполняющихся
буферов.Модификация
указателя this приводит к подмене виртуальных функций объекта. Достаточно лишь найти
в памяти указатель на интересующую нас функцию (или вручную сформировать его в
переполняющемся буфере) и установить на него this с таким расчетом, чтобы адрес следующей
вызываемой виртуальной функции попал на подложный указатель. С инженерной точки
зрения это достаточно сложная операция, поскольку кроме виртуальных функций
объекты еще содержат и переменные, которые более или менее активно используют.
Переустановка указателя this искажает их
«содержимое» и очень может быть, что уязвимая программа рухнет
раньше, чем успеет вызвать подложную виртуальную функцию. Можно, конечно,
сымитировать весь объект целиком, но не факт, что это удастся. Сказанное
относится и к указателю на объект, поскольку с точки зрения компилятора они
скорее похожи, чем различны. Однако, наличие двух различных сущностей дает
атакующему свободу выбора, – в некоторых случаях предпочтительнее затирать
указатель this, в некоторых случаях – указатель на объект.
Листинг 4 фрагмент программы, подверженной последовательному переполнению при записи, с затираем указателя на таблицу виртуальных функций
Листинг 5 дизассемблерный листинг переполняющийся программы с краткими комментариями
Рассмотрим
ситуацию, когда следом за переполняющимся буфером, идет указатель на скалярную
переменную p и сама переменная x, которая в некоторый момент выполнения программы по данному указателю
и записывается (порядок чередования двух последних переменных не существенен,
главное, чтобы переполняющийся буфер затирал их всех). Допустим так же, что с
момента переполнения ни указатель, ни переменная не претерпевают никаких
изменений (или изменяются предсказуемым образом). Тогда, в зависимости от
состояния ячеек, затирающих оригинальное содержимое переменных x и p, мы сможем записать
любое значение x по произвольному адресу p, осуществляя это «руками» уязвимой программы. Другими
словами, мы получаем аналог функций POKE и PatchByte/PatchWord языков Бейсик и IDA-Си соответственно.
Вообще-то, на выбор аргументов могут быть наложены некоторые ограничения
(например, функция gets не допускает символа нуля в середине строки), но это не слишком
жесткое условие и имеющихся возможностей вполне достаточно для захвата
управления над атакуемой системой.
Листинг 6 фрагмент программы, подверженной последовательному переполнению при записи и затиранием скалярной переменной и указателя на данные, поглощающими затертую переменную
Индексы являются своеобразной разновидностью
указателей. Грубо говоря, это относительные указатели, адресуемые относительно
некоторой базы. Смотрите, p[i]
можно представить и как *(p+i),
практически полностью уравнивая p и i
в правах.Модификация
индексов имеет свои слабые и сильные стороны. Сильные – указатели требуют
задания абсолютного адреса целевой ячейки, который обычно неизвестен, в то
время как относительный вычисляется на ура. Индексы, хранящиеся в переменных
типа char,
лишены проблемы нулевых символов. Индексы, хранящихся в переменных типа int, могут
беспрепятственно затирать ячейки, расположенные «выше» стартового
адреса (т. е. лежащие в младших адресах), при этом старшие байты индекса
содержат символы FFh, которые значительно более миролюбивы, чем символы нуля.Однако,
если обнаружить факт искажения указателей практически невозможно (дублировать
их значение в резервных переменных не предлагать), то оценить корректность
индексов перед их использованием не составляет никакого труда и многие
программисты именно так и поступают (правда, «многие» еще не означает
«все»). Другой слабой стороной индексов является их ограниченная
«дальнобойность», составляющая ±128/256 байт
(для индексов типа signed/unsignedchar) и ‑2147483648 байт для индексов
типа signedint.
Листинг 7 фрагмент программы, подверженной последовательному переполнению при записи, с затиранием индекса;
скалярные переменные
Скалярные
переменные, не являющиеся ни индексами, ни указателями, намного менее интересны
для атакующих, поскольку в подавляющем большинстве случаев их возможности очень
даже ограничены, однако, на безрыбье сгодятся и они (совместное использование
скальных переменных вместе с указателями/индексами мы только что рассмотрели,
сейчас же нас интересуют скальные переменные сами по себе).Рассмотрим
случай, когда вслед за переполняющимся буфером расположена переменная buks, инициализируемая до
переполнения, а после переполнения используемая для расчетов количества денег,
снимаемых со счета (не обязательно счета злоумышленника). Допустим, программа
тщательно проверяет входные данные и не допускает использования ввода
отрицательных значений, однако, не контролирует целостность самой переменной buks. Тогда, варьируя ее
содержимым по своему усмотрению, злоумышленник без труда обойдет все проверки и
ограничения.
Листинг 8 фрагмент программы, подверженный переполнению с затираем скалярной переменной.
При
всей своей искусственности, приведенный пример чрезвычайно нагляден.
