
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
В 21 веке не редкостью стало использование биометрических данных вместо обычных паролей, подписей и СМС. Это просто, удобно и практично. Но настолько ли надежны биометрические данные? Для начала стоит разобраться, что же такое биометрия и биометрическая идентификация.
В широком смысле биометрия – это наука о применении математических методов в биологии. Биометрия как наука сложилась чем-то средним между биологией и математикой. Ее развитие связано с превращением биологии как науки описательной в науку точную, основанную на измерениях, на применении количественных оценок. Основными методами биометрии, первоначально заимствованными из математики, были математическая статистика и теория вероятности.
Биометрическая идентификация – использование уникальных признаков человека для его идентификации. Примерами биометрических признаков могут выступать: отпечатки пальцев, лицо, радужная оболочка глаза, геометрия руки, узор вен в ладони, волос и многое другое.
Общие свойства биометрической идентификации:
Плюсы:
идентификатор невозможно забыть, потерять и так далее
затруднена передача идентификатора другому лицу
Минусы:
не 100% результат, ошибки в работе
высокая цена
низкая вандалостойкость, сложнее защитить
низкая скорость работы, процесса считывания (не во всех случаях)
Вероятностный характер работы биометрии:
невозможность достижения 100% достоверности результата
вероятность возникновения ошибки зависит от конкретной системы
Биометрические идентификаторы обеспечивают очень высокие показатели (вероятность несанкционированного доступа – 0,1…0,0001 %, вероятность ложного задержания – доли процентов, время идентификации – единицы секунд), но имеют более высокую стоимость по сравнению со средствами атрибутной идентификации.
Любая система не идеальна и имеет свойство ошибаться. Существует множество разных ситуаций, при которых, система даёт сбои. В качестве примера, рассмотри одну из самых простых ситуаций – верификация. Верификация работает по такому принципу: происходит сравнивание полученного биометрического признака (например, фотография) с уже имеющимся в базе данных. В данном случае она может ошибаться двумя разными способами:
Может сказать: «нет, это не он», но это будет правильный человек
Может сказать: «да, это он», но это будет совершенно другой человек
Ошибки первого и второго рода
Существует 4 разных ситуации реагирования системы на полученные данные:
Первые 2 происходят при нормальном положении дел.
Системе предъявлено изображение правильного человека, и она ответила: «да», это он;
Системе предъявлено изображение другого человека, и она ответила: «нет», это не он;
Системе предъявлено изображение другого человека, и она ответила: «да», это он. Эта ситуация называется ложный допуск, если говорить про контроль доступа. Также её называют ошибка первого рода, а вероятность возникновения такой ситуации обычно именуют FalseAcceptRate (FAR) и измеряют в процентах. Если написано в характеристиках FAR = 1%, это значит, что 1 раз из 100 такая ошибка возникнет;
Системе предъявлено изображение правильного человека, и она ответила: «нет», это не он. Эта ситуация называется ложный отказ. Также её называют ошибка второго рода, а вероятность ситуации обычно именуют FalseRejectRat (FRR) и измеряют в процентах.
Например, при FRR 1% FAR 0,1%. Читается данная запись так: При данном наборе параметров системы с вероятность 1 из 100 будет возникать ситуация ложного отказа, и с вероятностью 1 из 1000 будет возникать ситуация предоставления ложного доступа человеку.
FRR и FAR тесно связаны друг с другом, именно поэтому их пишут вместе.
Степень сходства
Степень сходства — безразмерный показатель сходства сравниваемых объектов. Существует несколько крайних положений, которые она может принимать: 0% — вообще не похож и 100% — очень похож. Но возникает вопрос, что же делать со средними значениями? Тут, в том или ином виде можно задать порог сходства, который определенным способом можно двигать, меняя настройки считывателя. Двигая его влево (к 0%) мы можем добиться того, что система будет менее склонна отказывать доступ, т.е. допускать ситуаций ошибок второго рода. Двигая его вправо (к 100%) мы можем добиться уменьшения количества ошибок первого рода.
У этого параметра нет какого-то идеально правильного единственного положения. Надо понимать, что существуют разные задачи и у каждой свои требования.
Соотношение ошибок FAR и FRR
Их соотношение можно представить в виде гиперболы. Каждая точка этой кривой соответствует определенному положению вещей. Каждая точка ее горизонтальной координаты означает ошибку второго рода (FRR), а вертикальной координаты – ошибку первого рода (FAR).
Чтобы добиться маленькой ошибки второго рода, приходиться платить большой ошибкой первого рода, и наоборот. Существует разные требования и применения соотношения ошибок FAR и FRR.
Например: Для систем с высоким требованием безопасности категорически нельзя дать ложный допуск. Тем самым, приходится платить большим процентом ложных отказов. Проще говоря: мы увеличиваем строгость системы. Она начинает часто отказывать, но тем самым не пропустит чужого.
Совершенно другое применение: для криминальных расследований. Мы должны понять, кто из представленных людей разыскивается, выловить его из толпы. Нам категорически не хочется его случайно пропустить. Для этого, нам нужно сделать низкую вероятность ошибки второго рода, т.е. ложного отказа. Тем самым, приходится платить большой ошибкой первого рода, т.е. система будет отфильтровывать людей, которые ей показались похожими. Для этого применения — это нормально, т.к. потом этих людей уже анализируют вручную. Системе нужно лишь сократить количество рассматриваемых людей.
Идентификация
Идентификация – мы не знаем наперед кто перед нами. Предъявлен какой-то биометрический признак; нужно понять кто из нескольких представленных вариантов, нужный нам человек. При этом от системы ожидается один из ответов:
Кому именно из N числа принадлежит предъявленный признак
Таких признаков нет в базе данных
В идентификации существенную роль играет ошибка первого рода. При сравнении с одним человеком вероятность 1 из 1000 нас устраивает, но, когда людей в базе данных много, большая вероятность, что эта ошибка может возникнуть для каждого из них.
Пример расчета: FRR = 2% FRR = 2%
N = 1 N = 5000
FAR = 0,0001% FAR = 0,5%
Подводя итоги можно сказать:
Для верификации:
нужен низкий FRR
FAR практически не имеет значение
Для идентификации:
нужен низкий FAR
высокий FRR нежелателен
В целом, надо признать, что для идентификации требования намного выше, чем для верификации.
Вывод
Нужно хорошо понимать ограничения и особенности систем биометрической идентификации. Такие системы не являются универсальными решениями, но требуется понимать разницу верификации и идентификации, уметь считать ошибки FAR и FRR. Возможно, в будущем данная технология претерпит значительные изменения и найдет способ снизить процентное соотношение ошибок до минимума.
УДК 004.056.52 ББК 30в6
Савинов А.Н., Иванов В.И.
АНАЛИЗ РЕШЕНИЯ ПРОБЛЕМ ВОЗНИКНОВЕНИЯ ОШИБОК ПЕРВОГО И ВТОРОГО РОДА В СИСТЕМАХ РАСПОЗНАВАНИЯ
КЛАВИАТУРНОГО ПОЧЕРКА
Savinov A.N., Ivanov V.I.
ANALYSIS OF THE SOLUTION PROBLEMS THE ORIGIN OF TYPE I ERRORS AND TYPE II ERRORS IN SYSTEM OF RECOGNITION
OF KEYSTROKE DINAMICS
Ключевые слова: клавиатурный почерк, ошибка I рода, ошибка II рода, частота ложных отказов, частота ложных приемов, система распознавания .
