
Диагностика работы сервера и агента Zabbix. Самые простые способы найти причины неработоспособности.
Проблемы, проблемы, проблемы…
В предыдущей статье мы рассматривали процесс установки Zabbix. Сегодня мы коснемся основных способов диагностики работы сервера и агента Zabbix, а также решение некоторых возникающих проблем.
Ничего сверхестественного. Только базовая информация, которая дает представление о том куда нужно двигаться при наличии проблем в работе мониторинга на базе Zabbix.
Как себя чувствует сервер
Бывает, что на сервере возникают какие-либо проблемы, связанные как с самой службой Zabbix-сервера, так и с его взаимодействием с агентами или связанными компонентами. Первый источник информации, который может помочь в поиске причин проблем — это логи Zabbix-сервера. Еще одним важным источником данных может быть сама система мониторинга, которая мониторит сама себя.
Логи наше все
Логи по традиции мира *.nix хранятся в текстовых файлах и располагаются в каталоге ‘/var/log/zabbix’.
[ypermitin@zabbix zabbix]$ ls
zabbix_agentd.log zabbix_agentd.log-20201011 zabbix_server.log-20201004.gz
zabbix_agentd.log-20201004.gz zabbix_server.log zabbix_server.log-20201011
В этом же каталоге можно увидеть файлы логов Zabbix-агента. Чаще всего на сервере Zabbix для отслеживания работы сервера установлен агент. Да, Zabbix-сервер следит сам за собой.
Прочитать содержимое можно стандартными для Linux способами:
- Смотрим файл логов с возможностью прокрутки.
less /var/log/zabbix/zabbix_server.log
- Просмотр файла логов в реальном времени.
tail -f /var/log/zabbix/zabbix_server.log
- Смотрим первые записи
head /var/log/zabbix/zabbix_server.log
- Смотрим последние события
tail -n 30 /var/log/zabbix/zabbix_server.log
- Получаем только записи с ошибками
grep -i error /var/log/zabbix/zabbix_server.log
В общем, это самые простые способы прочитать содержимое файла логов. Если Вы знаете что нужно искать, то grep Вам в помощью. В противном случае в бой вступает tail, но можно выполнять анализ и более сложными способами.
Вот, например, вывод последних 10 событий из файла логов.
[ypermitin@zabbix zabbix]$ tail -n 10 /var/log/zabbix/zabbix_server.log
1370:20201016:230008.844 housekeeper [deleted 4601 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.047217 sec, idle for 1 hour(s)]
1370:20201017:000346.901 executing housekeeper
1370:20201017:000346.958 housekeeper [deleted 4857 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.053027 sec, idle for 1 hour(s)]
1386:20201017:002028.428 Zabbix agent item "system.swap.size[,free]" on host "YY-COMP" failed: first network error, wait for 15 seconds
1394:20201017:002043.521 Zabbix agent item "system.uptime" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002058.554 Zabbix agent item "agent.ping" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002113.579 temporarily disabling Zabbix agent checks on host "YY-COMP": host unavailable
1394:20201017:003815.366 enabling Zabbix agent checks on host "YY-COMP": host became available
1370:20201017:010352.434 executing housekeeper
1370:20201017:010352.503 housekeeper [deleted 4599 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.063396 sec, idle for 1 hour(s)]
Здесь мы видим события процесса housekeeper, который отвечает за удаление устаревшей информации из базы данных мониторинга. Далее идут более интересные события об ошибке связи с хостом “YY-COMP”, а также события последующего восстановления соединения с агентом этого хоста.
1386:20201017:002028.428 Zabbix agent item "system.swap.size[,free]" on host "YY-COMP" failed: first network error, wait for 15 seconds
1394:20201017:002043.521 Zabbix agent item "system.uptime" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002058.554 Zabbix agent item "agent.ping" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002113.579 temporarily disabling Zabbix agent checks on host "YY-COMP": host unavailable
1394:20201017:003815.366 enabling Zabbix agent checks on host "YY-COMP": host became available
В любом случае, основным источником данных о том, что и как делает процесс Zabbix-сервера, есть ли у него проблемы и другую связанную с ним информацию можно найти в его логах. Метод “тыка” тоже работает, но эффективнее просто посмотреть в файл лога событий.
Мониторинг системы мониторинга
Благодаря тому, что Zabbix позволяет собирает метрики о состоянии самого себя, мы можем отслеживать некоторые проблемы с его помощью. После установки сервера, по умолчанию в списке хостов содержится сам сервер с шаблоном “Template App Zabbix Server”.

Этот шаблон является ключевым для диагностики работы Zabbix, т.к. содержит множество полезных метрик и триггеров на критичные события.

Например, если Вы увидите уведомления о проблеме “Zabbix poller processes more than 75% busy” от одного из триггеров этого шаблона, то идем в официальную документацию и читаем что это. Можно увидеть, что проблему можно решить изменив параметр “StartPollers” в файле конфигурации Zabbix-сервера.
Вообще, оптимизация настроек этой системы мониторинга отдельная тема, но должно быть понятно, что следить за сервером Zabbix является неотъемлемой частью мониторинга. Иначе как Вы узнаете, что пора актуализировать настройки сервера или проапгрейдить железо?
Все в очередь
Кроме логов и мониторинга Zabbix-сервера есть еще один важный показатель, демонстрирующий общую картину производительности процессов системы мониторинга. Причем помогает диагностировать проблемы не только в работе сервера, но и агентов Zabbix.
Речь идет про очередь обработки элементов данных, которая отлично описана в официальной документации. На следующем скриншоте показана идеальная картина, когда никаких очередей нет и все элементы обрабатываются за минимальное время.

Самыми распространёнными причинами увеличения очереди являются:
- Агент сбора данных стал недоступен и не присылает данные / не может ответить на запрос.
- У сервера не хватает ресурсов для выполнения обработки присланных элементов данных или опроса хостов (зависит от типа агента — активный или пассивный).
В случаях, когда Вы будете наблюдать большие значения очередей с периодом обработки более 1 минуты, то стоит насторожиться и начать диагностику сервера и агентов.
Вы всегда можете посмотреть элементы очереди детально, чтобы понять, где именно появилась проблема. Плюс ко всему, очередь обработки сообщений можно добавить в метрики сбора данных мониторинга и привязать на них триггеры. Таким образом, очереди позволяют отслеживать общее состояние как сервера Zabbix, так и состояние всего мониторинга с учетом агентов.
База данных требует внимания
Zabbix хранит данные метрик в одной из поддерживаемых СУБД: MySQL или PostgreSQL. Для оптимальной производительности обязательно нужно выполнить их настройку. Я предпочитаю использовать PostgreSQL, но тут все полностью зависит от задач.
Касательно PostgreSQL нужно обязательно адаптировать ее настройки под ресурсы сервера, т.к. по умолчанию там установлены максимальные ограничения на используемую память и другие ресурсы. Рекомендую зайти на сайт PGTune, который поможет подобрать параметры СУБД под Ваш сервер. Просто берете и переносите их в свой файл конфигурации “postgresql.conf”.
Конечно, со временем может понадобиться адаптировать эти параметры под свою нагрузку и задачи. Подробнее о настройках Вы можете прочитать здесь.

