
Подробно рассматриваем обратное распространение ошибки для простой нейронной сети. Численный пример
Уровень сложности
Средний
Время на прочтение
6 мин
Количество просмотров 4.6K
В данной статье мы рассмотрим прямое распространение сигнала и обратное распространение ошибки в полносвязной нейронной сети прямого распространения. В результате получим весь набор формул, необходимых для программной реализации нейронной сети. В завершении статьи рассмотрим численный пример.
«Полносвязная» (fully connected) — означает, что каждый нейрон предыдущего слоя соединён с каждым нейроном следующего слоя. «Прямого распространения» (feedforward) — означает, что сигнал проходит через нейронную сеть в одном направлении от входного к выходному слою.
Полносвязная нейронная сеть прямого распространения («перцептрон») — это простейший и наиболее типичный пример искусственной нейронной сети.
Содержание
-
Нейронная сеть как функция
-
Дизайн нейронной сети
-
Прямое распространение сигнала
-
Обратное распространение ошибки и обновление
4.1. Вычисление новых весов матрицы W^3
4.2. Вычисление новых смещений вектора b^3
4.3. Вычисление новых весов матрицы W^2
4.4. Вычисление новых смещений вектора b^2
-
Численный пример
-
Обобщение для произвольного числа слоёв
Нейронная сеть как функция
Искусственная нейронная сеть является математической функцией, а точнее — композицией (суперпозицией) функций.
Было доказано (George Cybenko, 1989), что полносвязная нейронная сеть прямого распространения с хотя бы одним скрытым слоем и достаточным количеством нейронов потенциально может аппроксимировать любую непрерывную функцию, т.е. по своей сути она — универсальный аппроксиматор.
«Свойства универсальной аппроксимации встречаются в математике чаще, чем можно было бы ожидать. Например, теорема Вейерштрасса — Стоуна доказывает, что любая непрерывная функция на замкнутом интервале может быть приближена многочленной функцией. Если ослабить наши критерии далее, можно использовать ряды Тейлора и ряды Фурье, предлагающие некоторые возможности универсальной аппроксимации (в пределах их областей схождения). Тот факт, что универсальная сходимость — довольно обычное явление в математике, дает частичное обоснование эмпирического наблюдения, что существует много малых вариантов полносвязных сетей, которые, судя по всему, дают свойство универсальной аппроксимации».
— Рамсундар Б., Заде Р.Б. TensorFlow для глубокого обучения. Спб., 2019. С. 101.
Запишем нейронную сеть, которую мы будем рассматривать в данной статье, в виде функции:

где ![]() — вектор входных значений — первый слой,
— вектор входных значений — первый слой, ![]() — второй, скрытый и
— второй, скрытый и ![]() — третий слои нейронной сети,
— третий слои нейронной сети, ![]() ,
, ![]() — векторы смещений и
— векторы смещений и ![]() ,
, ![]() — матрицы весов второго и третьего слоёв соответственно,
— матрицы весов второго и третьего слоёв соответственно, ![]() — вектор-функция активации второго слоя,
— вектор-функция активации второго слоя, ![]() — вектор-функция активации третьего, последнего слоя и, соответственно, вектор выходных значений нейронной сети.
— вектор-функция активации третьего, последнего слоя и, соответственно, вектор выходных значений нейронной сети.
Мы будем использовать принятую в литературе по нейронам сетям запись ![]() , где
, где ![]() — вектор-столбец (в литературе по математике под вектором стандартно (по умолчанию) понимается вектор-столбец). Произведение матриц
— вектор-столбец (в литературе по математике под вектором стандартно (по умолчанию) понимается вектор-столбец). Произведение матриц ![]() определено, если число столбцов
определено, если число столбцов ![]() равно числу строк
равно числу строк ![]() . Таким образом число столбцов
. Таким образом число столбцов ![]() матрицы
матрицы ![]() равно числу строк
равно числу строк ![]() векторов
векторов ![]() и
и ![]() .
.
Для комфортного чтения статьи необходимо обладать некоторым знанием линейной алгебры (обязательный минимум — операции над матрицами), производной сложной функции и частных производных.
Дизайн нейронной сети
Нейронная сеть имеет три слоя с тремя нейронами в каждом из них. Нелинейное изменение проходящего через сеть сигнала обеспечивает функция активации сигмоид (sigmoid) на скрытом и выходном слоях:
![]()
Поскольку на практике большинство реальных данных имеют нелинейный характер, используются нелинейные функции активации, позволяющие извлекать нелинейные зависимости в данных.

Перепишем уравнение рассматриваемой сети для заданных параметров:
![mathbf{a}^3=mathbf{f}(mathbf{x}^3)=mathbf{f}left(left[begin{matrix}w_{11}^3&w_{12}^3&w_{13}^3\w_{21}^3&w_{22}^3&w_{23}^3\w_{31}^3&w_{32}^3&w_{33}^3\end{matrix}right]timesmathbf{a}^2+left[begin{matrix}b_1^3\b_2^3\b_3^3\end{matrix}right]right),](https://habrastorage.org/getpro/habr/upload_files/7d9/387/8ac/7d93878ac1d30bbfde445535d7e3e7f3.svg)
![mathbf{a}^2=mathbf{f}(mathbf{x}^2)=mathbf{f}left(left[begin{matrix}w_{11}^2&w_{12}^2&w_{13}^2\w_{21}^2&w_{22}^2&w_{23}^2\w_{31}^2&w_{32}^2&w_{33}^2\end{matrix}right]timesleft[begin{matrix}x_1^1\x_2^1\x_3^1\end{matrix}right]+left[begin{matrix}b_1^2\b_2^2\b_3^2\end{matrix}right]right).](https://habrastorage.org/getpro/habr/upload_files/c07/997/3d8/c079973d8b3650c30d2c5bd87c39ba7d.svg)
Функция активации поэлементно применяется к каждому элементу соответствующего вектора ![]() .
.
Прямое распространение сигнала
Запишем уравнения для прямого прохождения сигнала через нейронную сеть:

и функцию стоимости (cost function)

где ![]() — номер соответствующего целевого
— номер соответствующего целевого ![]() (вектора
(вектора ![]() ) и выходного
) и выходного ![]() значений,
значений, ![]() — число выходных значений.
— число выходных значений.
Таким образом, функция стоимости для нашей нейронной сети в развёрнутом виде:
![]()
Функция стоимости показывает нам насколько сильно отличаются текущие значения нейронной сети от целевых.
Обратное распространение ошибки и обновление
В сущности, для реализации алгоритма обратного распространения ошибки используется довольно простая идея.
Градиент (в общем случае) — вектор, определяющий направление наискорейшего роста функции нескольких переменных. Вычитая из текущих значений весов и смещений соответствующие значения частных производных как элементов градиента функции стоимости ![]() , мы будем приближаться к одному из ближайших (относительно начальной точки) минимумов функции стоимости и, таким образом, уменьшать величину ошибки. Согласно необходимому условию экстремума, в точках экстремума функции многих переменных её градиент равен нулю,
, мы будем приближаться к одному из ближайших (относительно начальной точки) минимумов функции стоимости и, таким образом, уменьшать величину ошибки. Согласно необходимому условию экстремума, в точках экстремума функции многих переменных её градиент равен нулю, ![]() .
.
Этот подход называется алгоритмом градиентного спуска. Иногда может возникать путаница или отождествление этих двух алгоритмов, поскольку они тесно взаимосвязаны и один используется для реализации другого.
Несмотря на простоту и эффективность, алгоритм градиентного спуска в общем случае имеет свои ограничения, например, седловая точка, локальный минимум, перетренировка (overtraining) (попадание в глобальный минимум).
Найдём частные производные по всем элементам матрицы ![]() :
:

поскольку ![]() — константа, то
— константа, то ![]() ,
,

Преобразуем функцию активации сигмоид и найдём её производную:

В производной по матрице мы находим производную по каждому из её элементов.
Раскроем сумму для переменной ![]() матрицы
матрицы ![]() :
:
![]()
Найдём частную производную по переменной ![]() . Поскольку
. Поскольку


Преобразуем сигмоид и получим окончательную форму выражения для ![]() :
:

Обратное распространение ошибки является частным случаем автоматического дифференцирования, для реализации которого нам и необходимо привести все вычислительные выражения к определённому виду.
Таким же образом для переменных ![]() и
и ![]() получим:
получим:

Найдём новые значения (обновлённые веса) для переменных ![]() ,
, ![]() и
и ![]() :
:

где ![]() (и́та) — буква греческого алфавита, обычно используемая для обозначения скорости обучения (learning rate), её значение должно быть установлено на промежутке от 0 до 1; * — новое значение переменной.
(и́та) — буква греческого алфавита, обычно используемая для обозначения скорости обучения (learning rate), её значение должно быть установлено на промежутке от 0 до 1; * — новое значение переменной.
Найдём остальные частные производные для матрицы ![]() . Раскроем сумму для
. Раскроем сумму для ![]() :
:
![]()
Найдём частную производную по переменной ![]() :
:

Преобразуем сигмоид и получим окончательную форму выражения для ![]() :
:

Таким же образом для переменных ![]() и
и ![]() получим:
получим:

Найдём новые значения (обновлённые веса) для переменных ![]() ,
, ![]() и
и![]() :
:

Раскроем сумму для ![]() :
:
![]()
Найдём частную производную по переменной ![]() :
:

Преобразуем сигмоид и получим окончательную форму выражения для ![]() :
:

Таким же образом для переменных ![]() и
и ![]() получим:
получим:

Найдём новые значения (обновлённые веса) для переменных ![]() ,
, ![]() и
и ![]() :
:

Теперь найдём частные производные по всем элементам вектора ![]() :
:

Найдём частную производную по ![]() :
:
![]()

Преобразуем сигмоид и получим окончательную форму выражения для ![]() :
:

Найдём новое значение для смещения ![]() :
:
![]()
Вычислим частные производные по ![]() и
и ![]() :
:
![]()

![]()

Найдём новые значения для ![]() и
и![]() :
:

Найдём частные производные по всем элементам матрицы ![]() . Раскроем сумму для переменной
. Раскроем сумму для переменной ![]() матрицы
матрицы ![]() . Поскольку
. Поскольку

в свою очередь,

тогда сумма для переменной ![]() матрицы
матрицы ![]() :
:


Найдём новое значение (обновлённый вес) для переменной ![]() :
:

Найдём остальные частные производные и их новые значения для матрицы ![]() .
.