Keywords: keystroke dinamics, type I errors and type II errors, false acceptance rate, false rejection rate, recognition system.
Аннотация
В работе рассматриваются причины возникновения ошибок первого и второго рода в биометрических системах. Рассматриваются основные способы снижения вероятности возникновения данных ошибок.
Abstract
The article deals with cause of the errors of the first and second kind in biometric systems. The main ways to reduce the likelihood of this errors are considered.
В настоящее время всеобщей информатизации и автоматизации большое значение приобретают задачи защиты информации. Постоянно разрабатываются новые методы защиты, которые позволяют увеличивать надежность и стойкость систем, предназначенных для решения задач контроля и управления доступа к ключевым системам.
Среди задач защиты информации выделяются вопросы аутентификации (установление подлинности) пользователя ключевой системы. И одними из наиболее перспективных и активно развивающихся сейчас направлений являются методы биометрической аутентификации.
При рассмотрении любых систем принятия решений и (или) распознавания важнейшими показателями качества работы таких систем являются вероятности ошибок системы. Если система предназначена для разделения всех исследуемых объектов на два класса (а именно такое разделение осуществляют системы аутентификации пользователей
— они должны разделить на два класса «свой-чужой» всех, кто пытается авторизоваться), то для нее актуальны два вида ошибок. Это так называемые ошибки первого рода, когда система принимает «своего» за «чужого». И ошибки второго рода, когда, наоборот, «чужого» система принимает за «своего».
Ошибки первого рода (англ. type I errors, a errors, false positives) и ошибки второго рода (англ. type II errors, в errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Пусть дана выборка X={Xi,…,Xn} из неизвестного совместного распределения P , и поставлена бинарная задача проверки статистических гипотез: Но — нулевая гипотеза, а Н1 — альтернативная гипотеза. Допустим, что выборка соответствует клавиатурному
почерку оператора, проходящего процесс аутентификации. Например, она представлена временем удержания оператором клавиш клавиатуры. Тогда нулевая гипотеза Ис будет соответствовать предположению, что аутентифицируемый пользователь действительно является зарегистрированным пользователем системы (именно тем, кем он представился системе) и его можно авторизовать. Альтернативная гипотеза Щ будет иметь противоположное значение: аутентифицируемый пользователь не является законным пользователем системы и должен получить отказ в авторизации.
Предположим, что задан статистический критерий (1) сопоставляющий каждой реализации выборки X = x одну из имеющихся гипотез.
/ : Rn — {БсД}, (1)
Для примера с клавиатурным почерком в качестве статистического критерия возьмем меру Евклида (2) и стандартная непохожесть (порог чувствительности) MaxN подсистемы принятия решений, определяющая допустимое отклонение клавиатурного почерка от эталона, для принятия решения о том, что почерк тестируемого пользователя совпадает с эталонным, хранимым в базе.
s:=s+sqr((Times[i,0]-eTimes[i,0])/eTimes[i,0]), (2)
Здесь s — значение меры Евклида [6] . Times[i,0] — время удержания конкретной
клавиши из выборки, соответствующей клавиатурному почерку тестируемого
пользователя. eTimes[i,0] — время удержания конкретной клавиши, хранимое в эталонном образце клавиатурного почерка тестируемого пользователя. Согласно применению данного критерия возможны 2 случая:
— если s < MaxN, то отклонение характеристик почерка текущего оператора ключевой системы соответствует разрешенному диапазону. В этом случае принимается решение о том, что пользователь является законным и происходит процесс авторизации.
— если s > MaxN, то отклонение характеристик почерка текущего оператора ключевой системы не соответствует разрешенному диапазону. Значит, принимается решение о том, что пользователь не является законным, и он получает отказ в авторизации.
Возможны следующие четыре ситуации (таблица 1 ):
1. Распределение P выборки Х соответствует гипотезе Ис, и она точно определена статистическим критерием, то есть /^) = Значит, клавиатурный почерк пользователя совпадает с его эталонным почерком по заданному критерию. Пользователь является законным и успешно проходит авторизацию.
2. Распределение P выборки Х соответствует гипотезе Ис, но она неверно отвергнута статистическим критерием, то есть /^) = Щ. Значит, клавиатурный почерк пользователя не совпадает с его эталонным почерком по заданному критерию. Пользователь является законным, но система ошибочно принимает решение об отказе в авторизации.
3. Распределение PX выборки Х соответствует гипотезе Щ, и она точно определена статистическим критерием, то есть /^) = Щ. Значит, клавиатурный почерк пользователя не совпадает с его эталонным почерком по заданному критерию. Пользователь не является зарегистрированным пользователем системы и справедливо получает отказ в авторизации.
4. Распределение P выборки Х соответствует гипотезе Щ, но она неверно отвергнута статистическим критерием, то есть /^) = Значит, клавиатурный почерк пользователя не совпадает с его эталонным почерком по заданному критерию. Пользователь не является законным, но ошибочно получает разрешение на авторизацию.
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно.
Таблица 1 — Возможные варианты исходов при применении гипотезы
Верная гипотеза
И<> (предположение о том, что аутентифицирующийся оператор является зарегистрированным пользователем системы) (предположение о том, что аутентифицирующийся оператор не является зарегистрированным пользователем системы)
Результат применения критерия Ц, (оператор проходит процесс авторизации успешно) Ио верно принята (оператор является зарегистрированным пользователем системы и правомерно получает разрешение на авторизацию) Ис неверно принята (Ошибка второго рода) (оператор не является зарегистрированным пользователем системы, но ошибочно получает разрешение на авторизацию)
(оператор получает отказ в авторизации) Ис неверно отвергнута (Ошибка первого рода) (оператор является зарегистрированным пользователем системы, но ошибочно получает отказ в авторизации) Ио верно отвергнута (оператор не является зарегистрированным пользователем системы справедливо получает отказ в авторизации)
Пусть количество объектов в тестовом наборе равно N, из них Np — кол-во «положительных» (с меткой ‘1’) объектов, а Nn — кол-во объектов «отрицательных» (с меткой ‘-1’). Естественно, N=Np+Nn. Пусть количество ложных пропусков FN, а ложных обнаружений FP, тогда несложно подсчитать количество верных пропусков (3) и верных обнаружений (true negatives, true positives) (4).
TP = Np — FN, (3)
TN = Nn — FP, (4)
Используя эти величины можно рассчитать нормированные уровни ошибок первого и второго рода (5), а также долю верно распознаваемых пропусков и обнаружений (6).
nFN=FN / Np * 100%; nFP = FP / Nn * 100%, (5)
nTN=TN / Nn * 100%; nTP = TP / Np * 100%, (6)
Такие величины более наглядно в виде частоты (в процентах) встречаемости ошибок и верных обнаружений отражают качество распознавания, поскольку не зависят (в явном виде) от количества объектов в тестовом наборе.