То же самое относится и к MySQL. Вы можете обратиться к официальной документации, чтобы узнать больше.
Главное помнить, что настройки сервера баз данных являются ключевым фактором для достижения высокой производительности всей системы мониторинга.
Агент еще жив
Основные способы диагностики сервера Zabbix мы рассмотрели. А что на счет агентов на хостах, которые входят в мониторинг?
Выше уже было упомянуто, что у агента есть свои логи. Именно они и являются основным источником данных для диагностики его работы. Если мы говорим о *.nix системах, то обычно файл лога находится в “/var/log/zabbix/zabbix_agent.log”. Вот, например, его содержимое при старте процесса агента.
[ypermitin@zabbix zabbix]$ tail -n 30 /var/log/zabbix/zabbix_agentd.log
88139:20201017:164146.511 Starting Zabbix Agent [Zabbix server]. Zabbix 4.0.25 (revision 32662425e6).
88139:20201017:164146.511 **** Enabled features ****
88139:20201017:164146.511 IPv6 support: YES
88139:20201017:164146.511 TLS support: YES
88139:20201017:164146.511 **************************
88139:20201017:164146.511 using configuration file: /etc/zabbix/zabbix_agentd.conf
88139:20201017:164146.511 agent #0 started [main process]
88140:20201017:164146.511 agent #1 started [collector]
88141:20201017:164146.512 agent #2 started [listener #1]
88144:20201017:164146.513 agent #5 started [active checks #1]
88143:20201017:164146.515 agent #4 started [listener #3]
88142:20201017:164146.516 agent #3 started [listener #2]
Это идеальный вариант, когда агент был запущен и никаких проблем с его работой не наблюдается. Но там могут быть и ошибки или информация о проблемах связи. Например, вот это событие говорит о том, что что-то блокирует доступ агента к серверу Zabbix.
3900:20201017:002349.716 active check configuration update from [192.168.11.149:10051] started to fail (cannot connect to [[192.168.11.149]:10051]: (null))
Может не открыт порт на сервере? Или сервер недоступен? Или ошибка в конфигурационном файле агента?
Аналогичный файл лога есть для агентов всех поддерживаемых операционных систем, в том числе и Windows. Его расположение можно уточнить в самом конфигурационном файле агента в параметре “LogFile”. Для Windows это может быть каталог самого агента, например:
### Option: LogFile
# Log file name for LogType 'file' parameter.
#
# Mandatory: no
# Default:
# LogFile=
LogFile=C:Program FilesZabbixAgentzabbix_agentd.log
В любом случае, если у Вас проблемы в работе агента, то первым делом идем в его логи и смотрим что вообще происходит.
Решение некоторых проблем
Рассмотрим решение некоторых проблем в работе сервера и агента. Это ни в коем случае не полноценный мануал, а скорее пара заметок. Небольшая порция “траблшутинга”. Более развернутую информацию Вы можете найти в официальной Wiki.
Немного опечатались
Иногда бывает так, что порты и все доступы настроены, агент установлен, ошибок в логах нет, но метрики не приходят или приходят не полностью. В самом Zabbix хост “горит зеленым” и непонятно, что вообще происходит.

Можно потратить много времени на разбор ситуации, а причина окажется очень проста — ошибка в файле конфигурации из-за “копипасты”. То есть конфигурацию скопировали, но в файле не поменяли параметр “Hostname”. В итоге сервер Zabbix говорит, что агент доступен, но сам агент присылает данные для другого хоста. Вот так выглядит список дисков для проблемной машины. Нет никакой информации о дисках, но при этом общие показатели агент все же передал.

Как только мы исправим в файле конфигурации параметр “Hostname” на нужный (в нашем случае это “SRV-SQL-01-VM”), то картина сразу же изменится. В списке появятся все диски сервера.

Данные могут появиться не сразу, т.к. правила обнаружения выполняются не так часто, как получение обычных метрик, но Вы можете запустить их вручную в настройках хоста.
Копипаст — зло! Будьте осторожны!
Ребут и агента нет
Бывают случаи, когда агент был успешно установлен и настроен на хосте, мониторинг работает как надо. НО! При очередном запланированном перезапуске сервера (хоста) Zabbix-агент не смог запуститься.
Причин тому может быть несколько:
- Агент запускается от доменной учетной записи, но на момент старта сервера связи с доменом не оказалось.
- В момент запуска агент пытался запуститься, когда еще не “поднялся” доступ к сети.
При этом в файле лога агента может не быть какой-либо полезной информации, но она есть в системных журналах ОС. Чаще всего это поведение встречал в ОС Windows.
Решение достаточно простое: нужно установить для службы Windows режим запуска “Автоматически (отложенный запуск)”. В большинстве случаев проблема будет решена.

Быстро и просто!
Особые проблемы со счетчиками
Особой проблемой, которая встречается не очень часто, бывают проблемы со счетчиками производительности Windows. После настройки мониторинга на сервере можно увидеть для хоста элементы данных со статусом “Не поддерживается”. При этом все они получаются через показатели производительности Windows. Обратившись к логам агента Zabbix можно увидеть следующее.
zabbix agent log: check_counter_path(): cannot make counterpath
zabbix agent log: A required argument is missing or not correct.... active check "perf_counter[....]" is not supported
При этом для хоста у элементов данных будет такая ошибка.
ZBX_NOTSUPPORTED: Cannot obtain system information.
Проблема в некорректном списке доступных счетчиков производительности Windows на хосте с агентом, то есть на машине, которую мы собираемся мониторить. Можно проверить наличие нужного счетчика через “Монитор производительности” (perfmon.exe) или через ветку реестра:
"HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionPerflib09"
# Ключ "Counter" содержит список всех доступных счетчиков производительности.
Если нужного счетчика нет, то можно попытаться перестроить все счетчики ОС командой:
lodctr /r
# Утилита находится в "C:WINDOWSSystem32"
В большинстве случаев это помогает. Если остаются проблемы со счетчиками производительности сторонних приложений, то нужно изучить документацию по этим счетчикам. Например, для Microsoft SQL Server можно отдельно восстановить счетчики из поставляемых настроек. Подробнее можно узнать здесь.
Счетчики производительности для мониторинга Windows — отличный инструмент. И его, конечно же, нужно использовать.
Таймаут выполнения скриптов
Еще небольшой ошибкой может быть ситуация, когда на сервер не поступают данные по каким-либо элементам данных, а в логах агента можно увидеть ошибки вида:
ZBX_NOTSUPPORTED: Timeout while executing a shell script
Так происходит, поскольку выполняемый скрипт не укладывается в заданное время выполнения. Время задается также в конфигурации агента Zabbix и по умолчанию составляет 3 секунды.
### Option: Timeout
# Spend no more than Timeout seconds on processing
#
# Mandatory: no
# Range: 1-30
# Default:
# Timeout=3
Имеется три основных варианта решения:
- Увеличить таймаут до подходящего значения. Например, до 30 секунд:
### Option: Timeout
# Spend no more than Timeout seconds on processing
#
# Mandatory: no
# Range: 1-30
# Default:
# Timeout=3
Timeout=30
-
Второй вариант — разобраться в причинах долгого выполнения и попытаться их исправить. Конечно, если это возможно.
-
Отказаться от сбора этих метрик

В любом случае, посмотрите почему скрипт может выполняться дольше, чем запланировано. Только после этого меняйте настройки.
Продолжение следует
Это была еще одна небольшая публикация по теме мониторинга с помощью Zabbix. В следующих статьях мы поговорим об обновлении Zabbix с версии 4.0 на 5.0, создадим свой шаблон для сбора метрик и рассмотрим некоторые особенности этого процесса, настроим уведомления в Telegram-канал, а также получении данных с Prometheus и визуализации данных в Grafana. И, конечно же, оптимизация производительности сервера мониторинга Zabbix!
Будьте на связи 
Будьте в курсе
Создание материалов будет продолжаться. Хотите быть в курсе последних обновлений? Подписывайтесь на канал.
По любым вопросам пишите на электронную почту. Адрес в самом низу страницы.
Уровень сложности
Простой
Время на прочтение
4 мин
Количество просмотров 6.7K
Не смог найти нормальную актуальную инструкцию по мониторингу линуксовых логов забиксом — сделал свою, под 6.4.
И отвлекусь на установку агента — не зря же писал скрипт…
Установка и настройка агента
Открываем консоль на машине которую собираемся мониторить, локально или подключившись по SSH. Ставим zabbix-agent, рекомендуют использовать вторую версию. Я ставлю из RPM пакета, ссылку на версию под свою ОС берём на https://www.zabbix.com/ru/download

