
Как мы отметили ранее, насущной задачей теории аудита является разработка и обоснование методов оценки вероятности определения ожидаемой ошибки (аудиторского риска).
Дело в том, что в любом случае, даже при сплошных проверках, не говоря уже о выборочных, определение ожидаемой ошибки содержит элемент случайности (аудитор мог не заметить ошибку, мог неправильно истолковать содержание хозяйственной операции и т. д.).
Следовательно, определение ожидаемой ошибки К всегда осуществляется с какой-то вероятностью (аудиторским риском).
В соответствии с требованиями международных и федеральных аудиторских стандартов аудитор обязан оценивать аудиторский риск и разрабатывать процедуры, необходимые для снижения риска до приемлемо низкого уровня.
Стандарты устанавливают также, что аудитор должен оценивать риск как на уровне отчетности в целом, так и на уровне сальдо по счетам (т. е. для отдельных статей баланса), а также на уровне групп однотипных операций (т. е. для оборотов по счетам бухгалтерского учета).
Для осуществления требуемых оценок необходимо определить аудиторский риск и уяснить для себя его природу.
Стандарты определяют аудиторский риск как возможность выражения аудитором ошибочного мнения, в то время как в бухгалтерской отчетности будут содержаться существенные ошибки, искажения.
Это – концептуальное определение, малопригодное для практической работы. Дадим более строгое определение аудиторского риска.
Для этого введем следующие обозначения: S (руб.) – уровень существенности базового показателя (статьи бухгалтерской отчетности); К (руб.) – ожидаемая (наиболее вероятная) ошибка, которая, по мнению аудитора, содержится в статье бухгалтерской отчетности, для которой установлен уровень существенности S; Q (руб.) – действительная ошибка, содержащаяся в данной статье бухгалтерской отчетности.
Тогда аудиторский риск на уровне отчетности в целом – это вероятность события, заключающаяся в том, что хотя бы для одной статьи бухгалтерской отчетности выполняется неравенство K < S при выполнении неравенства Q > S (ожидаемая ошибка меньше уровня существенности, в то время как действительная ошибка превышает его).
Аудиторский риск на уровне сальдо конкретного счета (конкретной статьи баланса) – это вероятность события, заключающегося в том, что неравенства K < S при Q > S выполняются для данной статьи баланса.
Аудиторский риск на уровне оборота по конкретному счету (генеральной совокупности операций) – это вероятность события, заключающегося в том, что неравенства K < S при Q > S выполняются для генеральной совокупности операций, составляющей оборот (дебетовый или кредитовый) данного счета (в этом случае S, K, Q – уровень существенности, ожидаемая ошибка и действительная ошибка для оборота рассматриваемого счета).
Итак, согласно нашему определению аудиторский риск – это вероятность наступления некоего события. Вероятность есть величина математическая, и она может быть определена количественно (в долях единицы либо процентах).
Указанные выше стандарты предусматривают также возможность качественной оценки, исходя, по крайней мере, из трех градаций (низкий риск, средний риск, высокий риск).
Для того чтобы обоснованно выбрать способ оценки, надо уяснить себе природу аудиторского риска.
Очевидно, что аудиторский риск для отчетности в целом, равно как и аудиторский риск на уровне сальдо и оборотов по счетам при применении процедур сплошной проверки, либо выборочных процедур, основанных на нестатистических (содержательных) методах, – это субъективная вероятность, т. е. вероятность, основанная не на статистическом или классическом ее определении, а на суждении экспертов (аудиторов), учитывающих имеющийся опыт, влияние различных факторов и т. д.
Если же говорить об аудиторском риске на уровне сальдо и оборотов по счетам при применении выборочных процедур, основанных на статистических методах, то в этом случае аудиторский риск – это статистическая вероятность, которая может быть численно определена исходя из закона распределения случайной величины (размера ошибок либо количества ошибок в выборке).
Как мы отметили
ранее, применение статистических
выборочных методов определения ожидаемой
ошибки К, рассмотренных в предыдущих
разделах, оправдано не во всех случаях,
а лишь тогда, когда объем генеральных
совокупностей достаточно велик (сотни,
тысячи элементов), а ошибки случайны и
равновозможны.
Если объем
генеральной совокупности невелик
(например, не более нескольких десятков
документов), то проведение сплошной
проверки займет у аудитора меньше
времени, чем обработка результатов
выборочного исследования. Отметим, что
при сплошной проверке аудитор
непосредственно определяет ожидаемую
ошибку К как сумму всех выявленных им
в проверяемой совокупности ошибок.
В другом случае
объем генеральной совокупности может
быть слишком велик для сплошной проверки
(например, не менее нескольких сотен
документов). Но при этом у аудитора может
иметься информация (источники появления
ее будут рассмотрены позднее), исключающая
применимость предположения о
равновозможности и случайности ошибок
в генеральной совокупности. В таком
случае оправдано применение содержательных
методов выборочного исследования.
Содержательные методы, как следует из
их названия, основаны на содержании
имеющейся у аудитора информации о
характере распределения ошибок в
генеральной совокупности.
Рассмотрим
возможные причины неслучайности и
неравновозможности ошибок в генеральных
совокупностях.
Очевидно, что
ошибки неслучайны, если они появляются
в силу какой-то постоянно действующей
причины (в этом случае ошибки будут
систематическими). Причиной появления
систематических ошибок чаще всего
бывает слабое знание (незнание) либо
неправильное, недостаточное понимание
бухгалтером законодательных и нормативных
актов Российской Федерации в области
учета налогообложения, хозяйственного
права. Другой причиной появления
систематических ошибок может быть
давление на бухгалтера со стороны
руководства организации.