В биометрических системах выделяют следующие виды ошибок:
— FAR (False Acceptance Rate) — частота ложных приемов. Например, если из 100 проб входа в систему злоумышленником может произойти одна случайная идентификация его с законным пользователем, то FAR=0,01, что, в общем-то, многовато для статических (физиологических) систем и нормально для динамических (поведенческих);
— FRR (False Rejection Rate) — частота ложных отказов. Например, если на 100 аутентификаций, выполненных законным пользователем, произошло два неправомерных отказа, то FRR=0,02;
— EER, или ERR (Equal Error Rate, или ERror Rate) — частота ошибок. Это сложное понятие, которое формируется в связи с тем, что биометрическую систему обычно можно настраивать, варьировать ее параметры. Так вот FAR и FRR связаны между собой, и когда
один показатель уменьшается, второй обязательно увеличивается. Если при каких-то настройках FAR=FRR, то это и есть значение ERR.
Если администратор системы занижает порог отказа в допуске, то система будет более «снисходительно» оценивать совпадение хранимого шаблона с данными пользователя, и, естественно, увеличится вероятность, что она по ошибке разрешит вход постороннему. При установлении слишком высокого порога увеличивается вероятность того, что система будет отвергать вполне легитимных пользователей. С одной стороны, высокое значение FRR (вероятность ошибочного задержания «своего») может привести к дискредитации системы и снижению эффективности ее функционирования, так как при частых ложных срабатываниях персонал охраны практически перестает обращать внимание на задержания или отказы в доступе. С другой стороны, высокое значение FAR (вероятность ошибочного пропуска «чужого») увеличивает вероятность несанкционированного доступа. Учитывая зависимость FAR, FRR от установленных порогов обнаружения А (рисунок 1), следует отметить, что задача выбора порогов для администратора системы безопасности объекта чрезвычайно актуальна.
ЬКК КАК 1 1 / 1 ЛК
/ /
/
J
N. / V
/ НИК V
А ЬК* ШК
Рисунок 1 — График зависимостей FRR и FAR от порога обнаружения
Предложена разработка биометрической системы контроля доступа с высокой степенью адаптивности. Предложено обязательное наличие возможности изменения порогов обнаружения. Принцип контролируемости обеспечит в первую очередь наличие встроенных средств расчета FAR и FRR. При этом для расчета FAR целесообразно использовать предложенный аппарат сравнения методом «чужой» к «чужому», хранящихся в базе данных «эталонов» при вариации порога обнаружения. Предположим, что в базе хранятся n эталонов соответственно n операторов ключевой системы. Первый эталон клавиатурного почерка пользователя, хранящийся в базе данных, сравнивается со всеми остальными n-1 эталонами клавиатурных почерков пользователей из этой же базы. Соответственно для первого эталона происходит n-1 сравнений. Второй эталон уже сравнивался с первым эталоном. Значит, сравнение начнется с третьего эталона и всего для него произойдет n-2 сравнений. Указанная процедура осуществляется до предпоследнего эталона базы. Это значит, что число возможных сравнений VFAR «чужой» к «чужому» в базе из п эталонов будет (9):
(9)
Для оценки FRR целесообразно использовать отношение количества отказов в доступе по критерию «биометрический контроль не пройден» к общему количеству попыток предъявления биометрических параметров (в упрощенном случае — к общему числу проходов). Таким образом, будет получена самообучающаяся система, которая устанавливает порог чувствительности в зависимости от вариаций хранящихся в базе почерков. Также система после анализа почерков сотрудников-операторов ключевой
системы предложит администратору рекомендации по допустимым значениям порога с указанием вероятностей FRR и FAR при отклонении значения порога от нормальной величины. Естественно при первом запуске системы данные для определения FRR указанным методом или сравнением «свой» к «своему» (несколько образцов клавиатурного почерка одного и того же пользователя) в системе по понятным причинам отсутствуют. Таким образом, предлагается считать значение FAR обязательным для реализации системным параметром. А параметр FRR будем считать допустимым, если он соизмерим с вероятностью ошибки ложного срабатывания для систем контроля и управления доступом (СКУД), не имеющей биометрического контроля.
Фактически FRR определяется интенсивностью процессов авторизации операторов ключевой системы: если их мало, то FRR может быть относительно большим, а если много, то должен быть малым. Соответственно, чем важнее статус охраняемой системы, тем меньше допущенных лиц (меньшее количество авторизаций) и, следовательно, может быть задано более высокое значение FRR при уменьшении FAR.
Предложено проводить оценку FRR дополнительно для каждого пользователя с целью выявления людей с явно выраженным влиянием субъективного фактора. В системе могут применяться наряду с общесистемными порогами обнаружения индивидуальные. Данные пороги могут действовать выборочно для определенных людей и задаваться администратором, а могут варьироваться (в требуемом диапазоне) автоматически для всего персонала в зависимости от индивидуальной FRR. Вариация порогов оказывается также полезной на этапе адаптации персонала к биометрической системе. При начальном вводе биометрических данных необходимо уделять внимание их качеству (в том числе и тому факту, что не все люди имеют хорошо выраженный клавиатурный почерк), а, следовательно, в системе должны быть предусмотрены программные средства оценки качества эталона клавиатурного почерка и качества самого клавиатурного почерка. Следует отметить принципиальную важность автоматической подстройки хранящихся в базе данных эталонов с целью компенсации изменений биометрических параметров со временем ведь клавиатурный почерк — изменяющаяся со временем поведенческая биометрическая характеристика человека. Соответственно, с изменением почерка увеличится количество ошибок FRR.
Таким образом, проведен анализ причин и последствий возникновения ошибок первого и второго рода в биометрических системах. Предложены способы снижения количества ошибок FAR и FRR в системах распознавания клавиатурного почерка, основанные на характеристиках и свойствах клавиатурного почерка операторов ключевых систем. Повышение качества функционирования подсистемы принятия решений о классификации авторизирующегося пользователя увеличивает интерес администраторов и служб, обеспечивающих безопасность ключевых систем, к подобного рода продуктам.
Библиографический список
1. Иванов А.И. Нейросетевые алгоритмы биометрической идентификации личности. Серия «Нейрокомпьютеры и их применение». Кн. 15. — М.: Радиотехника, 2004. — С. 22-50.
2. Рыбченко Д.Е. Критерии устойчивости и индивидуальности компьютерного почерка при вводе ключевых фраз // Специальная техника средств связи. Серия «Системы, сети и технические средства конфиденциальной связи». — Пенза, ПНИЭИ, 1997, вып. № 2.
— С. 104-107.
3. Обзор технологий биометрической идентификации — 16.11.03. http://center.forever.kz/ hard/ otherf0003.htm
4. Брюхомицкий Ю.А., Казарин М.Н. Учебные биометрические системы контроля доступа по рукописному и клавиатурному почеркам. — Таганрог, ТРГУ, 2004 (http://www.library.mephi.ru/data/scientific-sessions/2006/vnk13/0-1-12.doc)
5. Владимир Вежневец. Оценка качества работы классификаторов. Компьютерная графика и мультимедиа. Выпуск № 4(1)/2006. http://cgm.computergraphics.ru/content/view/106
6. Методические указания по математическому анализу. Ч. 2. Курс лекций по математическому анализу (для студентов 2-го курса). Ч. 2. — М.: МФТИ. 2005. — 213 с.
7. http://wapedia.mobi/ru/Мощность_критерия.