Обычно версию системы можно узнать, введя в консоль.
hostnamectlВ моём случае это восьмая версия «Operating System: Rocky Linux 8.7 (Green Obsidian)»
Однако бывают подлости, например fedora 37 отсутствует в списке дистрибутивов и это не проблема — достаточно спросить у гугла на чём она основана, либо спросить через консоль и посмотреть результат (вторая строка)
cat /proc/version
Linux version 6.2.15-200.fc37.x86_64 (mockbuild@bkernel02.iad2.fedoraproject.org) (gcc (GCC) 12.2.1 20221121 (Red Hat 12.2.1-4), GNU ld version 2.38-27.fc37) #1 SMP...Соответственно выбираем Red Hat. А вот универсального решения для определения версии ос у меня нет, хотя чтение страницы редхата на википедии намекает на девятую версию.
Проверяем что в данный момент агент не установлен(вывод должен быть пустым):
systemctl list-units --type service | grep -E "*zabbix*"Непосредственно инсталляцию можно провести так как рекомендует заббикс во втором пункте, но использование rpm не самый удобный способ поэтому я заменил вызов на dnf с ключём автоподтверждения
dnf install https://repo.zabbix.com/zabbix/6.4/rhel/8/x86_64/zabbix-release-6.4-1.el8.noarch.rpm -y
dnf install zabbix-agent2 zabbix-agent2-plugin-* -yДля получения данных из файла необходимо запускать агент в активном режиме поэтому прописываем в конфиг ip сервера и стираем хостнэйм чтоб он брался из имени компьютера. И запускаем сервис.
sed -i 's/^Server=127.0.0.1/Server=192.168.6.22/' /etc/zabbix/zabbix_agent2.conf
sed -i 's/^ServerActive=127.0.0.1/ServerActive=192.168.6.22/' /etc/zabbix/zabbix_agent2.conf
sed -i 's/^Hostname=Zabbix server/ /' /etc/zabbix/zabbix_agent2.conf
systemctl enable zabbix-agent2 --nowОсталось выдать заббикс агенту правана чтение интересующего файла:
chown root:zabbix /var/log/messages
chmod 640 /var/log/messages*Настройки на Zabbix сервере
Идём в Сбор данных>Шаблоны>Создать шаблон. Указываем произвольное имя шаблона на английском и группу, добавляем и ищем его в общем списке. Переключаемся на вторую вкладку «Элементы данных» и создаём новый.
Произвольное имя и обязательно тип «Zabbix агент (активный)».
Ключ log[/var/log/messages,kernel] включает в себя:
Log позволяет читать дополняемые файлы, используйте logrt для файлов с ротацией. Не смотря на то messages архивирует старые данные ротацией — нас интересует только свежак, да и заббикс будет хранить в себе копию лога
/var/log/messages — путь к файлу, с этим всё понятно. А вот дальше интереснее — kernel это подстрока при наличии которой данные будут пересылаться на сервер. Нам нужны только важные события поэтому мы и выбираем kernel, разумеется для своих целей смотрим в файл и решаем что интересно именно вам.
Тип информации Журнал (лог). Интервал обновления я поставил в секунду — это не вызывает проблем с производительностью

Но и в кернелах хватает мусора! Переключаем на вкладку Предобработка в столбце Имя (очевидный косяк перевода) выставляем Замена, в параметрах какое значение нам необходимо фильтровать. Обратите внимание что параметры регистрозависимы.

Осталось заставить заббикса выводить оставшуюся информацию на главную панель.
На вкладке Тригер создаём новый Имя произвольное а вот в Имя события можно выводить полезную информацию. Мне удобно выводить имя устройства и всю строку переданную с заббикс агента. К слову ITEM.LASTVALUE2 выведет предпоследнюю строку и т. д.
Выражение — при появлении элемента данных найти в нём то что мы добавили в предобработке и проигнорировать, а остальные строки показать. Если поставим =1 покажет только строку добавленную в предобработку. Формируется этот запрос разумеется через кнопку Добавить — выбираем Элемент данных, Функцию find и всё!
Режим генерации событий ПРОБЛЕМА Множественная позволяет обрабатывать каждую строку по отдельности, хоть и не гарантирует оригинальный порядок строк.
Одиночный режим выводит только одну строку из полученных за последний Интервал обновления.
Генерация ОК события я отключаю, так как выводятся только важные события на которые стоит обратить пристальное внимание, но часто используют выражения вида nodata(/log_messages_kernel/log[/var/log/messages,kernel],15m)=0 — отсутствие событий за последние 15 минут. Вот только это не работает с Множественным режимом генерации проблем и вам придётся городить скрипты или зависимые события.
Ну и разрешить ручное закрытие разумеется.

Последний этап добавить узел сети Сбор данных, Узлы сети, Создать узел сети.
Имя узла сети для активного агента обязательно указывать таким же как в агенте. Если на агенте оно явно не прописано в строке Hostname файла /etc/zabbix/zabbix_agent2.conf, то берётся название из строки Static hostname: вывода команды hostnamectl что удобно для автоматизации процесса развёртывания.
Добавляем в Шаблоны только что созданный и Linux by Zabbix agent active для мониторинга стандартных метрик. Разумеется можно было добавить тригеры и элементы данных в стандартный шаблон, но очевидно это плохая практика.
Так же задаём удобную Группу узлов сети, Интерфейс с типом Агент и IP адресс машины с агентом.
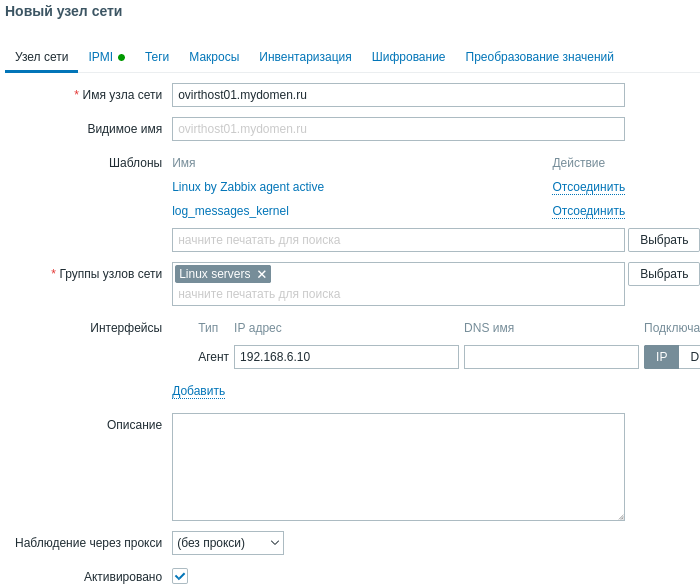
Готово!
")
Данная статья рассказывает о мониторинге журналов Windows через Zabbix и служит опорой в виде практических примеров, реализованных мной ранее. Важным моментом здесь является не столько сбор данных самого журнала, сколько правильная настройка триггера.

