
Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Вариант 1
Задание 1. Модель парной линейной регрессии.
Имеются данные о размере среднемесячных доходов в разных группах семей
|
Номер группы |
Среднедушевой денежный доход в месяц, руб., X |
Доля оплаты труда в структуре доходов семьи, %, Y |
|
1 |
79,8 |
64,2 |
|
2 |
152,1 |
66,1 |
|
3 |
199,3 |
69,0 |
|
4 |
240,8 |
70,6 |
|
5 |
282,4 |
72,4 |
|
6 |
301,8 |
74,3 |
|
7 |
385,3 |
76,0 |
|
8 |
457,8 |
77,1 |
|
9 |
577,4 |
78,4 |
Задания:
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a =0,05. Сделать выводы
2. Построить линейное уравнение парной регрессии Y на X и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Сделать выводы. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз доли оплаты труда структуре доходов семьи Y при прогнозном значении среднедушевого денежного дохода X, составляющем 111% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a =0,05. Сделать выводы.
Решение: Построим поле корреляции зависимости доли оплаты труда в структуре доходов семьи от среднедушевого денежного дохода в месяц.
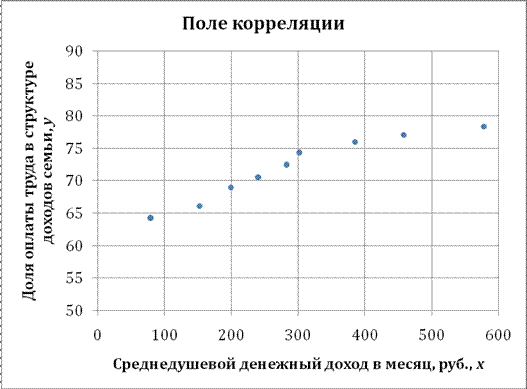
Точки на построенном графике размещаются вблизи кривой, напоминающей по форме Прямую, поэтому можно предположить, что между указанными величинами существует Линейная зависимость вида ![]() .
.
Для расчета линейного коэффициента парной корреляции и параметров линейной регрессии составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
X×Y |
X2 |
Y2 |
|
1 |
79,8 |
64,2 |
5123,16 |
6368,04 |
4121,64 |
|
2 |
152,1 |
66,1 |
10053,81 |
23134,41 |
4369,21 |
|
3 |
199,3 |
69,0 |
13751,70 |
39720,49 |
4761,00 |
|
4 |
240,8 |
70,6 |
17000,48 |
57984,64 |
4984,36 |
|
5 |
282,4 |
72,4 |
20445,76 |
79749,76 |
5241,76 |
|
6 |
301,8 |
74,3 |
22423,74 |
91083,24 |
5520,49 |
|
7 |
385,3 |
76,0 |
29282,80 |
148456,09 |
5776,00 |
|
8 |
457,8 |
77,1 |
35296,38 |
209580,84 |
5944,41 |
|
9 |
577,4 |
78,4 |
45268,16 |
333390,76 |
6146,56 |
|
S |
2676,7 |
648,1 |
198645,99 |
989468,27 |
46865,43 |
|
Среднее |
297,41 |
72,01 |
22071,78 |
109940,92 |
5207,27 |
Вычислим коэффициент корреляции. Используем следующую формулу:

![]() = 0,9568.
= 0,9568.
Можно сказать, что между рассматриваемыми признаками существует Прямая тесная Корреляционная связь.
Среднюю ошибку коэффициента корреляции определим по формуле:
![]() = 0,032.
= 0,032.
Найдем табличное значение TТабл по таблице распределения Стьюдента для
a = 0,05 и числе степеней свободы K = N – M – 1 = 9 – 1 – 1 = 7.
TТабл(0,05; 7) = 2,36.
Запишем доверительный интервал для коэффициента корреляции.
![]()
![]()
Доверительный интервал не включает число 0, поэтому при заданном уровне значимости коэффициент корреляции является статистически значимым.
Вычислим параметры уравнения регрессии.
![]() = 0,03.
= 0,03.
![]() = 72,01 – 0,03×297,41 = 63,09.
= 72,01 – 0,03×297,41 = 63,09.
Получим следующее уравнение: ![]() .
.
Для проверки статистической значимости (существенности) линейного коэффициента парной корреляции рассчитаем T-критерий Стьюдента по формуле:
 = 23,04.
= 23,04.
Фактическое значение по абсолютной величине больше табличного, что свидетельствует о значимости линейного коэффициента корреляции и существенности связи между рассматриваемыми признаками.
Проверим значимость оценок теоретических коэффициентов регрессии с помощью t-статистики Стьюдента и сделаем соответствующие выводы о значимости этих оценок.
Для определения статистической значимости коэффициентов A и B найдем T-статистики Стьюдента:
Рассчитаем по полученному уравнению теоретические значения![]() . Составим вспомогательную таблицу.
. Составим вспомогательную таблицу.
|
№ п/п |
X |
Y |
|
|
|
|
1 |
79,8 |
64,2 |
65,48 |
1,6384 |
47354,1 |
|
2 |
152,1 |
66,1 |
67,65 |
2,4025 |
21115,0 |
|
3 |
199,3 |
69,0 |
69,07 |
0,0049 |
9625,6 |
|
4 |
240,8 |
70,6 |
70,31 |
0,0841 |
3204,7 |
|
5 |
282,4 |
72,4 |
71,56 |
0,7056 |
225,3 |
|
6 |
301,8 |
74,3 |
72,14 |
4,6656 |
19,3 |
|
7 |
385,3 |
76,0 |
74,65 |
1,8225 |
7724,7 |
|
8 |
457,8 |
77,1 |
76,82 |
0,0784 |
25725,0 |
|
9 |
577,4 |
78,4 |
80,41 |
4,0401 |
78394,4 |
|
S |
2676,7 |
648,1 |
648,09 |
15,4421 |
193388,1 |
Вычислим стандартные ошибки коэффициентов уравнения.
 = 1,2.
= 1,2.
 = 0,003.
= 0,003.
Вычислим T-статистики.
![]()
![]()
Сравнение расчетных и табличных величин критерия Стьюдента показывает, что ![]() и
и ![]() , т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
, т. е. оценки A и B теоретических коэффициентов регрессии статистически значимы.
Сделаем рисунок.

Рассчитаем коэффициент детерминации: ![]() = 0,95682= 0,915 = 91,5%.
= 0,95682= 0,915 = 91,5%.
Таким образом, вариация результата Y на 91,5% объясняется вариацией фактора X.
Оценку значимости уравнения регрессии проведем с помощью F-критерия Фишера:
 = 75,81.
= 75,81.
Найдем табличное значение Fтабл по таблице критических точек Фишера для
a = 0,05; K1 = M = 1 (число факторов), K2 = N – M – 1 = 9 – 1 – 1 = 7.
Fтабл(0,05; 1; 7) = 5,59.
Поскольку F > FТабл, уравнение регрессии с вероятностью 0,95 в целом Является статистически значимым.
Выполним прогноз доли оплаты труда структуре доходов семьи y при прогнозном значении среднедушевого денежного дохода x, составляющем 111% от среднего уровня.
XP = 297,41 × 1,11 = 330,1.
Вычислим прогнозное значение Yp с помощью уравнения регрессии.
![]() » 73%.
» 73%.
Доверительный интервал прогноза имеет вид
(УP – Tкр×My, УP + Tкр×My),
Где  , M = 2 – число параметров уравнения.
, M = 2 – число параметров уравнения.
 = 1,695 » 1,7.
= 1,695 » 1,7.
Запишем доверительный интервал прогноза:
![]() Þ
Þ ![]()
Данный прогноз является надежным, поскольку доверительный интервал не включает число 0, точность прогноза составляет 4.
Задание 2. Модель парной нелинейной регрессии.
По территориям Центрального района известны данные за 1995 г.
|
Район |
Прожиточный минимум в среднем на одного пенсионера в месяц, тыс. руб., X |
Средний размер назначенных ежемесячных пенсий, тыс. руб., Y |
|
Брянская обл. |
178 |
240 |
|
Владимирская обл. |
202 |
226 |
|
Ивановская обл. |
197 |
221 |
|
Калужская обл. |
201 |
226 |
|
Костромская обл. |
189 |
220 |
|
Орловская обл. |
166 |
232 |
|
Рязанская обл. |
199 |
215 |
|
Смоленская обл. |
180 |
220 |
|
Тверская обл. |
181 |
222 |
|
Тульская обл. |
186 |
231 |
|
Ярославская обл. |
250 |
229 |
Задания:
1. Построить поле корреляции и сформулируйте гипотезу о форме связи. Рассчитать параметры уравнений полулогарифмической (![]() ) и степенной (
) и степенной (![]() ) парной регрессии. Сделать рисунки.
) парной регрессии. Сделать рисунки.
2. Дать с помощью среднего коэффициента эластичности сравнительную оценку силы связи фактора с результатом для каждой модели. Сделать выводы. Оценить качество уравнений регрессии с помощью средней ошибки аппроксимации и коэффициента детерминации. Сделать выводы.
3. По значениям рассчитанных характеристик выбрать лучшее уравнение регрессии. Дать экономический смысл коэффициентов выбранного уравнения регрессии
4. Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости a =0,05. Сделать выводы.
Решение: Решение: Для предварительного определения вида связи между указанными признаками построим поле корреляции. Для этого построим в системе координат точки, у которых первая координата X, а вторая – Y.
Получим следующий рисунок.

По внешнему виду диаграммы рассеяния трудно предположить, какая зависимость существует между указанными показателями.
Построение полулогарифмической модели регрессии.
Уравнение логарифмической кривой: ![]() .
.
Обозначим: ![]()
Получим линейное уравнение регрессии:
Y = A + B×X.