Модификация скалярных переменных только в исключительных случаях приводит к
захвату управления системой, но легко позволяет делать из чисел винегрет, а на
этом уже можно сыграть! Но что же это за исключительные случаи? Во-первых,
многие программы содержат отладочные переменные, оставленные разработчиками, и
позволяющие, например, отключить систему аутентификации. Во-вторых, существует
множество переменных, хранящих начальные или предельно допустимые значения
других переменных, например, счетчиков цикла – for (a =b; a < c; a++) *p++ = *x++; очевидно, что
модификация переменных b и c
приведет к переполнению буфера p со всеми отсюда вытекающими последствиями. В-третьих… да мало ли что
можно придумать – всего и не перечислишь! Затирание скалярных переменных
при переполнении обычно не приводит к немедленному обрушению программы, поэтому
такие ошибки могут долго оставаться не обнаруженными. Будьте внимательными!массивы и буфера
Что
интересного можно обнаружить в буферах? Прежде всего это строки, хранящиеся в PASCAL-формате, т. е.
с полем длины вначале, затирание которого порождает каскад вторичных
переполнений. Про уязвимость буферов с конфиденциальной информацией мы уже
говорили, а теперь, пожалуйста – конкретный, хотя и несколько наигранный
пример:
Листинг 9 фрагмент программы, подверженной последовательному переполнению при записи с затиранием постороннего буфера
Еще
интересны буфера, содержащие имена открываемых файлов (можно заставить
приложение записать конфиденциальные данные в общедоступный файл или, напротив,
навязать общедоступный файл взамен конфиденциального), тем более, что несколько
подряд идущих буферов вообще говоря не редкость.заключение
Изначально
статья задумывалось как исчерпывающее руководство, снабженное большим
количеством листингов и избегающее углубляться в академические
теоретизирования. Теперь, вычитывая статью перед заключительной правкой и внося
в нее мелкие, косметические улучшения, я с грустью осознаю, что выполнить свой
замысел мне так и не удалось… До практических советов разговор вообще не дошел
и львиная часть подготовленного материала осталось за кадром. Ох, и не
следовало мне пытаться объять необъятное…Надеюсь,
что следующие статьи этого цикла исправят положение. В первую очередь планируется
рассказать о передовых методиках переполнения кучи, приводящих к захвату
управления удаленной машиной, обсудить технические аспекты разработки shell-кода (приемы
создания позиционно-независимого кода, проблема вызова системных функций,
оптимизация размера и т. д.), затем будет можно перейти к разговору о
способах поиска переполняющихся буферов и о возможных мерах по
заблаговременному предотвращению оных. Отдельную статью хотелось бы посвятить
целиком червям Love Sun и Slapper, поскольку их дизассемблерные листинги содержат очень много
интересного.© Крис Касперски
archive
New Member
- Регистрация:
- 27 фев 2017
- Публикаций:
- 532

В статье разбираются причины возникновения и последствия ошибок переполнения буфера, предлагаются эффективные методы борьбы с ними. Изложение ориентировано на прикладных разработчиков, работающих с языками программирования Си/Си++ и операционными системами семейства Windows, однако многие из затронутых вопросов применимы и к Unix-подобным системам.
Просматривая популярную рассылку по информационной безопасности BUGTRAQ, легко убедиться, что подавляющее большинство уязвимостей приложений и операционных систем связано с ошибками переполнения буфера. Ошибки этого типа настолько распространены, что вряд ли существует хотя бы один полностью свободный от них программный продукт. Переполнение приводит не только к некорректной работе программы, но и к возможности удаленного вторжения в систему с наследованием всех привилегий компрометированной программы. Это обстоятельство широко используется злоумышленниками. Проблема настольно серьезна, что попытки ее решения предпринимаются как на уровне самих языков программирования, так и на уровне компиляторов. К сожалению, достигнутые результаты оставляют желать лучшего, и ошибки переполнения продолжают появляться даже в современных приложениях. Вот всего несколько примеров: Microsoft Internet Information Service 5.0, Outlook Express 5.5; Netscape Directory Server 4.1x; Apple QuickTime Player 4.1; ISC BIND 8; Lotus Domino 5.0 — список этот можно было бы продолжать и продолжать. А ведь все это серьезные продукты солидных компаний, не скупящихся на тестирование. Давайте поговорим о приемах программирования, следование которым значительно уменьшает вероятность появления ошибок переполнения, в то же время не требуя от разработчика особых дополнительных усилий.
Причины и последствия ошибок переполнения
Во многих языках программирования, в том числе и в Cи/Cи++, массив одновременно является и совокупностью определенного количества объектов данных некоторого типа, и безразмерным фрагментом памяти. Программист может получить указатель на начало массива, но не имеет возможности непосредственно определить его длину. В Си/Си++ не делается особых различий между указателями на массив и указателями на ячейку памяти. Допускаются различные математические операции с указателями.