Шаблон или прототип элемента мониторинга будет выглядеть следующим образом (параметры для удобства пронумерованы):
eventlog[1- имя журнала,2-регулярное выражение,3-важность,4-источник,5-eventid,6-макс кол-во строк, 7-режим]
Тип данных: журнал (лог)

Далее рассмотрим конкретные практические примеры.
1. Ошибки в журнале приложений.
Максимально простой пример сбора ошибок в журнале «Приложение» (события уровня «Ошибка»)
eventlog[Application,,"Error",,,,skip]
2. Ошибки отложенной записи.
eventlog[System,,"Warning",,50,,skip]
краткие пояснения:
System — журнал система
Warning — тип события: предупреждение
50 — id события равно 50
skip — берем только свежие значения (не перечитываем весь лог)
триггер:
count(/Terminal server/eventlog[System,,"Warning",,50,,skip],30m)>7 and nodata(/Terminal server/eventlog[System,,"Warning",,50,,skip],60m)<>1
где Terminal server — это просто имя шаблона, в котором используются элемент данных и триггер
3. Ошибки диска.
eventlog[System,,"Warning",,153,,skip]
триггер:
count(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],30m)>5 and nodata(/Template OS Windows by Zabbix agent active/eventlog[System,,"Warning",,153,,skip],60m)<>1
4. ошибки в журнале событий от службы MSSQLSERVER.
eventlog[Application,,"Error","MSSQLSERVER",,,skip]
триггер:
count(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],8m)>0 and nodata(/Template OS Windows SQL for 1C/eventlog[Application,,"Error","MSSQLSERVER",,,skip],10m)<>1
Полезные ссылки:
https://www.zabbix.com/documentation/5.0/ru/manual/config/items/itemtypes/zabbix_agent/win_keys
![]() The Windows Zabbix Agent provides a native interface to the Windows Performance Counters. and Event Log. This means that with minimal overhead, and no additional shells out to Powerscript or the command line, you can collect any of the metrics available from PerfMon or Event Viewer.
The Windows Zabbix Agent provides a native interface to the Windows Performance Counters. and Event Log. This means that with minimal overhead, and no additional shells out to Powerscript or the command line, you can collect any of the metrics available from PerfMon or Event Viewer.
Windows Event Log
To monitor the Windows Event log, use the eventlog[] item keys. This takes the syntax:
eventlog[name,<regexp>,<severity>,<source>,<eventid>,<maxlines>,<mode>]
I would always recommend using Event Viewer on the host to determine which event log names and exact codes you want to pull before trying to craft the query parameters.
As an example, let’s capture all the interactive login events happening on the host which are logged in the “Security” event log. On a host that has a Zabbix Agent on Windows, create an item with the type “Zabbix agent (active)”:
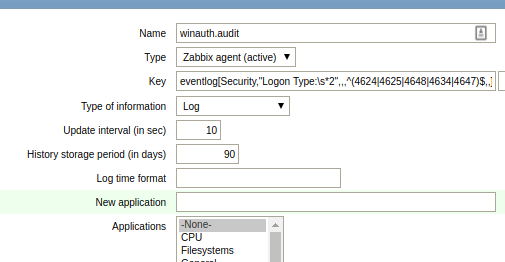
Name: winauth.audit Type: Zabbix agent (active) Key: eventlog[Security,"Logon Type:s*2",,,^(4624|4625|4648|4634|4647)$,,] Type of information: Log Update interval: 30
These 46xx codes are documented by Microsoft, and the logon type=2 signifies interactive logon.
Now going to Monitoring > Latest data after an interactive login should show you the event log entry within 30 seconds. This will show both successful as well as login failures.
Windows Performance Counters
The PerfMon tool comes standard on Windows hosts and can be used to capture and display live metrics as they are collected by the system.
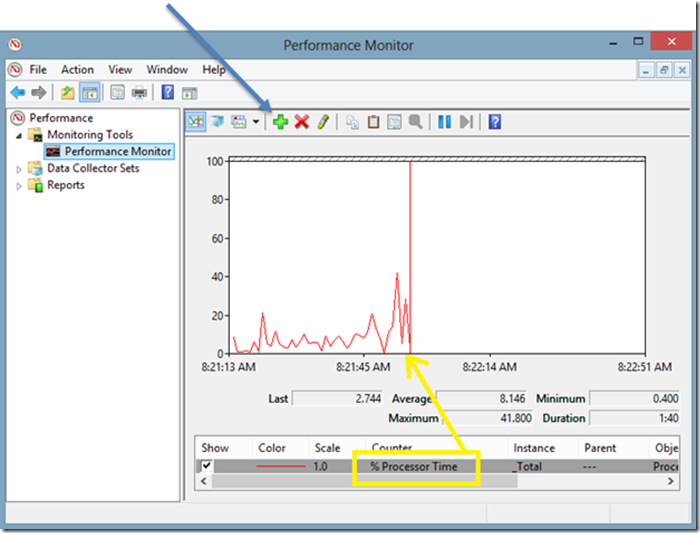
Collecting these same metrics using the Zabbix agent can be done using the perf_counter key. The syntax is:
perf_counter[counter,<interval>]
The easiest way to discover the full path to these counters is to use PerfMon to first find and examine the keys. But you can also list all the full paths from the command line using “typeperf -qx”.
In this example, I’m going to monitor the keys for:
- Microsoft IIS total GET and PUSH operations
- Microsoft FTP Server total files sent and received
- Microsoft SMTP server total mail received, delivered, and pending
Which are represented as the Zabbix key values below:
perf_counter["Web Service(_Total)Total Get Requests",30] perf_counter["Web Service(_Total)Total Post Requests",30] perf_counter["Microsoft FTP Service(_Total)Total Files Sent",30] perf_counter["Microsoft FTP Service(_Total)Total Files Received",30] perf_counter["SMTP Server(_Total)Remote Queue Length",30] perf_counter["SMTP Server(_Total)Messages Received Total",30] perf_counter["SMTP Server(_Total)Messages Delivered Total",30]
This looks like the following when viewed in the Latest Data:
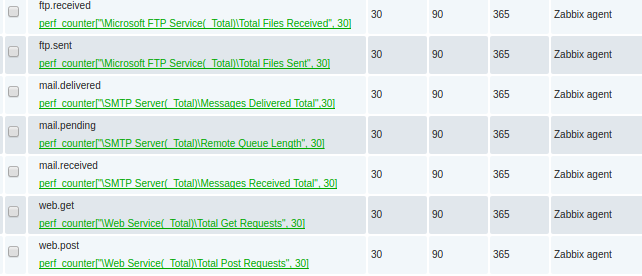
Each of these items created should be type=numeric(float) with an interval every 60 seconds.
REFERENCES
https://zabbix.org/wiki/Get_Zabbix
https://msdn.microsoft.com/en-us/library/ms804624.aspx (Web Service Object)
https://www.zabbix.com/documentation/3.0/manual/appendix/config/zabbix_agentd_win (agent conf, PerfCounter is sythesized avg value of sys perf meaning it needs float)
https://www.zabbix.com/documentation/2.4/manual/appendix/config/zabbix_agentd_win?s[]=perfcounter
https://www.zabbix.com/documentation/3.2/manual/config/items/itemtypes/zabbix_agent/win_keys (special item keys for Zabbix Windows agents)
https://blogs.technet.microsoft.com/brad_rutkowski/2007/09/22/using-typeperf-to-get-performance-data-on-the-command-prompt/
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd941621(v%3dws.10) (4634 4646 audit logoff)
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd941635(v%3dws.10) (4624,4625,4648 audit logon)
https://social.microsoft.com/Forums/en-US/712230b0-2d99-4cda-a374-1211117bf2a8/create-a-custom-security-log-event?forum=Offtopic (cannot write to security log, permissions)
NOTES
$ svn co svn://svn.zabbix.com/branches/2.4 (checkout source code)
eventcreate /l System /t INFORMATION /id 99 /d “just a test” (ids < 1000)
Write–EventLog –LogName Application –EntryType Error –Source MSSQLSERVER –EventId 1479 –Message “Test error event – ignore” (cannot write to SECURITY due to permissions)
Monitoring postfix queue on linux:
EnableRemoteCommands=1
UserParameter=mail.pending[*],/usr/sbin/postqueue -p | egrep -c “^[0-9A-F]{10}[^*]”
UserParameter=mail.active[*],/usr/sbin/postqueue -p | egrep -c “^[0-9A-F]{10}[*]”
typeperf -qx
typeperf -qx “SMTP Server”
typeperf -qx “Web Service”
typeperf -qx “Microsoft FTP Server” (“FTP Service” on older IIS6)
И есть ли в этом смысл?