Ошибки
неравновозможны, если в бухгалтерских
документах имеются учетные области, в
которых вероятность появления ошибок
значительно выше, чем в других. Такие
области (области с повышенной вероятностью
появления ошибок) будем называть
значимыми для аудита областями. Практика
показывает, что значимые для аудита
области могут иметь место, например, в
следующих случаях:
—
резкая неоднородность генеральной
совокупности — наличие в совокупности
документов, стоимость которых на порядок
(порядки) превышает стоимость большей
части документов (сосредоточение
значительных денежных сумм в небольшом
количестве документов нарушает
равновозможность появления ошибок);
—
появление в учете новых, ранее в данной
организации не встречавшихся хозяйственных
операций, вызванных, например, освоением
нового вида деятельности;
—
наличие в учете операций, неоднозначно
трактуемых законодательством, нормативными
актами, профессиональными комментаторами;
—
изменение правил учета и налогообложения
каких-либо операций (такие операции
будут составлять значимую область).
—
наличие в учёте операций со связанными
сторонами (при совершении подобных
операций возможны нарушения, обусловленные
взаимным интересом сторон и их особыми
отношениями друг с другом);
—
наличие в учёте операций с существенными
суммами по выполнению работ, оказанию
услуг, не имеющих вещественного результата
(консультации, информационные услуги,
обслуживание оборудования и т.д.);
—
наличие в учёте различных по сути
(подлежащих отнесению в связи с этим на
различные источники), но весьма близких
по своему содержанию операций и т.д.
Причины появления
значимых для аудита областей определяют
возможности содержательных выборочных
методов определения ожидаемой ошибки.
При этом следует иметь в виду, что
возможные причины появления значимых
для аудита областей, безусловно, не
ограничиваются приведенными выше
примерами, число их неисчерпаемо.
Поэтому, если
статистических методов, рассмотренных
выше, в общем-то, два, то содержательных
методов, наверное, столько же, сколько
практикующих аудиторов. Некоторые
аудиторы, проводя проверку, не задумываются
о методах (как не задумывался г-н Журден
о том, что он говорит прозой), а
руководствуются при осуществлении
выборки исключительно своим опытом и
интуицией, и при этом достигают отличных
результатов. Очевидно, происходит это
потому, что они неосознанно используют
эти самые содержательные методы.
Серьезного
научного обоснования содержательных
методов выборочного исследования в
аудите на сегодняшний день пока нет.
Тем не менее, некоторые общие принципы,
заложенные в основу содержательных
методов, хорошо себя зарекомендовали
на практике [6], и потому некоторые из
них могут быть рекомендованы для
практического использования. К подобным
методам выборочного исследования могут
быть отнесены следующие:
— метод,
основанный на блочном отборе документов
(метод «блочного отбора»);
— метод,
основанный на отборе документов
наибольшей стоимости (метод «основного
массива»);
— метод,
основанный на отборе документов, в
которых наличие ошибок наиболее вероятно,
либо в которых возникновение ошибок и
нарушений может вызвать наиболее
негативные для предприятия последствия
(метод «ключевых» элементов);
-комбинированный
метод, основанный на различных сочетаниях
вышеперечисленных методов.
Рассмотрим
содержание и практическое применение
указанных выше методов.
Метод «блочного
отбора»
заключается в формировании выборки
путем отбора из генеральной совокупности
«блока» документов – совокупности,
относящейся к определенному периоду
(например, документы за один месяц).
Ожидаемая
ошибка К генеральной совокупности
определяется при этом, как произведение
суммарной ошибки выборки на отношение
объемов генеральной совокупности и
выборки:
К = N
/ n
k
(руб.)
, (3.17)
где К (руб.) —
ожидаемая ошибка генеральной совокупности;
N (в натуральных единицах) – объем
генеральной совокупности; n (в натуральных
единицах) – объем выборки; k (руб.) —
суммарная ошибка в выборке.
Подобный прием
оправдан в тех случаях, когда в генеральной
совокупности преобладают систематические
ошибки, что исключает возможность
применения статистических методов.
Пример.
Аудитор проверяет кредитовый оборот
счета 02 — амортизацию основных средств,
начисленную в течение года. Объем
генеральной совокупности N = 1200 операций
(по 100 операций ежемесячно). В течение
года не было движения (выбытия или
оприходования) основных средств.
Соответственно, ежемесячная сумма
начисленной амортизации одна и та же.
Исходя из этого, аудитор предполагает,
что если генеральная совокупность
содержит ошибки, то исключительно
систематические, повторяющиеся ежемесячно
(например, неправильное применение
нормы амортизации). Аудитор выбирает
любой месяц и сплошным методом проверяет
начисление амортизации. Выявленная
ошибка k = 25 000 р. Поскольку объем выборки
n = 100 операций, то ожидаемая ошибка
генеральной совокупности
К = N
/ n
k
= 1200 / 100
25 000 = 300 000 р.