Произведем линеаризацию модели путем замены ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Xy |
X2 |
Y2 |
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
1243,63 |
26,85 |
57600 |
226,40 |
206,314 |
184,904 |
6,006 |
|
2 |
202 |
226 |
5,3083 |
1199,67 |
28,18 |
51076 |
225,17 |
0,132 |
0,694 |
0,370 |
|
3 |
197 |
221 |
5,2832 |
1167,59 |
27,91 |
48841 |
225,41 |
21,496 |
19,464 |
1,957 |
|
4 |
201 |
226 |
5,3033 |
1198,55 |
28,13 |
51076 |
225,22 |
0,132 |
0,615 |
0,348 |
|
5 |
189 |
220 |
5,2417 |
1153,18 |
27,48 |
48400 |
225,82 |
31,769 |
33,833 |
2,576 |
|
6 |
166 |
232 |
5,1120 |
1185,98 |
26,13 |
53824 |
227,08 |
40,496 |
24,172 |
2,165 |
|
7 |
199 |
215 |
5,2933 |
1138,06 |
28,02 |
46225 |
225,31 |
113,132 |
106,362 |
4,577 |
|
8 |
180 |
220 |
5,1930 |
1142,45 |
26,97 |
48400 |
226,29 |
31,769 |
39,601 |
2,781 |
|
9 |
181 |
222 |
5,1985 |
1154,07 |
27,02 |
49284 |
226,24 |
13,223 |
17,968 |
1,874 |
|
10 |
186 |
231 |
5,2257 |
1207,15 |
27,31 |
53361 |
225,97 |
28,769 |
25,273 |
2,225 |
|
11 |
250 |
229 |
5,5215 |
1264,41 |
30,49 |
52441 |
223,09 |
11,314 |
34,980 |
2,651 |
|
Итого |
2129 |
2482 |
57,862 |
13054,74 |
304,48 |
560528 |
2482,00 |
498,545 |
487,867 |
27,530 |
|
Среднее |
193,5 |
225,6 |
5,260 |
1186,79 |
27,68 |
50957,091 |
225,636 |
45,322 |
44,352 |
2,503 |
![]() = -9,76.
= -9,76.
![]() = 225,6 – (-9,76)×5,26 = 276,99.
= 225,6 – (-9,76)×5,26 = 276,99.
Уравнение модели имеет вид: ![]()
Определим индекс корреляции 
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,14642= 0,021 = 2,1%.
= 0,14642= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Рассчитаем средний коэффициент эластичности по формуле:
![]() = -0,04%.
= -0,04%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,04%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Построение степенной модели парной регрессии.
Уравнение степенной модели имеет вид: ![]() .
.
Для построения этой модели необходимо произвести линеаризацию переменных. Для этого произведем логарифмирование обеих частей уравнения:
![]() .
.
Произведем линеаризацию модели путем замены ![]() и
и ![]() . В результате получим линейное уравнение
. В результате получим линейное уравнение ![]() .
.
Рассчитаем его параметры, используя данные таблицы.
|
№ п/п |
X |
Y |
X = ln(X) |
Y = ln(Y) |
XY |
X2 |
Y2 |
|
|
|
|
Ai |
|
1 |
178 |
240 |
5,1818 |
5,4806 |
28,3995 |
26,851 |
30,037 |
226,3 |
206,3 |
188,391 |
241,661 |
6,07 |
|
2 |
202 |
226 |
5,3083 |
5,4205 |
28,7737 |
28,178 |
29,382 |
225,1 |
0,132 |
0,835 |
71,479 |
0,406 |
|
3 |
197 |
221 |
5,2832 |
5,3982 |
28,5196 |
27,912 |
29,140 |
225,3 |
21,496 |
18,671 |
11,934 |
1,918 |
|
4 |
201 |
226 |
5,3033 |
5,4205 |
28,7467 |
28,125 |
29,382 |
225,1 |
0,132 |
0,753 |
55,570 |
0,385 |
|
5 |
189 |
220 |
5,2417 |
5,3936 |
28,2720 |
27,476 |
29,091 |
225,7 |
31,769 |
32,607 |
20,661 |
2,530 |
|
6 |
166 |
232 |
5,1120 |
5,4467 |
27,8437 |
26,132 |
29,667 |
226,9 |
40,496 |
25,675 |
758,752 |
2,233 |
|
7 |
199 |
215 |
5,2933 |
5,3706 |
28,4284 |
28,019 |
28,844 |
225,2 |
113,132 |
104,576 |
29,752 |
4,540 |
|
8 |
180 |
220 |
5,1930 |
5,3936 |
28,0089 |
26,967 |
29,091 |
226,2 |
31,769 |
38,059 |
183,479 |
2,728 |
|
9 |
181 |
222 |
5,1985 |
5,4027 |
28,0858 |
27,024 |
29,189 |
226,1 |
13,223 |
16,950 |
157,388 |
1,821 |
|
10 |
186 |
231 |
5,2257 |
5,4424 |
28,4407 |
27,308 |
29,620 |
225,9 |
28,769 |
26,413 |
56,934 |
2,275 |
|
11 |
250 |
229 |
5,5215 |
5,4337 |
30,0021 |
30,487 |
29,525 |
223,1 |
11,314 |
34,846 |
3187,116 |
2,646 |
|
Итого |
2129 |
2482 |
57,862 |
59,603 |
313,521 |
304,479 |
322,969 |
2480,927 |
498,545 |
487,777 |
4774,727 |
27,548 |
|
Среднее |
193,5 |
225,6 |
5,260 |
5,418 |
28,502 |
27,680 |
29,361 |
225,539 |
45,322 |
44,343 |
434,066 |
2,504 |
С учетом введенных обозначений уравнение примет вид: Y = A + BX – линейное уравнение регрессии. Рассчитаем его параметры, используя данные таблицы.
![]() = -0,042.
= -0,042.
![]() = 5,418 – 0,959×5,26 = 5,637.
= 5,418 – 0,959×5,26 = 5,637.
Перейдем к исходным переменным X и Y, выполнив потенцирование данного уравнения.
A = eA = e5,637 = 280,76
Получим уравнение степенной модели регрессии: ![]() .
.
Определим индекс корреляции
Используя данные таблицы, получим:
 .
.
Рассчитаем коэффициент детерминации: ![]() = 0,1472= 0,021 = 2,1%.
= 0,1472= 0,021 = 2,1%.
Вариация результата Y всего на 2,1% объясняется вариацией фактора X.
Сделаем рисунок.

Для степенной модели средний коэффициент эластичности равен коэффициенту B.
![]() = -0,042%.
= -0,042%.
Коэффициент эластичности ![]() показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
показывает, что при среднем росте признака X на 1% признак Y снижается на 0,042%.
Вычислим среднюю ошибку аппроксимации. Используя данные расчетной таблицы, получаем:
![]() = 2,5%.
= 2,5%.
Сводная таблица вычислений
|
Параметры |
Модель |
|
|
Полулогарифмическая |
Степенная |
|
|
Уравнение связи |
|
|
|
Индекс корреляции |
0,1464 |
0,147 |
|
Коэффициент детерминации |
0,021 |
0,021 |
|
Средняя ошибка аппроксимации, % |
2,5 |
2,5 |
Для выявления формы связи между указанными признаками были построены полулогарифмическая и степенная модели регрессии. Анализ показателей корреляции, а также оценка качества моделей с использованием средней ошибки аппроксимации позволил предположить, что из перечисленных моделей более адекватной является степенная модель, поскольку для нее индекс корреляции принимает наибольшее значение R = 0,147, свидетельствующий о том, что между рассматриваемыми признаками наблюдается Слабая корреляционная связь.
Рассчитаем прогнозное значение результата по степенной модели регрессии, если прогнозируется увеличение значения фактора на 10% от среднего уровня.
Прогнозное значение составит:
![]() = 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
= 193,5 × 1,1 = 212,9 тыс. р., тогда прогнозное значение Y составит:
![]() = 224,6 тыс. р.
= 224,6 тыс. р.
Определим доверительный интервал прогноза для уровня значимости a = 0,05.
Вычислим Среднюю стандартную ошибку прогноза ![]() По следующей формуле:
По следующей формуле:
 , где
, где ![]()
Получаем:  = 7,55.
= 7,55.
Найдем предельную ошибку прогноза ![]() , где для доверительной вероятности 0,95 значение T составляет 1,96.
, где для доверительной вероятности 0,95 значение T составляет 1,96.
![]() = 14,8.
= 14,8.
Запишем доверительный интервал прогноза.
![]() = 224,6 – 14,8 = 209,8 тыс. р.
= 224,6 – 14,8 = 209,8 тыс. р.
![]() = 224,6 + 14,8 = 239,4 тыс. р.
= 224,6 + 14,8 = 239,4 тыс. р.
Таким образом, с вероятностью 0,95 можно утверждать, что прогнозное значение среднего размера назначенных ежемесячных пенсий будет находиться в пределах от 209,8 тыс. р. до 239,4 тыс. р.
Задание 3. Моделирование временных рядов
Имеются поквартальные данные по розничному товарообороту России в 1995-1999 гг.
|
Номер квартала |
Товарооборот % к предыдущему периоду |
Номер квартала |
Товарооборот % к предыдущему периоду |
|
1 |
100 |
11 |
98,8 |
|
2 |
93,9 |
12 |
101,9 |
|
3 |
96,5 |
13 |
113,1 |
|
4 |
101,8 |
14 |
98,4 |
|
5 |
107,8 |
15 |
97,3 |
|
6 |
96,3 |
16 |
112,1 |
|
7 |
95,7 |
17 |
97,6 |
|
8 |
98,2 |
18 |
93,7 |
|
9 |
104 |
19 |
114,3 |
|
10 |
99 |
20 |
108,4 |
Задания:
1. Построить график данного временного ряда. Охарактеризовать структуру этого ряда.
2. Рассчитать сезонную компоненты временного ряда и построить его Мультипликативную Модель.
3. Рассчитать трендовую компоненту временного ряда и построить его график
4. Оценить качество модели через показатели средней абсолютной ошибки и среднего относительного отклонения.