Для тех, кто задумался и сомневается, я решил описать кое-что из своего опыта.
Мониторинг вообще штука полезная, бесспорно. У меня лично в какой-то период возникло сразу несколько задач:
-
Круглосуточно и непрерывно мониторить одну специфическую железку по ряду параметров;
-
Мониторить у рабочих станций информацию о температурах, ЦП в первую очередь;
-
Всякие мелочи в связи с широким внедрением удалёнки: количество подключений по VPN, общее состояние дополнительных виртуальных машин.
Подробнее про локальные задачи:
-
Надо было оценить и наглядно представить данные об интернет-канале. Канал на тот момент представлял собой 4G-роутер Huawei. Это устройство было последним, но далеко не первым в огромном количестве плясок с бубном в попытках избавиться от разного рода нестабильностей. Забегая вперёд: забирать с него данные напрямую о качестве сигнала более-менее стандартными средствами оказалось невозможно, и даже добраться до этих данных — отдельный квест. Пришлось городить дендрофекальную конструкцию, которая, на удивление стабильно, и стала в итоге поставлять данные. Данные в динамике и в графическом представлении оказались настолько неутешительными, что позволили убедить всех причастных таки поменять канал, даже и на более дорогой;
-
Данные о температуре процессора дают сразу несколько линий: можно обнаружить шифровальщик в процессе работы, наглядно сделать вывод о недостаточной мощности рабочей станции, найти повод провести плановую чистку, узнать о нарушении условий эксплуатации. Последний пункт особенно хорош: множество отказов оборудования и BSOD’ов в итоге нашли причину в «я ставлю обогреватель под стол, ну и свой баул, ну да, прям к этой решётке. А что? А я канпуктер развернула, а то неудобно»;
-
Интерфейс того же OpenVPN… ну, он в общем даже и не интерфейс и оставляет желать любого другого. Отдельная история.
Как большой любитель велосипедить всё подряд, сначала я решил свелосипедить и это. Уже валялись под рукой всякие скрипты по сбору статистки, и html проекты с графиками на js, и какие-то тестовые БД… Но тут сработала жадность (и лень, чоужтам). А чего это, подумал я, самому опять корячиться, если в том же Zabbix уже куча всяких шаблонов, и помимо задач из списка можно будет видеть много чего ещё? Да и он бесплатный к тому же. Всего-то делов, виртуалку поднять да клиенты централизованно расставить. Потренируюсь с ним, опять же, он много где используется.
Итак, нам понадобятся:
-
Виртуальная машина или физический хост. Zabbix нетребователен к ресурсам при небольшом количестве хостов на мониторинге: мне хватило одного виртуального процессора на 2ГГц и 4 Гб RAM за глаза;
-
Любой инструмент для автоматического раскидывания zabbix-agent. При некотором скилле это можно делать даже через оригинальный WSUS, или просто батником с psexec, вариантов много. Также желательно запилить предварительно сконфигурированный инсталлятор агента — об этом ниже;
-
Много желания пилить напильником. Скажу честно и сразу: из первоначального списка 3 из 3 реализовывалось руками на местности. Zabbix стандартной комплектации в такое не может.
У Zabbix много вариантов установки. В моём случае (я начинал с 4 LTS) сработала только установка руками в чистую, из собственного образа, OC в виртуальной машине на Hyper-V. Так что, коли не получится с первого раза, — не сдавайтесь, пробуйте. Саму процедуру подробнее описывать не буду, есть куча статей и хороший официальный мануал.

Про формирование инсталлятора агента: один из самых простых способов — использовать утилиты наподобие 7zfx Builder . Нужно будет подготовить:
-
файл zabbix_agentd.conf ;
-
файлы сторонних приложений и скриптов, используемых в userParameters (об этом ниже) ;
-
скрипт инсталлятора с кодом наподобие этого:
SETLOCAL ENABLEDELAYEDEXPANSION
SET INSTDR=C:ZabbixAgent
SET IP=192.168.100.10
set ip_address_string="IPv4-адрес"
for /f "usebackq tokens=2 delims=:" %%F in (ipconfig ^| findstr /c:%ip_address_string%) do SET IP=%%F
SET IP=%IP: =%
ECHO SourceIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO ListenIP=%IP%>> "%INSTDR%confzabbix_agentd.conf"
ECHO Hostname=%COMPUTERNAME%>> "%INSTDR%confzabbix_agentd.conf"
"%INSTDR%binzabbix_agentd.exe" -c "%INSTDR%confzabbix_agentd.conf" -i
net start "Zabbix Agent"
ENDLOCALКстати, об IP. Адрес в Zabbix является уникальным идентификатором, так что при «свободном» DHCP нужно будет настроить привязки. Впрочем, это и так хорошая практика.
Также могу порекомендовать добавить в инсталлятор следующий код:
sc failure "Zabbix Agent" reset= 30 actions= restart/60000Как и многие сервисы, Zabbix agent под Windows при загрузке ОС стартует раньше, чем некоторые сетевые адаптеры. Из-за этого агент не может увидеть IP, к которому должен быть привязан, и останавливает службу. В оригинальном дистрибутиве при установке настроек перезапуска нет.
После этого добавляем хосты. Не забудьте выбрать Template – OS Windows. Если сервер не видит клиента — проверяем:
-
IP-адрес;
-
файрвол на клиенте;
-
работу службы на клиенте — смотрим zabbix_agentd.log, он вполне информативный.
По моему опыту, сервер и агенты Zabbix очень стабильны. На сервере, возможно, придётся расширить пул памяти по active checks (уведомление о необходимости такого действия появляется в дашборде), на клиентах донастроить упомянутые выше нюансы с запуском службы, а также, при наличии UserParameters, донастроить параметр timeout (пример будет ниже).
Что видно сразу, без настроек?
Сразу видно, что Zabbix заточен под другое Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
В общем-то, очень неплохо, но…
Что доделывать?
Оооо. Ну, хотел повелосипедить, так это всегда пожалуйста. Прежде всего, нет алертов на события типа «критические» из системного лога Windows, при том, что механизм доступа к логам Windows встроенный, а не внешний, как Zabbix agent active. Странно, ну штош. Всё придётся добавлять руками.
Например
для записи и оповещения по событию «Система перезагрузилась, завершив работу с ошибками» (Microsoft-Windows-Kernel-Power, коды 41, 1001) нужно создать Item c типом Zabbix agent (active) и кодом в поле Key:
eventlog[System,,,,1001]По этому же принципу создаём оповещения на другие коды. Странно, но готового template я не нашёл.
Cистема автоматизированной генерации по службам генерирует целую тучу спама. Часть служб в Windows предполагает в качестве нормального поведения тип запуска «авто» и остановку впоследствии. Zabbix в такое не может и будет с упорством пьяного сообщать «а BITS-то остановился!». Есть широко рекомендуемый способ избавления от такого поведения — добавление набора служб в фильтр-лист: нужно добавить в Template «Module Windows services by Zabbix agent», в разделе Macros, в фильтре {$SERVICE.NAME.NOT_MATCHES} имя службы в формате RegExp. Получается список наподобие:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|
clr_optimization_v.+|clr_optimization_v.+|
sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|
MapsBroker|IntelAudioService|Intel(R) TPM Provisioning Service|
dbupdate|DoSvc|BITS.*|ShellHWDetection.*$И он не работает работает с задержкой в 30 дней.