Теперь найдём частные производные по всем элементам вектора ![]() . Раскроем сумму для переменной
. Раскроем сумму для переменной ![]() :
:


Найдём новое значение для ![]() :
:

Найдём остальные частные производные для вектора ![]() :
:


Найдём новые значения для переменных ![]() и
и ![]() :
:

Численный пример
Задача обучения нейронной сети состоит в аппроксимации некоторой неизвестной функции, которая отображает ![]() в
в ![]() .
.
Другими словами, существует некоторая неизвестная нам функция ![]() , которая для набора значений независимых переменных
, которая для набора значений независимых переменных ![]() выдаёт результат, соответствующий набору значений зависимых переменных
выдаёт результат, соответствующий набору значений зависимых переменных ![]() . Задача нейронной сети в результате обучения «заменить», приблизить, т.е. аппроксимировать неизвестную функцию
. Задача нейронной сети в результате обучения «заменить», приблизить, т.е. аппроксимировать неизвестную функцию ![]() . В случае успешного решения задачи, значения нашей нейронной сети на выходном слое
. В случае успешного решения задачи, значения нашей нейронной сети на выходном слое ![]() будут приблизительно равны значениям вектора
будут приблизительно равны значениям вектора ![]() аппроксимируемой функции.
аппроксимируемой функции.
Выберем случайным образом следующие начальные значения для нашей нейронной сети:
![mathbf{W}^2=left[begin{matrix}0.88&0.39&0.9\0.37&0.14&0.41\0.96&0.5&0.6\end{matrix}right],mathbf{W}^3=left[begin{matrix}0.29&0.57&0.36\0.73&0.53&0.68\0.01&0.02&0.58\end{matrix}right],\mathbf{b}^2=left[begin{matrix}0.23\0.89\0.08\end{matrix}right], mathbf{b}^3=left[begin{matrix}0.78\0.83\0.8\end{matrix}right].](https://habrastorage.org/getpro/habr/upload_files/900/997/a15/900997a1533912461462a1ec0e063655.svg)
А также входные и целевые значения: ![mathbf{x}^1=left[begin{matrix}0.03\0.72\0.49\end{matrix}right], mathbf{y}=left[begin{matrix}0.93\0.74\0.17\end{matrix}right].](https://habrastorage.org/getpro/habr/upload_files/c3f/7e1/935/c3f7e1935fb14118bd8fb6a33caa669b.svg)
После первого прямого прохождения сигнала значения скрытого и выходного слоёв:
![mathbf{a}^2=left[begin{matrix}0.726750911\0.769022513\0.681961335\end{matrix}right], mathbf{a}^3=left[begin{matrix}0.842189045\0.903072871\0.771744079\end{matrix}right].](https://habrastorage.org/getpro/habr/upload_files/9f8/50f/e7d/9f850fe7dac1549ad7429c4b3fc72506.svg)
Для скорости обучения установим значение ![]() .
.
Вычислим для первой эпохи (epoch) обучения нейронной сети обновлённые значения весов ![]() и
и ![]() :
:

Новые значения других весов и смещений находятся аналогичным образом, в соответствии с полученными ранее формулами.
После 10 000 эпох обучения матрицы весов и выходной слой имеют следующие значения:
![mathbf{W}^2=left[begin{matrix}0.881449843&0.424796239&0.923680774\0.372218081&0.193233937&0.446228651\0.957567842&0.441628217&0.560274759\end{matrix}right],\mathbf{W}^3=left[begin{matrix}0.480573892&0.772236752&0.529654336\0.394700365&0.174298746&0.381672097\-0.771753134&-0.808346904&-0.127425218\end{matrix}right],\mathbf{a}^3=left[begin{matrix}0.913047169\0.741592957\0.173072228\end{matrix}right].](https://habrastorage.org/getpro/habr/upload_files/9f6/a7a/63a/9f6a7a63a8130c245b77fffa8ad573bf.svg)
Обобщение для произвольного числа слоёв
Мы рассмотрели частный случай алгоритма обратного распространения ошибки для нейронной сети с одним скрытым слоем. Запишем формулы для реализации нейронной сети с произвольным числом скрытых слоёв.

где ![]() — номер выходного слоя,
— номер выходного слоя, ![]() — индекс строки матрицы весов,
— индекс строки матрицы весов, ![]() — число выходных значений.
— число выходных значений.
![]() — обобщённое дельта-правило (delta rule).
— обобщённое дельта-правило (delta rule).
Надеемся, что статья будет интересной и полезной для всех, кто приступает к изучению глубинного обучения и нейронных сетей!
Говорим о нейронных сетях: легкая подача сложной информации так, что поймет даже ребенок. Изучаем базис и углубляемся в тему с нуля.

Машинное обучение, data science, нейронные сети – эти сферы не только крайне интересные, но и довольно сложные. Остановимся на нейронных сетях: объясним, что это такое, и расскажем об основных понятиях. Нет времени читать и готовы сразу перейти к практике? Обратите внимание на курс Deep Learning и нейронные сети.
Нейрон – базовая единица нейронной сети. У каждого нейрона есть определённое количество входов, куда поступают сигналы, которые суммируются с учётом значимости (веса) каждого входа. Далее сигналы поступают на входы других нейронов. Вес каждого такого «узла» может быть как положительным, так и отрицательным. Например, если у нейрона есть четыре входа, то у него есть и четыре весовых значения, которые можно регулировать независимо друг от друга.
Искусственная нейронная сеть имитирует работу естественной нейронной сети – человеческого мозга – и используется для создания машин с искусственным интеллектом. Как правило, для обучения ИИ нужен «учитель» – набор информации с определёнными параметрами, значениями и показателями.
Соединения связывают нейроны между собой. Значение веса напрямую связано с соединением, а цель обучения – обновить вес каждого соединения, чтобы в дальнейшем не допускать ошибок.

Смещение – это дополнительный вход для нейрона, который всегда равен 1 и, следовательно, имеет собственный вес соединения. Это гарантирует, что даже когда все входы будут равны нулю, нейрон будет активен.
Функция активации используется для того, чтобы ввести нелинейность в нейронную сеть. Она определяет выходное значение нейрона, которое будет зависеть от суммарного значения входов и порогового значения.
Также эта функция определяет, какие нейроны нужно активировать, и, следовательно, какая информация будет передана следующему слою. Благодаря функции активации глубокие сети могут обучаться.
Входной слой – это первый слой в нейронной сети, который принимает входящие сигналы и передает их на последующие уровни.
Скрытый (вычислительный) слой применяет различные преобразования ко входным данным. Все нейроны в скрытом слое связаны с каждым нейроном в следующем слое.
Выходной слой – последний слой в сети, который получает данные от последнего скрытого слоя. С его помощью мы сможем получить нужное количество значений в желаемом диапазоне.
Вес представляет силу связи между нейронами. Например, если вес соединения узлов 1 и 3 больше, чем узлов 2 и 3, это значит, что нейрон 1 оказывает на нейрон 3 большее влияние. Нулевой вес означает, что изменения входа не повлияют на выход. Отрицательный вес показывает, что увеличение входа уменьшит выход. Вес определяет влияние ввода на вывод.
Прямое распространение – это процесс передачи входных значений в нейронную сеть и получения выходных данных, которые называются прогнозируемым значением. Когда входные значения передаются в первый слой нейронной сети, процесс проходит без каких-либо операций. Второй уровень сети принимает значения первого уровня, а после операций по умножению и активации передает значения далее. Тот же процесс происходит на более глубоких слоях.
Обратное распространение ошибки. После прямого распространения мы получаем значение, которое называется прогнозируемым. Чтобы вычислить ошибку, мы сравниваем прогнозируемое значение с фактическим с помощью функции потери. Затем мы можем вычислить производную от значения ошибки по каждому весу в нейронной сети.
В методе обратного распространения ошибки используются правила дифференциального исчисления. Градиенты (производные значений ошибок) вычисляются по значениям веса последнего слоя нейронной сети (сигналы ошибки распространяются в направлении, обратном прямому распространению сигналов) и используются для вычисления градиентов слоев.
Этот процесс повторяется до тех пор, пока не будут вычислены градиенты каждого веса в нейронной сети. Затем значение градиента вычитают из значения веса, чтобы уменьшить значение ошибки. Ээто позволяет добиться минимальных потерь.
Скорость обучения – это характеристика, которая используется во время обучения нейронных сетей. Она определяет, как быстро будет обновлено значение веса в процессе обратного распространения. Скорость обучения должна быть высокой, но не слишком, иначе алгоритм будет расходиться. При слишком маленькой скорости обучения алгоритм будет сходиться очень долго и застревать в локальных минимумах.