Мало того, что контроль выхода указателя за границы массива всецело лежит на разработчике — строго говоря, этот контроль невозможен в принципе. Получив указатель на буфер, функция не может самостоятельно вычислить его размер и вынуждена либо полагать, что вызывающий код выделил буфер заведомо достаточного размера, либо требовать явного указания длины буфера в дополнительном аргументе (в частности, по первому сценарию работает gets, а по второму — fgets). Ни то, ни другое не может считаться достаточно надежным; знать наперед сколько памяти потребуется вызывающей функции, вообще говоря, невозможно, а постоянная «ручная» передача длины массива не только утомительна и непрактична, но и не застрахована от ошибок.
Другая частая причина возникновения ошибок переполнения буфера — слишком вольное обращение с указателями. Например, для перекодировки текста может использоваться следующий алгоритм: код преобразуемого символа складывается с указателем на начало таблицы перекодировки и из полученной ячейки извлекается искомый результат. Несмотря на изящество этого и подобных ему алгоритмов, он требует тщательного контроля исходных данных: передаваемый функции аргумент должен быть неотрицательным числом, не превышающим последний индекс таблицы перекодировки; в противном случае произойдет доступ совсем к другим данным. Однако о подобных проверках нередко забывают или реализуют их неправильно.
Можно выделить два типа ошибок переполнения: одни приводят к чтению не принадлежащих к массиву ячеек памяти, другие — к их модификации. В зависимости от расположения буфера за ним могут находиться:
- другие переменные и буферы;
- служебные данные (например, сохраненные значения регистров и адрес возврата из функции);
- исполняемый код;
- незанятая или несуществующая область памяти.
Несанкционированное чтение не принадлежащих к массиву данных может привести к утере конфиденциальности, а их модификация в лучшем случае заканчивается некорректной работой приложения (чаще всего «зависанием»), а в худшем — выполнением действий, никак не предусмотренных разработчиком (например, отключением защиты). Еще опаснее, если непосредственно за концом массива следуют адрес возврата из функции; в этом случае уязвимое приложение потенциально способно выполнить от своего имени любой код, переданный ему злоумышленником. И, если это приложение исполняется с наивысшими привилегиями (что типично для сетевых служб), взломщик сможет как угодно манипулировать системой.
Предотвращение возникновения ошибок переполнения
Таким образом, независимо от того, где располагается переполняющийся буфер — в стеке, сегменте данных или в области динамической памяти (куче), он делает работу приложения небезопасной. Поэтому представляет интерес поговорить о том, можно ли предотвратить такую угрозу и если да, то как.
Переход на другой язык
В идеале контроль за подобными ошибками следовало бы поручить языку, сняв это бремя с плеч программиста. Достаточно запретить непосредственное обращение к массиву, заставив вместо этого пользоваться встроенными операторами языка, которые бы постоянно следили за тем, происходит ли выход за установленные границы, и при необходимости либо возвращали ошибку, либо динамически увеличивали размер массива.
Именно такой подход использован в языках Ада, Perl, Java и некоторых других. Но сферу его применения ограничивает производительность: постоянные проверки требуют значительных накладных расходов, в то время как отказ от них позволяет транслировать даже серию операций обращения к массиву в одну инструкцию процессора. Тем более, такие проверки налагают жесткие ограничения на математические операции с указателями (в общем случае требуя их запретить), а это в свою очередь не позволяет реализовывать многие эффективные алгоритмы.
Если в критических областях применения (атомной энергетике, космонавтике и т.п.) выбор между производительностью и защищенностью автоматически делается в пользу последней, в офисных и уж тем более в бытовых приложениях ситуация обратная. В лучшем случае речь может идти только о разумном компромиссе. Покупать дополнительные мегабайты и мегагерцы ради одного лишь достижения надлежащего уровня безопасности и без всяких гарантий на отсутствие ошибок других типов рядовой клиент не будет, как бы его ни убеждали. Тем более, что ни Ада, ни Perl, ни Java (языки, не отягощенные проблемами переполнения) принципиально не способны заменить Си/Cи++, не говоря уже об ассемблере. Разработчики оказываются зажатыми между несовершенством используемого ими языка программирования и невозможностью перехода на другой язык. Даже если бы и появился язык, удовлетворяющий всем мыслимым требованиям, совокупная стоимость его изучения и переписывания с нуля созданного программного обеспечения многократно бы превысила убытки от отсутствия в старом языке продвинутых средств контроля за ошибками: производители вообще несут очень мало издержек за «ляпы» в своих продуктах и не особо одержимы идей их тотального устранения.
Использование «кучи» для создания массивов
От использования статических массивов рекомендуется вообще отказаться (за исключением тех случаев, когда их переполнение заведомо невозможно). Вместо этого следует выделять память из кучи (Heap), преобразуя указатель, возвращенный функцией malloc к указателю на соответствующий тип данных (char, int), после чего с ним можно обращаться точно так же, как с указателем на обычный массив. Вернее, почти «точно так» — за двумя небольшими исключениями. Во-первых, получившая такой указатель функция может с помощью вызова msize узнать истинный размер буфера, не требуя от программиста явного указания данной величины. А, во-вторых, если в ходе работы выяснится, что этого размера недостаточно, она может динамически увеличить длину буфера, обращаясь к realloc всякий раз, как только в этом возникнет потребность. В этом случае, передавая функции, читающей строку с клавиатуры, указатель на буфер, не придется мучительно соображать: какой именно величиной следует ограничить его размер, — об этом позаботится сама вызываемая функция. Программисту же не придется добавлять еще одну константу в свою программу.