Про службы, автоматически генерируемые в Windows 10, я вообще промолчу.
Нет никаких температур (но это, если подумать, ладно уж), нет SMART и его алертов (тоже отдельная история, конечно). Нет моих любимых UPS.
Некоторые устройства генерируют данные и алерты, работу с которыми надо выстраивать. В частности, например, управляемый свитч Tp-Link генерирует интересный алерт «скорость на порту понизилась». Почти всегда это означает, что рабочая станция просто выключена в штатном режиме (ушла в S3), но сама постановка вопроса заставляет задуматься: сведения, вообще, полезные — м.б. и драйвер глючит, железо дохнет, время странное…
Некоторые встроенные алерты требуют переработки и перенастройки. Часть из них не закрывается в «ручном» режиме по принципу «знаю, не ори, так надо» и создаёт нагромождение информации на дашборде.
Короче говоря, многое требует допиливания напильником под местные реалии и задачи.

О локальных задачах
Всё, что не встроено в Zabbix agent, реализуется через механизм Zabbix agent (active). Суть проста: пишем скрипт, который будет выдавать нужные нам данные. Прописываем наш скрипт в conf:
UserParameter=имя.параметра,путькскрипту Нюансы:
-
если хотите получать в Zabbix строку на кириллице из cmd — не надо. Только powershell;
-
если параметр специфический – для имени нужно будет придумать и сформулировать дерево параметров, наподобие «hardware.huawei.modem.link.speed» ;
-
отладка и стабильность таких параметров — вопрос и скрипта, и самого Zabbix. Об этом дальше.
Хотелка №1: температуры процессоров рабочих станций
В качестве примера реализуем хотелку «темература ЦП рабочей станции». Вам может встретиться вариант наподобие:
wmic /namespace:rootwmi PATH MSAcpi_ThermalZoneTemperature get CurrentTemperatureно это не работает (вернее, работает не всегда и не везде).
Самый простой способ, что я нашёл — воспользоваться проектом OpenHardwareMonitor. Он свои результаты выгружает прямо в тот же WMI, так что температуру получим так:
@echo OFF
SETLOCAL ENABLEDELAYEDEXPANSION
SET TMPTMP=0
for /f "tokens=* skip=1 delims=" %%I in ('wmic /namespace:rootOpenHardwareMonitor PATH Sensor WHERE Identifier^="/intelcpu/0/temperature/1" get Value') DO (
SET TMPTMP=%%I && GOTO :NXT
)
:NXT
ECHO %TMPTMP%
ENDLOCAL
GOTO :EOFКонечно, при условии, что OHM запущен. В текущем релизе OHM не умеет работать в качестве Windows service. Так что придётся либо смущать пользователей очередной иконкой в трее, либо снова городить свой инсталлятор и запихивать OHM в сервисы принудительно. Я выбрал поcледнее, создав инсталляционный cmd для всё того же 7zfx Builder наподобие:
nssm install OHMservice "%programfiles%OHMOpenHardwareMonitor.exe"
timeout 3
net start "OHMservice"
del nssm.exe /QДва момента:
-
NSSM — простая и достаточно надёжная утилита с многолетней историей. Применяется как раз в случаях, когда ПО не имеет режима работы «сервис», а надо. Во вредоносности утилита не замечена;
-
Обратите внимание на «intelcpu» в скрипте получения температуры от OHM. Т.к. речь идёт о внедрении в малом офисе, можно рассчитывать на единообразие парка техники. Более того, таким образом лично у меня получилось извлечь и температуру ЦП от AMD. Но тем не менее этот пункт требует особого внимания. Возможно, придётся модифицировать и усложнять инсталлятор для большей универсальности.
Работает более чем надёжно, проблем не замечено.
Хотелка № 2: получаем и мониторим температуру чего угодно
Понадобятся нам две вещи:
-
Штука от братского китайского народа: стандартный цифровой термометр DS18B20, совмещённый с USB-UART контроллером. Стоит не сказать что бюджетно, но приемлемо;
-
powershell cкрипт:
param($cPort='COM3')
$port= new-Object System.IO.Ports.SerialPort $cPort,9600,None,8,one
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
if (([int]$tmp -lt 1) -or ([int]$tmp -gt 55)){
#echo ("trigg "+$tmp)