Конвергенция – это явление, когда в процессе итерации выходной сигнал становится все ближе к определенному значению. Чтобы не возникло переобучения (проблем работы с новыми данными из-за высокой скорости), используют регуляризацию – понижение сложности модели с сохранением параметров. При этом учитываются потеря и вектор веса (вектор изученных параметров в данном алгоритме).
Нормализация данных – процесс изменения масштаба одного или нескольких параметров в диапазоне от 0 до 1. Этот метод стоит использовать в том случае, если вы не знаете, как распределены ваши данные. Также с его помощью можно ускорить обучение.
Стоит упомянуть и о таком термине, как полностью связанные слои. Это значит, что активность всех узлов в одном слое переходит на каждый узел в следующем. В таком случае слои будут полностью связанными.
С помощью функции потери вы можете вычислить ошибку в конкретной части обучения. Это среднее значение функции для обучения:
- ‘mse’ – для квадратичной ошибки;
- ‘binary_crossentropy’ – для двоичной логарифмической;
- ‘categorical_crossentropy’ – для мультиклассовой логарифмической.
Для обновления весов в модели используются оптимизаторы:
- SGD (Stochastic Gradient Descent) для оптимизации импульса.
- RMSprop – адаптивная оптимизация скорости обучения по методу Джеффа Хинтона.
- Adam – адаптивная оценка моментов, которая также использует адаптивную скорость обучения.
Для измерения производительности нейронной сети используются метрики производительности. Точность, потеря, точность проверки, оценка — это лишь некоторые показатели.
Batch size – количество обучающих примеров за одну итерацию. Чем больше batch size, тем больше места будет необходимо.
Количество эпох показывает, сколько раз модель подвергается воздействию обучения. Эпоха – один проход вперёд или назад для всех примеров обучения.
Так что же такое искусственная нейронная сеть? Это система нейронов, которые взаимодействуют между собой. Каждый нейрон принимает сигналы или же отправляет их другим процессорам (нейронам). Объединённые в одну большую сеть, нейроны, обучаясь, могут выполнять сложные задачи.
Углубиться в сферу искусственного интеллекта и наработать практические навыки по программированию глубоких нейронных сетей вы можете на специализированном курсе Deep Learning и нейронные сети, где познакомитесь с основными библиотеками для Deep Learning, такими как TensorFlow, Keras и другими.
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
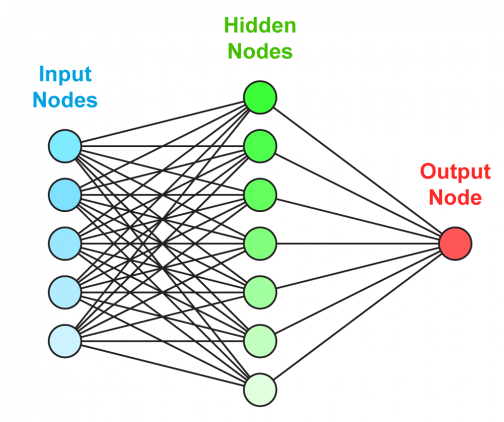
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
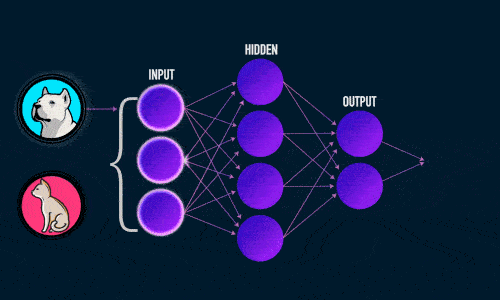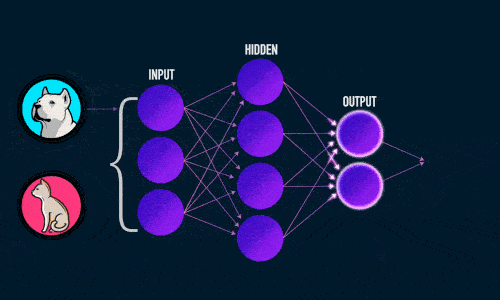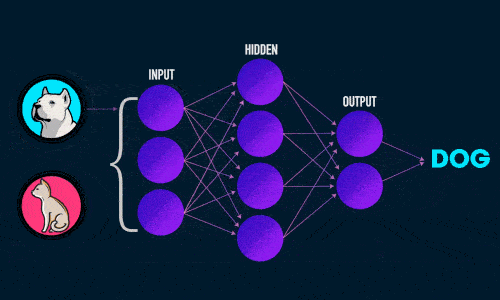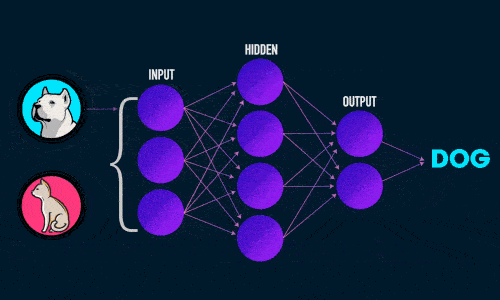
Прямое распространение ошибки
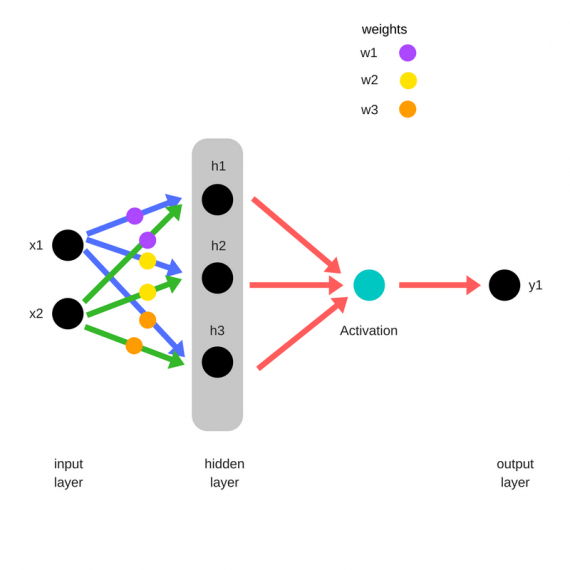
Зададим начальные веса случайным образом:
- w1
- w2
- w3
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение
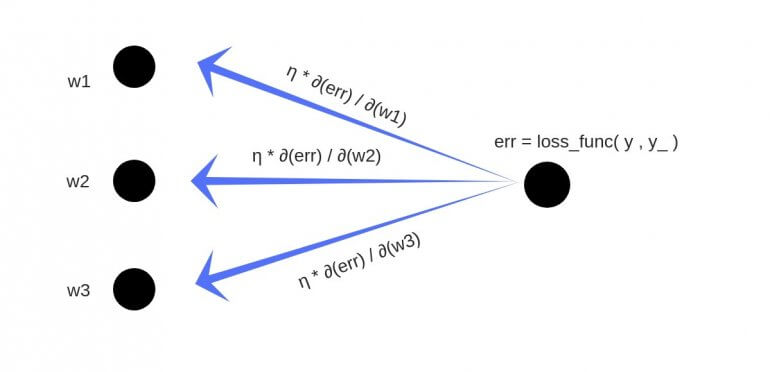
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.