Решение: Пронумеруем указанные месяцы от 1 до 24 и построим график временного ряда.

Полученный график показывает, что а данном временном ряду присутствуют сезонные колебания.
Построим мультипликативную модель временного ряда.
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T), сезонной (S) и случайной (E) компонент.
Построение мультипликативной моделей сведем к расчету значений T, S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1) Выравнивание исходного ряда методом скользящей средней.
2) Расчет значений сезонной компоненты S.
3) Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных T×E.
4) Аналитическое выравнивание уровней T×E и расчет значений T с использованием полученного уравнения тренда.
5) Расчет полученных по модели значений T×E.
6) Расчет абсолютных и/или относительных ошибок.
Шаг 1. Проведем выравнивание исходных уровней ряда методом скользящей средней. Для этого:
1.1. Просуммируем уровни ряда последовательно за каждые четыре месяца со сдвигом на один момент времени и определим условные годовые уровни объема продаж (гр. 3 табл. 2.1).
1.2. Разделив полученные суммы на 4, найдем скользящие средние (гр. 4 табл. 2.1). Полученные таким образом выровненные значения уже не содержат сезонной компоненты.
1.3. Приведем эти значения в соответствие с фактическими моментами времени, для чего найдем средние значения из двух последовательных скользящих средних – центрированные скользящие средние (гр. 5 табл. 2.1).
Таблица 2.1
|
№ месяца, T |
Товарооборот, Yi |
Итого за четыре месяца |
Скользящая средняя за четыре месяца |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
100,0 |
– |
– |
– |
– |
|
2 |
93,9 |
392 |
98 |
– |
– |
|
3 |
96,5 |
400 |
100 |
99 |
0,975 |
|
4 |
101,8 |
402 |
100,5 |
100,25 |
1,015 |
|
5 |
107,8 |
402 |
100,5 |
100,5 |
1,073 |
|
6 |
96,3 |
398 |
99,5 |
100 |
0,963 |
|
7 |
95,7 |
394 |
98,5 |
99 |
0,967 |
|
8 |
98,2 |
397 |
99,25 |
98,875 |
0,993 |
|
9 |
104,0 |
400 |
100 |
99,625 |
1,044 |
|
10 |
99,0 |
404 |
101 |
100,5 |
0,985 |
|
11 |
98,8 |
413 |
103,25 |
102,125 |
0,967 |
|
12 |
101,9 |
412 |
103 |
103,125 |
0,988 |
|
13 |
113,1 |
411 |
102,75 |
102,875 |
1,099 |
|
14 |
98,4 |
309 |
77,25 |
90 |
1,093 |
|
15 |
97,3 |
196 |
49 |
63,125 |
1,541 |
|
16 |
112,1 |
303 |
75,75 |
62,375 |
1,797 |
|
17 |
97,6 |
418 |
104,5 |
90,125 |
1,083 |
|
18 |
93,7 |
414 |
103,5 |
104 |
0,901 |
|
19 |
114,3 |
– |
– |
– |
– |
|
20 |
108,4 |
– |
– |
– |
– |
Шаг 2. Найдем оценки сезонной компоненты как частное от деления фактических уровней ряда на центрированные скользящие средние (гр. 6 табл. 2.1). Эти оценки используются для расчета сезонной компоненты S (табл. 2.2). Для этого найдем средние за каждый месяц оценки сезонной компоненты Si. Так же как и в аддитивной модели считается, что сезонные воздействия за период взаимопогашаются. В мультипликативной модели это выражается в том, что сумма значений сезонной компоненты по всем месяцам должна быть равна числу периодов в цикле. В нашем случае число периодов одного цикла равно 4.
Таблица 2.2
|
Показатели |
Год |
№ квартала, I |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
0,975 |
1,015 |
|
|
2 |
1,073 |
0,963 |
0,967 |
0,993 |
|
|
3 |
1,044 |
0,985 |
0,967 |
0,988 |
|
|
4 |
1,099 |
1,093 |
1,541 |
1,797 |
|
|
5 |
1,083 |
0,901 |
– |
– |
|
|
Всего за I-й квартал |
4,299 |
3,942 |
4,45 |
4,793 |
|
|
Средняя оценка сезонной компоненты для I-го квартала, |
0,860 |
0,788 |
0,890 |
0,959 |
|
|
Скорректированная сезонная компонента, |
0,984 |
0,901 |
1,018 |
1,097 |
Имеем: 0,860 + 0,788 + 0,890 + 0,959 = 3,497.
Определяем корректирующий коэффициент: K = 4 : 3,497 = 1,144.
Скорректированные значения сезонной компоненты ![]() получаются при умножении ее средней оценки
получаются при умножении ее средней оценки ![]() на корректирующий коэффициент K.
на корректирующий коэффициент K.
Проверяем условие: равенство 4 суммы значений сезонной компоненты:
0,984 + 0,901 + 1,018 + 1,097 = 4.
Шаг 3. Разделим каждый уровень исходного ряда на соответствующие значения сезонной компоненты. В результате получим величины ![]() (гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
(гр. 4 табл. 2.3), которые содержат только тенденцию и случайную компоненту.
Таблица 2.3
|
T |
Yt |
St |
|
T |
T×S |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
100,0 |
0,984 |
101,6 |
100,02 |
98,42 |
1,016 |
|
2 |
93,9 |
0,901 |
104,2 |
100,19 |
90,27 |
1,040 |
|
3 |
96,5 |
1,018 |
94,8 |
100,36 |
102,17 |
0,945 |
|
4 |
101,8 |
1,097 |
92,8 |
100,53 |
110,28 |
0,923 |
|
5 |
107,8 |
0,984 |
109,6 |
100,7 |
99,09 |
1,088 |
|
6 |
96,3 |
0,901 |
106,9 |
100,87 |
90,88 |
1,060 |
|
7 |
95,7 |
1,018 |
94,0 |
101,04 |
102,86 |
0,930 |
|
8 |
98,2 |
1,097 |
89,5 |
101,21 |
111,03 |
0,884 |
|
9 |
104,0 |
0,984 |
105,7 |
101,38 |
99,76 |
1,043 |
|
10 |
99,0 |
0,901 |
109,9 |
101,55 |
91,50 |
1,082 |
|
11 |
98,8 |
1,018 |
97,1 |
101,72 |
103,55 |
0,954 |
|
12 |
101,9 |
1,097 |
92,9 |
101,89 |
111,77 |
0,912 |
|
13 |
113,1 |
0,984 |
114,9 |
102,06 |
100,43 |
1,126 |
|
14 |
98,4 |
0,901 |
109,2 |
102,23 |
92,11 |
1,068 |
|
15 |
97,3 |
1,018 |
95,6 |
102,4 |
104,24 |
0,933 |
|
16 |
112,1 |
1,097 |
102,2 |
102,57 |
112,52 |
0,996 |
|
17 |
97,6 |
0,984 |
99,2 |
102,74 |
101,10 |
0,965 |
|
18 |
93,7 |
0,901 |
104,0 |
102,91 |
92,72 |
1,011 |
|
19 |
114,3 |
1,018 |
112,3 |
103,08 |
104,94 |
1,089 |
|
20 |
108,4 |
1,097 |
98,8 |
103,25 |
113,27 |
0,957 |
|
Среднее |
101,4 |
1,0011 |
Шаг 4. Определим компоненту T в мультипликативной модели. Для этого рассчитаем параметры линейного тренда, используя уровни T×E. Составим вспомогательную таблицу.
Таблица 2.4
|
T |
|
T2 |
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
1 |
101,6 |
1 |
101,6 |
2,5 |
1,58 |
2,0 |
|
|
2 |
104,2 |
4 |
208,4 |
13,2 |
3,87 |
56,3 |
|
|
3 |
94,8 |
9 |
284,4 |
32,1 |
5,88 |
24,0 |
|
|
4 |
92,8 |
16 |
371,2 |
71,9 |
8,33 |
0,2 |
|
|
5 |
109,6 |
25 |
548 |
75,9 |
8,08 |
41,0 |
|
|
6 |
106,9 |
36 |
641,4 |
29,4 |
5,63 |
26,0 |
|
|
7 |
94,0 |
49 |
658 |
51,3 |
7,48 |
32,5 |
|
|
8 |
89,5 |
64 |
716 |
164,6 |
13,07 |
10,2 |
|
|
9 |
105,7 |
81 |
951,3 |
18,0 |
4,08 |
6,8 |
|
|
10 |
109,9 |
100 |
1099 |
56,3 |
7,58 |
5,8 |
|
|
11 |
97,1 |
121 |
1068,1 |
22,6 |
4,81 |
6,8 |
|
|
12 |
92,9 |
144 |
1114,8 |
97,4 |
9,69 |
0,3 |
|
|
13 |
114,9 |
169 |
1493,7 |
160,5 |
11,20 |
136,9 |
|
|
14 |
109,2 |
196 |
1528,8 |
39,6 |
6,39 |
9,0 |
|
|
15 |
95,6 |
225 |
1434 |
48,2 |
7,13 |
16,8 |
|
|
20 |
102,2 |
400 |
2044 |
0,2 |
0,37 |
114,5 |
|
|
21 |
99,2 |
441 |
2083,2 |
12,3 |
3,59 |
14,4 |
|
|
22 |
104,0 |
484 |
2288 |
1,0 |
1,05 |
59,3 |
|
|
23 |
112,3 |
529 |
2582,9 |
87,6 |
8,19 |
166,4 |
|
|
24 |
98,8 |
576 |
2371,2 |
23,7 |
4,49 |
49,0 |
|
|
Сумма |
230 |
2035,2 |
3670 |
23588 |
1008,3 |
122,49 |
778,2 |
|
Среднее |
11,5 |
101,8 |
183,5 |
1179,4 |
50,4 |
6,12 |
38,91 |
Вычислим параметры уравнения тренда.