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
}
echo ($tmp)Связка работает достаточно надёжно, но есть интересный момент: иногда, бессистемно, появляются провалы или пики на графиках:
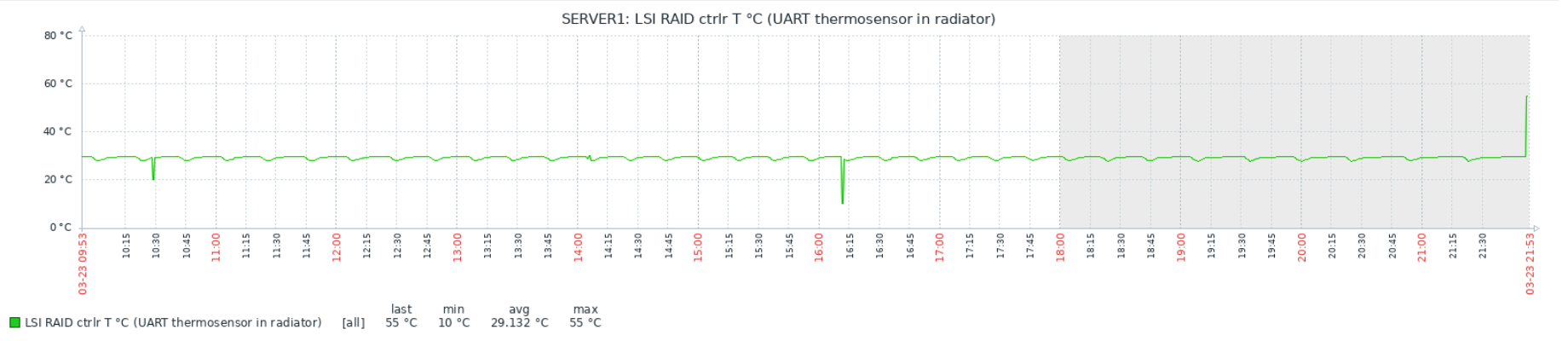
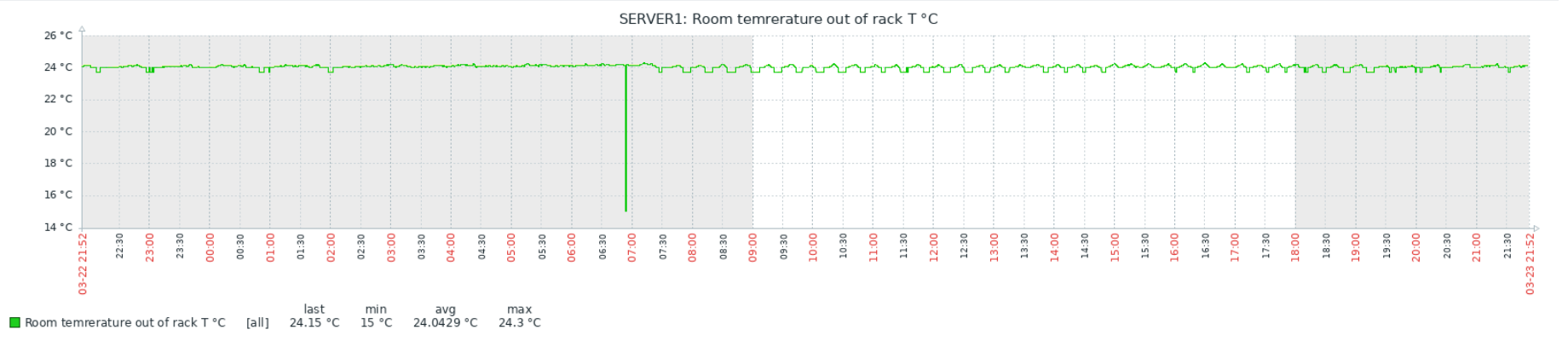
Тесты показали, что проблема в самом Zabbix, а данные с китайских датчиков приходят верные. Детальное рассмотрение пиков и провалов выявило неожиданный факт: похоже Zabbix иногда получает и/или записывает в БД не полное значение, а «хвост». Т.е., например, 1.50 от значения 21.50. При этом положение точки не важно — может получить и 1.50, и 50, и даже 0. Как так происходит, мне выяснить пока не удалось. Изменение timeout на поведение не влияет никак, ни в большую, ни в меньшую сторону.
Наверное, стоило бы написать багрепорт. Но уже вышел 6.0 LTS (у меня 5) и обновляться в текущей ситуации, пожалуй, не буду.
Хотелка № 3: OpenVPN подключения
Template’ов для OpenVPN и Zabbix существует довольно много, но все они реализованы на том или ином sh под *nix’ы . В свою очередь, «dashboard» OpenVPN-сервера представляет из себя, по сути, вывод утилиты в консоль, который пишется в файл по событиям. Мне лень было считать трафик по отдельным пользователям и вообще делать их discover, т.к. подключений и пользователей немного. Ограничился текущим количеством подключений:
$openvpnLogPath = "C:OpenVPNconfig"
$openvpnLogName = "openvpn-status.log"
try {
$logData = Get-Content $openvpnLogPath$openvpnLogName -ErrorAction Stop
}
catch{
Write-Host("Missing log file")
exit 1
}
$logHeader = "OpenVPN CLIENT LIST"
$logHeader2 = "Common Name,Real Address,Bytes Received,Bytes Sent,Connected Since"
$logMark1 = "ROUTING TABLE"
if ($logData[0] -ne $logHeader -or $logData[2] -ne $logHeader2 ){
Write-Host("Bad log file")
exit 1
}
$i = 0
foreach ($tmpStr in ($logData | select -skip 3)) {
if ($tmpStr -eq $logMark1) {break}
$i++
}
Write-Host($i)
exit 0Хотелка № 4: спецжелезка 1
Для большого количества специфического оборудования существуют написанные энтузиастами Template’ы. Обычно они используют и реализуют функционал, уже имеющийся в утилитах к этим железкам.
Боли лирическое отступление
установив один из таких темплейтов, я узнал, что «нормальная рабочая» температура чипа RAID-контроллера в серваке — 65+ градусов. Это, в свою очередь, побудило внимательнее посмотреть и на контроллер, и на сервер в целом. Были найдены косяки и выражены «фи»:
-
Apaptec’у – за игольчатый радиатор из неизвестного крашеного силумина высотой чуть более чем нихрена, поток воздуха к которому закрыт резервной батарейкой с высотой больше, чем радиатор. Особенно мне понравилось потом читать у Adaptec того же «ну, это его нормальная рабочая температура. Не волнуйтесь». Ответственно заявляю: при такой «нормальной рабочей температуре» контроллер безбожно и непредсказуемо-предсказуемо глючил;
-
Одному отечественному сборщику серверов. «Берём толстый жгут проводов. Скрепляем его, чтобы он был толстым, плотным, надёжным. Вешаем это прямо перед забором воздуха вентиляторами продува серверного корпуса. Идеально!». На «полу» сервера было дофига места, длины кабелей тоже хватало, но сделали почему-то так.
Также был замечен интересный нюанс поведения, связанный с Zabbix. Со старым RAID контроллером при наличии в системном логе специфичных репортов, отваливался мониторинг температуры контроллера в Zabbix, но! при запуске руками в консоли скрипта или спец. утилиты температура выводилась корректно и без задержек.
Но полный функционал реализован далеко не всегда. В частности, мне понадобились температуры жёстких дисков с нового RAID-контроллера (ну люблю я температуры, что поделать ), которых в оригинальном темплейте не было. Пришлось самому реализовывать температуры и заодно autodiscover физических дисков: https://github.com/automatize-it/zabbix-lsi-raid/commit/1d3a8b3a0e289b8c2df637028475177a2b940689