 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
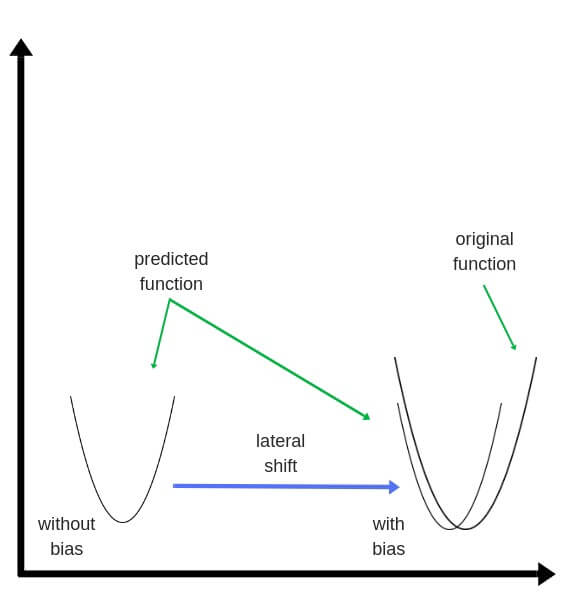
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
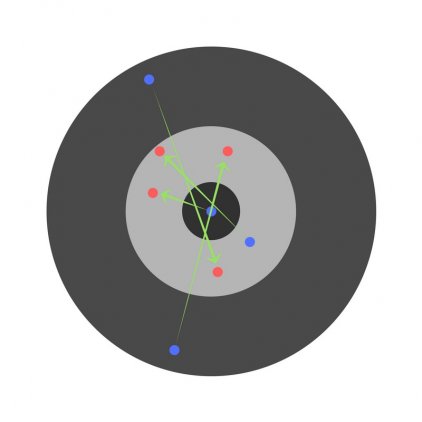
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
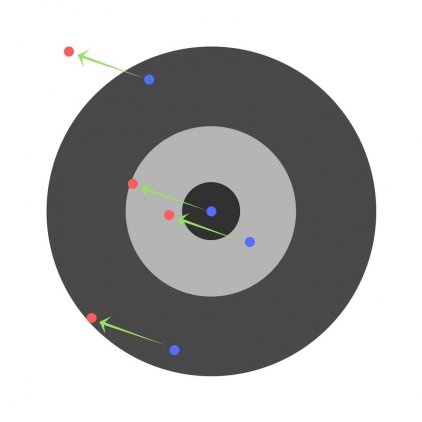
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
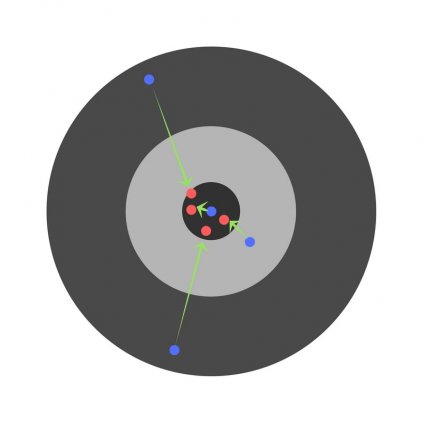
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
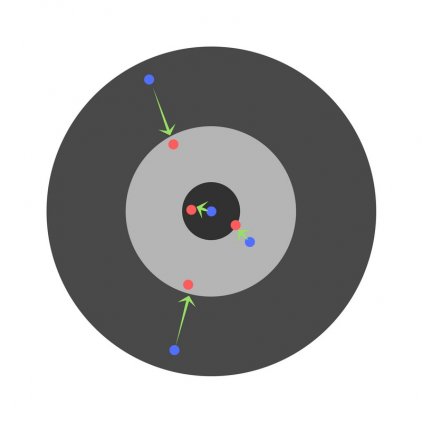
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
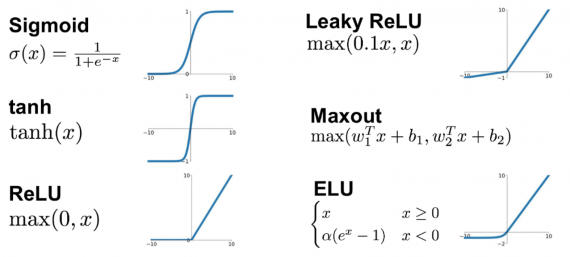
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
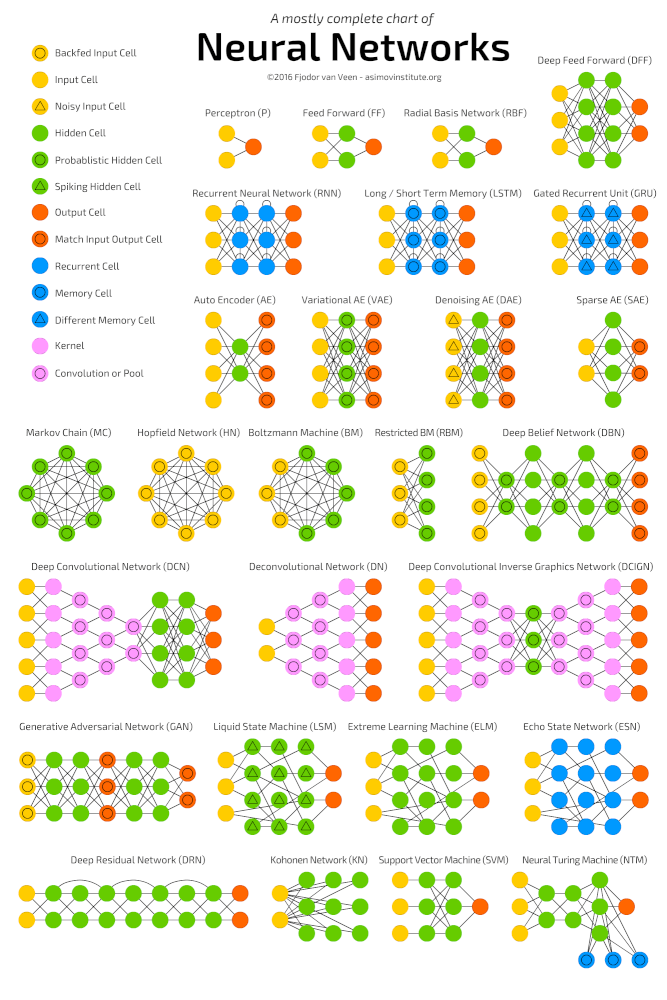
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:
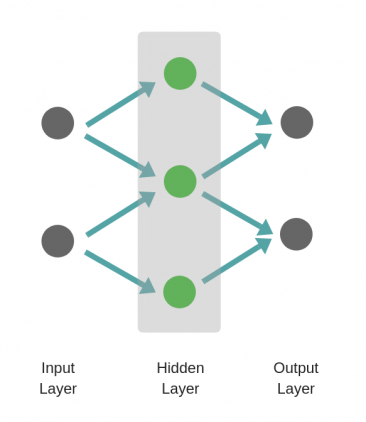
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
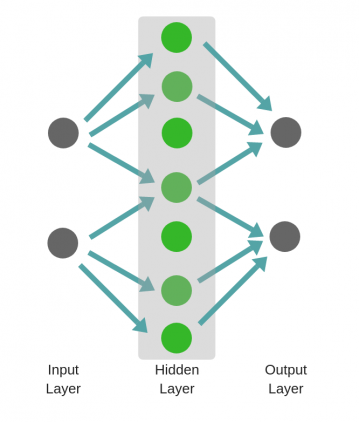
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
Но
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,
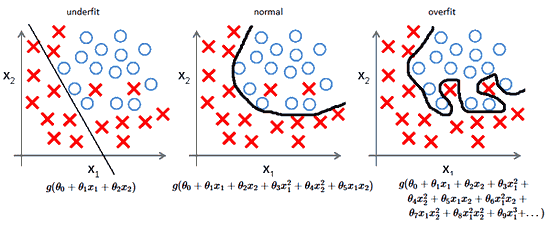
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Прямое распространение¶
- Простая сеть
- Прямой проход по шагам
- Код
- Более сложная сеть
- Архитектура
- Инициализация весов
- Bias Terms
- Working with Matrices
- Dynamic Resizing
- Refactoring Our Code
- Final Result
Простая сеть¶
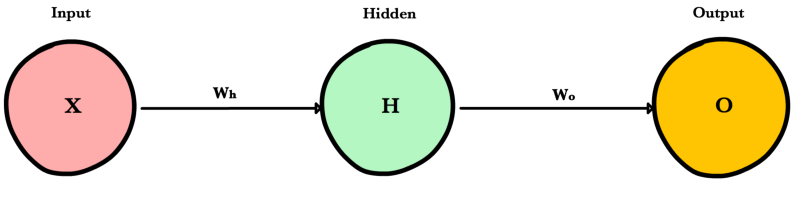
Прямое распространение — это процесс с помощью которого сеть делает предсказание (prediction). Также это основной режим работы обученной нейронной сети. Входные данные «распространяются» через каждый слой сети и выходной слой выдает финальный результат — предсказание. Для простой учебной нейронной сети один проход данных можно выразить математически как:
[Prediction = A(;A(;X W_h;)W_o;)]
Где (A) это функция активации, например ReLU, (X) это входные данные, (W_h) и (W_o) это веса слоев.
Прямой проход по шагам¶
- Вычислить значения входов скрытого слоя умножениием (X) на веса скрытого слоя (W_h) и получить (Z_h).
- Применить функцию активации к (Z_h) и передать результат (H) в выходной слой.
- Вычислить значения входов выходного слоя умножением значения (H) на веса выходного слоя (W_o) и получить (Z_o)
- Применить функцию активации к (Z_o). Результатом будет предсказание сети.
Код¶
Давайте напишем метод feed_forward() для распространения входных данных через нейронную сеть с 1-м скрытым слоем. Выход этого метода будет представлять собой предсказание модели.
def relu(z): return max(0,z) def feed_forward(x, Wh, Wo): # Hidden layer Zh = x * Wh H = relu(Zh) # Output layer Zo = H * Wo output = relu(Zo) return output
x это вход сети, Zo и Zh это «взвешенный» вход слоев, a Wo и Wh это веса слоев.
Более сложная сеть¶
Простая сеть очень помогает в учебном процессе, но реальные сети намного больше и сложнее устроены. Современные нейронные сети имеют гораздо больше скрытых слоев, больше нейронов в каждом слое, больше входных переменных. Рассмотрим более крупную (но всё ещё простую) нейронную сеть, которая позволит нам показать универсальный подход, основанный на матричном умножении, используемом в больших, «промышленных» нейронных сетях.
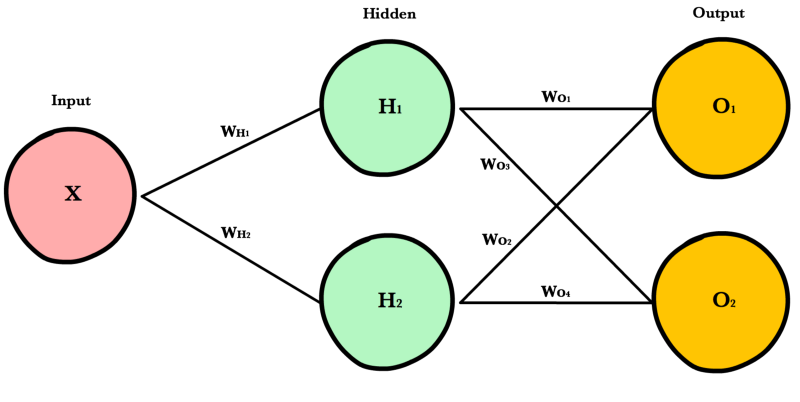
Архитектура¶
Для произвольного изменения количества входов или выходов сети, мы должны сделать наш код более гибким с помощью добавления новых параметров в __init_ метод: inputLayerSize, hiddenLayerSize,outputLayerSize. Мы будем продолжать ограничивать себя в количестве скрытых слоев, но сейчас это не так важно, потому что мы можем менять ширину (количество нейронов) имеющихся слоев.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2
Инициализация весов¶
Unlike last time where Wh and Wo were scalar numbers, our new weight variables will be numpy arrays. Each array will hold all the weights for its own layer — one weight for each synapse. Below we initialize each array with the numpy’s np.random.randn(rows, cols) method, which returns a matrix of random numbers drawn from a normal distribution with mean 0 and variance 1.
def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE)
Here’s an example calling random.randn():
arr = np.random.randn(1, 2) print(arr) >> [[-0.36094661 -1.30447338]] print(arr.shape) >> (1,2)
As you’ll soon see, there are strict requirements on the dimensions of these weight matrices. The number of rows must equal the number of neurons in the previous layer. The number of columns must match the number of neurons in the next layer.
A good explanation of random weight initalization can be found in the Stanford CS231 course notes [1] chapter on neural networks.