 = 0,17.
= 0,17.
![]() = 99,85.
= 99,85.
В результате получим уравнение тренда:
T = 99,85 + 0,17×T.
Подставляя в это уравнение значения T = 1,2,…,16, найдем уровни T для каждого момента времени (гр. 5 табл. 2.3).
Шаг 5. Найдем уровни ряда, умножив значения T на соответствующие значения сезонной компоненты (гр. 6 табл. 2.3). На одном графике откладываем фактические значения уровней временного ряда и теоретические, полученные по мультипликативной модели.

Расчет ошибки в мультипликативной модели произведем по формуле:
![]()
Средняя абсолютная ошибка составила 1,0011 (см. гр. 7 табл. 2.3).
Рассчитаем сумму квадратов абсолютных ошибок ![]() .
.
Используя 5-й столбец таблицы 2.4, получим:
 = 7,099.
= 7,099.
Рассчитаем среднюю относительную ошибку: ![]() .
.
Используя 6-й столбец таблицы 2.4, получим, что средняя относительная ошибка составила 6,12%, т. е. построенная модель достаточно точно описывает динамику данного явления.
| < Предыдущая | Следующая > |
|---|
Формализованными
называют
методы прогнозирования, которые
используют математическое описание
выявленных закономерностей в развитии
объекта для получения прогноза.
Фактографические
методы прогнозирования используют
в качестве источника информации
действительно свершившиеся факты,
которые зафиксированы на каком-либо
носителе информации с помощью
количественных или качественных
характеристик.
Статистические
методы прогнозирования,
основанные на выявленных в прошлом
закономерностях развития объекта и
предположениях об инерционном развитии
объекта в будущем на основе выявленных
математических закономерностей изменения
характеристик данного объекта с целью
получения прогнозных моделей.
Методы обработки
совокупностей включают осреднение
параметров одногодичных уравнений
регрессии, ковариационный анализ и др.
Имитационное
моделирование,
применяемое для анализа и прогнозирования
развития сложных систем, в которых
конечный результат зависит от множества
параметров. Дают возможность, анализируя
промежуточные результаты, менять в
процессе моделирования управляющие
параметры.
Историко-логический
анализ основан
на исследовании исторических аналогий
в развитии разных объектов или одного
объекта в разные периоды времени.
Методы
аналогий основаны
на выявлении сходства, общих черт в
закономерностях развития различных
процессов. К ним относятся методы
математических и исторических аналогий.
Опережающие
методы прогнозирования основаны
на определенных принципах специальной
обработки информации, учитывающих
ее свойство опережать практическое
применение инноваций. К ним относятся
методы исследования динамики
научно-технической информации,
использующие построение динамических
рядов на базе различных видов такой
информации, анализа и прогнозирования
на этой основе развития соответствующего
объекта (например, метод огибающих,
патентный метод).
Результат
прогноза, разработанного формализованным
методом, чаще всего выражается
количественным показателем, которому
может быть дана точечная (![]() )
)
и (или) интервальная оценка (![]() ).
).
Точечная
оценка (![]() )
)
– это единичная оценка прогнозного
параметра. Прогноз должен быть дан в
виде интервала значений.
Интервальная
оценка (![]() )
)
– это числовой интервал (доверительный
интервал), в котором, вероятно, находится
прогнозный параметр.
Точность
прогноза
тем выше, чем меньше величина ошибки,
которая представляет собой разность
между прогнозируемыми и фактическими
значениями исследуемой величины.
Математическая
вероятность (Рi)
случайной величины равна отношению
числа событий, благоприятствующих ее
появлению (т.е. свершению прогноза) к
общему числу событий (благоприятных и
неблагоприятных). Численное значение
вероятности прогноза лежит в пределах
от 0 до 1.
Границы доверительного
интервала можно задать такими широкими,
что прогнозируемое значение попадет
туда с любой вероятностью, включая Р =
0 и Р = 1. Такой прогноз называется абсолютно
достоверным. Однако границы доверительного
интервала будут столь широкими, что
полученный прогноз не будет иметь
практической ценности для принятия
управленческих решений. На практике
достаточно иметь вероятность прогноза
0,7-0,95.
Под
достоверностью
прогноза
понимается вероятность осуществления
прогноза в заданном доверительном
интервале
![]() .
.
Неформально
доверительный интервал может быть
определен экспертами с учетом степени
изменчивости фактических значений
показателей вокруг расчетных
(теоретических) значений в прошлом и
возможности деформации в будущем.
Суммарная ошибка решения прогнозной
задачи определяется по формуле
![]() , (3.1)
, (3.1)
где ![]() – суммарная ошибка;
– суммарная ошибка;
![]() –ошибки
–ошибки
информации, обусловленные неадекватностью
описания объекта, погрешностями
получения и обработки информации;
![]() –ошибки
–ошибки
метода прогнозирования, вызванные
невозможностью идеального выбора
метода для данного объекта, а также
обязательной схематичностью метода;
![]() –ошибки
–ошибки
вычислительных процедур;
![]() –ошибки,
–ошибки,
допущенные человеком и обусловленные
субъективными факторами (низкая
квалификация, восторженность, пессимизм);
![]() –нерегулярная
–нерегулярная
составляющая ошибки, обусловленная
возможностью появления непредсказуемых
изменений в объекте.
Формально границы
доверительного интервала можно определить
на основе оценки изменчивости уровней
ряда. Чем выше эта изменчивость, тем
менее точной может быть расчетная
величина и тем шире должен быть
доверительный интервал при одной и той
же вероятности прогноза.
Получая
прогнозный результат в виде точечного
значения
![]() ,
,
необходимо указать и возможную величину
ошибки![]() ,
,
т.е. перейти к интервальному прогнозу
по формуле:
![]() , (3.2)
, (3.2)
где ![]() – точечное значение прогнозной
– точечное значение прогнозной
характеристики;
![]() –интервальное
–интервальное
значение прогнозной характеристики;
![]() –вероятная
–вероятная
ошибка прогноза.
Для определения
границ доверительного интервала
используется выражение
![]() , (3.3).
, (3.3).
где ![]() – среднеквадратическое отклонение;
– среднеквадратическое отклонение;
![]() –критерий
–критерий
Стьюдента.
Величина
среднеквадратического отклонения
рассчитывается по формуле
![]() , (3.4):
, (3.4):
где ![]() – фактическое значение исследуемой
– фактическое значение исследуемой
характеристики на участке ретроспекции;
![]() –расчетное
–расчетное
значение исследуемой характеристики
на участке ретроспекции;
n
– число наблюдений (размер выборки).
Величина
![]() определяет минимальную ошибку прогноза.
определяет минимальную ошибку прогноза.
![]() –критерий
–критерий
Стьюдента, значение которого зависит
от размера выборочной совокупности и
заданной вероятности прогноза,
использование этого коэффициента
определяется ограниченностью выборки.
Критерий Стьюдента — чем выше заданная
вероятность прогноза и чем меньше размер
выборки, тем шире должны быть границы
доверительного интервала.
После наступления
прогнозируемого события ошибка прогноза
определяется как разность между
фактическим и прогнозным значением
показателя. Ошибка прогноза или
погрешность для каждого момента времени,
в котором рассматривается прогноз:
![]() , (3.5)
, (3.5)
где ![]() –
–
ошибка прогноза в момент времениt;
![]() –фактическое
–фактическое
значение в момент времени t;
![]() –прогнозное
–прогнозное
значение в момент времени t.
Способы оценки
средней ошибки прогноза (погрешности):
■ среднее
абсолютное отклонение (mean
absolute
derivation,
MAD).
Использование этого показателя имеет
смысл, когда исследователю необходимо
оценить ошибку в тех же единицах, что и
исходный ряд:
![]() ; (3.6)
; (3.6)
■ средняя
процентная ошибка (mean
percentage
error,
MPE)
позволяет оценить возможное смещение
прогноза, когда полученный прогноз
окажется завышенным или заниженным).
При несмещенном прогнозе имеем
величину ошибки, близкую к нулю, при
завышенном – большое положительное
процентное значение, при заниженном –
большое отрицательное:
![]() ; (3.7)
; (3.7)
■ средняя
абсолютная ошибка в процентах (mean
absolute
percentage
error,
МАРЕ):
![]() . (3.8)
. (3.8)
Модели динамики
данных:
Горизонтальную
модель используют,
если наблюдения колеблются относительно
постоянного уровня или среднего значения,
в этом случае временной ряд называют
стационарным. Внешние воздействия
относительно постоянны. Прогнозирование
включает использование его предыстории
для оценки среднего значения, которое
становится прогнозным. Используют
методы наивного прогнозирования,
простого среднего, скользящего среднего,
простое экспоненциальное сглаживание.
Трендовая
модель применяется,
если значения временного ряда возрастают
или убывают в течение некоторого,
достаточно большого промежутка времени.
Методы прогнозирования должны дать
возможность выявить закономерность
и рассчитать параметры средней
теоретической линии развития объекта.
Оперируют методами прогнозной
экстраполяции, методы скользящей средней
и линейного экспоненциального
сглаживания.
Сезонная
модель используется,
если на данные наблюдений влияют сезонные
факторы. В прогнозировании могут быть
использованы модели экстраполяции
с аддитивной и мультипликативной
компонентой.
Циклическая
модель применяется,
если данные характеризуются подъемами
и спадами, не зависящими от времени.
Циклическая компонента обычно имеет
причиной общие закономерности
экономического развития (жизненный
цикл продукции, деловой цикл, бизнес-цикл).
Методы прогнозирования – классическое
разложение, экономические индикаторы,
эконометрические модели, многомерная
регрессия.
Временной
(или динамический) ряд – это упорядоченная
вся времени совокупность измерений
одной из характеристик исследуемого
объекта (![]() ),t
),t
– порядковый номер анализируемого
периода.