Библиографическое описание:
Принципы работы и уязвимости биометрических систем аутентификации / И. П. Пересыпкин, Л. Е. Мартынова, К. Е. Назарова [и др.]. — Текст : непосредственный // Молодой ученый. — 2016. — № 30 (134). — С. 86-88. — URL: https://moluch.ru/archive/134/37699/ (дата обращения: 06.06.2023).
Как известно, в информационных системах хранится, обрабатывается, циркулирует различная информация, потеря или искажение которой может нанести существенный вред [1, c. 54]. Поэтому следует обеспечить безопасную аутентификацию В данной статье будет рассмотрена биометрическая аутентификация. Биометрические системы аутентификации находят всё большее применение на современном рынке средств безопасности.
На рисунке 1 приведены статистические данные по практическому использованию БСЗ (по данным Global Industry Analysts, Inc [2] на 2014г.)
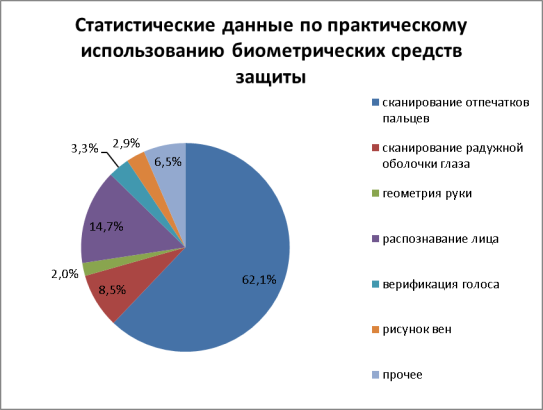
Рис. 1. Статистика по практическому использованию биометрических средств защиты
Наиболее часто применяемыми на сегодняшний день являются сканеры отпечатков пальцев и сканеры лица. Согласно исследованию аналитиков компании TrendForce (прогноз развития рынка 2015–2019), в ближайшие годы ожидается ускорение роста применения биометрических технологий, основанных на распознавании лиц и дактилоскопии в системах безопасности в следующих областях: государственный сектор, финансовая отрасль, корпоративный и потребительский рынки. По прогнозу аналитиков, объем рынка систем распознавания лиц в 2015 году составил $230 млн, к 2019-му году вырастет до $450 млн. Прогноз среднегодового роста составляет 18 %.
Все биометрические системы аутентификации работают по общему принципу [3]. При регистрации пользователя сканер извлекает образец биометрической черты, на основе которого создаётся биометрический шаблон, по средствам которого и происходит дальнейшая аутентификация пользователя. Шаблон заносится базу данных и хранится вместе с идентификатором пользователя. При аутентификации пользователя сравнивается его предоставленный образец биометрической черты, преобразуемый в биометрический шаблон, и шаблон, хранящийся в базе данных и созданный при регистрации пользователя. База данных с биометрическими шаблонами пользователей может быть украдена, модифицирована, уничтожена. Как показывает практика, наиболее распространенными являются атаки, реализуемые с помощью загрузки враждебного содержания. [4, c. 152] Следует уделить особое внимание её безопасности.
Для повышения надёжности могут применяться комбинированные системы использующие двухфакторную аутентификацию, например биометрический сканер и символьный пароль или ПИН-код.
Современные биометрические системы аутентификации уязвимы для двух видов ошибок [5]. Ошибка первого рода возникает в том случае, когда система не распознает легитимного пользователя. При этом происходит отказ в обслуживании. Ошибка второго рода — когда злоумышленник неверно идентифицируется как легитимный пользователь. Такие ошибки могут возникнуть по ряду причин. Их можно разделить на естественные ограничения и атаки злоумышленников.
В отличие от парольных систем аутентификации, требующих точного соответствия вводимого пароля и пароля, указанного при регистрации пользователя, биометрические системы аутентификации предоставляют доступ на основе достаточной степени сходства предоставляемого и хранимого биометрического образца. Так как биометрические образцы могут отличаться друг от друга при регистрации и аутентификации пользователя, то могут возникать ошибки первого и второго рода. Ошибка первого рода может возникнуть, когда два образца от одного пользователя имеют низкую степень сходства. Ошибка второго рода может возникнуть, если биометрические образцы разных пользователей имеют достаточно высокую степень сходства, вследствие чего система принимает постороннего пользователя как легитимного.
Биометрическая система может дать сбой в результате злоумышленных манипуляций, проводимых через инсайдеров, например системных администраторов, либо путем прямой атаки на системную инфраструктуру. Злоумышленник может обойти биометрическую систему, если вступит в сговор с инсайдерами (или принудит их), либо воспользуется их халатностью, либо выполнит мошеннические манипуляции с процедурами регистрации и обработки исключений, которые изначально были разработаны для помощи авторизованным пользователям. Внешние злоумышленники также могут вызвать сбой в биометрической системе, производя атаку непосредственно на пользовательский интерфейс, модули экстракции черт или сопоставления, либо на соединения между модулями, либо базу шаблонов.
В качестве примеров атак, направленных на системные модули и их межсоединения можно привести трояны, атаку «человек посередине», атаки воспроизведения. Поскольку большинство видов таких атак также применимы к системам аутентификации по паролю, для защиты от них применяются сходные меры, такие как криптография, отметки времени и взаимная аутентификация, позволяющие предотвратить или минимизировать эффект таких вторжений.
Для биометрических систем характерны две угрозы: атаки подделки на пользовательский интерфейс; утечка из базы шаблонов. Обе атаки оказывают серьезное негативное влияние на защищенность биометрической системы.
Атака подделки состоит в предоставлении поддельной биометрической черты, не полученной от легитимного пользователя: муляж отпечатка пальца, имитация глазного яблока, снимок или маска лица.
Фундаментальный принцип биометрической аутентификации состоит в том, что, хотя сами биометрические признаки не являются секретом (можно тайно получить фото лица человека или отпечаток его пальца с предмета или поверхности), система, тем не менее, защищена, так как признак физически привязан к живому пользователю. Успешные атаки подделки нарушают это базовое предположение, тем самым серьезно подрывая защищенность системы.
В качестве варианта проверки живого состояния дополнительно вводят верификацию физиологических характеристик пальцев или наблюдения за непроизвольными факторами, такими как моргание, таким образом можно удостовериться в том, что биометрическая особенность, зарегистрированная датчиком, действительно принадлежит живому человеку.
При утечке из базы шаблонов информация о шаблоне легитимного пользователя становится доступной злоумышленнику. При этом повышается опасность подделки, так как злоумышленнику становится проще восстановить биометрический рисунок путем простого обратного инжиниринга шаблона. В отличие от паролей и физических удостоверений личности, краденый шаблон нельзя просто заменить новым, так как биометрические признаки существуют в единственном экземпляре.
Важнейший фактор минимизации рисков безопасности и нарушения приватности, связанных с биометрическими системами — защита биометрических шаблонов, хранящихся в базе данных системы.
Основная трудность при разработке схем защиты биометрического шаблона состоит в том, чтобы достигнуть приемлемого компромисса между тремя требованиями: необратимость; различимость; отменяемость.
Имеется два общих принципа защиты биометрических шаблонов: трансформация биометрических черт и биометрические криптосистемы.
В случае трансформации биометрических черт защищенный шаблон получен за счет применения необратимой функции трансформации к оригиналу шаблона. Такая трансформация обычно основана на индивидуальных характеристиках пользователя. В процессе аутентификации система применяет ту же функцию трансформации к запросу, и сопоставление происходит уже для трансформированного образца.