Bias Terms¶
Смещение (Bias) terms allow us to shift our neuron’s activation outputs left and right. This helps us model datasets that do not necessarily pass through the origin.
Using the numpy method np.full() below, we create two 1-dimensional bias arrays filled with the default value 0.2. The first argument to np.full is a tuple of array dimensions. The second is the default value for cells in the array.
def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo
Working with Matrices¶
To take advantage of fast linear algebra techniques and GPUs, we need to store our inputs, weights, and biases in matrices. Here is our neural network diagram again with its underlying matrix representation.
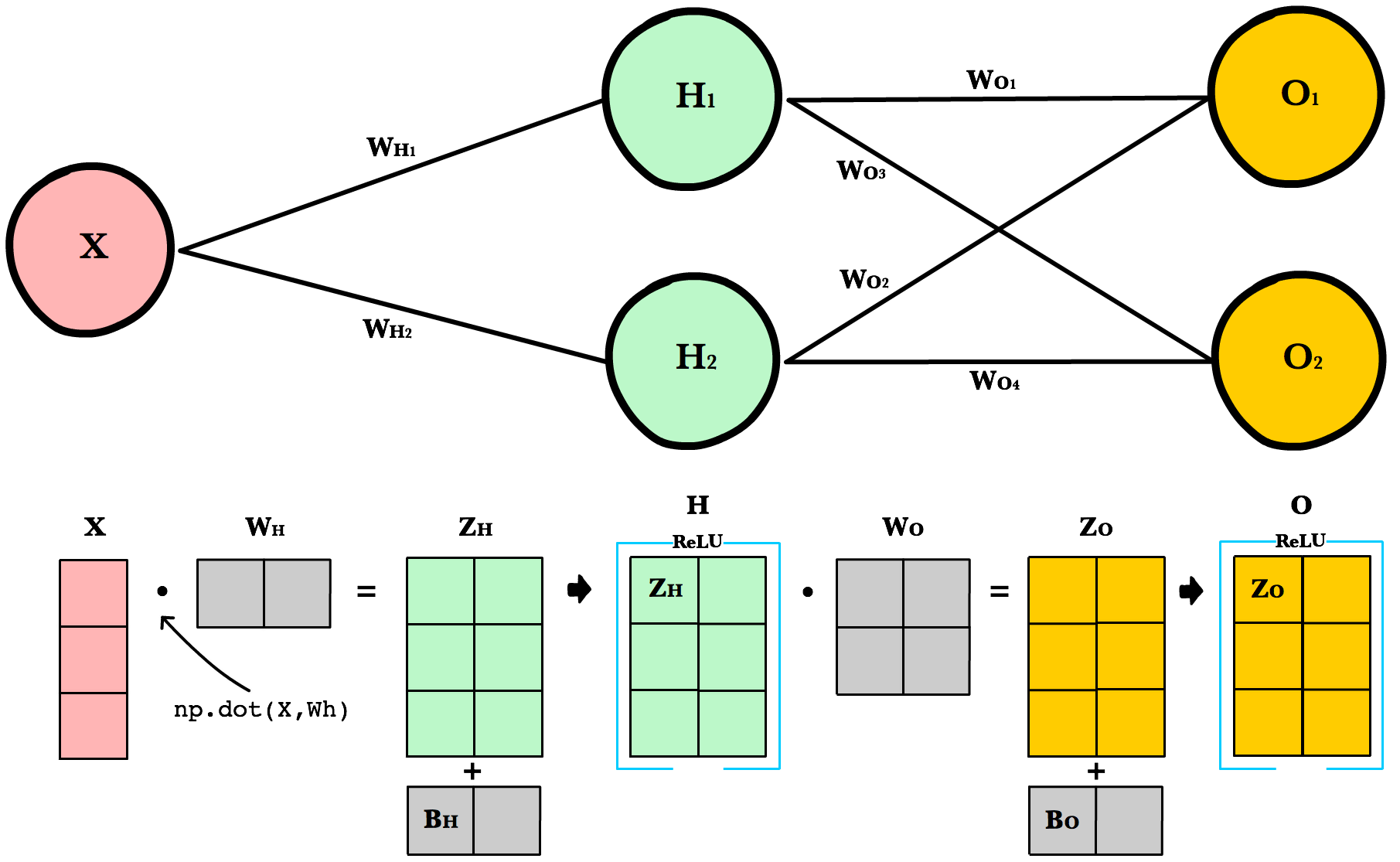
What’s happening here? To better understand, let’s walk through each of the matrices in the diagram with an emphasis on their dimensions and why the dimensions are what they are. The matrix dimensions above flow naturally from the architecture of our network and the number of samples in our training set.
Matrix dimensions
| Var | Name | Dimensions | Explanation |
X |
Input | (3, 1) | Includes 3 rows of training data, and each row has 1 attribute (height, price, etc.) |
Wh |
Hidden weights | (1, 2) | These dimensions are based on number of rows equals the number of attributes for the observations in our training set. The number columns equals the number of neurons in the hidden layer. The dimensions of the weights matrix between two layers is determined by the sizes of the two layers it connects. There is one weight for every input-to-neuron connection between the layers. |
Bh |
Hidden bias | (1, 2) | Each neuron in the hidden layer has is own bias constant. This bias matrix is added to the weighted input matrix before the hidden layer applies ReLU. |
Zh |
Hidden weighted input | (1, 2) | Computed by taking the dot product of X and Wh. The dimensions (1,2) are required by the rules of matrix multiplication. Zh takes the rows of in the inputs matrix and the columns of weights matrix. We then add the hidden layer bias matrix Bh. |
H |
Hidden activations | (3, 2) | Computed by applying the Relu function to Zh. The dimensions are (3,2) — the number of rows matches the number of training samples and the number of columns equals the number of neurons. Each column holds all the activations for a specific neuron. |
Wo |
Output weights | (2, 2) | The number of rows matches the number of hidden layer neurons and the number of columns equals the number of output layer neurons. There is one weight for every hidden-neuron-to-output-neuron connection between the layers. |
Bo |
Output bias | (1, 2) | There is one column for every neuron in the output layer. |
Zo |
Output weighted input | (3, 2) | Computed by taking the dot product of H and Wo and then adding the output layer bias Bo. The dimensions are (3,2) representing the rows of in the hidden layer matrix and the columns of output layer weights matrix. |
O |
Output activations | (3, 2) | Each row represents a prediction for a single observation in our training set. Each column is a unique attribute we want to predict. Examples of two-column output predictions could be a company’s sales and units sold, or a person’s height and weight. |
Dynamic Resizing¶
Before we continue I want to point out how the matrix dimensions change with changes to the network architecture or size of the training set. For example, let’s build a network with 2 input neurons, 3 hidden neurons, 2 output neurons, and 4 observations in our training set.
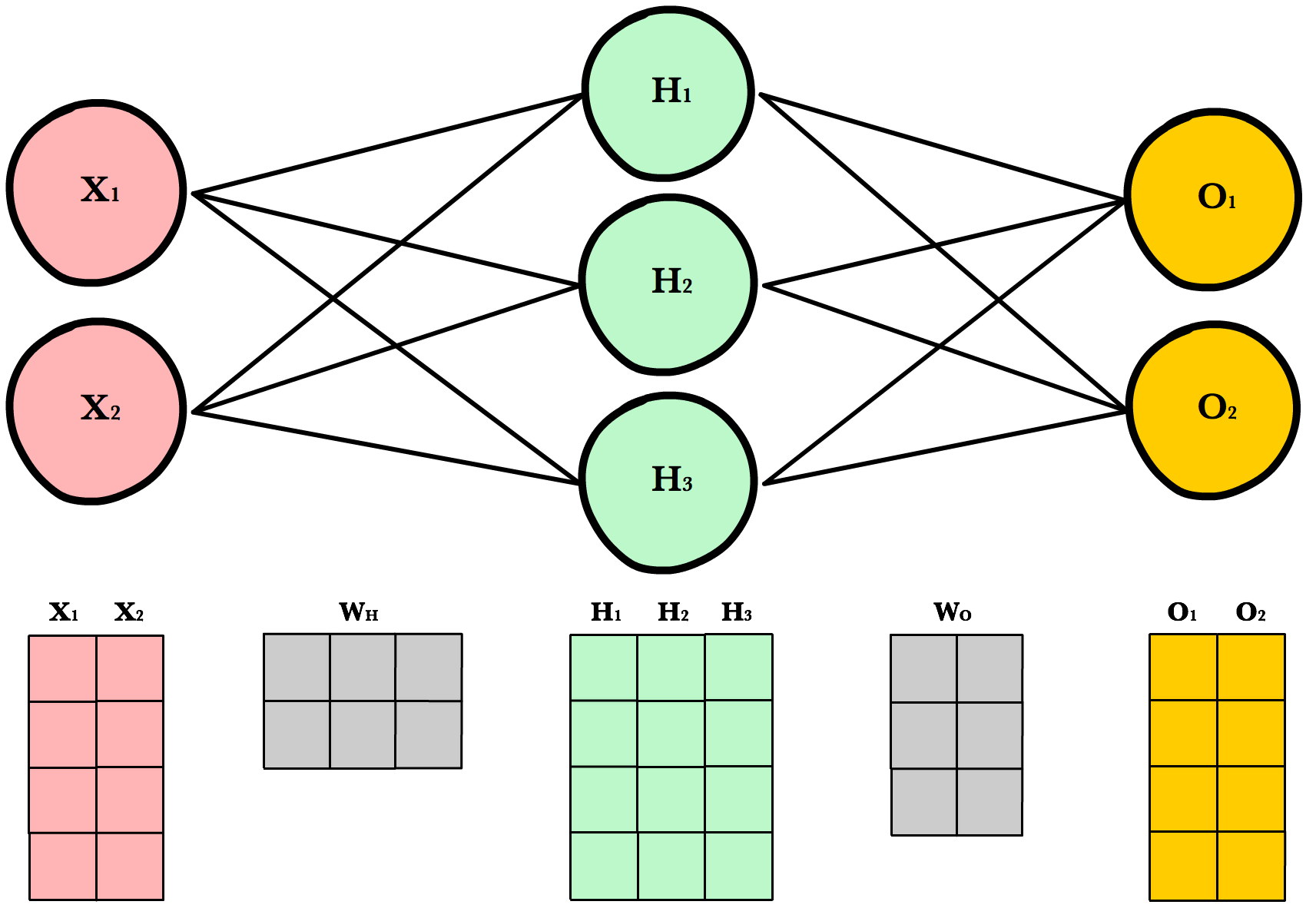
Now let’s use same number of layers and neurons but reduce the number of observations in our dataset to 1 instance:
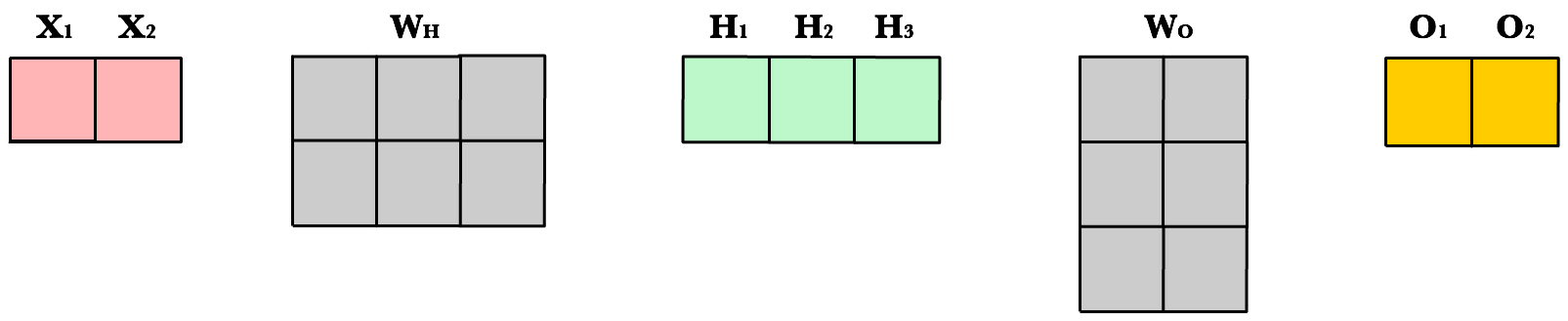
As you can see, the number of columns in all matrices remains the same. The only thing that changes is the number of rows the layer matrices, which fluctuate with the size of the training set. The dimensions of the weight matrices remain unchanged. This shows us we can use the same network, the same lines of code, to process any number of observations.
Refactoring Our Code¶
Here is our new feed forward code which accepts matrices instead of scalar inputs.
def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo) return yHat
Weighted input
The first change is to update our weighted input calculation to handle matrices. Using dot product, we multiply the input matrix by the weights connecting them to the neurons in the next layer. Next we add the bias vector using matrix addition.