Интервальный
временной ряд –
это совокупность показателей, каждый
из которых характеризует развитие
объекта исследования за определенный
период времени (год, квартал, месяц,
сутки и т.п.).
Моментный
временной ряд –
это совокупность показателей
характеризующих состояние объекта на
определенную дату.
Наивное
прогнозирование основано
на предположении, что предыдущее
значение лучше всего предсказывает
будущее.
Первый
вариант.
Прогнозное значение принимается равным
предыдущему фактическому значению,
такой прогноз называют прогнозом
без изменений:
![]() , (3.9)
, (3.9)
где ![]() – прогнозное значение в момент времениt;
– прогнозное значение в момент времениt;
![]() –фактическое
–фактическое
значение в момент времени t
— 1.
Второй
вариант.
Наивный прогноз, который можно получить
учитывая последние абсолютные или
относительные изменения показателей.
Он применяется, если значения фактических
величин изменяются во времени.
Методы
простых средних.
Прогнозное значение рассчитывается на
основе обобщенных средних характеристик
временного ряда в ретроспективном
периоде. К средним характеристикам
динамики относятся: средний уровень
ряда, или средняя хронологическая;
средний абсолютный прирост; средний
темп роста; средний темп прироста.
Показатель
рассчитывается различно для
интервальных и моментных рядов.
Для
интервального
ряда сумма
значений фактических показателей
временного ряда делится на число
показателей:
 . (3.10)
. (3.10)
Для
моментного
ряда расчет
осуществляется по формуле (3.11). Следует
учесть, что значения первого и последнего
показателей временного ряда берутся
в половинном размере, поэтому в знаменателе
количество показателей уменьшается на
единицу.
 . (3.11)
. (3.11)
Средний
абсолютный прирост ряда показывает
скорость развития явления и
рассчитывается по формуле
![]() , (3.12)
, (3.12)
где ![]() – первый зарегистрированный показатель
– первый зарегистрированный показатель
временного ряда;
y
– последний зарегистрированный
показатель временного ряда;
n
– число показателей временного ряда.
Средний
темп роста может
быть рассчитан по формуле средней
геометрической, при сравнении последнего
показателя временного ряда с первым
расчет осуществляется по формуле
![]() . (3.13)
. (3.13)
Средний
темп прироста определяется
по формуле
![]() . (3.14)
. (3.14)
Метод
простого скользящего среднего.
Прогноз строится с учетом не всех
наблюдений, а определенного количества
последних наблюдений. Как только новое
наблюдение становится доступным, оно
включается в расчетную формулу (3.15), а
наиболее старое исключается. Скользящее
среднее порядка
k
– это среднее значение k
последовательных наблюдений:
![]() , (3.15)
, (3.15)
где t
– количество измерений;
![]() –значение
–значение
исследуемой характеристики в текущем
периоде;
![]() –прогнозное
–прогнозное
значение исследуемой характеристики
на следующий период;
k
– количество наблюдений в скользящем
среднем.
Величина
k
может принимать произвольно выбранное
значения (3, 4, 5 и т.д.). Величина k
зависит от размера изучаемой совокупности,
чем большее количество наблюдений
анализируется, тем большее значение
она может принимать.
Метод
двойного скользящего среднего. Временной
ряд сглаживается методом простого
скользящего среднего, а потом повторяется
процедура усреднения для рассчитанных
значений.
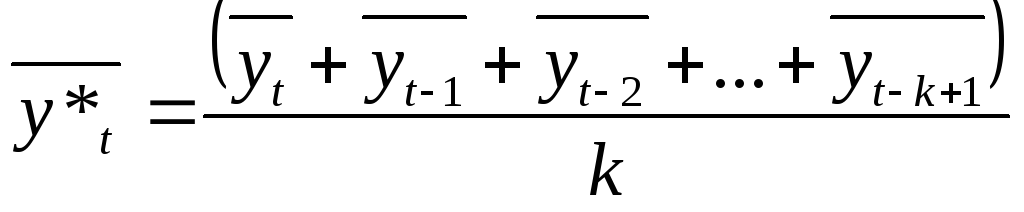 , (3.16)
, (3.16)
где ![]() – вторичное скользящее среднее.
– вторичное скользящее среднее.
Для
построения прогноза рассчитываются
сумма первичного скользящего среднего
и разницы между первичным и вторичным
скользящим средним
![]() (3.17) и коэффициент корректировки
(3.17) и коэффициент корректировки![]() :
:
 ; (3.17)
; (3.17)
 . (3.18)
. (3.18)
Прогнозное значение
пар периодов вперед определяется по
формуле
![]() . (3.19)
. (3.19)
Экстраполяция
– метод
прогнозирования, основанный на анализе
динамики объекта прогнозирования в
ретроспективном периоде. Метод
экстраполяции позволяет описать функцию,
характеризующую движение исследуемой
характеристики.
В процессе
экстраполяции определяют временной
ряд, тренд и случайную компоненту.
Формула временного ряда:
![]() . (3.20)
. (3.20)
Тренд
(эволюаторная составляющая, вековая
тенденция) – средняя линия движения
прогнозируемой характеристики (![]() ).
).
Случайная
компонента характеризует случайные
отклонения фактических показателей
динамики объекта от средней линии (![]() ).
).
Объективным
критерием оценки целесообразности
сглаживания может быть величина
абсолютного отклонения сглаженных
значений от фактических:
![]() , (3.21)
, (3.21)
где ![]() – положительное число, выбираемое из
– положительное число, выбираемое из
соображений точности представления
данных и точности последующих алгоритмов
обработки.
Выбор функции,
применяемой для описания явления,
зависит от типа динамики процесса. В
приложении 3 приведены основные
элементарные функции прогнозной
экстраполяции.
В социально-экономическом
прогнозировании экстраполяция применяется
для следующих типов динамики.
1. Равномерное
развитие, под которым понимают
экономический рост с постоянным
абсолютным приростом. Эта динамика
может быть описана линейной функцией
![]() , (3.22)
, (3.22)
где а
– теоретическое значение yt
в точке отсчета, t
– 0;
b
– коэффициент регрессии, определяющий
направление развития исследуемой
характеристики (если b
> 0, показатели
временного ряда равномерно возрастают,
если b
< 0, показатели
временного ряда равномерно убывают,
если b
= 0, показатели
временного ряда неизменны во времени).
2. Равноускоренное
(равнозамедленное) развитие — экономический
рост с постоянными темпами прироста.
Данный тип динамики может быть описан
функцией параболы второго порядка,
показательной или экспоненциальной
функциями. Уравнение параболической
функции имеет следующий вид:
![]() , (3.23)
, (3.23)
где с
– постоянное изменение интенсивности
развития (в единицу времени).
Если
с >
0, то для процесса характерно ускорение
динамики, если с
< 0 –
замедление. При этом параметр b
может принимать положительные или
отрицательные значения.
3. Развитие с
переменным ускорением (замедлением) —
экономический рост со стабильно
изменяющимися темпами прироста. Динамика
может быть описана кубической параболой:
![]() , (3.24)
, (3.24)
Для нахождения
параметров функции решаются определенные
системы уравнений, которые приведены
в приложении 4.
Экстраполяция на
основе полученных функций дает возможность
получить точечное прогнозное значение.
Следующий этап – переход от точечного
прогноза к интервальному:
![]() , (3.25)
, (3.25)
где ![]() –
–
интервальное значение прогнозной
характеристики в момент времениt;
![]() –точечное
–точечное
значение прогнозной характеристики в
момент времени t;
![]() –ошибка
–ошибка
прогноза.
Расширение границ
доверительного интервала при линейном
тренде, вследствие дисконтирования
прогнозной информации, учитывается
коэффициентом:
![]() , (3.26)
, (3.26)
где l
– безразмерный интервал периода
упреждения прогноза;
n
– число наблюдений на участке
ретроспекции.
Длина интервала
периода упреждения прогноза численно
равна временному шагу между ретроспективными
значениями.
Формула расчета
границ доверительного интервала
примет следующий вид:
![]() .
.
(3.27)
Для выяснения
закономерностей необходимо получить
надежно повторяемые и достаточно
достоверные многократные совпадения
ожидаемых величин и фактических значений.
Исследование динамики экономических
показателей может привести к открытию
новых зависимостей, которые не всегда
очевидны и доступны для других методов.
Под
сезонностью
понимается устойчивая, повторяющаяся
во времени периодичность в развитии
экономических явлений. Исследовать
влияние сезонности можно по временным
рядам, содержащим информацию о значениях
показателя по кварталам, месяцам, недели,
дням, времени суток или часам.
В процессе
прогнозирования сезонных изменений
каждый уровень временного ряда можно
представить как результат взаимодействия
трендовой, сезонной и случайной компонент.
Модель
с аддитивной компонентой
строится путем сложения составляющих.
Уравнение временного ряда с учетом
сезонных колебаний может быть
представлено формулой:
![]() , (3.28)
, (3.28)
где ![]() – сезонная компонента;
– сезонная компонента;
L
– номер сезона.
Модель с аддитивной
компонентой целесообразно использовать,
если среднегодовые значения показателя
остаются неизменными на протяжении
длительного периода.
Модель
с мультипликативной компонентой
строится путем перемножения трендовой
составляющей и индекса сезонности (![]() )
)
, соответственно, уравнение временного
ряда может быть представлено формулой
![]() .
.
(3.29)
Этапы
построения прогнозной модели
с аддитивной компонентой:
построение и визуальный анализ графика
сезонной волны; расчет значений сезонной
компоненты; десезонализация данных,
т.е. вычитание сезонной компоненты из
фактических значений; расчет тренда на
основе полученных десезонализированньи
данных; оценка ошибки для оценки степени
соответствия модели исходным данным,
расчет среднеквадратического отклонения;
построение прогноза с учетом сезонных
колебаний.