Биометрические криптосистемы хранят только часть информации, полученной из биометрического шаблона, — эта часть называется защищенным эскизом (secure sketch). Хотя его самого недостаточно для восстановления оригинального шаблона, он все же содержит необходимое количество данных для восстановления шаблона при наличии другого биометрического образца, похожего на полученный при регистрации.
Таким образом, в качестве уязвимостей биометрических систем аутентификации можно выделить ошибки первого и второго рода, атаки подделки, утечки из базы данных биометрических шаблонов. Учет их при использовании биометрических систем аутентификации повысит уровень их защищенности и надёжности.
Литература:
- Багров Е. В. Мониторинг и аудит информационной безопасности на предприятии. Вестник волгоградского государственного университета. Волгоград: 2011, с.54.
- Global Industry Analysts, Inc [Электронный ресурс] URL: http://www.strategyr.com/MarketResearch/Fingerprint_Biometrics_Market_Trends.asp (дата обращения 13.12.2016)
3. Анил Джейн, Картик Нандакумар. Биометрическая аутентификация: защита систем и конфиденциальность пользователей// Открытые системы. СУБД. — 2012. -№ 10. URL: http://www.osp.ru/os/2012/10/13033122 (дата обращения 13.12.2016)
- Никишова А. В., Чурилина А. Е. Программный комплекс обнаружения атак на основе анализа данных реестра// Вестник ВолГУ. Серия 10. Инновационная деятельность. Выпуск 6. 2012 г. В.: Изд-во ВолГУ, 2012, стр. 152–155
- Мальцев Антон. Современные биометрические методы идентификации. [Электронный ресурс] URL: http://habrahabr.ru/post/126144/ Дата публикации 11.08.11. (дата обращения 15.12.2016)
Основные термины (генерируются автоматически): биометрическая система аутентификации, биометрическая система, биометрический шаблон, легитимный пользователь, атака подделки, баз данных, баз шаблонов, регистрация пользователя, система, биометрическая аутентификация.
Пожалуй нет ни одной другой технологии сегодня, вокруг которой было бы столько мифов, лжи и некомпетентности. Врут журналисты, рассказывающие о технологии, врут политики которые говорят о успешном внедрении, врут большинство продавцов технологий. Каждый месяц я вижу последствия того как люди пробуют внедрить распознавание лиц в системы которые не смогут с ним работать.

Тема этой статьи давным-давно наболела, но было всё как-то лень её писать. Много текста, который я уже раз двадцать повторял разным людям. Но, прочитав очередную пачку треша всё же решил что пора. Буду давать ссылку на эту статью.
Итак. В статье я отвечу на несколько простых вопросов:
- Можно ли распознать вас на улице? И насколько автоматически/достоверно?
- Позавчера писали, что в Московском метро задерживают преступников, а вчера писали что в Лондоне не могут. А ещё в Китае распознают всех-всех на улице. А тут говорят, что 28 конгрессменов США преступники. Или вот, поймали вора.
- Кто сейчас выпускает решения распознавания по лицам в чём разница решений, особенности технологий?
Большая часть ответов будет доказательной, с сылкой на исследования где показаны ключевые параметры алгоритмов + с математикой расчёта. Малая часть будет базироваться на опыте внедрения и эксплуатации различных биометрических систем.
Я не буду вдаваться в подробности того как сейчас реализовано распознавание лиц. На Хабре есть много хороших статей на эту тему: а, б, с (их сильно больше, конечно, это всплывающие в памяти). Но всё же некоторые моменты, которые влияют на разные решения — я буду описывать. Так что прочтение хотя бы одной из статей выше — упростит понимание этой статьи. Начнём!
NB!
Если что, статья 2018 года. Сейчас как минимум 2021. Не то, что что-то принципиально изменилось. Но, точности стали другими (советую смотреть актуальные оригиналы метрик которые я упоминаю в статье). Появилось много новых идей/подходов, которые расширяют области применения распознавания лиц.
А в целом, — советую читать мой канал (vk, telegram) про более новые методы/подходы. Статьи с Хабра свои я там тоже аноншу.
Введение, базис
Биометрия — точная наука. Тут нет места фразам «работает всегда», и «идеальная». Все очень хорошо считается. А чтобы подсчитать нужно знать всего две величины:
- Ошибки первого рода — ситуация когда человека нет в нашей базе, но мы опознаём его как человека присутствующего в базе (в биометрии FAR (false access rate))
- Ошибки второго рода — ситуации когда человек есть в базе, но мы его пропустили. (В биометрии FRR (false reject rate))
Эти ошибки могут иметь ряд особенностей и критериев применения. О них мы поговорим ниже. А пока я расскажу где их достать.
Характеристики
Первый вариант. Давным-давно ошибки производители сами публиковали. Но тут такое дело: доверять производителю нельзя. В каких условиях и как он измерял эти ошибки — никто не знает. И измерял ли вообще, или отдел маркетинга нарисовал.
Второй вариант. Появились открытые базы. Производители стали указывать ошибки по базам. Алгоритм можно заточить под известные базы, чтобы они показывали офигенное качество по ним. Но в реальности такой алгоритм может и не работать.
Третий вариант — открытые конкурсы с закрытым решением. Организатор проверяет решение. По сути kaggle. Самый известный такой конкурс — MegaFace. Первые места в этом конкурсе когда-то давали большую популярность и известность. Например компании N-Tech и Vocord во многом сделали себе имя именно на MegaFace.
Всё бы хорошо, но скажу честно. Подгонять решение можно и тут. Это куда сложнее, дольше. Но можно вычислять людей, можно вручную размечать базу, и.т.д. И главное — это не будет иметь никакого отношения к тому как система будет работать на реальных данных. Можете посмотреть кто сейчас лидер на MegaFace, а потом поискать решения этих ребят в следующем пункте.
Четвёртый вариант. На сегодняшний день самый честный. Мне не известны способы там жульничать. Хотя я их не исключаю.
Крупный и всемирно известный институт соглашается развернуть у себя независимую систему тестирования решений. От производителей поступает SDK которое подвергается закрытому тестированию, в котором производитель не принимает участия. Тестирование имеет множество параметров, которые потом официально публикуются.
Сейчас такое тестирование производит NIST — американский национальный институт стандартов и технологий. Такое тестирование самое честное и интересное.
Нужно сказать, что NIST производит огромную работу. Они выработали пяток кейсов, выпускают новые апдейты раз в пару месяцев, постоянно совершенствуются и включают новых производителей. Вот тут можно ознакомиться с последним выпуском исследования.
Казалось бы, этот вариант идеален для анализа. Но нет! Основной минус такого подхода — мы не знаем, что в базе. Посмотрите вот на этот график:

Это данные двух компаний по которым проводилось тестирование. По оси x — месяца, y — процент ошибок. Тест я взял «Wild faces» (чуть ниже описание).
Внезапное повышение точности в 10 раз у двух независимых компаний (вообще там у всех взлетело). Откуда?