Отказ от индикатора завершения
По возможности не используйте какой бы то ни было индикатор завершения для распознания конца данных (например, нуль для задания конца строки). Во-первых, это приводит к неопределенности в длине самих данных и количества памяти, необходимой для их размещения, в результате чего возникают ошибки типа buff = malloc(strlen(Str)), которые с первого взгляда не всегда удается обнаружить (правильный код должен выглядеть так: buff = malloc(strlen(Str)+1), поскольку, в длину строки, возвращаемой функцией srtlen, не входит завершающий ее нуль).
Во-вторых, если по каким-то причинам индикатор конца будет уничтожен, функция, работающая с этими данными, «забредет» совсем не в свой «лес».
В-третьих, такой подход приводит к крайне неэффективному подсчету объема памяти, занимаемого данными: приходится их последовательно перебирать один за другим до тех пор пока не встретится символ конца, а, поскольку по соображениям безопасности при каждой операции конкатенации и присваивания необходимо проверять, достаточно ли свободного пространства для ее завершения, очень важно оптимизировать этот процесс.
Значительно лучше явным образом указывать размер данных в отдельном поле (так, например, задается длина строк в компиляторах Turbo Pascal и Delphi). Однако такое решение не устраняет несоответствия размера данных и количества занимаемой ими памяти. Поэтому надежнее вообще отказаться от какого бы то ни было задания длины данных и всегда помещать их в буфер строго соответствующего размера.
Избавиться от накладных расходов, связанных с необходимостью частых вызовов достаточно медленной функции realloc можно введением специального ключевого значения, обозначающего отсутствие данных. В частности, для этой цели подойдет тот же нуль, однако, теперь он будет иметь другое значение — обозначать не конец строки, а отсутствие символа в данной позиции. Конец же строки определяется размером выделенного под нее буфера данных. Выделив буфер «про запас» и забив его «хвост» нулями, можно значительно сократить количество вызовов realloc. (Правда, в этом случае за эффективное использование ресурсов процессора приходится расплачиваться существенным перерасходом памяти. — Прим. ред.)
Обработка структурных исключений
Описанные приемы реализуются без особых усилий и излишних накладных расходов. Единственным серьезным недостатком является их несовместимость со стандартными библиотеками, так как они интенсивно используют признак завершения и не умеют по указателю на начало буфера определять его размер. Частично эта проблема может быть решена написанием слоя переходного кода, «посредничающего» между стандартными библиотеками и вашей программой.
Однако следует помнить, что описанные подходы сами по себе не защищают от ошибок переполнения, а только уменьшают вероятность их появления. Они исправно работают только в том случае, когда разработчик всегда помнит о необходимости постоянного контроля за границами массивов. Гарантировать выполнение такого требования невозможно в любой «полновесной» программе, состоящей из десятков или сотен тысяч строк. К тому же, чем больше проверок делает программа, тем «тяжелее» и медлительнее получается код и тем вероятнее, что хотя бы одна из проверок реализована неправильно или по забывчивости не реализована вообще. Можно ли, избежав нудных проверок, в то же время получить высокопроизводительный код, гарантированно защищенный от ошибок переполнения?
Несмотря на смелость вопроса, на него есть основания дать положительный ответ. И помогает в этом обработка структурных исключений. В общих чертах идея состоит в следующем: выделяется некий буфер, с обеих сторон «окольцованный» несуществующими страницами памяти и устанавливается обработчик исключений, «отлавливающий» прерывания, вызываемые при попытке доступа к несуществующей странице (вне зависимости от того, был ли это запрос на запись или чтение). Необходимость постоянного контроля границ массива при каждом к нему обращении отпадает. Точнее, теперь она «перекладывается» на процессор, а от программиста требуется всего лишь написать несколько строк кода, возвращающего ошибку или увеличивающего размер буфера при его переполнении. Единственным незакрытым лазом останется возможность прыгнуть далеко-далеко за конец буфера и случайно попасть на не имеющую к нему никакого отношения, но все-таки существующую страницу. В этом случае прерывания не произойдет и обработчик исключений ничего не узнает о факте нарушения. Однако такая ситуация достаточно маловероятна (чаще всего буферы читаются и записываются последовательно, а не в разброс), поэтому ею можно полностью пренебречь.
Преимущества технологии обработки структурных исключений заключаются в надежности, компактности и ясности использующего ее программного кода, не отягощенного беспорядочно разбросанными проверками, затрудняющими его понимание. Основной недостаток — плохая переносимость и системная зависимость. Не всякие операционные системы позволяют прикладному коду манипулировать на низком уровне со страницами памяти, а те, что позволяют, реализуют это каждая по-своему. В Windows, к счастью, такая возможность есть.