Оригинальный репозиторий, вероятно, заброшен, как это довольно часто бывает.
Хотелка № 5, на десерт: спецжелезка 2
Как и обещал, делюсь опытом вырывания данных из беспроводной железки Huawei. Речь о 4G роутере серии B*. Внутри себя железка имеет ПО на ASP, а данные о качестве сигнала — RSSI, SINR и прочее — в пользовательском пространстве показывать не хочет совсем. Смотри, мол, картинку с уровнем сигнала и всё, остальное не твоего юзерского ума дело. К счастью, в ПО остались какие-то хвосты, выводящие нужное в plain JSON. К сожалению, взять да скачать это wget-ом не получается никак: мало того, что авторизация, так ещё и перед генерацией plain json требуется исполнение JS на клиенте. К счастью, существует проект phantomjs. Кроме того, нам понадобится перенесённая руками кука из браузера, где мы единожды авторизовались в веб-интерфейсе, вручную. Кука живёт около полугода, можно было и скрипт написать, но я поленился.
Алгоритм действий и примеры кода:
вызываем phantomjs с кукой и сценарием:
phantomjs.exe --cookies-file=cookie.txt C:cmdyota_signalscenery.jsПримеры сценариев:
//получаем общий уровень сигнала
var url = "http://192.168.2.1/html/home.html";
var page = require('webpage').create();
page.open(url, function(status) {
//console.log("Status: " + status);
if(status === "success") {
var sgnl = page.evaluate(function() {
return document.getElementById("status_img").innerHTML; //
});
var stt = page.evaluate(function() {
return document.getElementById("index_connection_status").innerText; //
});
var sttlclzd = "dis";
var sgnlfnd = "NA";
if (stt.indexOf("Подключено") != -1) {sttlclzd = "conn";}
if (sgnl.indexOf("icon_signal_01") != -1) {sgnlfnd = "1";}
else {
var tmpndx = sgnl.indexOf("icon_signal_0");
sgnlfnd = sgnl.substring(tmpndx+13,tmpndx+14);
}
console.log(sttlclzd+","+sgnlfnd);
var fs = require('fs');
try {
fs.write("C:cmdsiglvl.txt", sgnlfnd, 'w');
} catch(e) {
console.log(e);
}
}
phantom.exit();
});
//получаем технические параметры сигнала через какбэ предназначенный для этого "API"
var url = "http://192.168.2.1/api/device/signal";
var page = require('webpage').create();
page.onLoadFinished = function() {
//console.log("page load finished");
//page.render('export.png');
console.log(page.content);
parser = new DOMParser();
xmlDoc = parser.parseFromString(page.content,"text/xml");
var rsrq = xmlDoc.getElementsByTagName("rsrq")[0].childNodes[0].nodeValue.replace("dB","");
var rsrp = xmlDoc.getElementsByTagName("rsrp")[0].childNodes[0].nodeValue.replace("dBm","");
var rssi = xmlDoc.getElementsByTagName("rssi")[0].childNodes[0].nodeValue.replace("dBm","").replace(">=","");
var sinr = xmlDoc.getElementsByTagName("sinr")[0].childNodes[0].nodeValue.replace("dB","");
var fs = require('fs');
try {
fs.write("C:cmdrsrq.txt", rsrq, 'w');
fs.write("C:cmdrsrp.txt", rsrp, 'w');
fs.write("C:cmdrssi.txt", rssi, 'w');
fs.write("C:cmdsinr.txt", sinr, 'w');
} catch(e) {
console.log(e);
}
phantom.exit();
};
page.open(url, function() {
page.evaluate(function() {
});
});
Конструкция запускается из планировщика задач. В Zabbix-агенте производится лишь чтение соответствующих файлов:
UserParameter=internet.devices.huawei1.signal.level,type C:cmdsiglvl.txt 
Требует постоянного присмотра, ручных прибиваний и перезапусков процессов, обновления кук. Но для такого шаткого нагромождения фекалий и палок работает достаточно стабильно.
Итого
Стоит ли заморачиваться на Zabbix, если у вас 20 машин и 1-2 сервера, да ещё и инфраструктура Windows?
Как можно понять из вышеизложенного, работы будет много. Я даже рискну предположить, что объёмы работ и уровень квалификации для них сравнимы с решением «свелосипедить своё с нуля по-быстрому на коленке».
Не стоит рассматривать Zabbix как панацею или серебряную пулю.
Тем не менее, использование уже готового и популярного продукта имеет свои преимущества — в первую очередь, это релевантный опыт для интересных работодателей.
А красивые графики дают усладу глазам и часто — новое видение процессов в динамике.
Если захочется внедрить, то могу пообещать, как минимум — скучно не будет!
Zabbix – Мониторинг логов
Задача
Требуется мониторить логи Centos 7 /var/log/messages на предмет записи “Out of memory: Kill process”
Подготовка сервера, который мы будем мониторить
Добавляем файл /var/log/messages в группу zabbix и назначить на него права доступа 640
[root@localhost]# chown root:zabbix /var/log/messages
[root@localhost]# chmod 0640 /var/log/messagesПроверяем настройки zabbix agent.
Server = ip-адрес Zabbix Server
ServerActive = ip-адрес Zabbix Server
Hostname = Такое же имя, как прописано в вэб интерфейсе Zabbix Server (Настройки - Узлы сети)Настройка мониторинга в Zabbix
Настройки – Узлы сети – выбираем наш сервер, на котором мы будем мониторить логи.
Добавляем новую группу элементов данных:
Переходим во вкладку “Группы элементов данных”, нажимаем “Создать группу элементов данных”, я назвал ее log.
Добавляем новый элемент данных:
Переходим во вкладку “Элементов данных”, нажимаем “Создать элемент данных”
Имя: log_messages
Тип: Zabbix агент (активные)
Ключ: log[/var/log/messages,"Out of memory: Kill process","UTF-8",100]
Тип информации: Журнал (лог)
Группы элементов данных: logДобавляем новый триггер:
Переходим во вкладку “Триггеры”, нажимаем “Создать триггер”
Имя: cl-gc-geoserver-01:log_messages:Kill_process
Важность: Высокая
Выражение: {cl-gc-geoserver-01:log[/var/log/messages,"Out of memory: Kill process","UTF-8",100].str(Kill,30)}=1 and {cl-gc-geoserver-01:log[/var/log/messages,"Out of memory: Kill process","UTF-8",100].nodata(30)}=0Триггер срабатывает при наличии строки Kill в пересылаемых данных и отключается через 30 секунд отсутствия новых данных.
UPD 03.04.2019
Бывают случаи, когда в элементах данный узла сети висит сообщение
zabbix cannot open file /var/log/messages 13 permission deniedИ из-за этого элемент данных не активен, следовательно логи не приходят на почту
Это случается из-за следующих моментов:
- SeLinux блокирует zabbix-agent
- права доступа на файл /var/log/messages принадлежат пользователю root
Что бы добавить zabbix-agent в исключение для SeLinux, устанавливаем утилиту policycoreutils
[root@localhost]# yum install policycoreutils-pythonИ выполняем команду
[root@localhost]# semanage permissive -a zabbix_agent_tПосле этого надо перезапустить zabbix-agent
[root@localhost]# systemctl restart zabbix-agentЧто бы открыть доступ для zabbix-agent на чтение файла /var/log/messages, изменим права доступа
[root@localhost]# chown root:zabbix /var/log/messages
У блога появился хостинг, его любезно предоставила компания Облакотека. Облакотека — облачные сервисы для создания и управления виртуальной ИТ-инфраструктурой.
Если вам понравился мой блог и вы хотели бы видеть на нем еще больше полезных статей, большая просьба поддержать этот ресурс.
Если вы размещаете материалы этого сайта в своем блоге, соц. сетях, и т.д., убедительная просьба публиковать обратную ссылку на оригинал
Zabbix может многое. Главное — суметь это настроить Одна из полезных возможностей — мониторинг лог-файлов на наличие определенных записей. Если вы хотите держать руку на пульсе событий при мониторинге серверов, то без мониторинга логов никак не обойтись: почти все серьезные ошибки пишутся в логи и во многих случаях гораздо эффективнее мониторить один-два лога, чем настраивать отслеживания статуса 50 сервисов, работоспособность которых не всегда легко проверить.
Мониторинг логов возможен только при установке агента на хост
Собственно, в самой настройке мониторинга логов нет ничего сложного: добавляем соответствующий Item, пишем регулярное выражение для триггера и начинаем получать уведомления! Например, мы хотим отслеживать все ошибки из System лога на серверах под управлением OS Windows. Для этого, создаем следующий Item:
eventlog[System,,"Error",,@eventlog,,skip]
Параметры следующие: System — лог, который отслеживаем; второй параметр — регулярное выражение, которое ищем (пропущен, берем все записи); третий — «Error» — важность, согласно классификации ОС; четвертый — любой источник; пятый — @eventlog — макрос, который исключает события с идентификаторами ^(1111|36888|36887|36874)$; шестой — максимальное кол-во строк, которое мы отправляем серверу в секунду (неограниченное); последний параметр — skip — заставляет сервер читать только новые записи лога, а не перечитывать его весь.
В качестве триггера мы используем следующую строку:
{host:eventlog[System,,"Error",,@eventlog,,skip].regexp(^.*$)}<>0
Т.е. мы берем любую строку, которая попала в Item и высылаем уведомление.
После такой настройки мы получим первую ошибку из лога и триггер будет висеть в состоянии PROBLEM до скончания веков, т.к. нет события, которое его переводит в состояние OK. Для решения этой проблемы необходимо добавить к триггеру еще одно условие: наличие новых данных в течение промежутка времени, меньшего, чем время опроса Item. Т.е. если мы проверяем лог на ошибки раз в минуту, то нам надо поставить любой промежуток времени, меньший, чем минута. Итоговый триггер будет выглядеть как-то так:
{host:eventlog[System,,"Error",,@eventlog,,skip].regexp(^.*$)}<>0 and {host:eventlog[System,,"Error",,@eventlog,,skip].nodata(10)}<>1
Выглядеть это будет как «нашли что-то в Item» И «за последние 10 секунд были получены новые данные». При следующей проверке триггер перейдет в состояние OK, т.к. за последние 10 секунд новых данных получено не было. Других способов возврата триггера для лога в нормальное состояние в заббиксе версии 2 не предусмотрено.