Последовательность
этапов построение модели с
мультипликативной компонентой
(первый способ): расчет значений индекса
сезонности; десезонализация данных,
т.е. деление фактических значений на
индекс сезонности; расчет параметров
тренда для полученных десезонализированных
данных; оценка ошибки для оценки степени
соответствия модели исходным данным;
расчет среднеквадратического отклонения;
построение прогноза с учетом сезонных
колебаний.
Последовательность
этапов построение модели с
мультипликативной компонентой (второй
способ): определение вида тренда и расчет
параметров тренда без учета сезонных
колебаний; построение и визуальный
анализ графика сезонной волны; расчет
индексов сезонности.
Формула индекса
сезонности, определенного по средней
арифметической, будет иметь следующий
вид:
![]() , (3.30)
, (3.30)
где ![]() –
–
фактическое значение исследуемой
характеристики в момент времениj;
![]() –теоретическое
–теоретическое
значение исследуемой характеристики
в момент времени j;
j
– номер измерения 1-х
сезонов в рассматриваемом временном
интервале;
l
– номер сезона;
k
– количество l-х
сезонов в рассматриваемом временном
интервале.
Расчет
скорректированных индексов сезонности.
Индекс корректировки можно определить
по формуле (3.31), а скорректированные
индексы сезонности рассчитать по формуле
(3.32). Далее при прогнозировании используются
именно скорректированные индексы
сезонности:
 ;
;
(3.31)
 . (3.32)
. (3.32)
Формирование
уравнений тренда с учетом индексов
сезонности (3.33). Эта формула должна
быть конкретизирована для каждого типа
динамики, т.е. для равномерного развития
![]() будет рассчитываться по формуле линейной
будет рассчитываться по формуле линейной
зависимости, для равноускоренного –
по степенной или параболической:
![]() .
.
(3.33)
Рассчитанные
по уравнению (3.33) прогнозные характеристики
отражают и закономерности среднегодовой
динамики исследуемой характеристики
и среднесезонные отклонения от нее.
С количественной
точки зрения различают три вида
взаимосвязей: балансовые; компонентные;
факторные.
Балансовая
связь
показателей характеризует соответствие
двух элементов — спроса и предложения,
доходов и расходов, производства и
потребления, наличия рабочей силы и
потребностей в ней и т.п. Методический
инструмент прогнозирования балансовых
связей – балансы и разрабатываемые на
их основе балансовые модели.
Компонентные
связи
показателей характеризуются изменением
прогнозного показателя – результат
изменения компонентов, входящих в этот
показатель как множители. В прогнозировании
этот вид взаимосвязи может быть
использован для определения прогноза
одного из показателей при известных
прогнозах компонентов, используемых
при расчете искомой характеристики
(метод укрупненных измерителей, метод
Кольма) либо для оценки качества прогнозов
взаимосвязанных показателей.
Факторные
связи
характеризуются тем, что проявляются
в согласованной вариации изучаемых
показателей. При этом одни показатели
выступают как факторные (причины,
независимые переменные), другие – как
следствие (результат, зависимая
переменная). По своему характеру этот
вид связи – причинно-следственная
зависимость.
Факторные
связи могут рассматриваться как
функциональные или корреляционные. При
функциональной связи
изменение результативного признака
всецело обусловлено действием факторного.
При
корреляционной связи
изменение результативного признака
лишь частично обусловлено влиянием
факторного признака, так как не исключается
возможность воздействия и других
факторов.
Корреляционно-регрессионный
анализ используется
для исследования форм связи, устанавливающих
количественные соотношения между
случайными величинами изучаемого
процесса. При этом значение независимой
переменной (х)
нам известно по предположению. В процессе
прогнозирования оно может быть
использовано нами для оценки зависимой
переменной (y).
Функция регрессии
![]() показывает, каким будет в среднем
показывает, каким будет в среднем
значение переменнойy,
если переменные х
примут конкретное значение.
Переменная
у,
характеризующая результат, формируется
пот воздействием других переменных и
факторов. Поэтому она всегда стохастична
(случайна) по природе. Переменные х
(объясняющие переменные) характеризуют
причину. Значения ряда переменных x
могут характеризовать внутренние
элементы системы или задаваться «извне»
прогнозируемой системы.
По
своей природе объясняющие переменные
могут быть случайными и неслучайными.
Регрессионные остатки
![]() – это латентные (скрытые) случайные
– это латентные (скрытые) случайные
компоненты, влияющие нау,
а также случайные ошибки в измерении
анализируемых результирующих переменных.
Парная
корреляция –
корреляционные связи между двумя
переменными. Экономико-математические
модели, построенные с учетом такого
рода взаимосвязей, называют однофакторными
моделями.
Множественная
корреляция –
корреляционные взаимосвязи между
несколькими переменными.
Ложная
корреляция –
это отсутствие причинной связи между
явлениями, связанными корреляционной
связью.
Регрессионный
анализ –
решаются задачи выбора независимых
переменных, существенно влияющих на
зависимую величину, определенней формы
уравнения регрессии, оценивание
параметров.
Последовательность
процедур прогнозирования на основе
однофакторных моделей линейной регрессии:
1. Сбор исходной
информации.
2. Качественный
анализ взаимосвязи исследуемых
показателей, определение причинно-следственной
связи между анализируемыми характеристиками.
3.
Оценка тесноты связи. Коэффициент
корреляции R
характеризует тесноту связи между
случайными величинами (х,у),
может быть рассчитан по формуле
 . (3.34)
. (3.34)
По численному
значению коэффициента корреляции можно
сделать следующие выводы:
R
= 0 –
рассматриваемые величины не взаимосвязаны;
R
= 1 – имеет
место прямая функциональная зависимость,
изменение значений переменных
однонаправленное, при увеличении одной
переменной другая тоже увеличивается;
R
= — 1 – имеет
место обратная функциональная зависимость,
изменение значений переменных
разнонаправленное, при увеличении одной
переменной другая уменьшается.
По абсолютному
значения коэффициента корреляции можно
прийти к следующим заключениям:
![]() –связи
–связи
практически нет;
![]() –связь
–связь
слабая;
![]() –связь
–связь
заметная;
![]() –связь
–связь
тесная;
![]() –связь,
–связь,
близкая к функциональной.
Прогнозы строятся
на основе взаимосвязей с коэффициентом
корреляции 0,75-1.
4.
Расчет параметров уравнения регрессии.
Оценка параметров уравнения регрессии
осуществляется методом наименьших
квадратов на основе формул (3.35), (3.36),
(3.37):
![]() ; (3.35)
; (3.35)
 ; (3.36)
; (3.36)
![]() , (3.37)
, (3.37)
где n
– объем выборки.
5. Оценка значимости,
типичности.
6.
Задание условий прогнозного периода
(вероятных значений параметра х).
7.
Прогнозирование возможных значений
параметра y
при заданных значениях параметра х.
Временным
лагом (![]() )
)
называется промежуток времени, по
истечении которого изменение показателей
одного временного ряда оказывает влияние
на показатели другого. Корреляционно-регрессионная
зависимость с учетом временного лага
описана следующим уравнением:
![]() . (3.38)
. (3.38)
Авторегрессионной
называют
модель, в которой лаговое соотношение
связывает значение одного и того же
показателя в разные моменты времени:
![]() . (3.39)
. (3.39)
Экономический
барометр –
это система экономических показателей,
применяемых для анализа и прогнозирования
конъюнктуры рынка. Все показатели
делятся на три группы: опережающие
(лидирующие), совпадающие (синхронные)
и запаздывающие.
Во
многих прогнозах ставится вопрос не о
запаздывании, а об упреждении событий.
По предположению принимается прогнозное
значение
![]() ,
,
и рассчитывается необходимая величина
![]() .
.
Интуитивные
(экспертные) методы прогнозирования –
это методы прогнозирования, использующие
в качестве источника информации
обработанные суждения экспертов,
полученные в ходе проведения
специальных опросов.
Индивидуальные
экспертные оценки –
методы прогнозирования, основанные на
использовании в качестве источника
информации одного эксперта.
Прямой
опрос (интервью).
Прогноз составляется по результатам
беседы прогнозиста (интервьюера) с
экспертом, в ходе которой прогнозист
задает вопросы в соответствии с заранее
разработанной программой.
Анонимный
опрос предполагает
самостоятельную творческую работу
эксперта по поставленной проблеме.
Аналитические
докладные записки.
Прогнозная информация представленная
в форме докладной записки, является
результатом длительной, тщательной
самостоятельной работы эксперта над
анализом прогнозируемого объекта.
Коллективные
экспертные оценки –
методы прогнозирования, основанные на
выявлении обобщенной объективизированной
оценки экспертной группы в результате
обработки индивидуальных независимых
оценок, вынесенных экспертами, входящими
в группу. Зависимый интеллектуальный
эксперимент проводится путем коллективного
обсуждения исследуемой проблемы.
Независимый интеллектуальный эксперимент
проводится с помощью анкетирования.
Оценка компетентности
экспертов. Составляется рабочая таблица
– «Матрица оценки компетентности
экспертов первого порядка», по результатам
которой рассчитываются коэффициенты
компетентности экспертов первого
порядка:
 . (3.40)
. (3.40)
По результатам
этих расчетов строится матрица оценки
коэффициентов компетентности
экспертов второго порядка, оценки в
которой взвешиваются с учетом
компетентности эксперта, давшего
оценку, и рассчитывается коэффициент
компетентности экспертов второго
порядка:
 , (3.41)
, (3.41)
где ![]() – результат анкетирования, заключение
– результат анкетирования, заключение
данноеi-м
экспертом по поводу компетентности
j-го
эксперта;
I
– номер оценивающего эксперта;
j
– номер оцениваемого эксперта;
![]() ,
,
если i-й
эксперт назвал j-ro
эксперта;
![]() ,
,
если i-й
эксперт не назвал j-го
эксперта;
![]() –коэффициент
–коэффициент
компетентности первого порядка j-гo
эксперта, показывает долю голосов,
полученных j-м
экспертом, в общей сумме голосов.