Функция VirtualAlloc обеспечивает выделение сегмента виртуальной памяти, с которым можно обращаться в точности как и с обычным динамическим буфером, а вызов VirtualProtect позволят изменить его атрибуты защиты. Можно задавать любой требуемый тип доступа, например, разрешить только чтение памяти, но не запись или исполнение. Это позволяет защищать критически важные структуры данных от разрушения некорректно работающими функциями. А запрет на исполнение кода в буфере даже при наличии ошибок переполнения не дает злоумышленнику никаких шансов запустить собственноручно переданный им код.
Использование функций, непосредственно работающих с виртуальной памятью, позволяет творить настоящие чудеса, на которые не способны функции стандартной библиотеки Си/Cи++. Единственный их недостаток заключается в непереносимости. Однако эту проблему можно решить, собственноручно реализовав функции VirtualAlloc, VirtualProtect и некоторые другие (правда, в некоторых случаях это придется делать на уровне компонентов ядра; обработка же структурных исключений изначально заложена в Си++).
Таким образом, усилия, направленные на защиту от ошибок переполнения буфера не настолько чрезмерны, чтобы не окупить полученный результат.
Традиции против надежности
Здравый смысл подсказывает: «Если все очень хорошо, то что-то тут не так». Если описанные приемы программирования столь хороши, почему же они не получили массового распространения? Видимо, на практике не все так складно, как на бумаге.
Пожалуй, основной камень преткновения — «верность традициям». В сложившейся культуре программирования признаком хорошего тона считается использование везде, где только возможно, стандартных функций самого языка, а не специфических возможностей операционной системы, «привязывающих» программу к одной платформе. Вряд ли этот подход бесспорен, но многие разработчики ему следуют. Но что лучше — мобильный, но нестабильно работающий и небезопасный код или плохо переносимое (в худшем случае вообще не переносимое), зато устойчивое и безопасное приложение? Если отказ от использования стандартных библиотек позволит уменьшить количество ошибок в приложении и многократно повысить его безопасность, стоит ли этим пренебрегать? Удивительно, но существует и такое мнение, что непереносимость — более тяжкий грех, чем ошибки, от которых, как водится, никто не застрахован. Аргументы: дескать, ошибки — явление временное и теоретически устранимое, а непереносимость — это навсегда. Однако, использование в своей программе функций, специфичных для какой-то одной операционной системы, не является непреодолимым препятствием для ее переноса на платформы, где этих функций нет. Достаточно лишь реализовать эти функции самостоятельно.
Другая причина нераспространенности описанных приемов программирования — непопулярность обработки структурных исключений вообще. Эта технология так и не получила массового распространения — а жаль. Ведь при возникновении нештатной ситуации любое приложение может если не исправить положение, то, по крайней мере, записать не сохраненные данные на диск и затем корректно завершить свою работу. Напротив, если возникшее исключение не обрабатывается приложением, операционная система аварийно завершает его работу, а пользователь теряет все несохраненные данные.
Нет никаких объективных причин, препятствующих активному использованию структурной обработки исключений — кроме желания держаться за старые традиции, игнорируя все новое. Обработка структурных исключений — очень полезный механизм, области применения которого ограничены разве что фантазией разработчика.
Как с ними борются?
Было бы по меньшей мере удивительно, если бы с ошибками переполнения никто не пытался бы бороться. Такие попытки предпринимались неоднократно, но результат во всех случаях оставлял желать лучшего. Очевидное «лобовое» решение проблемы состоит в синтаксической проверке выхода за границы массива при каждом обращении к нему. Такие проверки реализованы в некоторых компиляторах Си, например, в Compaq C для Tru64 Unix и Alpha Linux. Они не предотвращают возможности переполнения вообще и обеспечивают лишь контроль непосредственных ссылок на элементы массивов, но бессильны предсказать значение указателей.
Проверка корректности указателей вообще не может быть реализована синтаксически, а осуществима только на машинном уровне. Bounds Checker — специальное дополнение для компилятора gcc — именно так и поступает, гарантированно исключая всякую возможность переполнения. Платой за надежность становится значительное, измеряемое десятками раз падение производительности программы. В большинстве случаев это не приемлемо, поэтому такой подход не стал популярен и практически никем не применяется. Bounds Checker хорошо подходит для облегчения отладки приложений, но вовсе не факт, что все допущенные ошибки проявят себя еще на стадии отладки и будут замечены тестировщиками. В рамках проекта Synthetix удалось найти несколько простых и надежных решений, не спасающих от ошибок переполнения, но затрудняющих их использование злоумышленниками для несанкционированного вторжения в систему. StackGuard, еще одно расширение к компилятору gcc, дополняет пролог и эпилог каждой функции особым кодом, контролирующим целостность адреса возврата.