В логе NIST стоит пометка «база была слишком сложной, мы её упростили». И нет примеров ни старой базы, ни новой. На мой взгляд это серьёзная ошибка. Именно на старой базу была видна разница алгоритмов вендоров. На новой у всех 4-8% пропусков. А на старой было 29-90%. Моё общение с распознаванием лиц на системах видеонаблюдения говорит, что 30% раньше — это и был реальный результат у гроссмейстерских алгоритмов. Сложно распознать по таким фото:

И конечно, по ним не светит точность 4%. Но не видя базу NIST делать таких утверждений на 100% нельзя. Но именно NIST — это главный независимый источник данных.
В статье я описываю ситуацию актуальную на июль 2018 года. При этом опираюсь на точности, по старой базе лиц для тестов связанных с задачей «Faces in the wild».
Вполне возможно что через пол года всё измениться полностью. А может будет стабильным следующие десять лет.
Итак, нам нужна вот эта таблица:
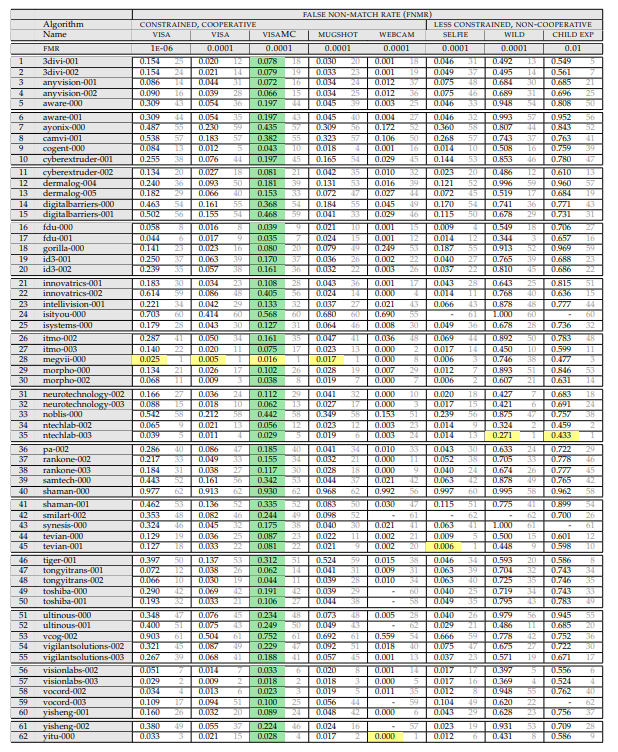
(апрель 2018, т.к. wild тут более адекватный)
Давайте разберём что в ней написано, и как оно измеряется.
Сверху идёт перечисление экспериментов. Эксперимент состоит из:
Того, на каком сете идёт замер. Сеты есть:
Того при каком уровне ошибок первого рода идёт замер (этот параметр рассматривается только для фотогафий на паспорт):
- 10^-4 — FAR (одно ложное срабатывание первого рода) на 10 тысяч сравнений с базой
- 10^-6 — FAR (одно ложное срабатывание первого рода) на миллион сравнений с базой
Результат эксперимента — величина FRR. Вероятность того что мы пропустили человека который есть в базе.
И уже тут внимательный читатель мог заметить первый интересный момент. «Что значит FAR 10^-4?». И это самый интересный момент!
Главная подстава
Что вообще такая ошибка значит на практике? Это значит, что на базу в 10 000 человек будет одно ошибочное совпадение при проверке по ней любого среднестатистического человека. То есть, если у нас есть база из 1000 преступников, а мы сравниваем с ней 10000 человек в день, то у нас будет в среднем 1000 ложных срабатываний. Разве это кому то нужно?
В реальности всё не так плохо.
Если посмотреть построить график зависимости ошибки первого рода от ошибки второго рода, то получится такая классная картинка (тут сразу для десятка разных фирм, для варианта Wild, это то что будет на станции метро, если камеру поставить где-то чтобы её не видели люди):
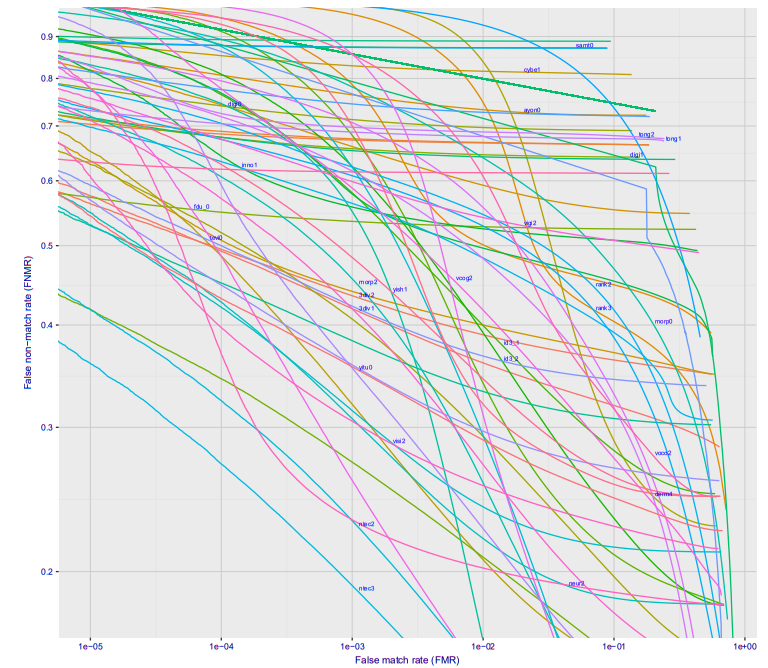
При ошибке 10^-4 27% процентов не распознанных людей. На 10^-5 примерно 40%. Скорее всего на 10^-6 потери составят примерно 50%
Итак, что это значит в реальных цифрах?
Лучше всего идти от парадигмы «сколько ошибок в день можно допустить». У нас на станции идёт поток людей, если каждые 20-30 минут система будет давать ложное срабатывание, то никто не будет её воспринимать всерьёз. Зафиксируем допустимое число ложных срабатываний на станции метро 10 человек в день (по хорошему, чтобы система не была выключена как надоедливая — нужно ещё меньше). Поток одной станции Московского метрополитена 20-120 тысяч пассажиров в сутки. Среднее — 60 тысяч.
Пусть зафиксированное значение FAR — 10^-6 (ниже ставить нельзя, мы и так при оптимистической оценке потеряем 50% преступников). Это значит что допустить 10 ложных тревог мы можем при размере базы в 160 человек.
Много это или мало? Размер базы в федеральном розыске ~ 300 000 человек. Интерпола 35 тысяч. Логично предположить, что где-то 30 тысяч москвичей находятся в розыске.
Это даст уже нереальное число ложных тревог.
Тут стоит отметить, что 160 человек может быть и достаточной базой, если система работает on-line. Если искать тех кто совершил преступление в последние сутки — это уже вполне рабочий объём. При этом, нося чёрные очки/кепки, и.т.д., замаскироваться можно. Но много ли их носит в метро?
Второй важный момент. Несложно сделать в метро систему дающее фото более высокого качества. Например поставить на рамки турникетов камеры. Тут уже будет не 50% потерь на 10^-6, а всего 2-3%. А на 10^-7 5-10%. Тут точности из графика на Visa, всё будет конечно сильно хуже на реальных камерах, но думаю на 10^-6 можно оставить сего 10% потерь:

Опять же, базу в 30 тысяч система не потянет, но всё что происходит в реальном времени детектировать позволит.