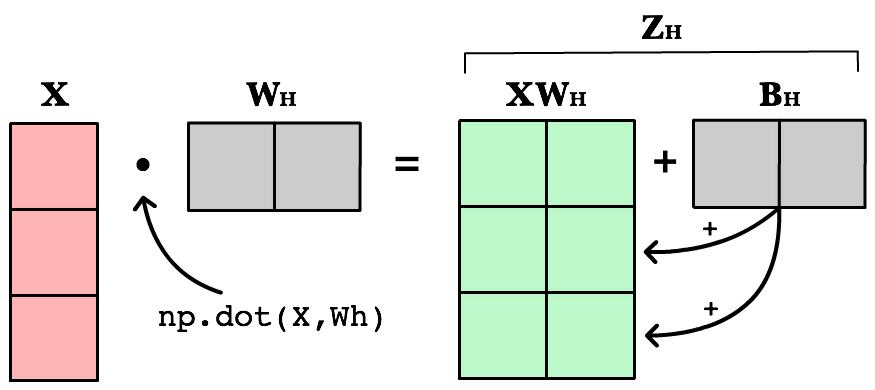
The first column in Bh is added to all the rows in the first column of resulting dot product of X and Wh. The second value in Bh is added to all the elements in the second column. The result is a new matrix, Zh which has a column for every neuron in the hidden layer and a row for every observation in our dataset. Given all the layers in our network are fully-connected, there is one weight for every neuron-to-neuron connection between the layers.
The same process is repeated for the output layer, except the input is now the hidden layer activation H and the weights Wo.
ReLU activation
The second change is to refactor ReLU to use elementwise multiplication on matrices. It’s only a small change, but its necessary if we want to work with matrices. np.maximum() is actually extensible and can handle both scalar and array inputs.
def relu(Z): return np.maximum(0, Z)
In the hidden layer activation step, we apply the ReLU activation function np.maximum(0,Z) to every cell in the new matrix. The result is a matrix where all negative values have been replaced by 0. The same process is repeated for the output layer, except the input is Zo.
Final Result¶
Putting it all together we have the following code for forward propagation with matrices.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2 def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE) def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo def relu(Z): return np.maximum(0, Z) def relu_prime(Z): ''' Z - weighted input matrix Returns gradient of Z where all negative values are set to 0 and all positive values set to 1 ''' Z[Z < 0] = 0 Z[Z > 0] = 1 return Z def cost(yHat, y): cost = np.sum((yHat - y)**2) / 2.0 return cost def cost_prime(yHat, y): return yHat - y def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo)
References
| [1] | http://cs231n.github.io/neural-networks-2/#init |
В этой статье мы узнаем о нейронных сетях прямого распространения, также известных как сети с глубокой прямой связью или многослойные персептроны. Они составляют основу многих важных нейронных сетей, используемых в последнее время, таких как сверточные нейронные сетиએ (широко используемые в приложениях компьютерного зрения), рекуррентные нейронные сетиએ (широко используемые для понимания естественного языка и последовательного обучения) и так далее. Мы постараемся понять важные концепции, используя интуитивно понятную игрушку и не будем вдаваясь в математику. Если вы хотите погрузиться в глубокое обучение, но не обладаете достаточным опытом в области статистики и машинного обучения, то эта статья станет идеальной отправной точкой.
Мы будем использовать сеть прямого распространения для решения задачи двоичной классификации. В машинном обучении классификация — это тип метода контролируемого обучения, в котором задача состоит в том, чтобы разделить образцы данных на заранее определенные группы с помощью функции принятия решений. Когда есть только две группы, это называется двоичной классификацией. На приведенном ниже рисунке показан пример. Точки синего цвета принадлежат одной группе (или классу), а оранжевые точки — другой. Воображаемые линии, разделяющие группы, называются границами принятия решений. Функция принятия решения извлекается из набора помеченных образцов, который называется обучающими данными, а процесс обучения функции принятия решения называется обучением.
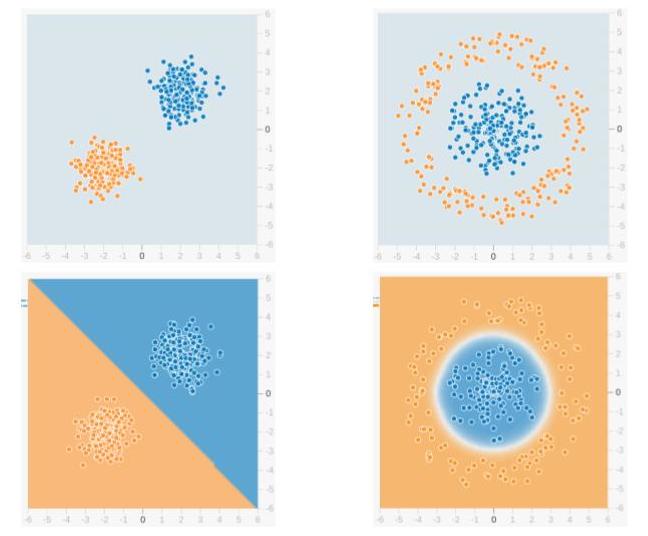
В приведенном примере верхняя строка показывает два разных распределения данных, а нижняя строка показывает границу решения. На левом изображении показан пример данных, которые можно разделить линейно. Это означает, что линейная граница (например, прямой линии) достаточно, чтобы разделить данные на группы. С другой стороны, изображение справа показывает пример данных, которые нельзя разделить линейно. Граница решения в этом случае должна быть круговой или многоугольной, как показано на рисунке.
1. Что есть нейронная сеть?
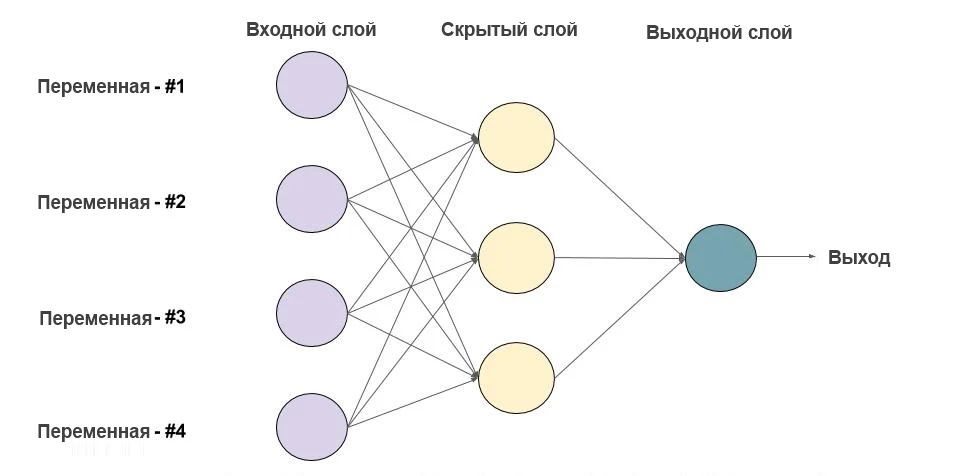
Ниже приведен пример нейронной сети прямого распространения. Это направленный ациклический граф, что означает, что в сети нет обратных связей или петель. У него есть входной слой, выходной слой и скрытый слой. Как правило, может быть несколько скрытых слоев. Каждый узел в слое — нейрон, который можно рассматривать как основной процессор нейронной сети.