Алгоритм в общих чертах таков: в стек вместе с адресом возврата заносится так называемое Canary Word, расположенный до адреса возврата. Искажение адреса обычно сопровождается и искажением Canary Word, что легко проконтролировать. Соль в том, что Canary Word содержит символы «», CR, LF, EOF, которые могут быть обычным путем введены с клавиатуры. А для усиления защиты добавляется случайная привязка, генерируемая при каждом запуске программы. Компилятор MS Visual C++ также способен контролировать сбалансированность стека на выходе из функции: сразу после входа в функцию он копирует содержимое регистра-указателя вершины стека в один из регистров общего назначения, а затем сверяет их перед выходом из функции. Недостаток: впустую расходуется один из семи регистров и совсем не проверяется целостность стека, а лишь его сбалансированность.
Bounds Checker для Windows 9x/NT, выпущенный компанией NuMega, неплохо отлавливает ошибки переполнения, но, поскольку он выполнен не в виде расширения к какому-нибудь компилятору, а представляет собой отдельное приложение, к тому же требующее для своей работы исходных текстов «подопытной» программы, может использоваться лишь для отладки.
Итак, готовых «волшебных» решений проблемы переполнения не существует и сомнительно, чтобы они появились в обозримом будущем. Да и так ли они необходимы при наличии поддержки структурных исключений со стороны операционной системы и современных компиляторов?
Поиск уязвимых программ
Приемы, предложенные в разделе «Предотвращение ошибок переполнения», хорошо использовать при создании новых программ, а внедрять их в существующие и более или менее устойчиво работающие продукты бессмысленно. Но даже проверенное временем приложение не застраховано от наличия ошибок переполнения, которые годами могут спать, пока не будут кем-то обнаружены.
Самый простой и наиболее распространенный метод поиска уязвимостей заключается в методичном переборе всех возможных длин входных данных. Как правило, такая операция осуществляется не вручную, а специальными автоматизированными средствами. Но таким способом обнаруживаются далеко не все ошибки переполнения. Наглядной демонстрацией этого утверждения служит следующая программа:
int file(char *buff)
{ char *p; int a=0; char
proto[10];
p=strchr(&buff[0],?:?);
if (p) {
for (;a!=(p-&buff[0]);a++)
proto[a]=buff[a];
proto[a]=0;
if (strcmp(&proto[0],»file»))
return 0; else
WinExec(p+3,SW_SHOW);
}
else WinExec(&buff[0],SW_SHOW);
return 1;
}
main(int argc,char **argv)
{if (argc>1) file(&argv[1][0]);}
Программа запускает файл, имя которого указано в командной строке. Попытка вызвать переполнение вводом цепочек различной длины, скорее всего, ни к чему не приведет. Но даже беглый анализ исходного кода позволит обнаружить ошибку, допущенную разработчиком. Если в имени файла присутствует символ «:», программа полагает, что имя записано в формате «протокол://путь к файлу/имя файла» и пытается выяснить, какой именно протокол указан. При этом она копирует название протокола в буфер фиксированного размера, полагая, что при нормальном ходе вещей его хватит для вмещения имени любого протокола. Но если ввести цепочку наподобие «ZZZZZZZZZZZZZZZZZZZZZZ:», произойдет переполнение буфера со всеми вытекающими последствиями.
Приведенный пример — один из самых простых. На практике нередко встречаются и более коварные ошибки, проявляющиеся лишь при стечении множества маловероятных самих по себе обстоятельств. Обнаружить подобные уязвимости только лишь перебором входных данных невозможно (тем не менее, даже такой поиск позволяет выявить огромное число ошибок в существующих приложениях). Значительно лучший результат дает анализ исходных текстов программы. Чаще всего ошибки переполнения возникают вследствие путаницы между длинами и индексами массивов, выполнения операций сравнения до модификации переменной, небрежного обращения с условиями выхода из цикла, злоупотребления операторами «++» и «—», молчаливого ожидания символа завершения и т.д. Например, конструкция «buff[strlen(str)-1]=0», удаляющая заключительный символ возврата каретки, будет «спотыкаться» на цепочках нулевой длины, затирая при этом байт, предшествующий началу буфера.
Вообще же, поиск ошибок — дело неблагодарное и чрезвычайно осложненное инерцией мышления. Программист подсознательно исключает из проверки те значения, которые противоречат «логике» и «здравому смыслу», но тем не менее могут встречаться на практике. Поэтому легче решать эту задачу с конца: сначала определить, какие значения каждой переменной приводят к ненормальной работе кода (т.е. попытаться посмотреть на программу глазами взломщика), а уж потом выяснить, выполняется ли соответствующая проверка или нет.
Особняком стоят проблемы многопоточных приложений и ошибки их синхронизации. Однопоточное приложение выгодно отличается воспроизводимостью аварийных ситуаций: установив последовательность операций, приводящих к проявлению ошибки, их можно повторить в любое время требуемое число раз. Это значительно упрощает поиск и устранение источника их возникновения. Напротив, неправильная синхронизация потоков, как и полное ее отсутствие, порождает трудноуловимые «плавающие» ошибки, проявляющиеся время от времени с некоей (возможно, пренебрежительно малой) вероятностью.