В зарубежной
литературе по аудиту содержатся указание
на то, что при методе «блочного отбора»
экстраполяция ошибки на генеральную
совокупность может осуществляться как
пропорционально соотношению объемов
генеральной и выборочной совокупностей
(N/n),
так и пропорционально соотношению их
стоимостей. Тогда ожидаемая ошибка
генеральной совокупности К будет
определяться из следующей зависимости:
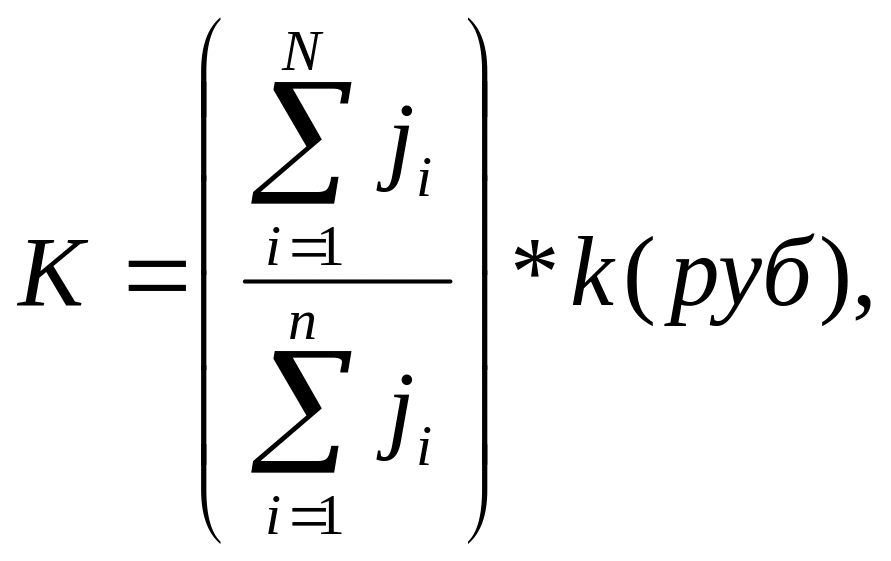
(3.18)
где
— стоимость i-го
документа.
Численный
анализ, проведенный в работе [15], показал,
что при однородной стоимости элементов
генеральной совокупности (коэффициент
вариации менее 0,3) формулы (3.17) и (3.18) дают
практически равные результаты. При
большей неоднородности генеральной
совокупности формула (3.18) неприменима,
поскольку погрешность ее может быть
весьма значительной.
Метод «основного
массива»,
как следует из его названия, состоит в
том, что аудитор формирует выборку путем
отбора из генеральной совокупности
элементов наибольшей стоимости
(элементов, стоимость которых превышает
уровень существенности). Этот метод
оправдан в тех случаях, когда генеральная
совокупность неоднородна по стоимости
документов, составляющих ее: в совокупности
есть документы, стоимость которых на
порядок (порядки) превышает стоимость
бóльшей части документов. Опыт показывает,
что чаще всего количество подобных
документов в совокупностях невелико.
В литературе встречается даже «магическое»
соотношение: 20·80 (часто на 20% документов
приходится 80% стоимости всех документов
купности). Как отмечено ранее, применение
статистических методов в таком случае
неоправданно, так как сосредоточение
значительных денежных сумм в небольшом
количестве мест (документов) нарушает
принцип равновозможности — единственная
ошибка в документе, входящем в «основной
массив», сразу превышает уровень
существенности, в то время как в документах
«неосновного массива» для превышения
уровня существенности таких ошибок
должно быть, например, несколько десятков.
При применении
метода «основного массива» ожидаемая
ошибка генеральной совокупности К
принимается равной суммарной ошибке в
выборке k:
К=k
(руб). (3.19)
Теперь рассмотрим
метод «ключевых
элементов».
Метод состоит в формировании выборки
путем отбора элементов (операций), в
которых вероятность появления ошибок
значительно выше, чем в других (значимые
для аудита области), а также тех операций,
ошибки или нарушения в которых могут
вызвать существенный ущерб для
проверяемого субъекта, государства или
третьих лиц. Данные для осуществления
отбора могут быть основаны на опыте
предыдущих проверок, результатах
наблюдения и опроса, результатах
использования аналитических или
специальных процедур.
Как и в предыдущем
случае, ожидаемая ошибка генеральной
совокупности К принимается равной
суммарной ошибке в выборке k.
Пример.
Аудитор
проверяет дебетовый оборот счета 41 —
оприходование товара. Объем генеральной
совокупности N = 250 накладных. Из них 245
поставок — от постоянных российских
поставщиков, 5 поставок — от заграничных
поставщиков по импортным контрактам.
Причем ранее валютные операции проверяемым
предприятием не осуществлялись. Очевидно,
что 5 операций по импорту товара являются
как ключевыми по риску (вероятность
ошибок в непривычных операциях всегда
гораздо выше, чем в повседневных), так
и по последствиям (ошибки или нарушения
в валютных операциях могут повлечь
тяжелые последствия . Аудитор отбирает
5 операций импорта товара и проверяет
их сплошным образом.
Комбинированный
метод, как
следует из его названия, включает в себя
все вышеперечисленные методы в различных
сочетаниях. На практике чаще всего
применяется именно комбинированный
метод.
Пример.
Аудитор проверяет учет производственных
затрат (дебетовый оборот счета 20) на
малом предприятии. В состав производственных
затрат входят:
|
№ п/п |
Наименование |
Сумма, тыс. |
% |
|
1 |
Ремонт |
520 |
49 |
|
2 |
Заработная |
258 |
24 |
|
3 |
Амортизация |
75 |
7 |
|
4 |
Списание |
185 |
17 |
|
5 |
Услуги сторонних |
30 |
3 |
|
ИТОГО |
1068 |
100 |
Генеральная
совокупность (операции, отраженные по
дебету счета 20) неоднородна по виду
операций, вследствие чего аудитор
стратифицирует ее на 5 совокупностей.
Совокупность
операций по ремонту (520 тыс. р.) аудитор
подвергает сплошной проверке в качестве
как «основного массива», так и «ключевых
элементов». Ожидаемая ошибка страты,
выявленная в ходе сплошной проверки,
составила К1
= 4,5 тыс. р. (необоснованное отнесение на
счет 20).