Оценка профессиональных
качеств эксперта способом самооценки
предполагает наличие тестов, анкет, на
вопросы которых эксперту предстоит
дать самостоятельный ответ. Каждый
ответ на вопрос получает определенное
количество баллов, соответствующее, с
одной стороны, значимости оцениваемого
показателя, а с другой – варианту ответа
эксперта на данный вопрос. Конкретные
численные значения весовых коэффициентов
определяются рабочей группой и не
сообщаются потенциальным экспертам.
Коэффициент компетентности конкретного
эксперта может быть получен как частное
от деления количества баллов данного
эксперта на количество баллов, которое
может получить «эталонный» эксперт:
 , (3.42)
, (3.42)
где ![]() – количество баллов, полученноеj-м
– количество баллов, полученноеj-м
экспертом при ответе на i-й
вопрос анкеты;
![]() –количество
–количество
баллов, которое может получить «эталонный»
эксперт при ответе на i-й
вопрос анкеты.
Зависимый
интеллектуальный эксперимент проводится
путем коллективного обсуждения
исследуемой проблемы, в результате
которого эксперты вырабатывают обобщенную
прогнозную оценку. К методам данной
группы могут быть отнесены методы
комиссий (совещание), суда и мозговой
атаки.
Метод
деструктивной отнесенной оценки (ДОО).
Основные этапы
ДОО: формирование группы участников
мозговой атаки: составление проблемной
записки участника мозговой атаки —
описание сущности и основных процедур
метода ДОО и описание проблемной
ситуации; генерация идей; систематизация
идей; разрушение систематизированных
идей; оценка критических замечаний и
составление списка практически
осуществимых идей.
Метод
обмена мнениями.
Группе экспертов предлагают критически
обсудить заранее подготовленный прогноз.
В процессе мозговой атаки необходимо
найти уязвимые места в первоначальном
прогнозе и превратить его в согласованный
документ.
Операционное
творчество.
Только руководитель группы знает
истинный характер проблемы и организует
обсуждение таким образом, чтобы найти
решение.
Независимый
интеллектуальный эксперимент
проводится заочно с помощью анкетирования.
К числу его методов могут быть отнесены
социологические опросы, анкетирование
методом Дельфи, метод ранговой корреляции
и др.
Обработка
и представление результатов коллективных
экспертных опросов.
Способ обработки результатов экспертизы
зависит oт
природы исследуемых факторов и типа
шкалы результатов, требуемых точности
и оперативности получения необходимых
характеристик.
При прогнозировании
методами коллективных экспертных оценок
важно установить среднюю оценку
экспертной группы. Используют следующие
показатели: среднее значение прогнозируемой
величины, дисперсию, коэффициент
вариации оценок.
Среднее
значение прогнозируемой величины (![]() )
)
определяется по формуле
 , (3.43)
, (3.43)
где ![]() – значение прогнозируемой величины,
– значение прогнозируемой величины,
данноеi-м
экспертом;
n
– число экспертов в группе.
При известных
коэффициентах компетентности экспертов
корректнее применять среднюю
взвешенную оценку, используя в качестве
весов коэффициенты компетентности:
 . (3.44)
. (3.44)
Дисперсия
значений прогнозируемой величины (D):
 . (3.45)
. (3.45)
Среднеквадратическое
отклонение индивидуальных экспертных
оценок (![]() ):
):
![]() . (3.46)
. (3.46)
Коэффициенты
вариации оценок, данных экспертами (v):
![]() . (3.47)
. (3.47)
Метод
Дельфи –
метод коллективного экспертного
поискового прогнозирования, основанный
на выявлении согласованной оценки
экспертной группы путем анонимного
опроса экспертов в несколько туров,
предусматривающий сообщение экспертам
результатов предыдущего тура с целью
дополнительного обоснования оценки
экспертов в последующем туре.
Обработка информации,
полученной методом Дельфи.
1. Получение ответов
на вопросы от экспертов в письменной
форме.
2. Статистическая
обработка – расчет медианы, моды,
квартилей и децилей. Для этого
необходимо первоначально упорядочить
полученные экспертные оценки по
возрастанию или убыванию прогнозируемого
признака.
Медиана
— значение прогнозируемого признака,
которым обладает центральный член ряда,
составленного в порядке возрастания
значений признака (ответ эксперта в
центре ранжированного ряда). Мода
— наиболее
часто встречающееся в ранжированном
ряду значение прогнозируемого признака.
Квартиль
– значение прогнозируемого признака,
которым обладают члены ряда под
номером, представляющим 1/4 всего ряда
(нижний квартиль) и 3/4 всего ряда
(верхний квартиль).
Дециль
– это значение прогнозируемого признака,
которым обладают члены ряда под
номером, представляющим 1/10, всего ряда
и 9/10 всего ряда.
В результате
статистической обработки вся совокупность
ответов разбивается на несколько
групп и выделяется 80- и 50%-ный коридор
ответов.
3. Экспертам
присылается анкета, в которой сообщаются
результаты анализа, обобщенные в
двух разделах. В первом дан перечень
пунктов, по которым большинство
экспертов дали согласованную оценку.
Во втором разделе отобраны недостаточно
согласованные оценки.
4. Повторное
анкетирование и обработка его результатов.
Согласованность
мнений экспертов может быть оценена
коэффициентом конкордации.
Коэффициент
конкордации (W)
показывает степень согласованности
мнений экспертов по важности каждого
из оцениваемых направлений:
 , (3.48)
, (3.48)
где n
– количество экспертов;
m
– количество параметров (направлений,
оцениваемых объектов);
![]() –отклонение
–отклонение
суммы рангов по j-му
направлению от среднего значения рангов.
Если среди рангов,
данных одним экспертом, есть равные,
формула оценки согласованности экспертных
оценок приобретает следующий вид:
 , (3.49)
, (3.49)
если W
= 1 – полная
согласованность мнений экспертов;
W
= 0 – полная
несогласованность мнений экспертов.
Последовательность
расчетов методом ранговой корреляции.
1. Получение
индивидуальных экспертных оценок
относительно важности, значимости,
приоритетности оцениваемых параметров
или направлений. Оценки даются в виде
весовых коэффициентов (от 0 до 1). Сумма
коэффициентов одного эксперта, должна
равняться 1.
2.
Ранжирование оценок важности, данных
экспертами. Каждая оценка, данная i-м
экспертом, выражается рангом
![]() (число натурального ряда) таким образом,
(число натурального ряда) таким образом,
что значение 1 – максимальная оценка,a
n
– минимальная. Если среди оценок, данных
i-м
экспертом есть одинаковые, то им
присваивается одинаковый ранг, равный
среднему арифметическому соответствующих
чисел натурального ряда.
3.
Расчет суммы рангов по каждому направлению
(![]() ):
):
![]() . (3.50)
. (3.50)
4.
Расчет среднего значения суммы рангов
по всем направлениям (![]() ):
):
 , (3.51)
, (3.51)
где m
– количество оцениваемых направлений;
j
– номер направления.
5.
Расчет отклонения суммы рангов по j-му
направлению от среднего значения
суммы рангов (![]() ):
):
![]() . (3.52)
. (3.52)
6.
Расчет показателя
![]() характеризующего равные ранги:
характеризующего равные ранги:
![]() , (3.53)
, (3.53)
где ![]() – количество равных рангов вi-й
– количество равных рангов вi-й
группе.
7. Расчет коэффициента
конкордации, выводы о согласованности
мнений экспертов.
8. Анализ значимости
исследуемых параметров. Параметр с
наименьшей суммой рангов имеет
наибольшее значение. Средний коэффициент
весомости определяется как отношение
величины обратной сумме рангов к их
сумме:
 . (3.54)
. (3.54)
Степень предпочтения
параметров заранее считается неизвестной,
она определяется в результате обработки
полученных оценок. Результаты оценивания
фиксируются в виде квадратной матрицы
смежности парных сравнений в виде
знаков:
■ >,
если
![]() ;
;
■ <,
если
![]() ;
;
■ =,
если
![]() .
.
Далее
строится квадратная матрица
![]() ,
,
где![]() ,
,
если![]() ,
,![]() ,
,
если![]() ,
,![]() ,
,
если![]() ,
,
гдеу
– любое рациональное число в заданном
интервале.
Далее
в расчет вводится понятие «итерированная
сила» порядка, «К»
параметров в виде матрицы-столбца Р(К),
которая определяется в общем случае
как:
![]() , (3.55)
, (3.55)
где К
=1,2, … m.
Итерированная
сила объекта х
– произведение строки матрицы А
на столбец матрицы Р(К)
по формуле:
![]() . (3.56)
. (3.56)
В
начале расчета принимается итерированная
сила Р(К) = 1,
т.е. для определения
![]() берется
берется![]() .
.
Исходная матрицаА
умножается на
![]() .
.
Далее этот процесс продолжается с учетом
полученной итерированной силы
предыдущей итерации.
Практическую
ценность представляет нормированная
итерированная сила k-го
порядка i-го
параметра
![]() ,
,
она трактуется как значение коэффициента
весомостиi-го
параметра:
![]() ; (3.57)
; (3.57)
![]() . (3.58)
. (3.58)
С каждой последующей
итерацией результаты уточняются.
Морфологический
анализ –
метод предпрогнозных исследований,
основанный на формировании и анализе
максимального числа вариантов развития
или состояния объекта прогнозирования
с последовательным исключением
нереальных или наименее целесообразных,
варианты морфологических подходов к
прогнозированию: метод морфологических
деревьев, метод ступенчатого поиска
решения, функционально-стоимостной
анализ, метод принудительного образования
связей, метод отрицания и конструирования,
метод крайностей, метод сопоставления
совершенного с дефектным.
Последовательность
построения «морфологического ящика».
1. Точная формулировка
поставленной цели или проблемы.
2.
Структурирование объекта исследования.