1.1. Что есть нейрон?
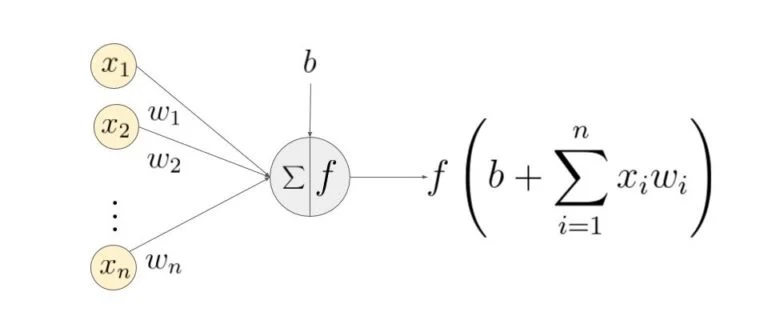
Искусственный нейрон — это основная единица нейронной сети. Принципиальная схема нейрона приведена ниже.
Как видно выше, он работает в два этапа: вычисляет взвешенную сумму своих входных данных, а затем применяет функцию активации для нормализации суммы. Функции активации могут быть линейными или нелинейными. Также, есть веса, связанные с каждым входом нейрона. Это параметры, которые сеть должна приобрести на этапе обучения.
1.2. Функции активации
Функция активацииએ используется как орган принятия решений на выходе нейрона. Нейрон изучает линейные или нелинейные границы принятия решений на основе функции активации. Он также оказывает нормализующее влияние на выход нейронов, что предотвращает выход нейронов после нескольких слоев, чтобы стать очень большим, за счет каскадного эффекта. Есть три наиболее часто используемых функции активации.
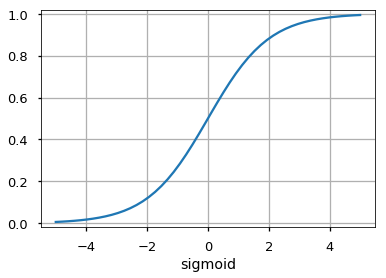
Сигмоидаએ
Он отображает входные данные (ось x) на значения от 0 до 1.
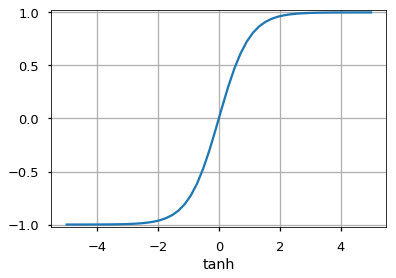
Tanh
Похожа на сигмовидную функцию, но отображает входные данные в значения от -1 до 1.
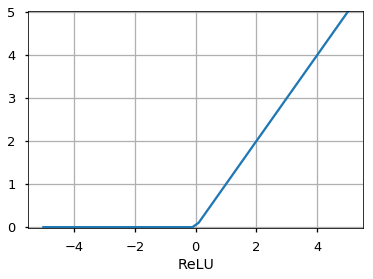
Rectified Linear Unit (ReLU)
Он позволяет проходить через него только положительным значениям. Отрицательные значения отображаются на ноль.
Функция активацииએ может быть другой, например, функция Unit Step, leaky ReLU, Noisy ReLU, Exponential LU и т.д., которые имеют свои плюсы и минусы.
1.3. Входной слой
Это первый слой нейронной сети. Он используется для передачи и приёма входных данных или функций в сеть.
1.4. Выходной слой
Это слой, который выдает прогнозы. Функция активации, используемая на этом уровне, различается для разных задач. Для задачи двоичной классификации мы хотим, чтобы на выходе было либо 0, либо 1. Таким образом, используется сигмовидная функция активации. Для задачи мультиклассовой классификации используется Softmaxએ (воспринимайте это как обобщение сигмоида на несколько классов). Для задачи регрессии, когда результат не является предопределенной категорией, мы можем просто использовать линейную единицу.
1.5. Скрытый слой
Сеть прямого распространения применяет к входу ряд функций. Имея несколько скрытых слоев, мы можем вычислять сложные функции, каскадируя более простые функции. Предположим, мы хотим вычислить седьмую степень числа, но хотим, чтобы вещи были простыми (поскольку их легко понять и реализовать). Вы можете использовать более простые степени, такие как квадрат и куб, для вычисления функций более высокого порядка. Точно так же вы можете вычислять очень сложные функции с помощью этого каскадного эффекта. Наиболее широко используемый скрытый блок — это тот, где функция активацииએ использует выпрямленный линейный блок (ReLU). Выбор скрытых слоёв — очень активная область исследований в машинном обучении. Тип скрытого слоя отличает разные типы нейронных сетей, такие как CNNએ, RNNએ и т.д. Количество скрытых слоев называется глубиной нейронной сети. Вы можете задать вопрос: сколько слоев в сети делают ее глубокой? На это нет правильного ответа. В общем случае, более глубокие сети могут научиться более сложным функциям.
1.6. Как сеть учится?
Обучающие образцы передаются по сети, и выходные данные, полученные от сети, сравниваются с фактическими выходными данными. Эта ошибка используется для изменения веса нейронов таким образом, чтобы ошибка постепенно уменьшалась. Это делается с помощью алгоритма обратного распространения ошибки, также называемого обратным распространением. Итеративная передача пакетов данных по сети и обновление весов для уменьшения ошибки называется стохастический градиентный спускએ (SGD). Величина, на которую изменяются веса, определяется параметром, называемым «Скорость обучения». Подробности SGD и backprop будут описаны в отдельном посте.
2.Зачем использовать скрытые слои?
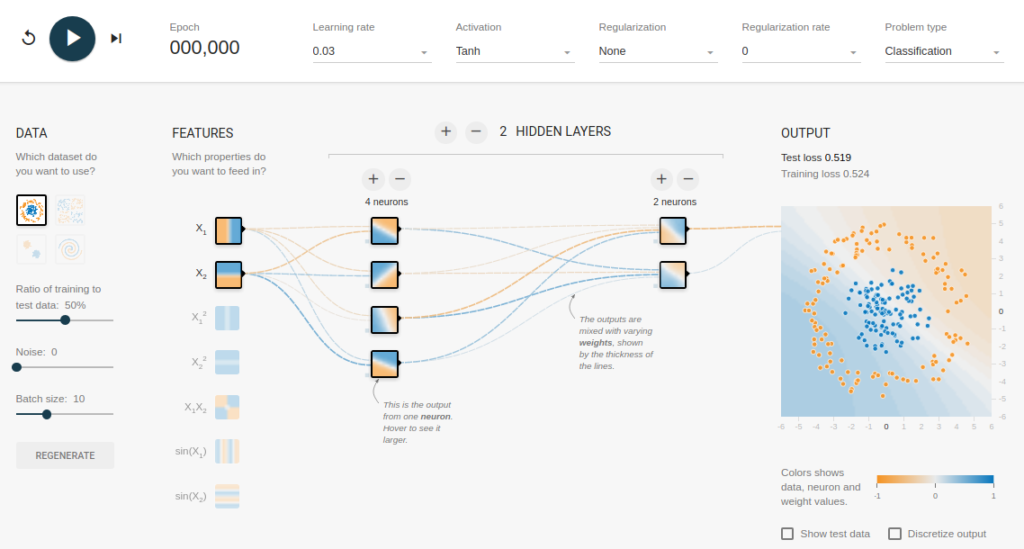
Чтобы понять значение скрытых слоев, мы попытаемся решить проблему двоичной классификации без скрытых слоев. Для этого мы будем использовать интерактивную платформу от Google, plays.tensorflow.org, которая представляет собой веб-приложение, где вы можете создавать простые нейронные сети с прямой связью и видеть эффекты обучения в реальном времени. Вы можете поиграть, изменив количество скрытых слоев, количество нейронов в скрытом слое, тип функции активации, тип данных, скорость обучения, параметры регуляризации и т.д. Выше приведен снимок экрана веб-страницы.