Совокупность
операций по учету заработной платы с
начислениями (258 тыс. р.) аудитор подвергает
проверке методом «блочного отбора»,
полагая, что в ней преобладают
систематические ошибки. В качестве
блока аудитор выбирает документы за
один месяц. В ходе их проверки ошибок
не обнаружено,ожидаемая ошибка К2
= 0.
Совокупность
операций по начислению амортизации (75
тыс. р.) аудитор из тех же соображений
подвергает «блочному отбору». В ходе
проверки документов за отобранный месяц
обнаружена ошибка в начислении амортизации
k = 500 р. Тогда ожидаемая ошибка страты
К3
= N
/ n
k
= 12 / 1 · 500 = 6000 р.
Совокупность
операций по списанию материалов (185 тыс.
р.) содержит 450 операций. Аудитор подвергает
ее выборочной проверке с использованием
метода, основанного на нормальном
распределении. В ходе обработки
результатов выборочной проверки
получено: средняя ошибка выборки![]()
= 20 р. Тогда ожидаемая ошибка страты
К4
=
N
= 20
450 = 9 000 р.
Совокупность
операций по отнесению на затраты услуг
сторонних организаций (30 тыс. р.) аудитор
решает не проверять ввиду несущественности
ее суммы.
Тогда ожидаемая
ошибка генеральной совокупности:
К = К1
+К2
+К3
+ К4
= 4500 + 0 + 6000 + 9 000 = 19 500 р.
3.10.
Оценка аудиторского риска на уровне
сальдо и оборотов по
счетам
По результатам
применения аудиторских процедур,
рассмотренных выше, может быть оценен
аудиторский риск (его компоненты) на
уровне сальдо и оборотов по счетам, то
есть на уровне генеральных совокупностей,
в отношении которых применялись
аудиторские процедуры.
Рассмотрим эти
оценки.
3.10.1.
Оценка аудиторского риска при применении
выборочных
вероятностно-статистических
процедур
При применении
выборочных вероятностно-статистических
процедур аудиторский риск проявляет
себя как статистическая вероятность,
и может быть численно определен исходя
из закона распределения случайной
величины (размера ошибок, либо количества
ошибок в выборке).
Как известно
из статистики, при экстраполировании
результатов исследования репрезентативной
выборки на генеральную совокупность
вероятность определяется объёмом
выборки.
Упомянутая
статистическая вероятность при
репрезентативной выборке зависит только
от объема выборки, вследствие чего
согласно федеральному стандарту аудита
№ 16 «Аудиторская выборка» ее следует
определить, как риск выборки (риск,
связанный с объемом выборки – будем
обозначать его
![]()
).
Следует отметить, что наряду со
статистической вероятностью
при применении выборочных процедур,
основанных на вероятностно-статистических
методах, присутствует и субъективная
вероятность, которую стандарт № 16
определяет, как риск, не связанный с
объемом выборки (обозначим его
![]()
).
Этот риск зависит от прочих факторов,
не связанных с объемом выборки (опытом
и квалификацией аудитора, его
добросовестностью и пр.), и проявляет
себя в рассматриваемом случае, как
вероятность того, что аудитор может
обнаружить в выборке не все имеющиеся
в ней ошибки.
Таким образом,
аудиторский риск RА
на уровне сальдо и оборотов по счетам
бухгалтерского учета при применении
выборочных процедур, основанных на
вероятностно- статистических методах,
является функцией двух компонентов —
риска выборки RВ
и риска, не связанного с выборкой RНВ
:
RА
= f (RВ,RНВ).
(3.20)
Получим выражения
для риска выборки и аудиторского риска
применительно к известным
вероятностно-статистическим методам.
Сперва получим
выражение для риска выборки RВ
применительно к процедуре, основанной
на нормальном
распределении размера ошибок.
Риск
выборки RВ
является вероятностью события,
заключающегося в том, что действительная
ошибка Q
генеральной совокупности окажется
больше «применяемого» для данной
генеральной совокупности уровня
существенности S
, в то время, как полученная аудитором
ожидаемая ошибка К менее уровня
существенности (Q
S
при К
S).
Заметим, что неравенство К
S
может быть приведено к виду
![]()
![]()
,
где
![]()
— средний уровень существенности;
= K/N
– генеральная средняя; N
– объем генеральной совокупности.
Получим выражение
для риска выборки RВ.
Для этого вспомним, что при нормальном
распределении может быть определена
верхняя граница доверительного интервала
![]()
,
которую генеральная средняя
не должна превысить:
![]()
,
(3.21)
где
![]()
—
выборочная средняя;
![]()
— среднеквадратичная погрешность
выборочной средней; t
– предел
интеграла Лапласа..
Вероятность R
превышения генеральной средней
верхней границы доверительного интервала
a
будет являться риском выборки RВ
в том случае, когда верхняя граница
доверительного интервала будет равна
среднему уровню существенности (a=
).