Выделение и изучение параметров (![]() ),
),
от которых зависит решение проблемы.
3.
Нахождение для каждого выделенного
параметра (![]() )
)
его значений![]() и сведение их в «морфологический ящик».
и сведение их в «морфологический ящик».
Значения параметров независимы и
несводимы.
4.
Нахождение вариантов решения проблемы.
Возможный вариант решения – любая
совокупность значений всех параметров
(по одному значению из каждой строки
«морфологического ящика»). Общее число
вариантов решения проблемы (N)
определяется по формуле
![]() , (3.59)
, (3.59)
где ![]() – число значенийi-го
– число значенийi-го
параметра (![]() ).
).
5. Определение
функциональной ценности всех полученных
в «морфологическом ящике» вариантов.
В результате оценки варианты решения
проблемы ранжируются по уровню избранного
критерия, из полученной их совокупности
исключаются неосуществимые и признанные
на прогнозный период нецелесообразными.
6. Выбор наиболее
желательного или наиболее реального
варианта решения.
Прогнозный
сценарий –
метод предпрогнозных исследований,
с помощью которого устанавливается
логическая последовательность
событий для определения будущего
состояния объекта исследования. При
прогнозировании социально-экономических
проблем в сценарии указываются
альтернативные события и вероятные
сроки их наступления.
В результате
сценарного исследования эксперт
оформляет доклад, в который включаются
разделы: предисловие: описание сущности
и назначения сценариев; краткое описание
теоретических и информационно-статистических
оснований исследования, временного
горизонта; описание разработанных
вариантов; сравнение вариантов между
собой; рекомендации для процесса принятия
решений; выводы.
Литература: 1, 10, 15.
|
|
эта статья нужны дополнительные цитаты для проверка. Пожалуйста помоги улучшить эту статью от добавление цитат в надежные источники. Материал, не полученный от источника, может быть оспорен и удален. |
В статистика, а ошибка прогноза разница между фактическим или реальным и прогнозируемым или прогноз стоимость Временные ряды или любое другое интересное явление. Поскольку ошибка прогноза выводится из одного и того же масштаба данных, сравнение ошибок прогноза разных рядов может быть выполнено только в том случае, если ряды имеют одинаковый масштаб.[1]
В простых случаях прогноз сравнивается с результатом в один момент времени, и сводка ошибок прогноза строится по набору таких моментов времени. Здесь прогноз может быть оценен с использованием разницы или пропорциональной ошибки. По соглашению ошибка определяется с использованием значения результата минус значение прогноза.
В других случаях прогноз может состоять из прогнозируемых значений за несколько периодов времени; в этом случае для оценки ошибки прогноза может потребоваться рассмотреть более общие способы оценки совпадения временных профилей прогноза и результата. Если основное применение прогноза состоит в том, чтобы предсказать, когда определенные пороговые значения будут пересечены, один из возможных способов оценки прогноза — использовать временную ошибку — разницу во времени между тем, когда результат пересекает порог, и тем, когда прогноз это делает. Когда есть интерес к достижению максимального значения, оценка прогнозов может быть выполнена с использованием любого из:
- разница времен пиков;
- разница пиковых значений в прогнозе и исходе;
- разница между пиковым значением результата и значением, прогнозируемым на этот момент времени.
Ошибка прогноза может быть ошибкой календарного прогноза или ошибкой перекрестного прогноза, когда мы хотим суммировать ошибку прогноза по группе единиц. Если мы наблюдаем среднюю ошибку прогноза для временного ряда прогнозов для одного и того же продукта или явления, мы называем это ошибкой календарного прогноза или ошибкой прогноза временного ряда. Если мы наблюдаем это для нескольких продуктов за один и тот же период, то это перекрестная ошибка производительности. Прогнозирование эталонного класса был разработан для уменьшения ошибки прогноза. Также было показано, что комбинирование прогнозов снижает ошибку прогноза.[2][3]
Расчет ошибки прогноза
Ошибка прогноза — это разница между наблюдаемым значением и его прогнозом на основе всех предыдущих наблюдений. Если ошибка обозначена как  тогда ошибку прогноза можно записать как;
тогда ошибку прогноза можно записать как;

где,
 = наблюдение
= наблюдение
 = обозначают прогноз на основе всех предыдущих наблюдений
= обозначают прогноз на основе всех предыдущих наблюдений
Ошибки прогноза можно оценить с помощью различных методов, а именно: средняя процентная ошибка, среднеквадратичная ошибка, средняя абсолютная ошибка в процентах, среднеквадратичная ошибка. Другие методы включают сигнал слежения и смещение прогноза.
Для ошибок прогноза по обучающим данным
обозначает наблюдение и это прогноз
Для ошибок прогноза на тестовых данных
 обозначает фактическое значение наблюдения h-шага, а прогноз обозначается как
обозначает фактическое значение наблюдения h-шага, а прогноз обозначается как 
Академическая литература
Дреман и Берри в 1995 г. в «Financial Analysts Journal» утверждали, что прогнозы аналитиков ценных бумаг слишком оптимистичны и что инвестиционное сообщество слишком сильно полагается на их прогнозы. Однако этому противостоял Лоуренс Д. Браун в 1996 году, а затем снова в 1997 году, который утверждал, что аналитики, как правило, более точны, чем аналитики «наивных или сложных моделей временных рядов», и что ошибки не увеличиваются с течением времени.[4][5]
Хиромичи Тамура в 2002 году утверждал, что консенсусные аналитики не только представляют свои оценки доходов, которые в конечном итоге близки к консенсусу, но и что их личные качества сильно влияют на эти оценки.[6]
Примеры ошибок прогнозирования
Майкл Фиш — За несколько часов до Великая буря 1987 года сломался, 15 октября 1987 года, он сказал во время прогноза: «Ранее сегодня, по всей видимости, женщина позвонила на BBC и сказала, что слышала, что был ураган в дороге. Что ж, если вы смотрите, не волнуйтесь, его нет! ». буря было хуже всего ударить Юго-Восточная Англия за три столетия, в результате чего был нанесен рекордный ущерб и погибло 19 человек.[7]
Великая рецессия — Финансово-экономический кризис разразился в 2007 году — возможно, худший со времен Великая депрессия 1930-х годов — не предвиделось большинством прогнозистов, даже если несколько одиноких аналитиков предсказывали это в течение некоторого времени (например, Нуриэль Рубини и Роберт Шиллер ). Неспособность спрогнозировать «Великая рецессия «вызвало много душевных поисков в профессии. Королева Великобритании Елизавета сама спросила, почему никто не заметил, что кредитный кризис приближается, и группа экономистов — экспертов из бизнеса, Сити, его регулирующих органов, академических кругов и правительство — пытался объяснить в письме.[8]
Это было не только предсказание Великой рецессии, но и ее влияние, когда было ясно, что экономисты боролись. Например, в Сингапуре Citi утверждал, что страна испытает «самую серьезную рецессию в истории Сингапура». В 2009 году экономика выросла на 3,1%, а в 2010 году в стране наблюдался рост на 15,2%.[9][10]
В конце 2019 года Международный Валютный Фонд по оценкам, глобальный рост в 2020 году достигнет 3,4%, но в результате коронавирус пандемия МВФ пересмотрел свою оценку в ноябре 2020 года, ожидая сокращения мировой экономики на 4,4%.[11][12]
Смотрите также
- Расчет точности прогноза спроса
- Ошибки и неточности в статистике
- Прогнозирование
- Точность прогнозов
- Среднеквадратичная ошибка прогноза
- Смещение оптимизма
- Прогнозирование эталонного класса
использованная литература
- ^ «2.5 Оценка точности прогнозов | OTexts». www.otexts.org. Получено 2016-05-12.
- ^ Дж. Скотт Армстронг (2001). «Комбинирование прогнозов». Принципы прогнозирования: руководство для исследователей и практиков (PDF). Kluwer Academic Publishers.
- ^ Дж. Андреас Грефе; Скотт Армстронг; Randall J. Jones, Jr .; Альфред Дж. Кузан (2010). «Комбинирование прогнозов для предсказания результатов президентских выборов в США» (PDF).
- ^ Браун, Лоуренс Д. (1996). «Ошибки прогнозирования аналитиков и их значение для анализа безопасности: альтернативная перспектива». Журнал финансовых аналитиков. 52 (1): 40–47. ISSN 0015–198X.
- ^ Браун, Лоуренс Д. (1997). «Ошибки прогнозирования аналитиков: дополнительные доказательства». Журнал финансовых аналитиков. 53 (6): 81–88. ISSN 0015–198X.
- ^ Тамура, Хиромичи (2002). «Характеристики индивидуального аналитика и ошибка прогноза». Журнал финансовых аналитиков. 58 (4): 28–35. ISSN 0015–198X.
- ^ «Майкл Фиш вновь посещает сериал» Великий шторм 1987 года «». BBC. 16 октября 2017 г.. Получено 16 октября 2017.
- ^ Британская академия — Глобальный финансовый кризис, почему никто не заметил? — Проверено 27 июля 2015 г. В архиве 7 июля 2015 г. Wayback Machine
- ^ Чен, Сяопин; Шао, Ючэнь (11.09.2017). «Торговая политика для малой открытой экономики: пример Сингапура». Мировая экономика. Дои:10.1111 / twec.12555. ISSN 0378-5920.
- ^ Саблер, Джейсон (2009-01-02). «Фабрики сокращают выпуск, рабочие места по всему миру». Рейтер. Получено 2020-09-20.
- ^ «МВФ предупреждает, что мировой рост самый медленный со времен финансового кризиса». Новости BBC. 2019-10-15. Получено 2020-11-22.
- ^ «МВФ: экономика« теряет динамику »на фоне второй волны вируса». Новости BBC. 2020-11-19. Получено 2020-11-22.

Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
.
SD – стандартное отклонение

где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже. Скачать пример расчета в Excel >>>
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:

где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Источник: сайт http://uppravuk.net/