Рассмотрим пример: пусть один поток модифицирует цепочку символов, и в тот момент, когда на место завершающего ее нуля помещен новый символ, но сам завершающий нуль еще не добавлен, второй поток пытается скопировать цепочку в свой буфер. Поскольку завершающего нуля нет, происходит выход за границы массива. Поскольку, потоки в действительности выполняются не одновременно, а вызываются поочередно, получая в свое распоряжение некоторое (как правило, очень большое) количество «тиков» процессора, вероятность прерывания потока в данном конкретном месте очень мала и даже самое тщательное, и широкомасштабное тестирование не всегда способно выловить такие ошибки. Вследствие трудностей воспроизведения аварийной ситуации разработчики в подавляющем большинстве случаев не смогут быстро обнаружить и устранить допущенную ошибку, поэтому пользователям придется довольно долго работать с приложением, ничем не защищенным от атак.
Печально, что, получив в свое распоряжение возможность делить процессы на потоки, многие программисты чересчур злоупотребляют этим, применяя потоки даже там, где легко было бы обойтись и без них. Стоит ли после этого удивляться крайней нестабильности многих распространенных продуктов? Не призывая разработчиков напрочь отказываться от потоков, хотелось бы заметить, что гораздо лучше распараллеливать решение задач на уровне процессов.
К сожалению, заменить потоки уже существующего приложения на процессы достаточно сложно и трудоемко. Однако порой это все же гораздо проще, чем искать источник ошибок многопоточного приложения.
Заключение
Задумываться о борьбе с ошибками переполнения следует еще до начала разработки программы, а не лихорадочно вспоминать о них на стадии завершения проекта. Если это и не поможет гарантированно их предотвратить, то по крайней мере уменьшит вероятность возникновения. Напротив, возлагать решение всех проблем на участников бета-тестирования и надеяться, что надежно работающий продукт удастся создать с одной лишь их помощью, слишком наивно. Тем не менее, именно такую тактику выбрали ведущие производители, — стремясь захватить рынок, они готовы распространять сырой программный продукт, который «доводится до ума» пользователями, сообщающими разработчику об обнаруженных ими ошибках, а взамен получающих либо «заплатку», либо обещание устранить ошибку в последующих версиях.
Как показывает практика, данная стратегия работает безупречно и даже обращает ошибку в пользу, а не в убыток — веской мотивацией пользователя к приобретению новой версии зачастую становятся отнюдь не ее новые возможности, а заверения, что все ошибки теперь исправлены. На самом деле исправляется лишь незначительная часть ошибок и добавляется множество новых.
Крис Касперски (kpnc@aport.ru) — независимый автор
Среди многочисленных проблем программного характера, возникающих при работе с компьютером, пользователям может встречаться ошибка, сообщающая об обнаружении переполнения стекового буфера в конкретном приложении и возможности получения злоумышленником управления данными софта. Этому багу уже десятки лет, но и сегодня разрабатываемые программы не могут похвастать абсолютной надёжностью. Переполнение стековой памяти может возникать у любого неидеально продуманного приложения, что влечёт за собой аварийное закрытие или зависание софта, а также позволяет злоумышленнику внедрить вредоносный код, выполняемый от имени уязвимой программы. Если при этом приложение выполняется с наивысшими привилегиями, это открывает путь взломщику к любым манипуляциям в системе.

Бывает, что переполнение буфера при программировании продукта является средством, служащим определённым целям, например, намеренно применяется системным софтом для обхода отдельных ограничений. Рассмотрим подробнее, что это за явление, почему возникает и как избавиться от системной ошибки.
Причины возникновения ошибки переполнения стекового буфера
Для размещения данных программами используются блоки памяти (буферы), обычно фиксированной длины, то есть вмещающие ограниченный объём информации. Ошибка переполнения стекового буфера возникает, когда приложение пишет больше данных, чем выделено под стековый буфер, провоцируя перезаписывание, и не исключено, что будут перезаписаны важные избыточные данные в стеке, расположенные следом за массивом или перед ним.

Стек (абстрактный тип данных) являет собой список элементов, располагающихся стопкой, где информация упорядочена таким образом, что добавление элемента делает его головным, а удаление убирает первый элемент, тогда как головным станет следующий за ним. Принцип работы стека часто сравнивается со стопкой тарелок – выдернуть из середины тарелку нельзя, снимаются они поочерёдно, начиная с верхней, то есть порядок взаимодействия осуществляется по принципу LIFO (Last In, First Out – последним пришёл, первым ушёл).
Такое явление как переполнение буфера, когда программа захватывает больше данных, чем выделенный под них массив, в лучшем случае при ошибочном переполнении приводит к отказу софта или некорректной работе. В худшем, это будет означать, что уязвимость может быть применена в целях вредительства. Переполнение в стековом кадре используется злоумышленниками для изменения адреса возврата выполняемой функции, открывая возможности управления данными, независимо от того, буфер расположен в стеке, который растёт вниз, и адрес возврата идёт после буфера, или же стек растёт вниз, и адрес возврата находится перед буфером. Реализовать такое поведение программы несложно с применением вредоносного кода. С блоками памяти определённого размера компьютер работает в любых приложениях или процессах.