Получаем следующее
выражение:
![]()
(3.22)
Среднеквадратичное
отклонение выборочной средней в выражении
для доверительного интервала подсчитывается
по известной зависимости:
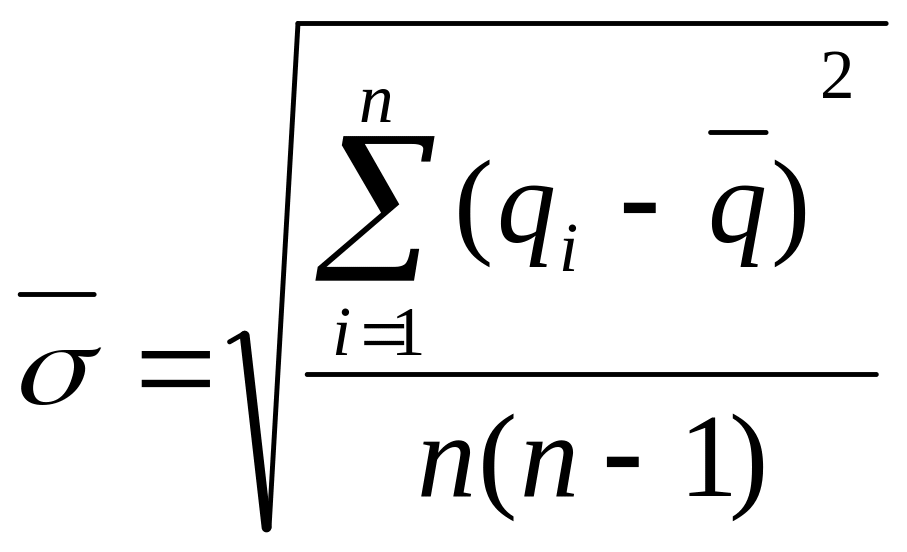
.
(3.23)
где
n-
объем выборки; qi
(руб.) –
размер ошибки в i-ом
элементе выборки.
Тогда
риск выборки RВ
может
быть найден из статистических таблиц
по значению t,
полученному из выражения для доверительного
интервала:
![]()
.
(3.24)
Таким
образом, для выборочной процедуры,
основанной на нормальном распределении
размера ошибки, риск выборки может быть
найден из зависимости
![]()
,
где значение предела интеграла Лапласа
t
определяется с помощью выражения (3.24).
Рассмотрим возможность применения
полученных зависимостей на примере.
Пример.
Воспользуемся
исходными данными примера, рассмотренного
ранее: объем
генеральной совокупности N=850
авансовых отчетов общей стоимостью
J=1 800 000
руб.; объем выборки n=50
авансовых отчетов; ошибки в авансовых
отчетах, попавших в выборку:
руб.,
руб.,
руб.
Уровень существенности установлен
аудитором в размере s=5%
( S
= 90 000 руб.). Определим ожидаемую ошибку
генеральной совокупности К и риск
выборки RВ.
Средняя ошибка
в выборке:
Ожидаемая
ошибка генеральной совокупности:
К=
*N=34*850=28 900
руб.
Среднеквадратичное
отклонение выборочной средней:
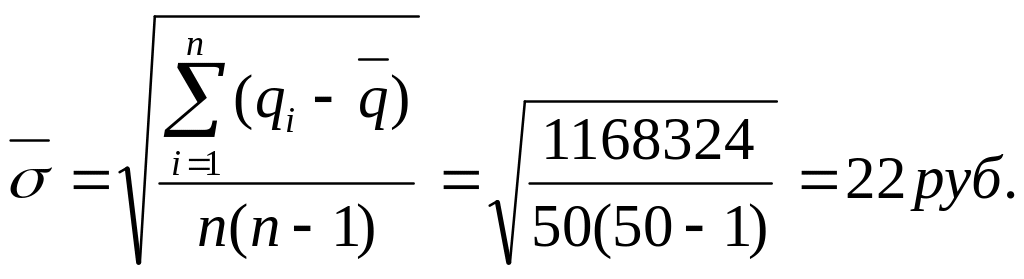
Средний уровень
существенности:
![]()
Расчетное
значение предела интеграла Лапласа:
![]()
Из
статистических таблиц [11] получаем, что
при t
=3,3 вероятность превышения генеральной
средней верхней границы доверительного
интервала равна 0,001. Таким образом, риск
выборки RВ
=0,1%. Из
этого следует, что с вероятностью 99,9%
ожидаемая ошибка генеральной совокупности
(наиболее вероятное значение которой
составляет 28 900 руб.) не превысит
уровень существенности, равный 90 000
руб.
Приведенные
выше рассуждения основаны на предположении
о том, что аудитор обнаружит в выборке
все ошибки qi,
то есть на предположении о том, что риск
RНВ,
определяемый опытом аудитора, его
информированностью о клиенте и т.д.,
равен нулю.
На
практике, конечно риск RНВ
0,
поскольку аудитор в силу различных
причин (недостаток опыта, квалификации,
усталость, небрежность и т.д.) может
обнаружить не все ошибки в выборке.
Введём понятие
ошибки в выборке, обнаруженной аудитором
–
![]()
(руб.).
Вероятность
обнаружения аудитором всех ошибок в
выборке составит в таком случае
![]()
,
где
![]()
— средняя ошибка в выборке, обнаруженная
аудитором.
Поскольку эта
вероятность определяется всеми прочими
факторами (опыт и квалификация аудитора,
его добросовестность, знакомство с
проверяемой организацией и т.д.), то
вероятность противоположного события
– это риск RНВ.
Тогда:
![]()
.
(3.25)
Из
выражения (3.14) получаем:
![]()
.
(3.26)
Риск
RНВ
может быть численно оценен путем анализа
определяющих его указанных выше факторов,
например, как это показано выше, с помощью
линейной полиномиальной модели.