На приведенной выше странице вы можете выбрать данные и нажать кнопку воспроизведения, чтобы начать обучение.
Он покажет вам изученную границу решения и кривые потерь в правом верхнем углу.
2.1. Без скрытого слоя
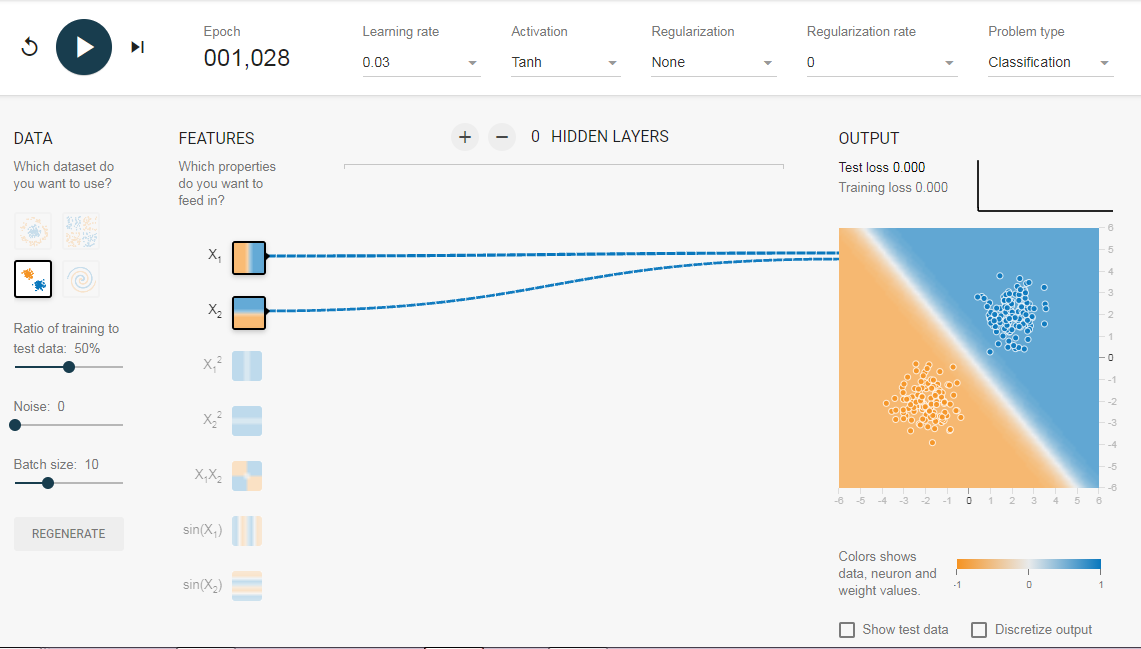
Нам нужна сеть без скрытого слоя, который я создал по этой ссылке. Здесь нет скрытых слоев, поэтому он становится простым нейроном, способным изучать линейную границу принятия решения. Мы можем выбрать тип данных в верхнем левом углу. В случае линейно разделяемых данных (3-й тип), он сможет получить (когда вы нажмете кнопку воспроизведения) линейную границу, как показано ниже.
Однако, если вы выберете первые данные, вы не сможете для них узнать границу кругового решения.
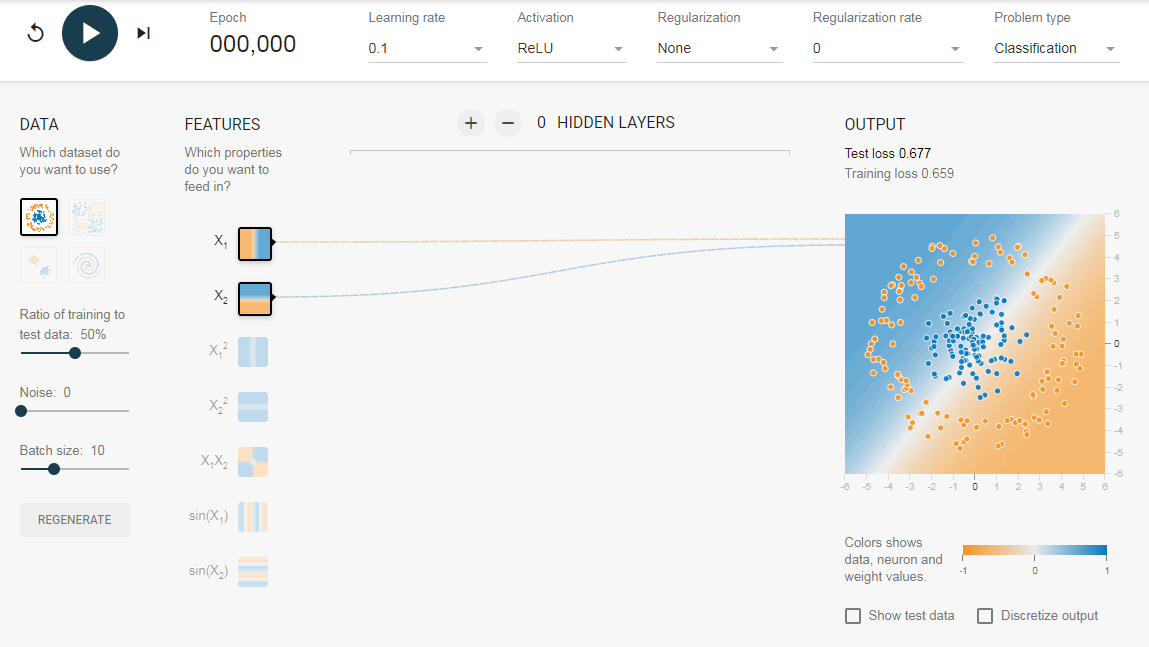
Поскольку данные находятся в круговой области, можно сказать, что использование квадратов значений функций в качестве входных данных может помочь. Оказывается, после обучения нейрон сможет найти круговую границу принятия решения.
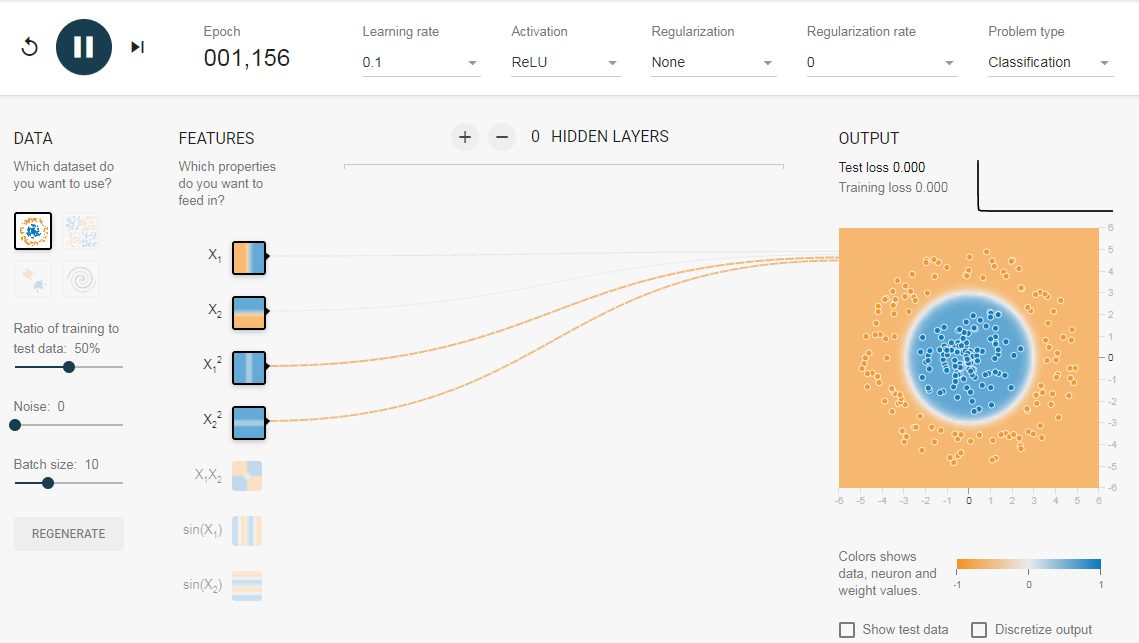
Теперь, если вы выберете 2-е данные, та же конфигурация не сможет узнать соответствующую границу решения.
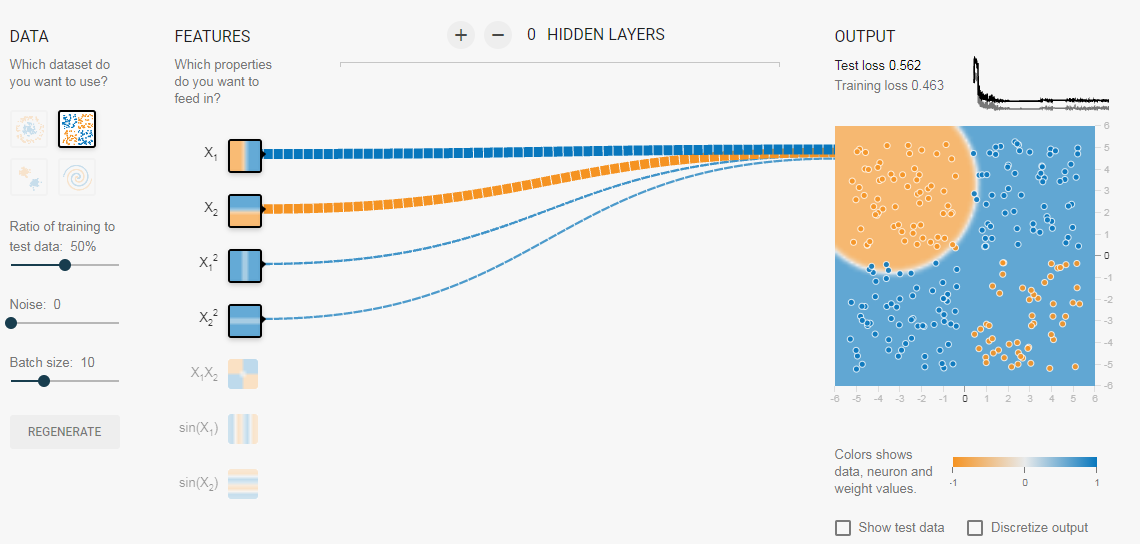
Опять же интуитивно кажется, что граница решения — это коническое сечение (например, парабола или гипербола). Итак, если мы включим продукт функции (например, X_1 X_2), нейрон сможет узнать желаемую границу принятия решения.
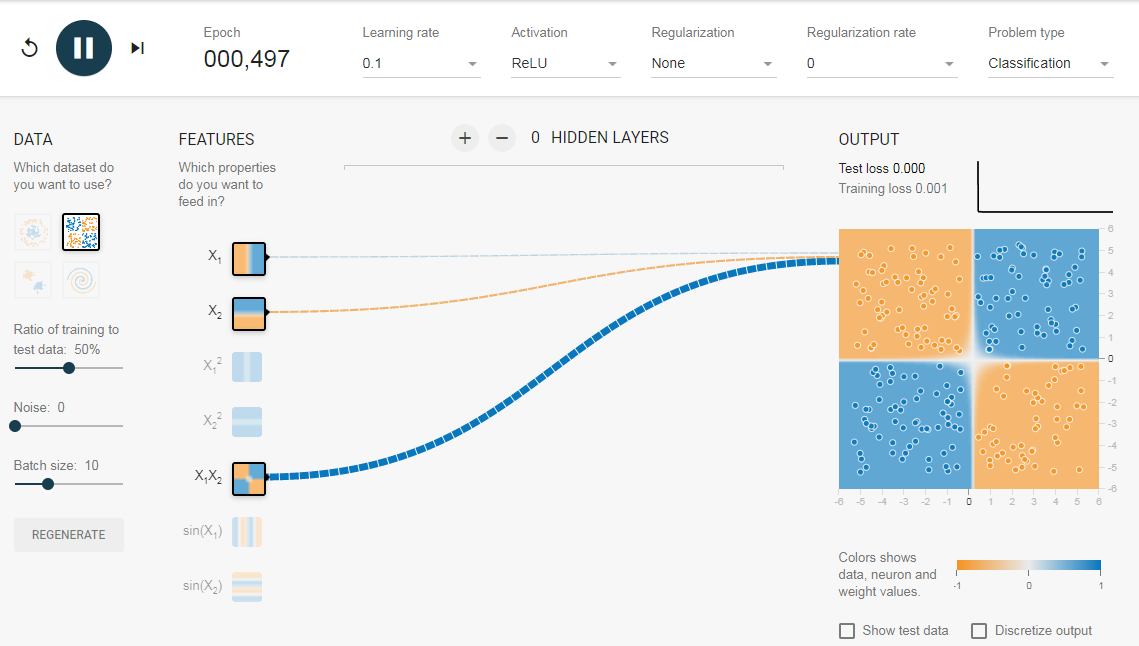
Описанные эксперименты показали:
- Используя один нейрон, мы можем узнать только линейную границу решения.
- Нам пришлось придумать преобразования функций (например, квадрат функций или продукт функций) путем визуализации данных. Этот шаг может быть сложным для данных, которые нелегко визуализировать.
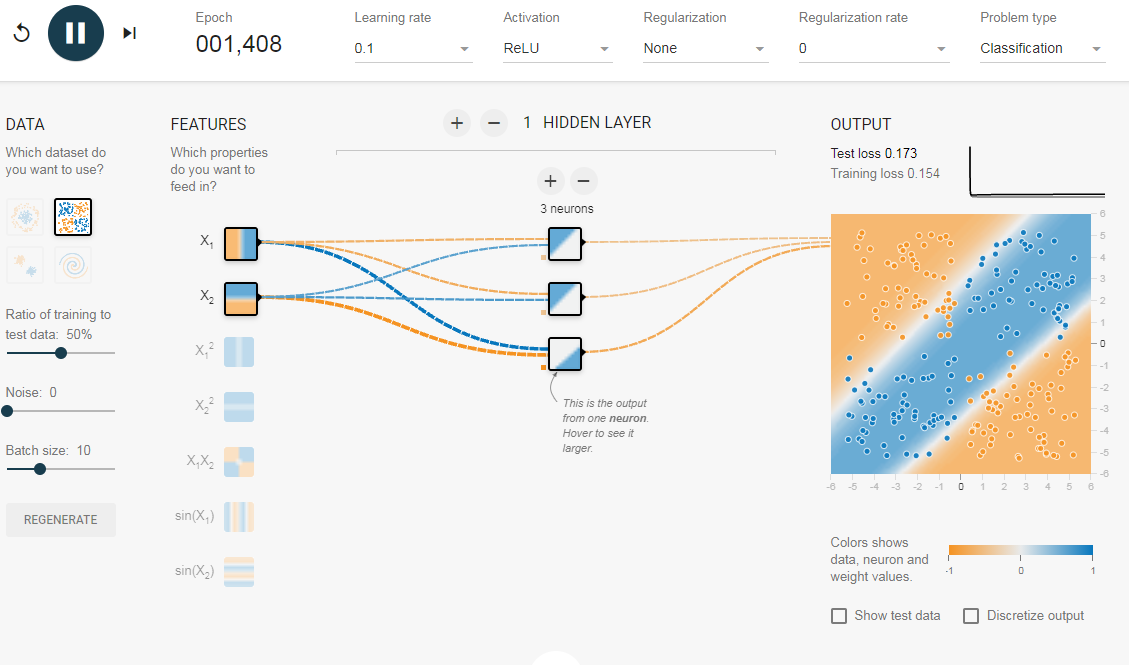
2.2. Добавление скрытого слоя
Добавив скрытый слой, как показано в этой ссылке, мы можем избавиться от этой функции проектирования и получить единую сеть, которая может изучить все три границы принятия решений. Нейронная сеть с одним скрытым слоем с нелинейными функциями активации считается универсальным аппроксиматором функций, теорема Цыбенкоએ (т.е. способной к обучению любой функции). Однако количество единиц в скрытом слое не фиксировано. Результат добавления скрытого слоя всего с 3 нейронами показан ниже:
3. Регуляризация
Как мы видели в предыдущем разделе, многослойная сеть может изучать нелинейные границы принятия решений. Однако, если в данных есть шум (что часто бывает), сеть может попытаться изучить нелинейность, вносимую шумом, пытаясь подогнать зашумленные выборки. В таких случаях зашумленные образцы следует рассматривать как выбросы. В этой ссылке я добавил немного шума к линейно разделяемым данным. Также, чтобы продемонстрировать идею, я увеличил количество скрытых нейронов.
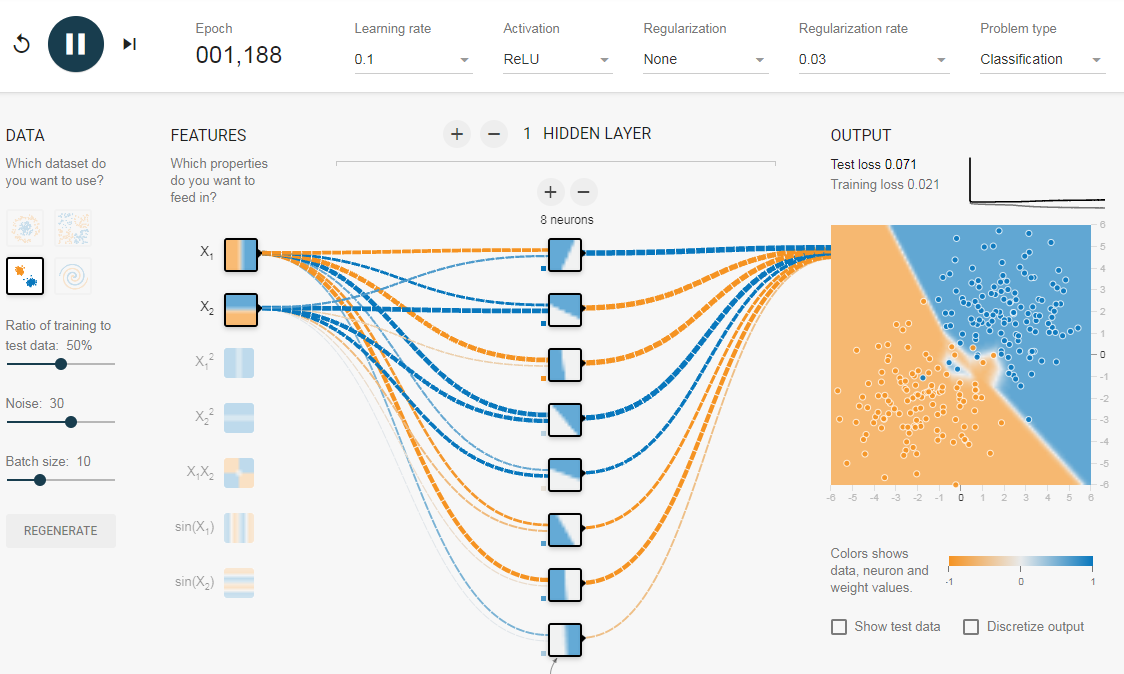
На приведенном выше рисунке можно увидеть, что граница принятия решения очень старается приспособить зашумленные выборки, чтобы уменьшить ошибку. Но, как видите, это ошибочно из-за шумных сэмплов. Другими словами, сеть будет неустойчивой при наличии шума. Это явление называется переобучением. В таких случаях, ошибка обучающих данных может уменьшиться, но сеть плохо работает с невидимыми данными. Это видно по кривым потерь в правом верхнем углу.
Потери в обучении уменьшаются, но потери в тестах увеличиваются. Также, можно видеть, что некоторые веса стали очень большими (очень толстые соединения или вы можете увидеть веса, если наведете курсор на соединения). Это можно исправить, наложив некоторые ограничения на значения весов (например, не позволяя весам становиться очень высокими). Это называется регуляризацией. Мы накладываем ограничения на остальные параметры сети. В некотором смысле мы не полностью доверяем обучающим данным и хотим, чтобы сеть усвоила «хорошие» границы принятия решений. Я добавил регуляризацию L2 в приведенную выше конфигурацию по этой ссылке, и результат показан ниже.
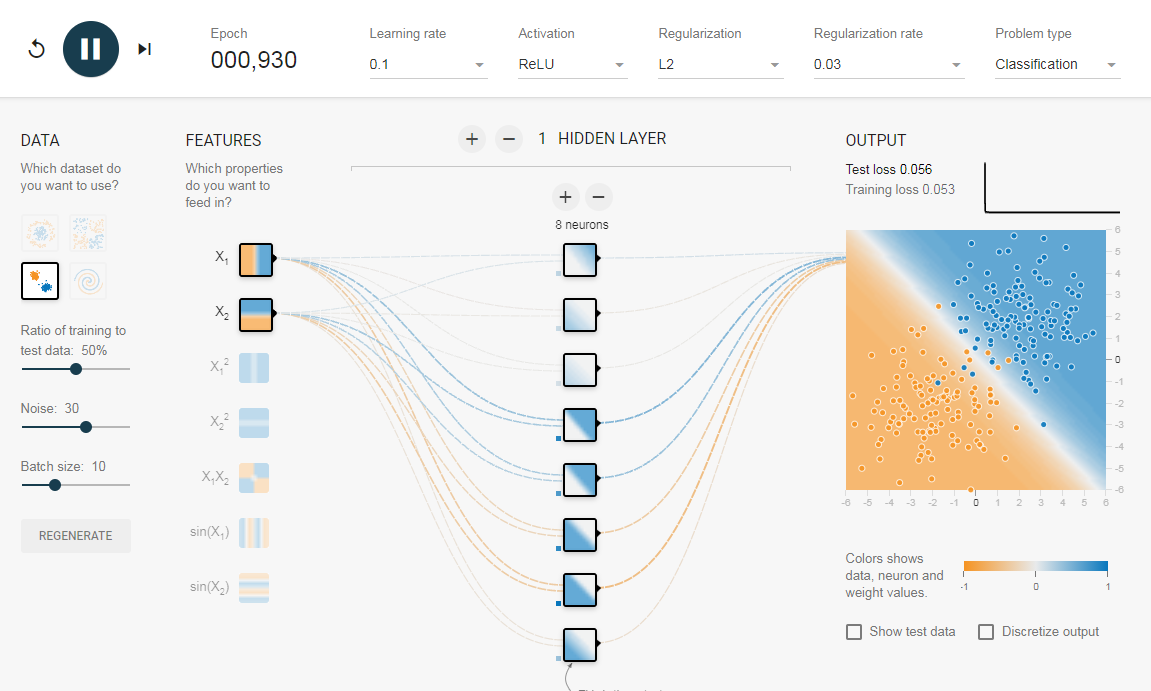
После включения регуляризации L2 граница принятия решения, изученная сетью, становится более гладкой и аналогичной случаю, когда не было шума. Эффект регуляризации также можно увидеть из кривых потерь и значений весов.
В следующем посте, если он случится мы узнаем, как реализовать нейронную сеть прямого распространения в Keras для решения нескольких проблема классификации и узнайте ещё больше о сетях прямого распространения.
Использованы материалы Understanding Feedforward Neural Networks