Так, в своих целях применять переполнение стекового буфера могут сетевые черви или иной вредоносный софт. Особенно опасными являются эксплойты, использующие уязвимость, которые предназначаются для получения привилегий путём передачи программе намеренно созданных входных данных, повреждающих стек. Эти данные переполняют буфер и меняют данные, следующие в памяти за массивом.
Скачивание сомнительного, взломанного программного обеспечения, включая пиратские сборки Виндовс, всегда таит в себе определённые риски, поскольку содержимое может хранить вредоносный код, выполняющийся при установке софта на компьютер.
Что делать, если обнаружена уязвимость в данном приложении
Первое, что нужно сделать в том случае, когда ошибка проявилась в конкретной программе, это попробовать её переустановить, загрузив инсталлятор из проверенного источника, лучше официального. Перед инсталляцией софта следует убедиться в его безопасности, просканировав антивирусом, особенно внимательно нужно устанавливать ПО при пакетной установке, когда в довесок к скачиваемому продукту идут и дополнительные элементы, часто вредоносные или просто ненужные. Переустановка софта и перезагрузка компьютера избавляют от ошибки, если она была случайной.
Рассмотрим, несколько способов, как исправить ошибку, если произошло переполнение стекового буфера Windows 10.
Использование антивирусного ПО
В тексте ошибки переполнения буфера говорится о потенциальной угрозе безопасности, и, несмотря на достаточно преклонный возраст и известность бага, он всё ещё актуален и нередко становится средством взлома систем. Причём сбою поддаются программы различных типов, а спровоцировать его можно специально задействованным вредоносным софтом.
Рекомендуется просканировать систему на вирусы, можно в безопасном режиме, если ОС не загружается, и выполнить проверку и устранение угроз посредством встроенного Защитника Windows.
Как очистить компьютер от вирусов при появлении ошибки «Стековый буфер переполнен»:
- Открываем Защитник Windows через поисковую строку меню «Пуск» или в области уведомлений на панели задач;
- Выбираем «Защита от вирусов и угроз» и переходим к параметрам сканирования;
- Отмечаем флажком «Автономное сканирование Защитника Windows» и жмём соответствующую кнопку для начала проверки.
Чистая загрузка ОС Windows
Если переустановка софта и перезагрузка не помогли, и ошибка переполнения стекового буфера не исчезла, стоит попробовать выполнить чистую загрузку системы. Возможно, причины проблемы не относятся к данному приложению, ведь кроме работающих программ в Windows запущен ряд прочих процессов, которые и могут провоцировать баг. Для выполнения загрузки ОС в чистом виде нужно войти под учётной записью администратора компьютера, некоторые функции и приложения при этом будут недоступны, поскольку в данном режиме запускаются только необходимые системе файлы.

Для чистой загрузки Windows выполняем следующие действия:
- Открываем консоль «Выполнить» (Win+R), вводим в поле команду msconfig, жмём «Ок» или клавишу Enter.
- В окне «Конфигурация системы» на вкладке «Общие» снимаем отметку с пункта «Загружать элементы автозагрузки». Затем на вкладке «Службы» отмечаем пункт «Не отображать службы Майкрософт» и жмём кнопку «Отключить все».
- Идём на вкладку «Автозагрузка» и жмём ссылку «Открыть диспетчер задач» (для Windows 10), в открывшемся окне Диспетчера задач поочерёдно отключаем каждую программу в списке.
- Возвращаемся к окну конфигурации и жмём «Ок», после чего перезагружаемся и проверяем, исчезла ли ошибка.
Для того чтобы выявить программу, ставшую причиной проблемы, нужно включать софт по одному в автозагрузке и службах, после чего выполнять перезагрузку.
Специализированный софт
В сети есть немало лечащих утилит (Dr.Web CureIt, Kaspersky и др.), способных избавить компьютер от вирусов. Портативные программы не будут конфликтовать с уже установленным антивирусом и эффективно выполнят задачу сканирования и удаления вредоносного ПО. Есть также антивирусный софт, способный решать проблему на низком уровне, если вирусы не дают системе запуститься. Используя утилиты с обновлённой вирусной базой, можно исправить, в том числе ошибку переполнения стекового буфера.
Восстановление Windows
Ещё одна мера, позволяющая избавится от системной ошибки, предполагает выполнение восстановления системы. Для использования функции потребуется наличие заранее созданного накопителя восстановления Windows, в качестве которого можно использовать диск или флешку. Выполняем следующие действия:
- отключаем от компьютера лишние устройства, не требуемые для работы;
- вставляем загрузочный накопитель и загружаемся с него, предварительно выставив приоритет загрузки в BIOS;
- выбираем «Восстановление системы» – «Диагностика» – «Дополнительные параметры» – «Восстановление при загрузке», далее выбираем ОС, которую требуется восстановить, и ждём окончания процесса, перезагружаемся.
Крайней мерой, когда более простые и гуманные способы решения не помогли исправить ошибку, является переустановка Windows.