Тогда
аудиторский риск может быть определён
из статистических таблиц, как функция
![]()
,
где значение предела интеграла Лапласа
определяется из зависимости:
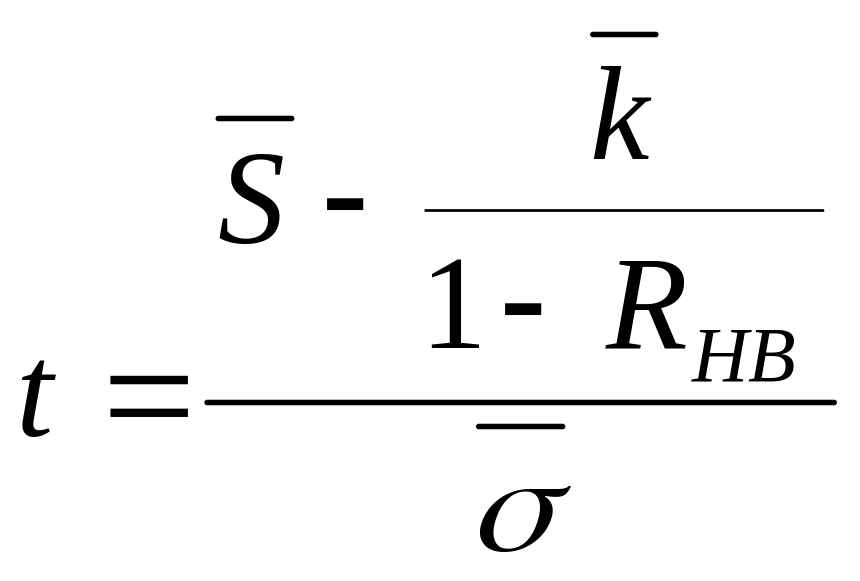
.
(3.27)
Пример. Используя
исходные данные предыдущего примера,
определим аудиторский риск, если
значение RНВ
=35%.
Расчетное
значение предела интеграла Лапласа:
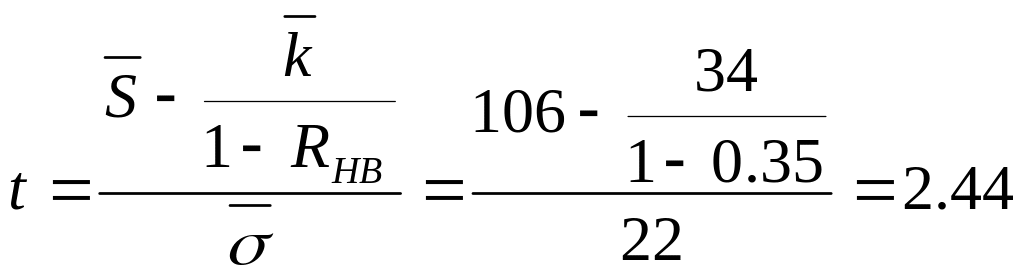
Из таблиц [11]
получаем, что при t
=2,44 аудиторский риск RА
=0,005
(0,5%).
Теперь получим
выражение для риска выборки и аудиторского
риска применительно к процедуре,
основанной на биномиальном
распределении количества ошибок в
выборке.
Ведем следующие
обозначения: N
– объем генеральной совокупности; n
– объем выборки; m
– количество ошибок в выборке; M
– ожидаемая ошибка генеральной
совокупности (ожидаемое количество
ошибок в генеральной совокупности).
Как мы указали
ранее, в математической статистике
показано, что для биномиального
распределения наиболее вероятное
значение величины М определяется из
выражения M
= m*N/n.
В
[11] показано также, что для отношения
M/N
может быть определена верхняя граница
доверительного интервала a,
которую величина M/N
с вероятностью P
= 1 – R
не должна превысить:
![]()
,
(3.28)
где
t
– предел интеграла Лапласа;
![]()
— относительное количество ошибок в
выборке.
В
[11] указано, что формула (3.28) является
приближенной, но достаточной для
практических расчетов при значениях n
порядка сотен.
Приравняв верхнюю
границу доверительного интервала
среднему уровню существенности
![]()
,
(3.29)
получаем
значение предела интеграла Лапласа,
определяющее риск выборки RВ:

,
(3.30)
где
— средний уровень существенности.
Используя тот же
прием, что и при рассмотрении выборочной
процедуры, основанной на нормальном
распределении, получаем выражение для
предела интеграла Лапласа, определяющего
аудиторский риск:
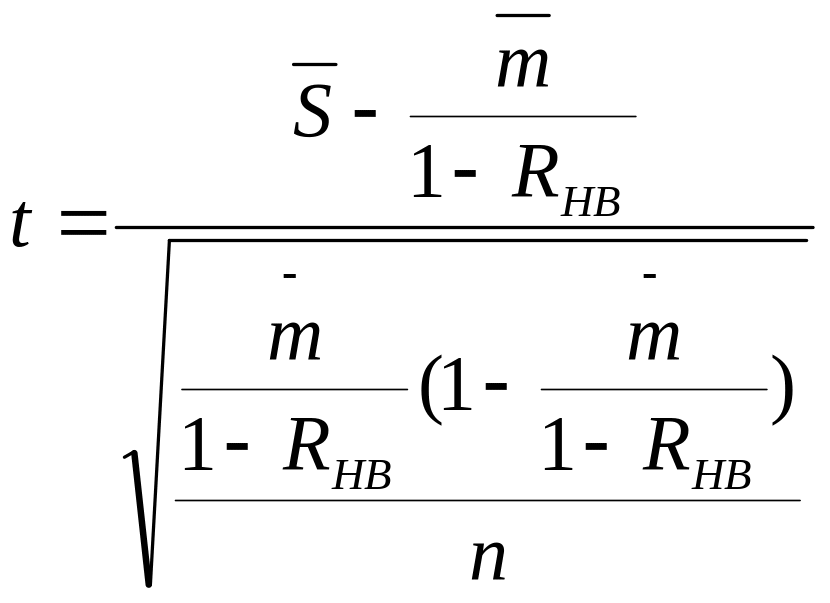
.