Первые вопросы
Похоже время ответить на первую часть вопросов:
Ликсутов заявил что выявили 22 находящихся в розыске человека. Правда ли это?
Тут основной вопрос — что эти люди совершили, сколько было проверено не находящихся в розыске, насколько в задержании этих 22 людей помогло распознавание лиц.
Скорее всего, если это люди которых искали планом «перехват» — это действительно задержанные. И это неплохой результат. Но мои скромные предположения позволяют сказать, что для достижения этого результата было проверено минимум 2-3 тысячи людей, а скорее около десятка тысяч.
Это очень хорошо бьётся с цифрами которые называли в Лондоне. Только там эти числа честно публикуют, так как люди протестуют. А у нас замалчивают…
Вчера на Хабре была статья на счёт ложняков по распознаванию лиц. Но это пример манипуляций в обратную сторону. У Амазона никогда не было хорошей системы распознавания лиц. Плюс вопрос того как настроить пороги. Я могу хоть 100% ложняков сделать, подкрутив настройки;)
Про Китайцев, которые распознают всех на улице — очевидный фэйк. Хотя, если они сделали грамотный трекинг, то там можно сделать какой-то более адекватный анализ. Но, если честно, я не верю что пока это достижимо. Скорее набор затычек.
А что с моей безопасностью? На улице, на митинге?
Поехали дальше. Давайте оценим другой момент. Поиск человека с хорошо известной биографией и хорошим профилем в соцсетях.
NIST проверяет распознавание лица к лицу. Берётся два лица одного/разных людей и сравнивается насколько они близки друг к другу. Если близость больше порога, тогда это один человек. Если дальше — разные. Но есть другой подход.
Если вы почитали статьи, которые я советовал в начале — то знаете, что при распознавании лица формируется хэш-код лица, отображающий его положение в N-мерном пространстве. Обычно это 256/512 мерное пространство, хотя у всех систем по разному.
Идеальная система распознавания лиц переводит одно и то же лицо в один и тот же код. Но идеальных систем нет. Одно и то же лицо обычно занимает какую-то область пространства. Ну, например, если бы код был двумерным, то это могло бы быть как-то так:
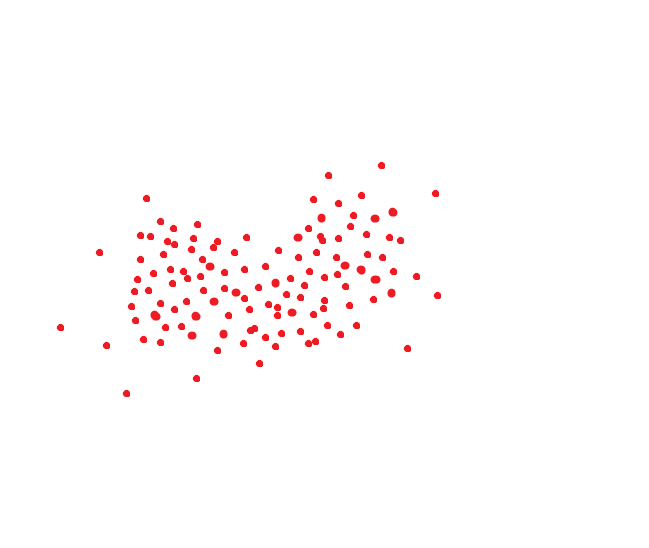
Если мы руководствуемся методом который принимается в NIST, то вот это расстояние было бы целевым порогом, чтобы мы могли распознать человека как одного и того же индивида с вероятностью под 95%:
Но ведь можно поступить по другому. Для каждого человека настроить область гиперпространства где хранятся достоверные для него величины:

Тогда пороговое расстояние при сохранении точности уменьшится в несколько раз.
Только нам нужно очень много фотографий на каждого человека.
Если у человека есть профиль в социальных сетях / база его снимков разного возраста, то точность распознавания можно повысить очень сильно. Точной оценки того как вырастает FAR|FRR я не знаю. Да и оценивать уже некорректно такие величины. У кого-то в такой базе 2 фото, у кого-то 100. Очень много обёрточной логики. Мне кажется, что максимальная оценка — один/полтора порядка. Что позволяет дострелить до ошибок 10^-7 при вероятности не распознавания 20-30%. Но это умозрительно и оптимистично.
Вообще, конечно, с менеджментом данного пространства проблем не мало (возрастные фишки, фишки редакторов изображений, фишки шумов, фишки резкости), но как я понимаю большая часть уже успешно решена у крупных фирм кому было нужно решение.
К чему это я. К тому, что использование профилей позволяет в несколько раз поднять точность алгоритмов распознавания. Но она далека от абсолютной. С профилями требуется много ручной работы. Похожих людей много. Но если начинать задавать ограничения по возрасту, местонахождению, и.т.д., то этот метод позволяет получить хорошее решение. На пример того как нашли человека по принципу «найти профиль по фото»->«использовать профиль для поиска человека» я давал ссылку в начале.
Но, на мой взгляд, это сложно масштабируемый процесс. И, опять же, людей с большим числом фоток в профиле дай бог 40-50% в нашей стране. Да и многие из них дети, по которым всё плохо работает.
Но, опять же — это оценка.
Так вот. Про вашу безопасность. Чем меньше у вас фото в профиле — тем лучше. Чем более многочисленный митинг куда вы идёте — тем лучше. Никто не будет разбирать 20 тысяч фотографий в ручную. Тем кто заботиться о своей безопасности и приватности — я бы советовал не делать профилей со своими картинками.
На митинге в городе с 100 тысячным населением вас легко найдут, просмотря 1-2 совпадения. В Москве — задолбаются. Где-то пол года назад Vasyutka, с которым мы работаем вместе, давал рассказывал на эту тему:
Кстати, про соцсети
Тут я позволю себе сделать небольшой экскурс в сторону. Качество обучения алгоритма распознавания лиц зависит от трёх факторов:
- Качество выделения лица.
- Используемая метрика близости лиц при обучения Triplet Loss, Center Loss, spherical loss, и.т.д.
- Размер базы
По п.2 вроде как сейчас достигнут предел. В принципе, математика развивается по таким вещам очень быстро. Да и после triplet loss остальные функции потерь не давали драматического прироста, лишь плавное улучшение и понижение размера базы.
Выделение лица — это сложно, если надо найти лица под всеми углами, потеряв доли процента. Но создание такого алгоритма — это достаточно предсказуемый и хорошо управляемый процесс. Чем более всё синее, тем лучше, большие углы корректно обрабатываются:

А полгода назад было так:

Видно, что потихоньку всё больше и больше компаний проходят этот путь, алгоритмы начинают распознавать всё более и более повёрнутые лица.
А вот с размером базы — всё интереснее. Открытые базы — маленькие. Хорошие базы максимум на пару десятков тысяч человек. Те что большие — странно структурированы / плохие (megaface, MS-Celeb-1M).
Как вы думаете, откуда создатели алгоритмов взяли эти базы?
Маленькая подсказка. Первый продукт NTech, который они сейчас сворачивают — Find Face, поиск людей по вконтакту. Думаю пояснения не нужны. Конечно, вконтакт борется с ботами, которые выкачивают все открытые профили. Но, насколько я слышал, народ до сих пор качает. И одноклассников. И инстаграмм.