(3.31)
Пример. Объем
генеральной совокупности N=2500
счетов-фактур. Объем выборки n
= 100 счетов- фактур. Количество ошибок
(неправильно заполненных счетов-фактур)
в выборке m
= 2. Уровень существенности S
=125 счетов- фактур (5%). Риск RНВ
по
оценке аудитора составляет RНВ
=20%.
Определим ожидаемую ошибку генеральной
совокупности М, риск выборки RВ
и
аудиторский риск RА.
Относительное
количество ошибок в выборке:
![]()
.
Ожидаемая ошибка
генеральной совокупности:
M
= m*N/n
= 2* 2500/100 = 50 счетов-фактур.
Средний уровень
существенности:
![]()
.
Значение предела
интеграла Лапласа, определяющее риск
выборки:
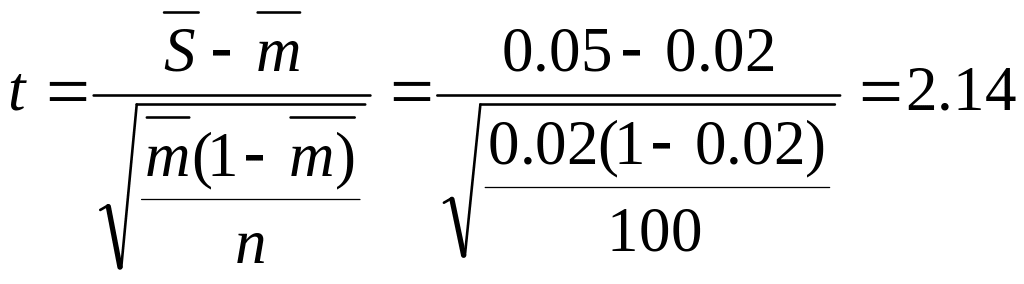
.
При t
=2,14 риск выборки составляет RВ
=0,02
(2%).
Значение интеграла
Лапласа, определяющее аудиторский
риск:
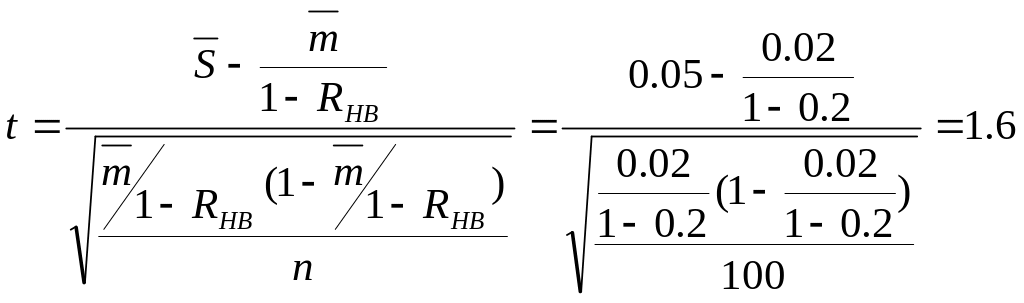
При t
= 1,6 аудиторский риск составляет RА
=5,5%.
Итак, мы получили
выражения, с помощью которых можно
количественно оценить компоненту
аудиторского риска (риск выборки) как
статистическую вероятность при выборочных
проверках, основанных на нормальном
либо биномиальном законах распределения
случайных величин.
Но количественная
оценка риска выборки возможна ещё в
одном случае – при использовании
процедуры «основного массива». Покажем
это.
Выборочная проверка: ожидаемая ошибка
«Аудит и налогообложение», 2012, N 4
Предлагаемый новый метод оценки ожидаемой ошибки в генеральной совокупности и риска выборки при использовании статистического подхода к формированию выборки учитывает дисперсию стоимости элементов генеральной совокупности, что позволяет избежать необходимости ее стратификации.
Федеральным стандартом аудиторской деятельности N 16 «Аудиторская выборка» установлена возможность двух подходов к выборочной проверке: статистического и нестатистического.
Статистический подход к выборочной проверке, согласно ФСАД N 16, означает:
- формирование выборки с помощью случайного (либо систематического со случайным выбором начальной точки) отбора элементов из генеральной совокупности;
- применение теории вероятности (математической статистики) для оценки результатов проверки выборки (оценки ожидаемой ошибки в генеральной совокупности и оценки риска выборки).
На практике при применении статистического подхода к выборочной проверке в качестве процедуры «по существу» часто используют монетарный метод (выборку по денежной единице).
Известно, что использование монетарного метода возможно лишь при однородной стоимости элементов генеральной совокупности. В приведенной далее формуле показано, что при значениях коэффициента вариации стоимости элементов генеральной совокупности, превышающих 0,2:0,3, погрешность монетарного метода может быть весьма существенной. В подобном случае, как считают некоторые специалисты, генеральную совокупность следует стратифицировать по стоимости элементов, в результате чего достигается однородность каждой страты. Однако практика показывает, что подобная рекомендация не всегда бывает эффективной (в некоторых случаях для достижения однородности должно быть несколько страт, что усложняет и формирование выборок, и оценку результатов).
Альтернативой может быть метод, который позволяет оценить ожидаемую ошибку в генеральной совокупности и оценить риск выборки с учетом дисперсии стоимости элементов генеральной совокупности, что позволяет избежать необходимости ее стратификации.
Допустим:
N (в натуральных единицах) — объем генеральной совокупности элементов (операций либо первичных документов, относящихся к обороту счета бухгалтерского учета — накладных, счетов-фактур и т.п.).
J (руб.) — суммарная стоимость элементов, составляющих генеральную совокупность.
Тогда:
N
J = SUM j ,
i=1 i
где j (руб.) - стоимость i-го элемента генеральной совокупности.
i
Предлагаемый метод основан на том, что каждый элемент генеральной совокупности имеет два признака случайности:
- размер (стоимость, руб.);
- «отмеченность» (наличие искажений).
Известным образом определим наиболее вероятное количество отмеченных элементов (элементов, содержащих искажения) в генеральной совокупности. Для этого сформируем случайную выборку элементов объемом n и проверим ее.
Пусть:
m — количество отмеченных элементов в выборке.
Тогда:
w = m/n — относительная частота появления элементов, содержащих искажения, в выборке объемом n.
Наиболее вероятное количество элементов, содержащих искажения, в генеральной совокупности M составит:
M = N x w.
Поскольку мы априорно исходим из случайности распределения элементов, содержащих искажения, в генеральной совокупности, совокупность объемом M элементов, содержащих искажения, применительно к указанному выше первому признаку случайности можно рассматривать как случайную выборку.
_
Обозначим выборочную среднюю выборки объемом M через k (руб.).
Тогда наиболее вероятное значение суммарной стоимости элементов, составляющих выборку объемом M, составит:
_
K = M x k (руб.).
Очевидно, что K — искомая ожидаемая ошибка генеральной совокупности.
_
Для того чтобы найти значение k, вспомним, что наиболее вероятным
значением генеральной средней является значение выборочной средней.
Справедливо и обратное утверждение: наиболее вероятным значением выборочной
средней является значение генеральной средней.
_
Тогда в качестве наиболее вероятного значения выборочной средней k
_
может быть принято известное нам значение генеральной средней j, где:
N
SUM j
_ J i=1 i
j = - = ------.
N N
Для определения риска выборки необходимо найти дисперсию D(K) случайной
_
величины K, являющейся произведением двух случайных величин (M и k). Для
этого найдем дисперсии указанных сомножителей.
Из теории вероятности известно, что дисперсия D(w) относительной частоты w может быть оценена из выражения:
w(1 - w)
D(w) = --------.
n
Поскольку N — величина постоянная, то оценка дисперсии случайной величины M составит:
2
D(M) = N x D(w).
_
Дисперсия выборочной средней D(k) может быть оценена по выборочной
дисперсии D(k):
_ D(k)
D(k) = ----.
M
Выборочная дисперсия D(k), в свою очередь, может быть оценена по генеральной дисперсии D(j) (смещенностью оценки пренебрегаем):
D(k) = D(j).
_
Тогда для оценки дисперсии выборочной средней D(k) получим выражение:
_ D(j)
D(k) = ----.
M
Генеральная дисперсия D(j) в полученном выражении может быть найдена известным образом:
N _ 2
SUM (j - j)
i=1 i
D(j) = ------------.
N
Поскольку случайная величина K является произведением двух независимых случайных величин, то ее дисперсия может быть получена из формулы:
_ _2 _ 2
D(K) = D(M) x D(k) + D(M) x k + D(k) x M .
Среднеквадратичное отклонение случайной величины K:
___
сигма = /D(K).
k
Оценку риска выборки произведем из следующих соображений. Риск выборки — это вероятность того, что ожидаемая ошибка (случайная величина K) превысит уровень существенности S, применяемый для данной генеральной совокупности. Приравняем верхнюю границу доверительного интервала для случайной величины K к применяемому уровню существенности S:
S = K + t x сигма
k
или:
S - K
тау = ------,
сигма
k
где t — предел интеграла Лапласа.
По полученному значению t из таблиц нормального распределения находим значение риска выборки.
Пример. Аудитор проверяет правомерность предъявления НДС к вычету.
Объем генеральной совокупности N = 1000 счетов-фактур.
Дебетовый оборот счета 68 в корреспонденции со счетом 19 — J = 3000 тыс. руб.
Применяемый уровень существенности s = 5% (тогда S = 150 тыс. руб.).
Объем выборки n = 100 счетов-фактур.
В выборке обнаружены два недостоверных счета-фактуры (m = 2).
Генеральная средняя:
_ J 3 000 000
j = - = --------- = 3000 руб.
N 1000
Генеральная дисперсия:
N _ 2
SUM (j - j)
i=1 i
D(j) = ------------ = 2 500 000.
N
Относительная частота:
m 2
w = - = --- = 0,02.
n 100
Наиболее вероятное количество ошибок в генеральной совокупности:
M = N x w = 1000 x 0,02 = 20.
Дисперсия величины M:
2 w(1 - w) 2 0,02 x (1 - 0,02)
D(M) = N -------- = 1000 x ----------------- = 196.
n 100
Дисперсия выборочной средней:
_ D(j) 2 500 000
D(k) = ---- = --------- = 125 000.
M 20
Ожидаемая ошибка:
_
K = M x k = 20 x 3000 = 60 000 руб.
Дисперсия ожидаемой ошибки K:
_ _2 _ 2
D(K) = D(M) x D(k) + D(M) x k + D(k) x M = (196 x 125 000) +
2 2
+ (196 x 3000 ) + (125 000 x 20 ) = 1 838 500 000.
Среднеквадратичное отклонение:
___ _____________
сигма = /D(K) = /1 838 500 000 = 42 878 руб.
k
Предел интеграла Лапласа:
S - K 150 000 - 60 000
t = ------ = ---------------- = 2,1.
сигма 42 878
k
По таблицам нормального распределения получаем:
для t = 2,1 риск выборки составляет 2%.
Ю.Кочинев
Д. э. н.,
профессор
Санкт-Петербургского
политехнического университета,
директор по аудиту
ООО «Аспект-Аудит»