Вроде как с Facebook — там всё сложнее. Но почти уверен, что что-то тоже придумали.
Так что да, если ваш профиль открыт — то можете гордиться, он использовался для обучения алгоритмов;)
Про решения и про компании
Тут можно гордиться. Из 5 компаний-лидеров в мире сейчас два — Российские. Это N-Tech и VisionLabs. Пол года назад лидерами был NTech и Vocord, первые сильно лучше работали по повёрнутым лицам, вторые по фронтальным.
Сейчас остальные лидеры — 1-2 китайских компании и 1 американская, Vocord что-то сдал в рейтингах.
Еще российские в рейтинге itmo, 3divi, intellivision. Synesis — белорусская компания, хотя часть когда-то была в Москве, года 3 назад у них был блог на Хабре. Ещё про несколько решений знаю, что они принадлежат зарубежным компаниям, но офисы разработки тоже в России. Ещё есть несколько российских компаний которых нет в конкурсе, но у которых вроде неплохие решения. Например есть у ЦРТ. Очевидно, что у Одноклассников и Вконтакте тоже есть свои хорошие, но они для внутреннего пользования.
Короче да, на лицах сдвинуты в основном мы и китайцы.
NTech вообще первым в миру показал хорошие параметры нового уровня. Где-то в конце 2015 года. VisionLabs догнал NTech только только. В 2015 году они были лидерами рынка. Но их решение было прошлого поколения, а пробовать догнать NTech они стали лишь в конце 2016 года.
Если честно, то мне не нравятся обе этих компании. Очень агрессивный маркетинг. Я видел людей которым было впарено явно неподходящее решение, которое не решало их проблем.
С этой стороны Vocord мне нравился сильно больше. Консультировал как-то ребят кому Вокорд очень честно сказал «у вас проект не получится с такими камерами и точками установки». NTech и VisionLabs радостно попробовали продать. Но что-то Вокорд в последнее время пропал.
Выводы
В выводах хочется сказать следующее. Распознавание лиц это очень хороший и сильный инструмент. Он реально позволяет находить преступников сегодня. Но его внедрение требует очень точного анализа всех параметров. Есть применения где достаточно OpenSource решения. Есть применения (распознавание на стадионах в толпе), где надо ставить только VisionLabs|Ntech, а ещё держать команду обслуживания, анализа и принятия решения. И OpenSource вам тут не поможет.
На сегодняшний день нельзя верить всем сказкам о том, что можно ловить всех преступников, или наблюдать всех в городе. Но важно помнить, что такие вещи могут помогать ловить преступников. Например чтобы в метро останавливать не всех подряд, а только тех кого система считает похожими. Ставить камеры так, чтобы лица лучше распознавались и создавать под это соответствующую инфраструктуру. Хотя, например я — против такого. Ибо цена ошибки если вас распознает как кого-то другого может быть слишком велика.
P.S.
В последнее время делаю много мелких статей/видеороликов. Но так как это не формат Хабра — то публикую их в блоге или на ютубе. Трансляция всего есть в телеге и вк.
На Хабре обычно публикую, когда рассказ становится уже более самозамкнутым, иногда собрав 2-3 разных мини-рассказа на соседние темы.
Оценка качества Биометрических систем
Работа
биометрической системы идентификации
пользователя (БСИ) описывается техническими
и ценовыми параметрами. Качество работы
БСИ характеризуется процентом ошибок
при прохождении процедуры допуска. В
БСИ различают ошибки трех видов:
-
FRR
(False Rejection Rate)ошибка первого рода—
вероятность принять «своего» за
«чужого». Обычно в коммерческих
системах эта ошибка выбирается равной
примерно 0,01, поскольку считается, что,
разрешив несколько касаний для «своих»,
можно искусственным способом улучшить
эту ошибку. В ряде случаев (скажем, при
большом потоке, чтобы не создавать
очередей) требуется улучшение FRR до
0,001-0,0001. В системах, присутствующих на
рынке, FRR обычно находится в диапазоне
0,025-0,01. -
FAR
(False Acceptance Rate)ошибка второго рода— вероятность принять «чужого» за
«своего». В представленных на рынке
системах эта ошибка колеблется в
основном от 10-3до 10-6, хотя
есть решения и с FAR = 10-9. Чем больше
данная ошибка, тем грубее работает
система и тем вероятнее проникновение
«чужого»; поэтому в системах с
большим числом пользователей или
транзакций следует ориентироваться
на малые значения FAR.
-
EER
(Equal Error Rates)– равная вероятность
(норма) ошибок первого и второго рода.
Биометрические
технологии
основаны на биометрии, измерении
уникальных характеристик отдельно
взятого человека. Это могут быть как
уникальные признаки, полученные им с
рождения, например: ДНК, отпечатки
пальцев, радужная оболочка глаза; так
и характеристики, приобретённые со
временем или же способные меняться с
возрастом или внешним воздействием,
например: почерк, голос или походка.
Все
биометрические системы работают
практически по одинаковой схеме.
Во-первых, система запоминает образец
биометрической характеристики (это и
называется процессом записи). Во время
записи некоторые биометрические системы
могут попросить сделать несколько
образцов для того, чтобы составить
наиболее точное изображение биометрической
характеристики. Затем полученная
информация обрабатывается и
преобразовывается в математический
код. Кроме того, система может попросить
произвести ещё некоторые действия для
того, чтобы «приписать» биометрический
образец к определённому человеку.
Например, персональный идентификационный
номер (PIN) прикрепляется к определённому
образцу, либо смарт-карта, содержащая
образец, вставляется в считывающее
устройство. В таком случае, снова делается
образец биометрической характеристики
и сравнивается с представленным образцом.
Идентификация по любой биометрической
системе проходит четыре стадии:
-
Запись
– физический или поведенческий образец
запоминается системой; -
Выделение
– уникальная информация выносится из
образца и составляется биометрический
образец; -
Сравнение
– сохраненный образец сравнивается с
представленным; -
Совпадение/несовпадение
— система решает, совпадают ли
биометрические образцы, и выносит
решение.
Подавляющее
большинство людей считают, что в памяти
компьютера хранится образец отпечатка
пальца, голоса человека или картинка
радужной оболочки его глаза. Но на самом
деле в большинстве современных систем
это не так. В специальной базе данных
хранится цифровой код длиной до 1000 бит,
который ассоциируется с конкретным
человеком, имеющим право доступа. Сканер
или любое другое устройство, используемое
в системе, считывает определённый
биологический параметр человека. Далее
он обрабатывает полученное изображение
или звук, преобразовывая их в цифровой
код. Именно этот ключ и сравнивается с
содержимым специальной базы данных для
идентификации личности [19].
Преимущества
биометрической идентификации состоит
в том, что биометрическая защита дает
больший эффект по сравнению, например,
с использованием паролей, смарт-карт,
PIN-кодов, жетонов или технологии
инфраструктуры открытых ключей. Это
объясняется возможностью биометрии
идентифицировать не устройство, но
человека.
Обычные
методы защиты чреваты потерей или кражей
информации, которая становится открытой
для незаконных пользователей.
Исключительный биометрический
идентификатор, например, отпечатки
пальцев, является ключом, не подлежащим
потере [18].
Соседние файлы в папке ГОСЫ
- #
- #
- #
- #
- #
- #
- #
- #
- #